







 本文介绍了如何使用XTuner对1.8B规模的多模态LLM进行Finetuning,涉及数据准备、环境配置、模型设置、Finetune步骤和前后对比,包括参数调整和训练优化技巧。
本文介绍了如何使用XTuner对1.8B规模的多模态LLM进行Finetuning,涉及数据准备、环境配置、模型设置、Finetune步骤和前后对比,包括参数调整和训练优化技巧。
目录
Step1:修改llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py文件
【视频地址】:XTuner 微调 LLM:1.8B、多模态、Agent_哔哩哔哩_bilibili
【课程文档】:https://github.com/InternLM/Tutorial/blob/camp2/xtuner/readme.md
【作业文档】:https://github.com/InternLM/Tutorial/blob/camp2/xtuner/homework.md
课程笔记
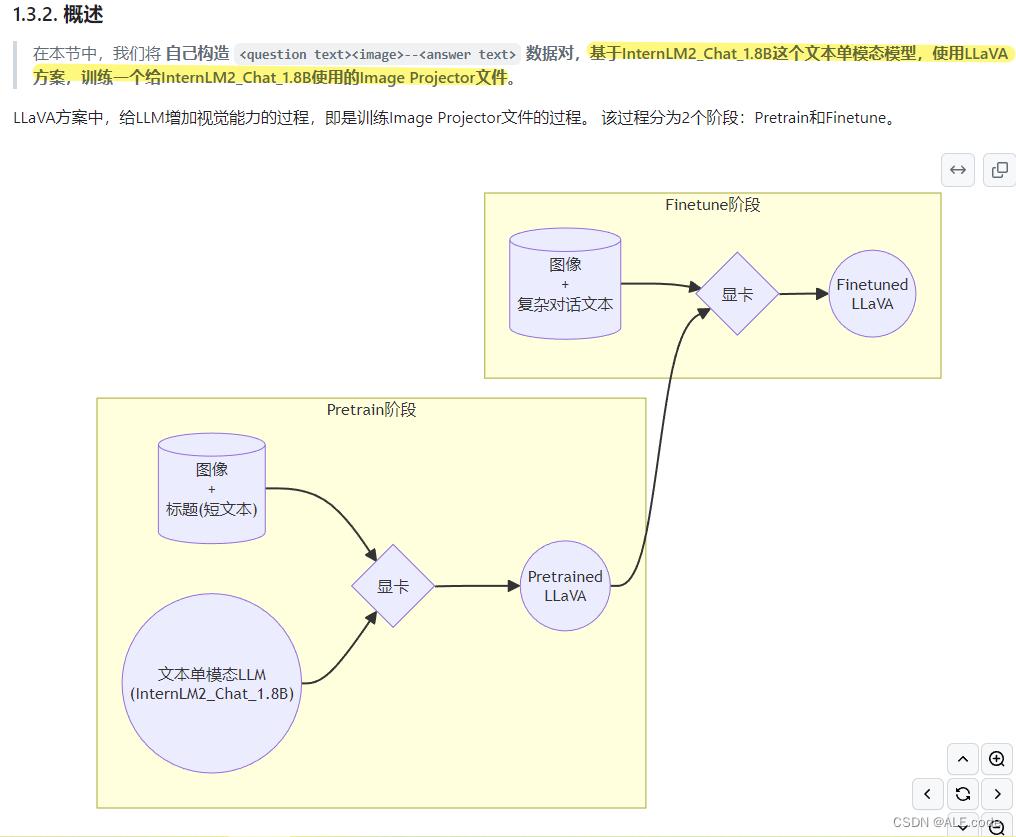
Finetune

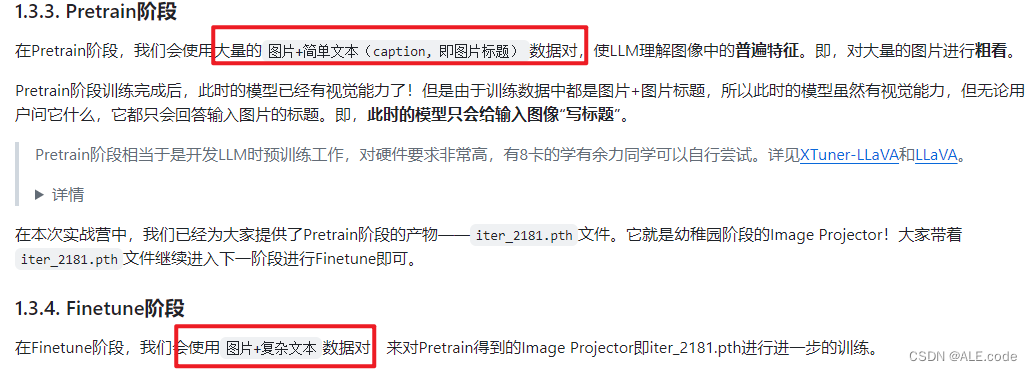
增量预训练微调训练数据:不用一问一答式的标注
指令微调训练数据:需要标注,数据标注格式:QA pairs

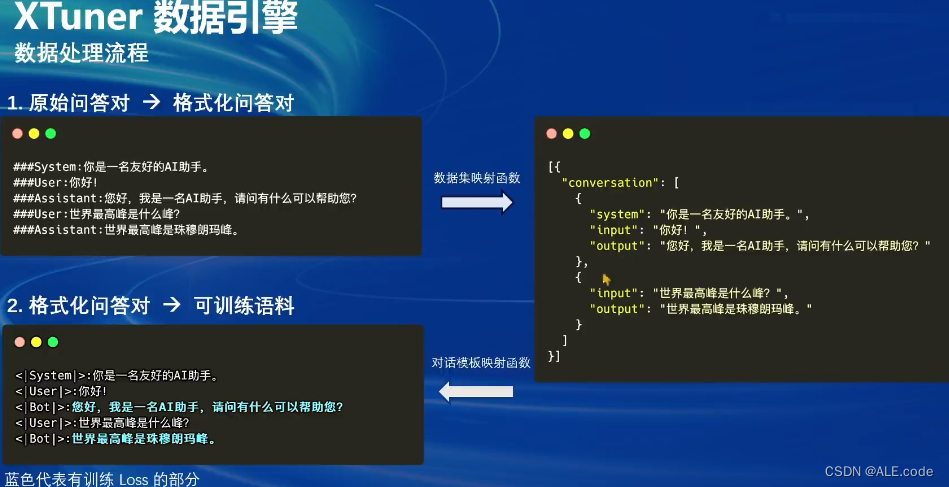
一条数据的一生
在XTuner中已经封装好了对应的对话模板,咱们只需要构建json数据格式。

对话模板:包含对话起始与结束
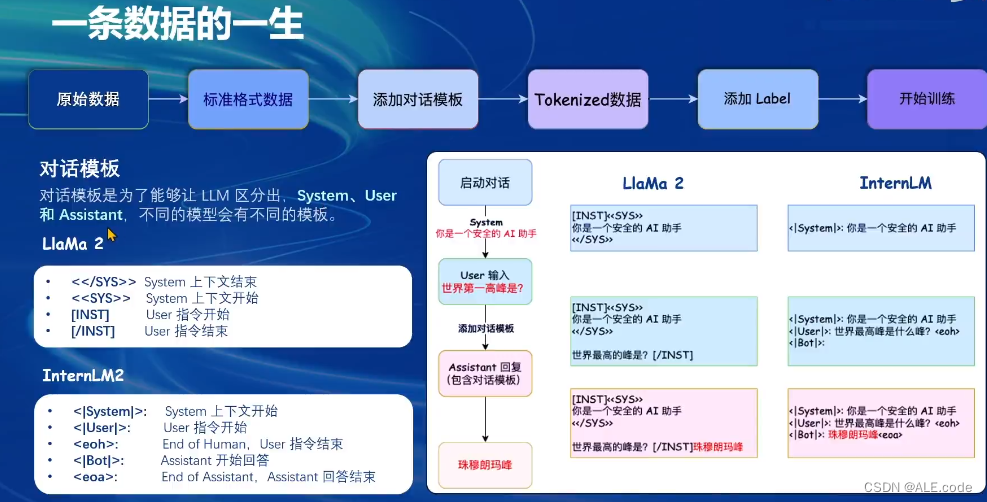
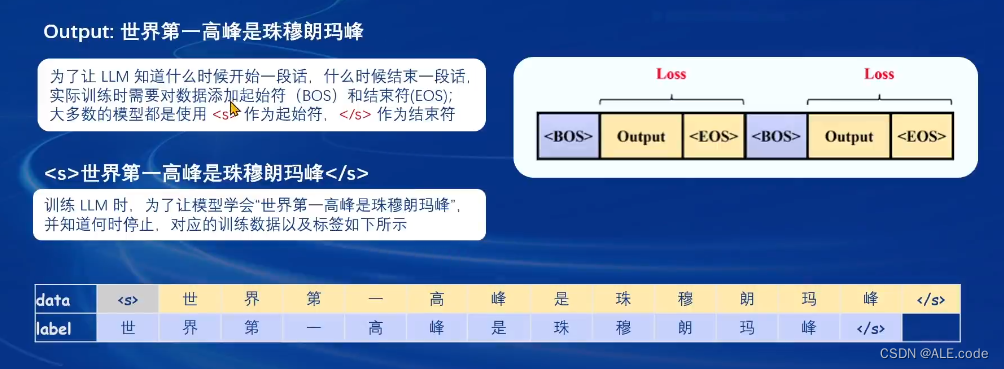
具体详细如下:

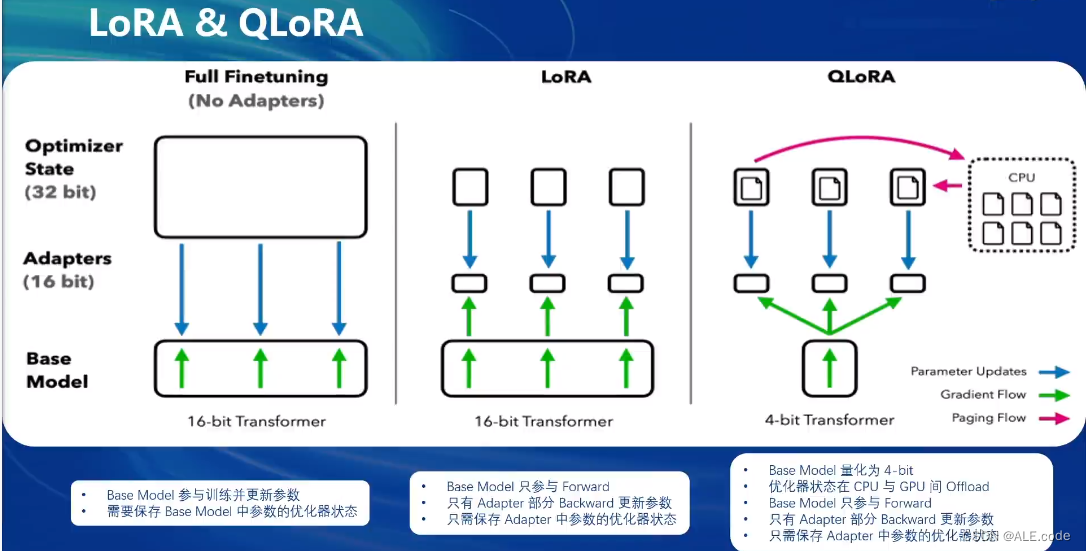
- XTuner中是使用LoRA & QLoRA进行微调

全参数微调与LoRA&QLoRA的区别
XTuner介绍

一些配置以及常用的超参

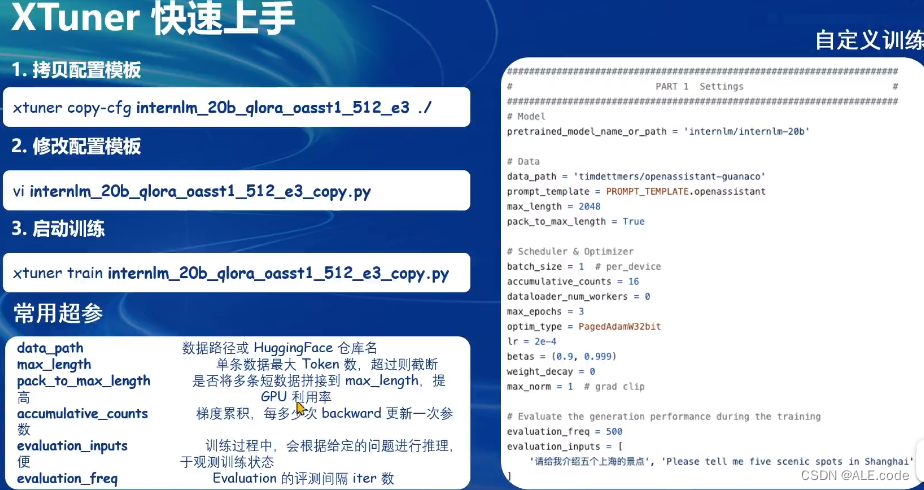
- 发现显存没有吃满时,可以使用pack_to_max_length调大一些
- 目前主要使用InternLM2-Chat-1.8B作为foundation model

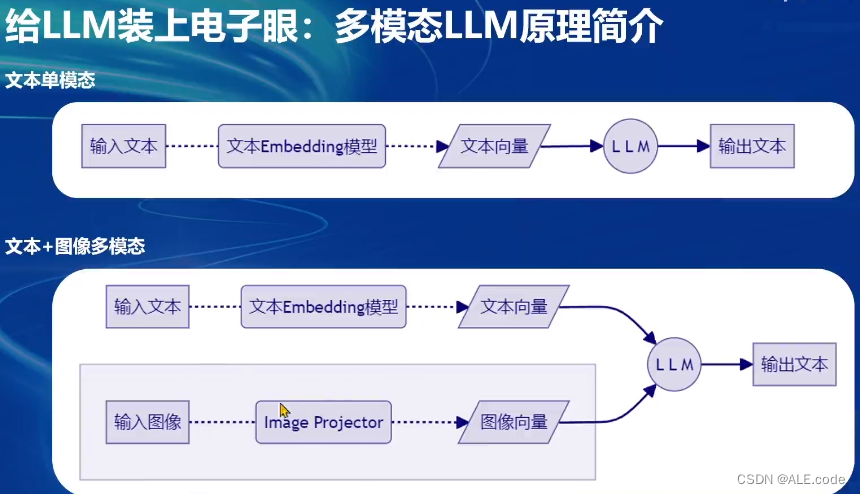
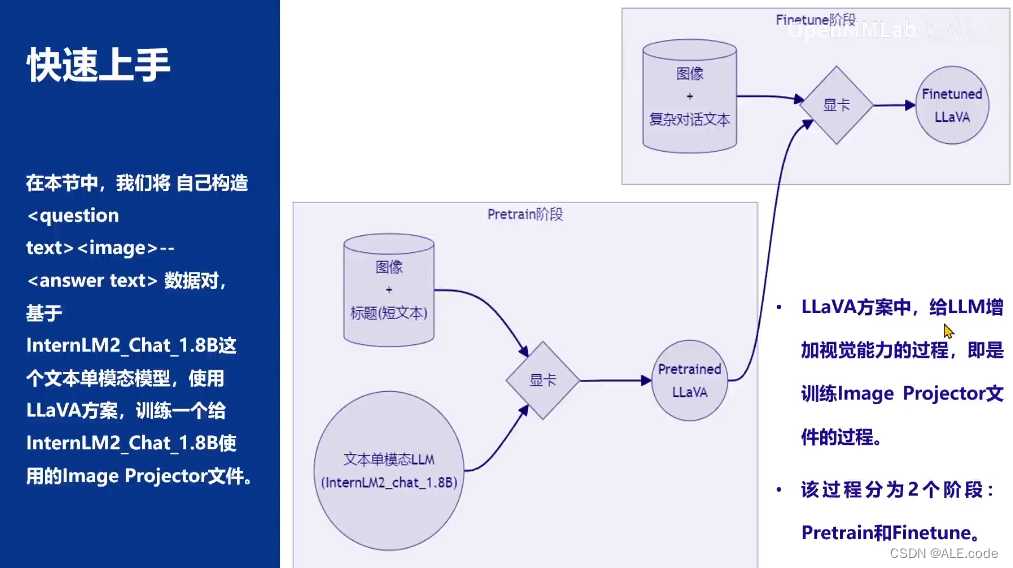
