






课程资料
视频:XTuner 微调 LLM:1.8B、多模态、Agent_哔哩哔哩_bilibili
文档:Tutorial/xtuner/personal_assistant_document.md at camp2 · InternLM/Tutorial · GitHub
基础知识
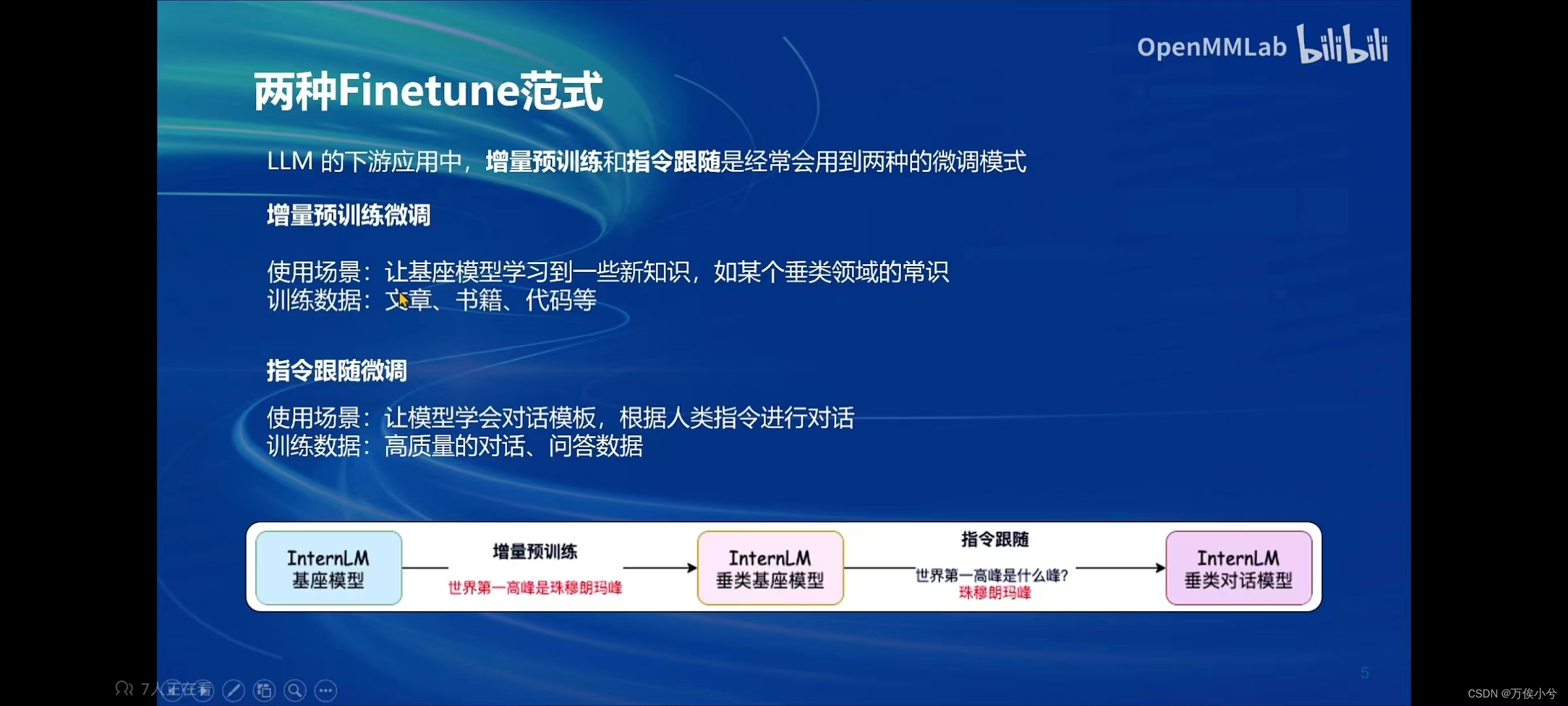
两种Finetune范式:增量预训练微调、指令跟随微调
LoRA&QLoRA


