




 本文深入探讨了ASCII、GB系列、Unicode及UTF-8等字符编码的基本原理,并提供了Unity中实现不同编码方式下字符长度限制的具体代码示例。
本文深入探讨了ASCII、GB系列、Unicode及UTF-8等字符编码的基本原理,并提供了Unity中实现不同编码方式下字符长度限制的具体代码示例。
问题:游戏中输入角色名字不能超过一定字节数,记作n
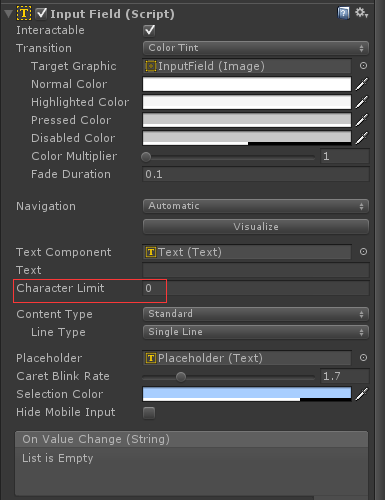
组件InputField里
Character Limit:限制字符长度(0表示不限制),比如:设置只能输入3个字符(中文,英文,数字,符号都按1个字符来算)
当设置为5,
输出结果:
中文或者英文,均只能输入五个。
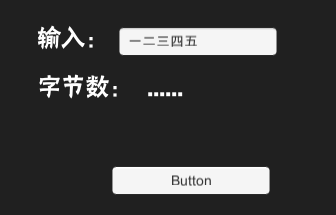
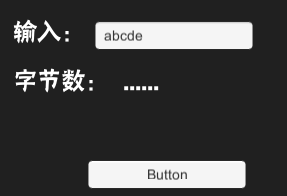
明显不满足,十个字节=5个中文=10个英文
所以,需要添加额外代码检测,判断是否超过了n个字节。
在此之前,先了解ASCII、gb系列、Unicode、UTF-8的区别
- ASCII码
美国:八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。ASCII码一共规定了128个字符的编码,这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。范围:0000000~1111111
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
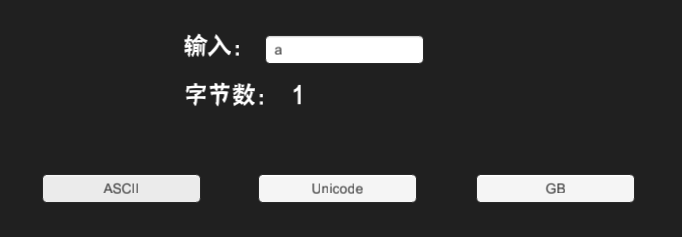
测试:
using UnityEngine;
using System.Collections;
using UnityEngine.UI;
public class CheckASCIICodeScript : MonoBehaviour {
public InputField m_input;//输入的内容
public Text m_output;//输出
public Button m_AsciiBtn;
public Button m_unicodeBtn;
public Button m_GBBtn;
public Button m_UTF8;
void Start()
{
m_AsciiBtn.onClick.AddListener(OnExcuteHandler);
m_unicodeBtn.onClick.AddListener(OnExcuteUnicodeHandler);
m_GBBtn.onClick.AddListener(OnExcuteGBHandler);
m_UTF8.onClick.AddListener(OnExcuteUTF8Handler);
}
private void OnExcuteUTF8Handler()
{
byte[] encodedBytes = System.Text.ASCIIEncoding.UTF8.GetBytes(m_input.text);
m_output.text = encodedBytes.Length + "";
Output(encodedBytes, "UTF8", m_input.text);
}
private void OnExcuteGBHandler()
{
byte[] encodedBytes = System.Text.ASCIIEncoding.Default.GetBytes(m_input.text);
m_output.text = encodedBytes.Length + "";
Output(encodedBytes,"GB",m_input.text);
}
private void OnExcuteUnicodeHandler()
{
byte[] encodedBytes = System.Text.ASCIIEncoding.Unicode.GetBytes(m_input.text);
m_output.text = encodedBytes.Length + "";
Output(encodedBytes, "Unicode",m_input.text);
}
private void OnExcuteHandler()
{
byte[] encodedBytes = System.Text.ASCIIEncoding.ASCII.GetBytes(m_input.text);
m_output.text = encodedBytes.Length + "";
Output(encodedBytes,"ASCII", m_input.text);
}
/// <summary>
/// 按十六进制 输出
/// </summary>
/// <param name="encodedBytes"></param>
private void Output(byte[] encodedBytes,string noticeType,string inputContent)
{
string result = "";
string asciiCode = "";
for (int byteIndex = 0; byteIndex < encodedBytes.Length; byteIndex++)
{
asciiCode += encodedBytes[byteIndex]+" ";
string sixteenStr = encodedBytes[byteIndex].ToString("x");//十六进制
result += "0X" + sixteenStr.ToUpper() + " ";
bool isChinese = encodedBytes[byteIndex]<0 || encodedBytes[byteIndex]>127;
}
Debug.Log("[ "+inputContent+" ]" + "的" + noticeType);
Debug.Log("ASCII= " + asciiCode);
Debug.Log("十六进制= "+result);
}
}
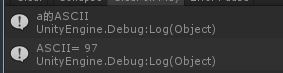
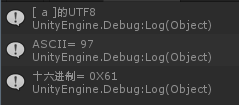
输入a,结果:
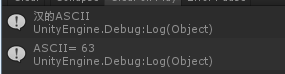
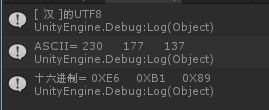
输入汉字,结果都是63,因为汉字超过了128,所以获取不了正确的ASCII。
- 非ASCII码
1个字节==8个二进制位,1个英文字母==1个字符==1个字节,1个汉字==2个字节
(1)其他非英语国家,各自为政,将剩下的128个未占用状态填充上自己的语言。这也仅可添加128种,对于高达10万的汉字来讲肯定是不够的。
(2)GB2312。于是GB2312就出来了,GB2312 是对 ASCII 的中文扩展, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。
(3)GBK。但是这对于汉字来讲还是不够,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
(4)GB18030。对于GBK再扩展,加入几千个新的少数民族的字。
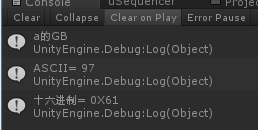
输入a:
输入汉字:

汉字的第一位字节的ASCII码186已经超过了128。故说明,通过单独取ASCII是无法得到正确结果,一直返回的是63.
UNICODE编码
每个国家都搞出像天朝这样一套自己的编码标准,于是ISO(国际标谁化组织)重新搞了一套标准–UNICODE, 在UNICODE中,一个汉字算两个英文字符的时代已经快过去了。UNICODE的UCS-2编码方式是定长双字节编码,包括英文字母在内。UCS-2只能表示65535个字符,IOS预备了UCS-4方案,四个字节来表示一个字符,可以组合出21亿个不同的字符出来(最高位有其他用途)。英文字母只用一个字节表示就够了,但是其他更大的符号可能需要3个字节或者4个字节,甚至更多。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费。
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。于是出现了多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。unicode在很长一段时间内无法推广,直到互联网的出现。

输入汉字:你,
结果为:
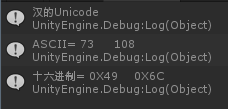
输入a,英文也由两个字节组成。第二个字节为0
结果为:
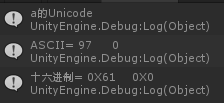
UTF8
UTF-8是Unicode的实现方式之一,传输、存储,其他还有UTF-16(字符用两个字节或四个字节表示),UTF-32(字符用四个字节表示)。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。1个字节==8个二进制位==2^8==256。UTF-8的编码规则很简单,只有二条:
(1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
(2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
——————–+———————————————
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx

如果是汉字,每一位ascii 大于128
因此当指定一个文本里最多出现多少个字节的字的时候,
可以通过InputField OnValueChange拖入脚本,这样,没输入一个字符(中文或英文)都会及时检测。
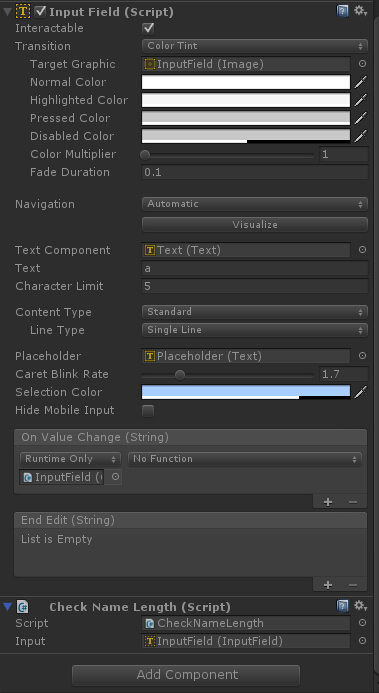
检测方法有几个:
using UnityEngine;
using System.Collections;
using UnityEngine.UI;
using System;
public class CheckNameLengthScript : MonoBehaviour {
public InputField input;
private const int CHARACTER_LIMIT = 10;
public CheckNameLengthScript.SplitType m_SplitType = SplitType.ASCII;
public enum SplitType
{
ASCII=1,
GB=2,
Unicode=3,
UTF8=4,
}
public void Check()
{
input.text = GetSplitName((int)m_SplitType);
}
public string GetSplitName(int checkType)
{
string temp = input.text.Substring(0, (input.text.Length < CHARACTER_LIMIT + 1) ? input.text.Length : CHARACTER_LIMIT + 1);
if (checkType == (int)SplitType.ASCII)
{
return SplitNameByASCII(temp);
}
else if (checkType == (int)SplitType.GB)
{
return SplitNameByGB(temp);
}
else if (checkType == (int)SplitType.Unicode)
{
return SplitNameByUnicode(temp);
}
else if (checkType == (int)SplitType.UTF8)
{
return SplitNameByUTF8(temp);
}
return "";
}
//4、UTF8编码格式(汉字3byte,英文1byte),//UTF8编码格式,目前是最常用的
private string SplitNameByUTF8(string temp)
{
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
string tempStr = temp.Substring(i, 1);
byte[] encodedBytes = System.Text.ASCIIEncoding.UTF8.GetBytes(tempStr);//Unicode用两个字节对字符进行编码
string output = "[" + temp + "]";
for (int byteIndex = 0; byteIndex < encodedBytes.Length; byteIndex++)
{
output += Convert.ToString((int)encodedBytes[byteIndex], 2)+" ";//二进制
}
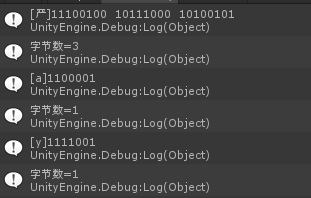
Debug.Log(output);
int byteCount = System.Text.ASCIIEncoding.UTF8.GetByteCount(tempStr);
Debug.Log("字节数=" + byteCount);
if (byteCount>1)
{
count += 2;
}
else
{
count += 1;
}
if (count <= CHARACTER_LIMIT)
{
outputStr += tempStr;
}
else
{
break;
}
}
return outputStr;
}
private string SplitNameByUnicode(string temp)
{
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
string tempStr = temp.Substring(i, 1);
byte[] encodedBytes = System.Text.ASCIIEncoding.Unicode.GetBytes(tempStr);//Unicode用两个字节对字符进行编码
if(encodedBytes.Length==2)
{
int byteValue = (int)encodedBytes[1];
if (byteValue == 0)//这里是单个字节
{
count += 1;
}
else
{
count += 2;
}
}
if (count <= CHARACTER_LIMIT)
{
outputStr += tempStr;
}
else
{
break;
}
}
return outputStr;
}
private string SplitNameByGB(string temp)
{
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
string tempStr = temp.Substring(i, 1);
byte[] encodedBytes = System.Text.ASCIIEncoding.Default.GetBytes(tempStr);
if (encodedBytes.Length == 1)
{
//单字节
count += 1;
}
else
{
//双字节
count += 2;
}
if (count <= CHARACTER_LIMIT)
{
outputStr += tempStr;
}
else
{
break;
}
}
return outputStr;
}
private string SplitNameByASCII(string temp)
{
byte[] encodedBytes = System.Text.ASCIIEncoding.ASCII.GetBytes(temp);
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
if ((int)encodedBytes[i] == 63)//双字节
count += 2;
else
count += 1;
if (count <= CHARACTER_LIMIT)
outputStr += temp.Substring(i, 1);
else if (count > CHARACTER_LIMIT)
break;
}
if (count <= CHARACTER_LIMIT)
{
outputStr = temp;
}
return outputStr;
}
}

















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