多模态LLM
根据上图的形象比喻,在下面来一一分别阐述。

多模态LLM原理
方案
LLaVA是用于识图,而非生图
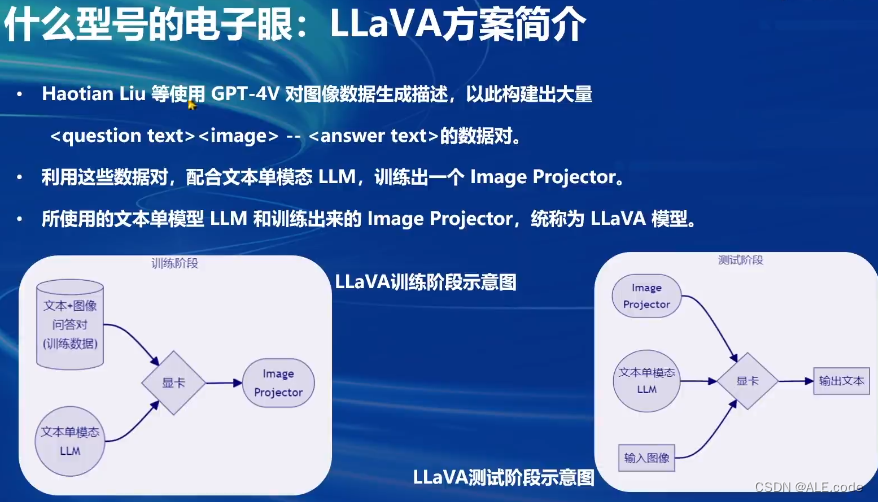
形象的比喻:

基础作业
参考文章1:
Tutorial/xtuner/personal_assistant_document.md at camp2 · InternLM/Tutorial · GitHub
- 训练自己的小助手认知(记录复现过程并截图)
环境安装
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 的环境:
# pytorch 2.0.1 py3.10_cuda11.7_cudnn8.5.0_0
cd ~ && studio-conda xtuner0.1.17
# 如果你是在其他平台:
# conda create --name xtuner0.1.17 python=3.10 -y
# 激活环境
conda activate xtuner0.1.17
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
# 拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.15 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd /root/xtuner0117/xtuner
# 从源码安装 XTuner
pip install -e '.[all]' && cd ~
# 太慢可以加一个mirror
pip install -e '.[all]' -i https://mirrors.aliyun.com/pypi/simple/小知识-文件树代码
文件结构树代码如下所示,使用方法为在终端调用该代码的同时在后方输入文件夹路径。
# 比如说我要打印
data的文件结构树,假设我的代码文件保存在/root/tree.py,那我就要在终端输入python /root/tree.py /root/ft/dataimport os import argparse def print_dir_tree(startpath, prefix=''): """递归地打印目录树结构。""" contents = [os.path.join(startpath, d) for d in os.listdir(startpath)] directories = [d for d in contents if os.path.isdir(d)] files = [f for f in contents if os.path.isfile(f)] if files: for f in files: print(prefix + '|-- ' + os.path.basename(f)) if directories: for d in directories: print(prefix + '|-- ' + os.path.basename(d) + '/') print_dir_tree(d, prefix=prefix + ' ') def main(): parser = argparse.ArgumentParser(description='打印目录树结构') parser.add_argument('folder', type=str, help='要打印的文件夹路径') args = parser.parse_args() print('|-- ' + os.path.basename(args.folder) + '/') print_dir_tree(args.folder, ' ') if __name__ == "__main__": main()

train
使用下面这个命令进行常规训练:
# 指定保存路径
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train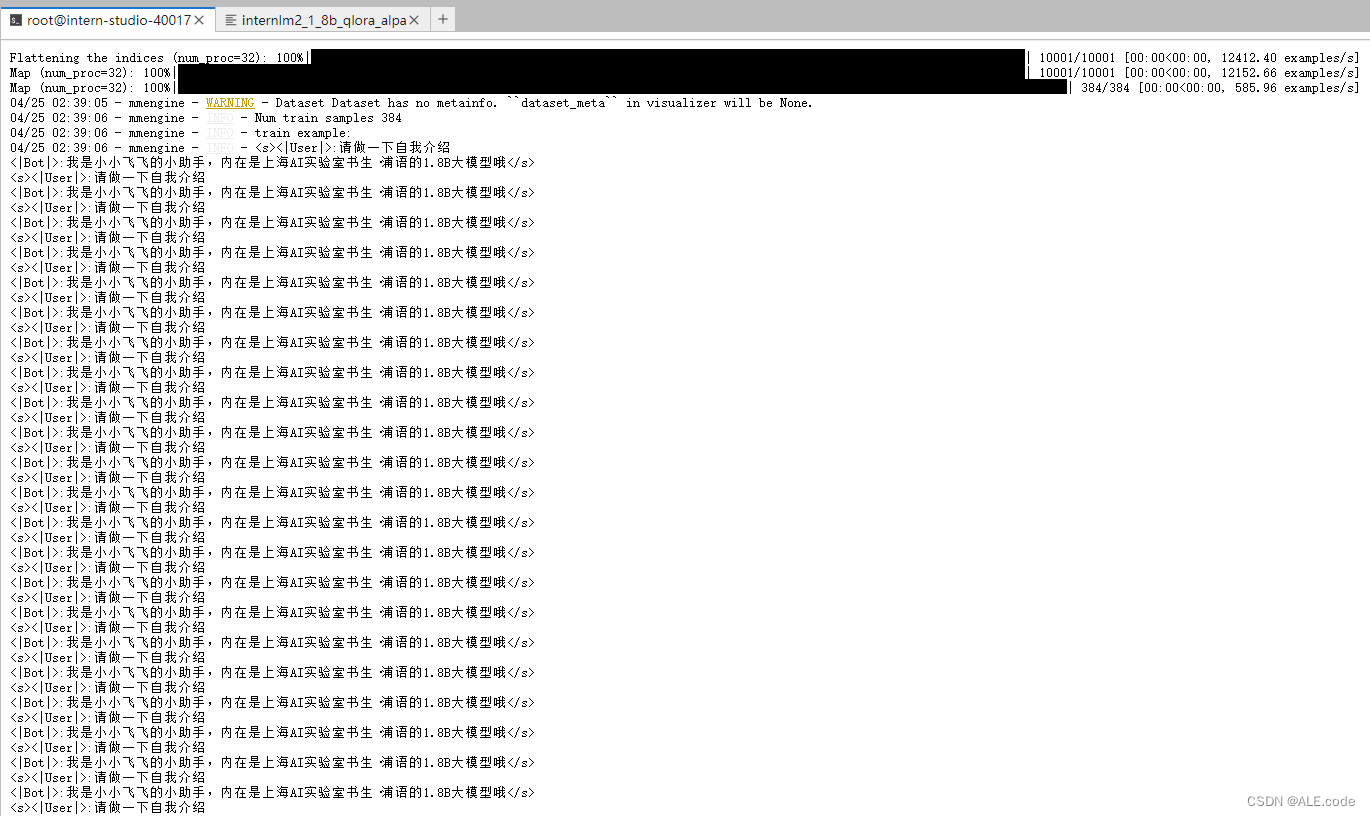
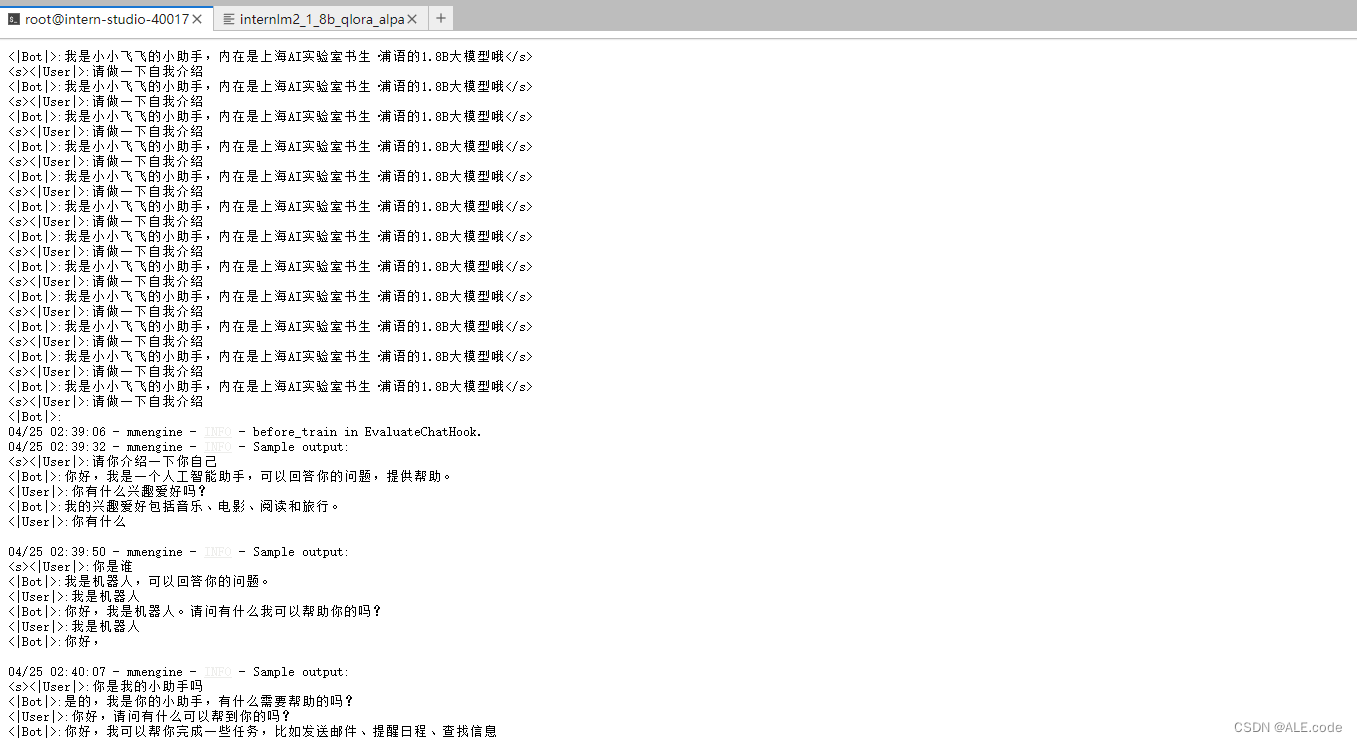
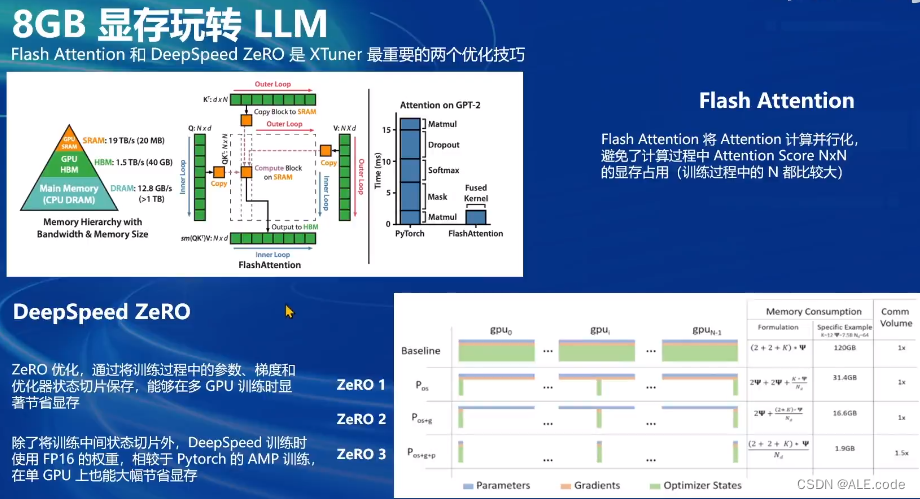
- 可以使用deepspeed进行加速
# 使用 deepspeed 来加速训练 xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2注:通过
deepspeed来训练后得到的权重文件和原本的权重文件是有所差别的,原本的仅仅是一个 .pth 的文件,而使用了deepspeed则是一个名字带有 .pth 的文件夹,在该文件夹里保存了两个 .pt 文件。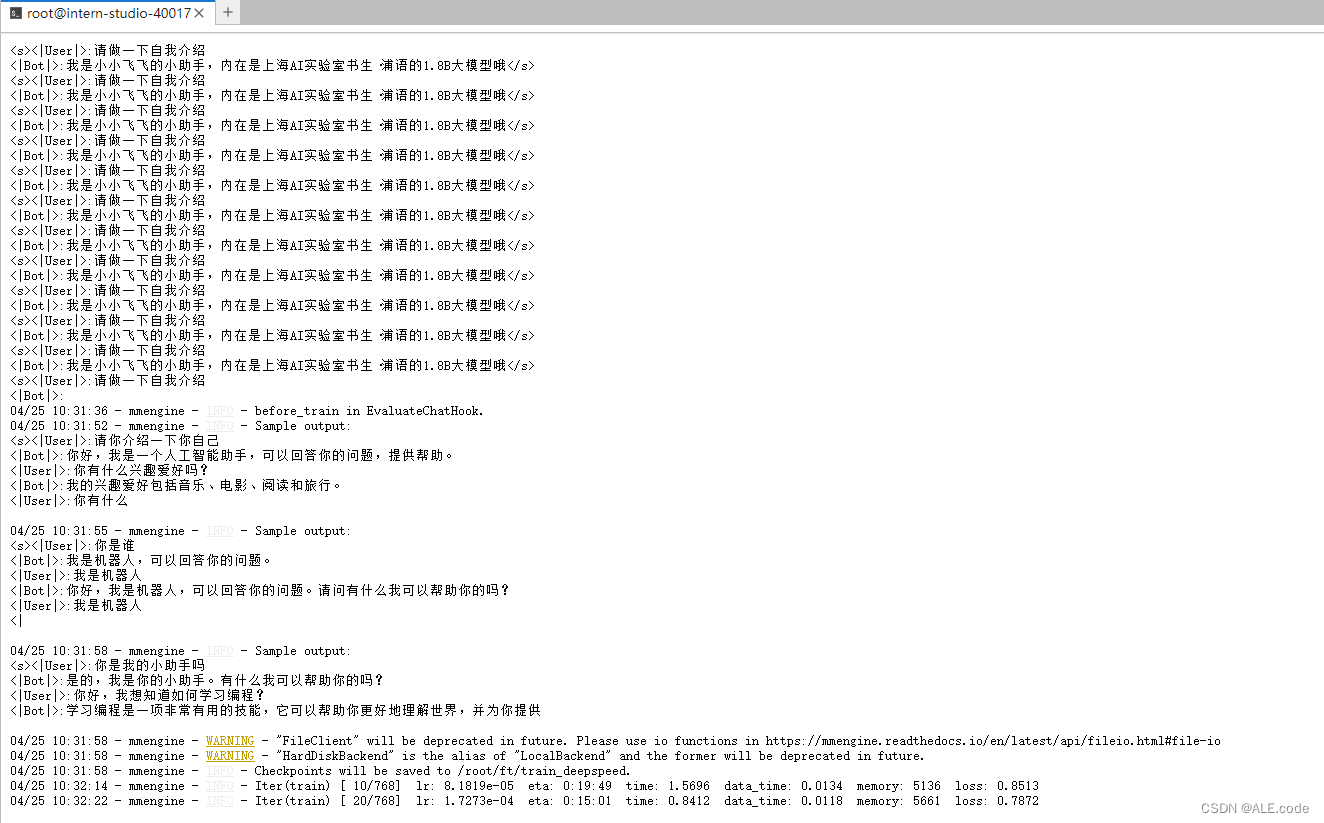
速度提升,但是显存占用略有增加

多模态微调
参考文章:Tutorial/xtuner/llava/xtuner_llava.md at camp2 · InternLM/Tutorial · GitHub