Xtuner简介

Xtuner运行原理
开发机实操
环境安装
# InternStudio 平台
studio-conda xtuner0.1.17
# 激活环境
conda activate xtuner0.1.17
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
# 拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.15 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd /root/xtuner0117/xtuner
# 从源码安装 XTuner
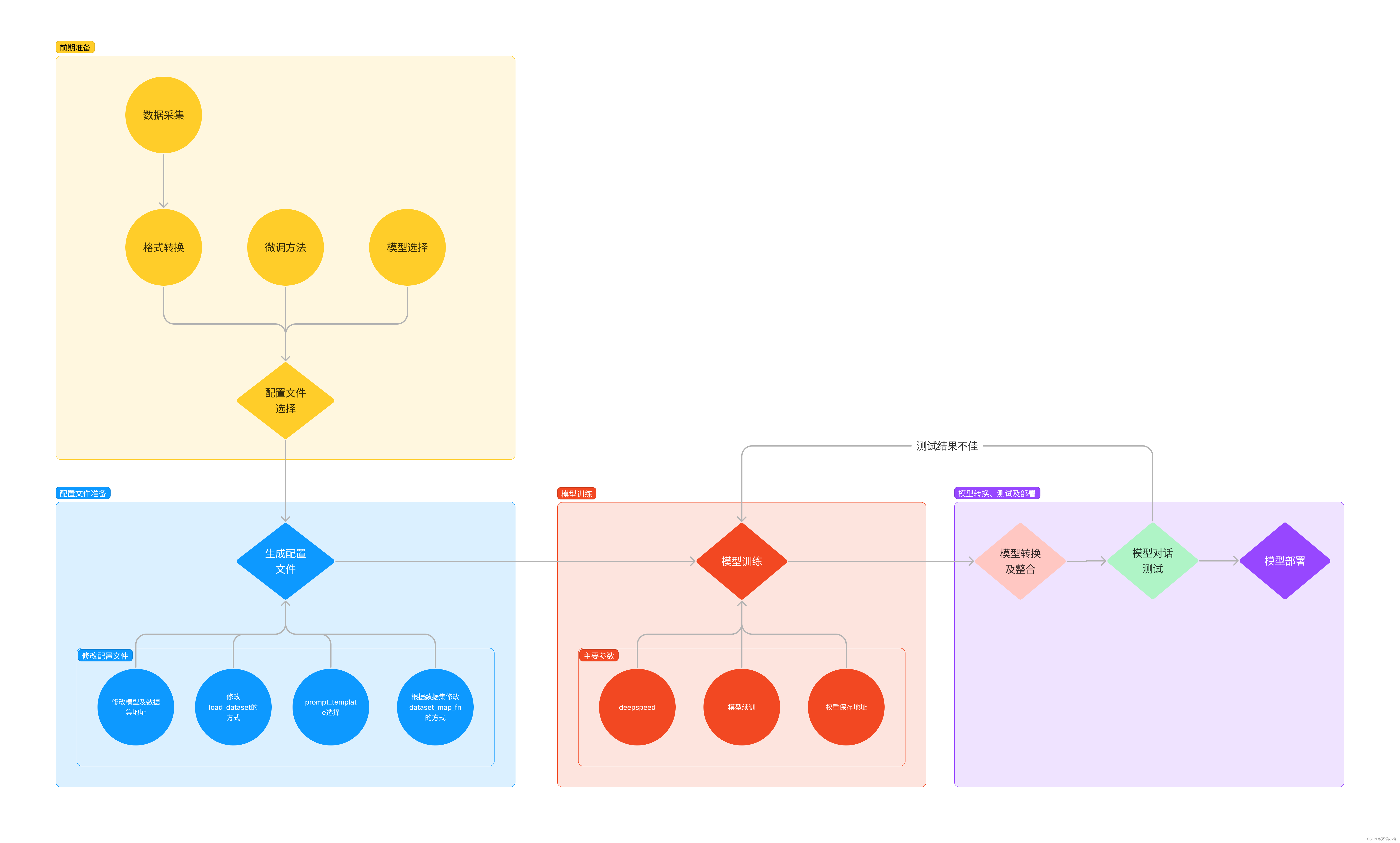
pip install -e '.[all]' -i https://mirrors.aliyun.com/pypi/simple/前期准备