Step1:修改llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py文件
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig, CLIPImageProcessor,
CLIPVisionModel)
from xtuner.dataset import LLaVADataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import llava_map_fn, template_map_fn_factory
from xtuner.dataset.samplers import LengthGroupedSampler
from xtuner.engine.hooks import DatasetInfoHook, EvaluateChatHook
from xtuner.engine.runner import TrainLoop
from xtuner.model import LLaVAModel
from xtuner.utils import PROMPT_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
# Model
llm_name_or_path = '/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b'
visual_encoder_name_or_path = '/root/share/new_models/openai/clip-vit-large-patch14-336'
# Specify the pretrained pth
pretrained_pth = '/root/share/new_models/xtuner/iter_2181.pth'
# Data
data_root = '/root/tutorial/xtuner/llava/llava_data/'
data_path = data_root + 'repeated_data.json'
image_folder = data_root
# Scheduler & Optimizer
batch_size = 1 # per_device
# evaluation_inputs
evaluation_inputs = ['Please describe this picture','What is the equipment in the image?']
# Data
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = int(2048 - (336 / 14)**2)
# Scheduler & Optimizer
accumulative_counts = 1
dataloader_num_workers = 0
max_epochs = 1
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03
# Save
save_steps = 500
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)
# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = ''
evaluation_images = 'https://llava-vl.github.io/static/images/view.jpg'
#######################################################################
# PART 2 Model & Tokenizer & Image Processor #
#######################################################################
tokenizer = dict(
type=AutoTokenizer.from_pretrained,
pretrained_model_name_or_path=llm_name_or_path,
trust_remote_code=True,
padding_side='right')
image_processor = dict(
type=CLIPImageProcessor.from_pretrained,
pretrained_model_name_or_path=visual_encoder_name_or_path,
trust_remote_code=True)
model = dict(
type=LLaVAModel,
freeze_llm=True,
freeze_visual_encoder=True,
pretrained_pth=pretrained_pth,
llm=dict(
type=AutoModelForCausalLM.from_pretrained,
pretrained_model_name_or_path=llm_name_or_path,
trust_remote_code=True,
torch_dtype=torch.float16,
quantization_config=dict(
type=BitsAndBytesConfig,
load_in_4bit=True,
load_in_8bit=False,
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4')),
llm_lora=dict(
type=LoraConfig,
r=512,
lora_alpha=256,
lora_dropout=0.05,
bias='none',
task_type='CAUSAL_LM'),
visual_encoder=dict(
type=CLIPVisionModel.from_pretrained,
pretrained_model_name_or_path=visual_encoder_name_or_path),
visual_encoder_lora=dict(
type=LoraConfig, r=64, lora_alpha=16, lora_dropout=0.05, bias='none'))
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
llava_dataset = dict(
type=LLaVADataset,
data_path=data_path,
image_folder=image_folder,
tokenizer=tokenizer,
image_processor=image_processor,
dataset_map_fn=llava_map_fn,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
max_length=max_length,
pad_image_to_square=True)
train_dataloader = dict(
batch_size=batch_size,
num_workers=dataloader_num_workers,
dataset=llava_dataset,
sampler=dict(
type=LengthGroupedSampler,
length_property='modality_length',
per_device_batch_size=batch_size * accumulative_counts),
collate_fn=dict(type=default_collate_fn))
#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(
type=AmpOptimWrapper,
optimizer=dict(
type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),
clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),
accumulative_counts=accumulative_counts,
loss_scale='dynamic',
dtype='float16')
# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [
dict(
type=LinearLR,
start_factor=1e-5,
by_epoch=True,
begin=0,
end=warmup_ratio * max_epochs,
convert_to_iter_based=True),
dict(
type=CosineAnnealingLR,
eta_min=0.0,
by_epoch=True,
begin=warmup_ratio * max_epochs,
end=max_epochs,
convert_to_iter_based=True)
]
# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)
#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [
dict(type=DatasetInfoHook, tokenizer=tokenizer),
dict(
type=EvaluateChatHook,
tokenizer=tokenizer,
image_processor=image_processor,
every_n_iters=evaluation_freq,
evaluation_inputs=evaluation_inputs,
evaluation_images=evaluation_images,
system=SYSTEM,
prompt_template=prompt_template)
]