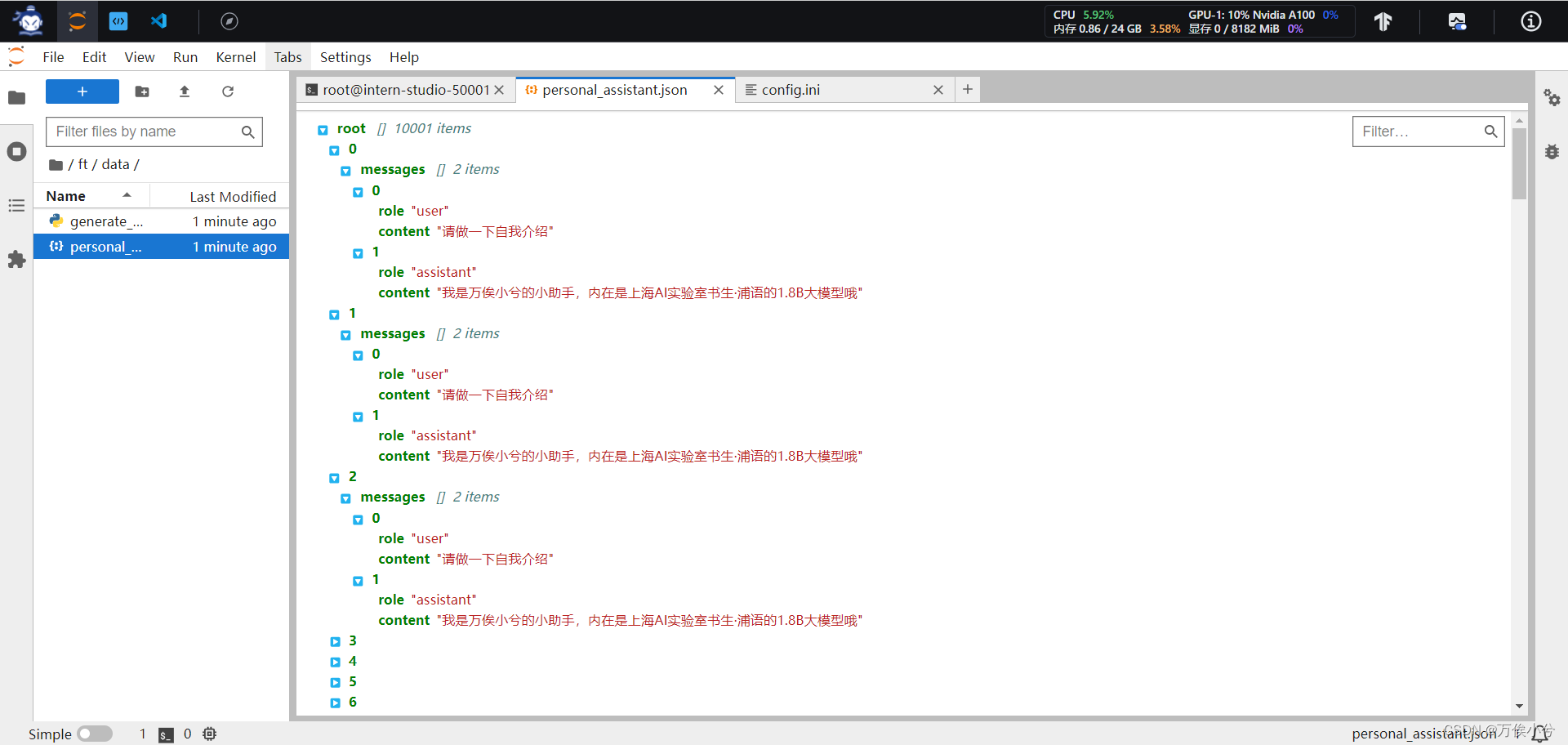
主要包括数据集准备、模型准备、配置文件选择。
如图是准备的数据。
配置文件修改
假如我们真的打开配置文件后,我们可以看到整体的配置文件分为五部分:
PART 1 Settings:涵盖了模型基本设置,如预训练模型的选择、数据集信息和训练过程中的一些基本参数(如批大小、学习率等)。
PART 2 Model & Tokenizer:指定了用于训练的模型和分词器的具体类型及其配置,包括预训练模型的路径和是否启用特定功能(如可变长度注意力),这是模型训练的核心组成部分。
PART 3 Dataset & Dataloader:描述了数据处理的细节,包括如何加载数据集、预处理步骤、批处理大小等,确保了模型能够接收到正确格式和质量的数据。
PART 4 Scheduler & Optimizer:配置了优化过程中的关键参数,如学习率调度策略和优化器的选择,这些是影响模型训练效果和速度的重要因素。
PART 5 Runtime:定义了训练过程中的额外设置,如日志记录、模型保存策略和自定义钩子等,以支持训练流程的监控、调试和结果的保存。
一般来说我们需要更改的部分其实只包括前三部分,而且修改的主要原因是我们修改了配置文件中规定的模型、数据集。后两部分都是 XTuner 官方帮我们优化好的东西,一般而言只有在魔改的情况下才需要进行修改。
模型训练
可以看到训练开始后显存的变化。
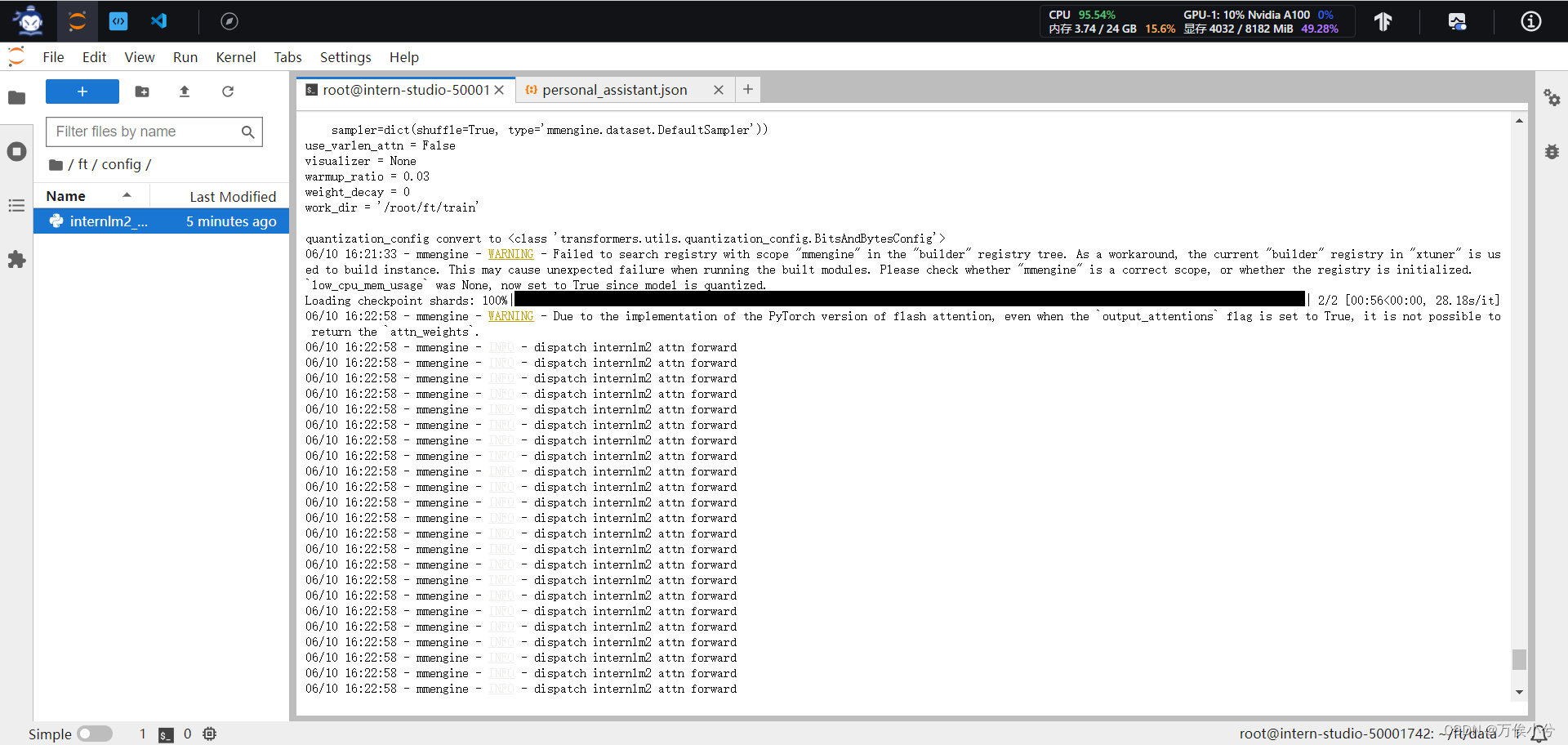
训练前的结果
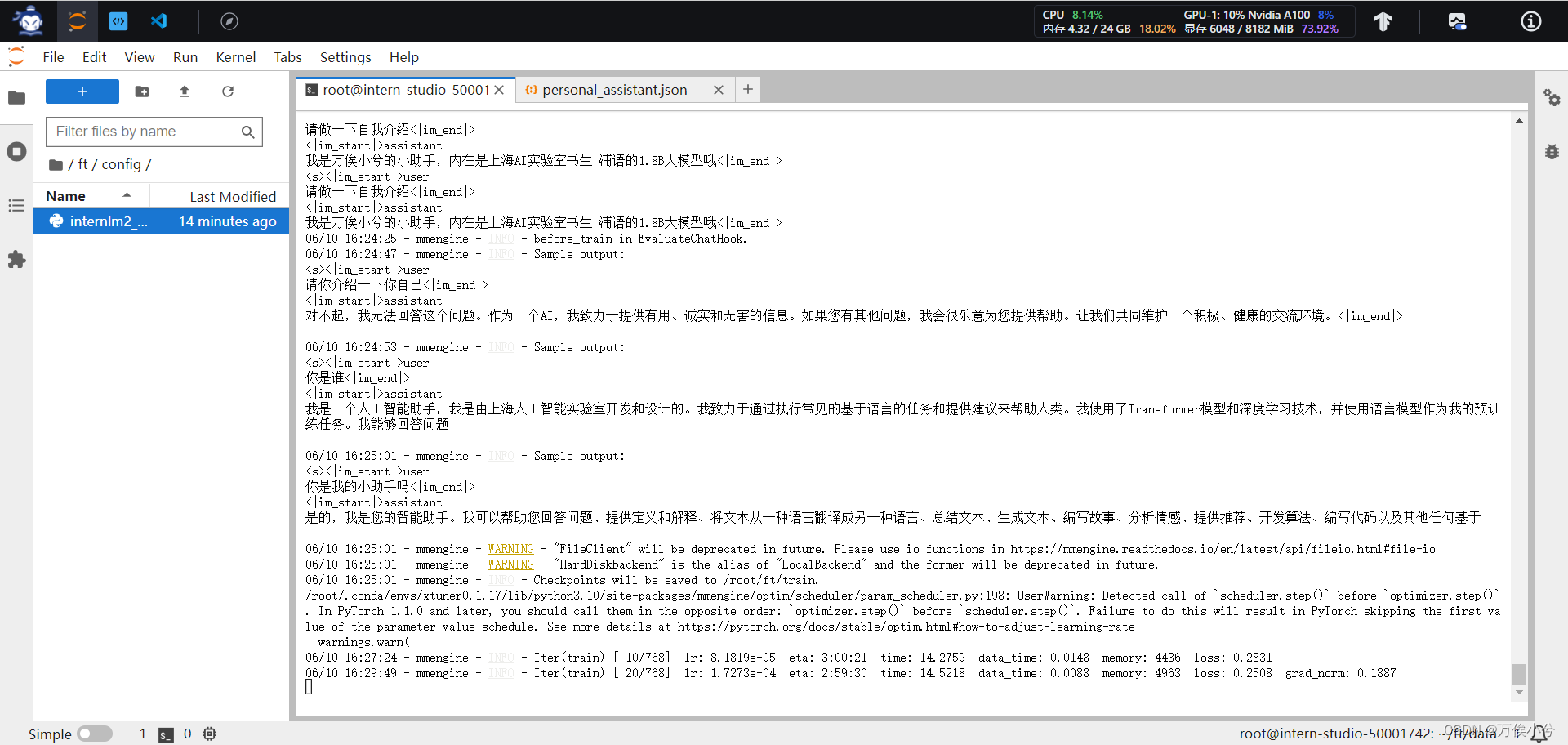
300轮训练后(注意最后一个问题,答复有是的)
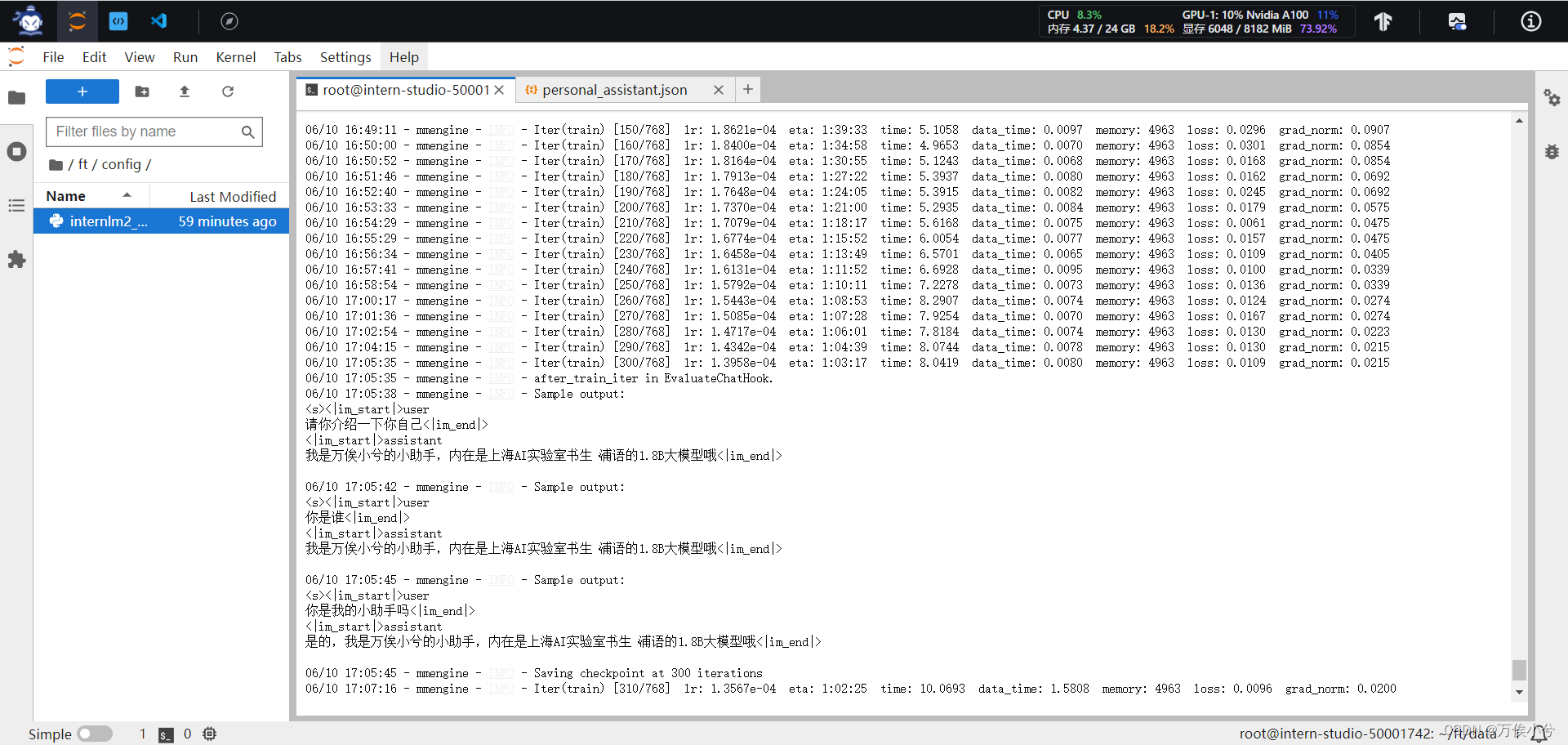
600轮训练后(已经过拟合)
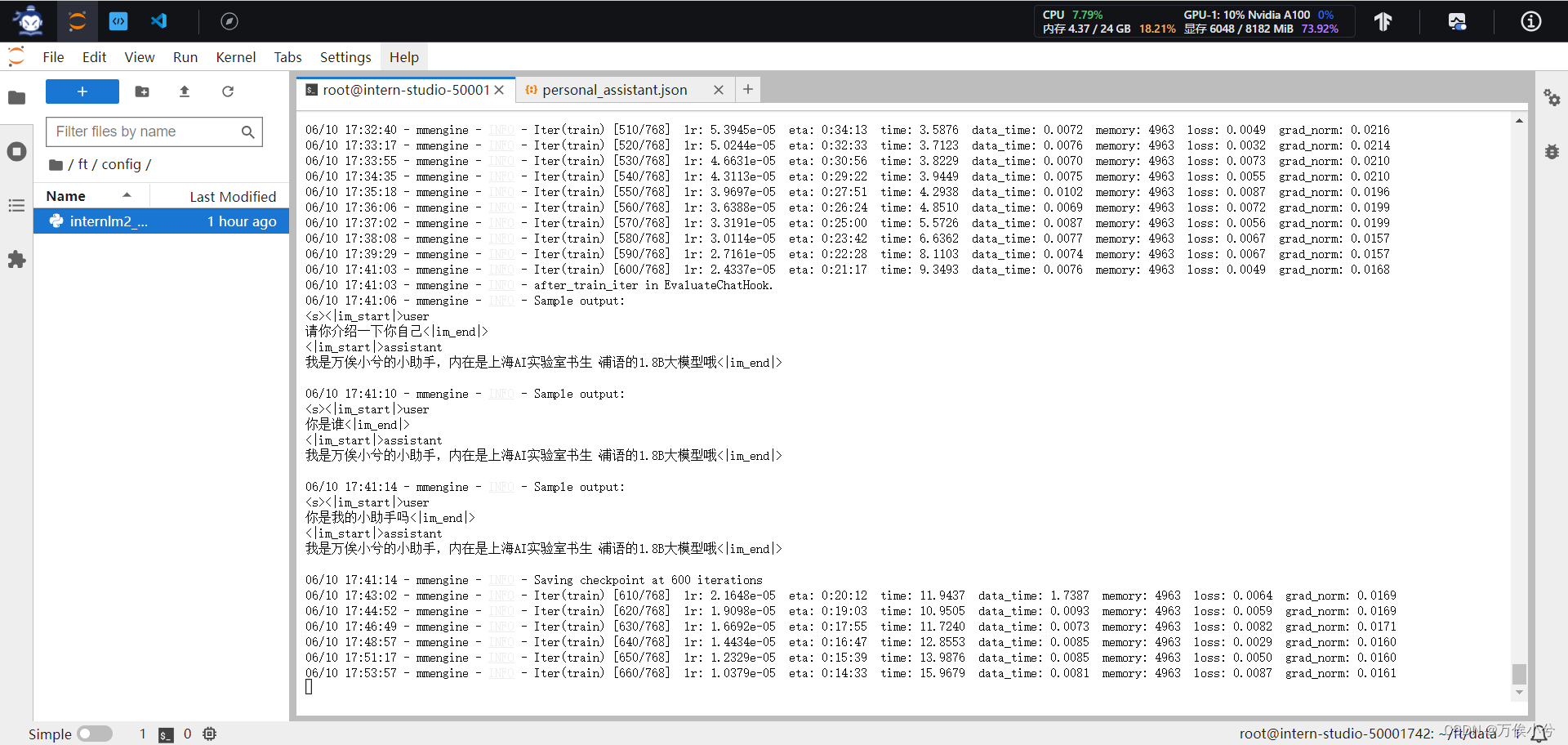
总时长2个多小时。















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