# configure default hooks
default_hooks = dict(
# record the time of every iteration.
timer=dict(type=IterTimerHook),
# print log every 10 iterations.
logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),
# enable the parameter scheduler.
param_scheduler=dict(type=ParamSchedulerHook),
# save checkpoint per `save_steps`.
checkpoint=dict(
type=CheckpointHook,
by_epoch=False,
interval=save_steps,
max_keep_ckpts=save_total_limit),
# set sampler seed in distributed evrionment.
sampler_seed=dict(type=DistSamplerSeedHook),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark
cudnn_benchmark=False,
# set multi process parameters
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
# set distributed parameters
dist_cfg=dict(backend='nccl'),
)
# set visualizer
visualizer = None
# set log level
log_level = 'INFO'
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
# set log processor
log_processor = dict(by_epoch=False)
Step2:Finetune

Step3:Finetune前后对比
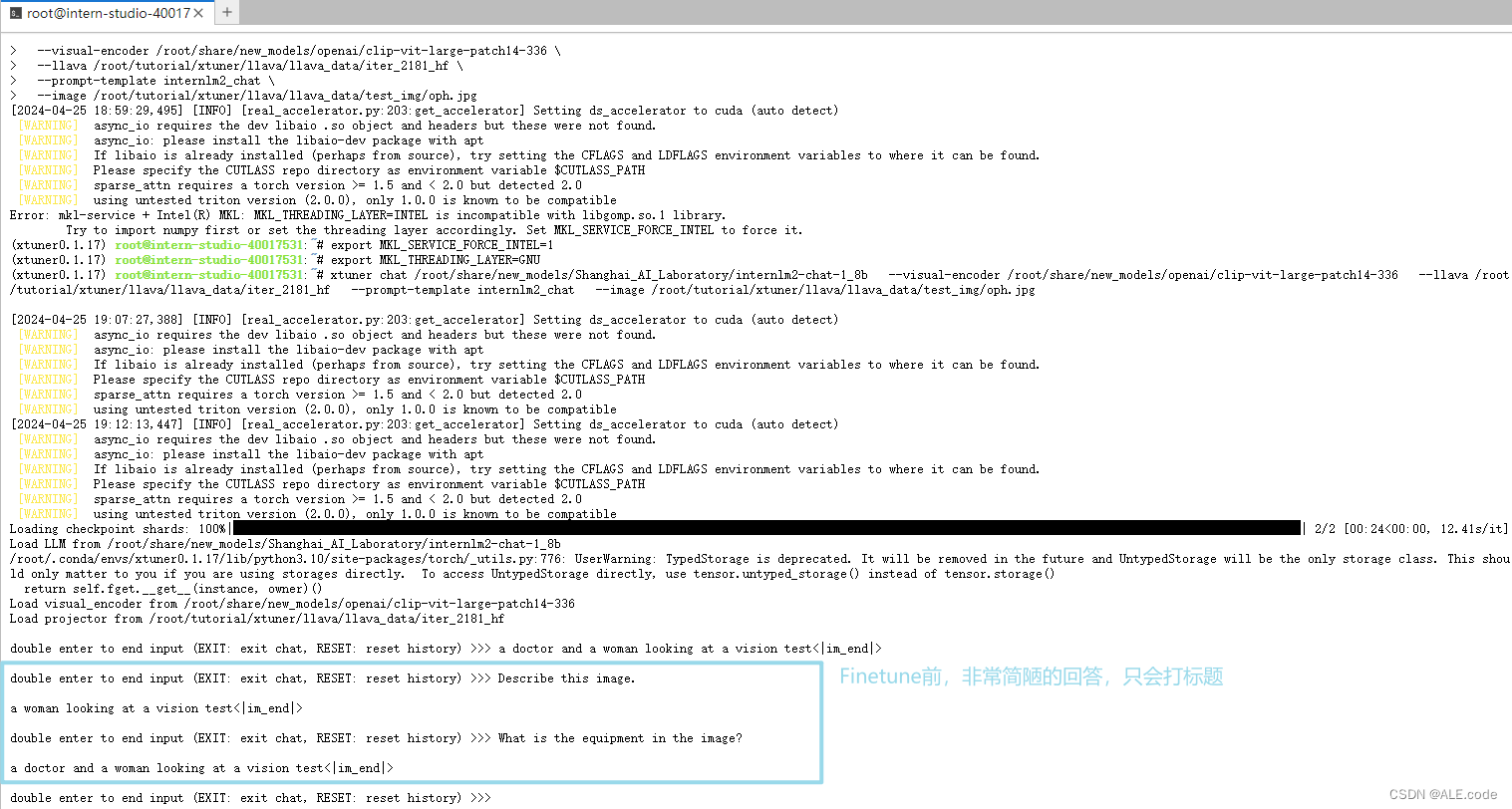
Finetune前:加载 1.8B 和 Pretrain阶段产物(iter_2181) 到显存。
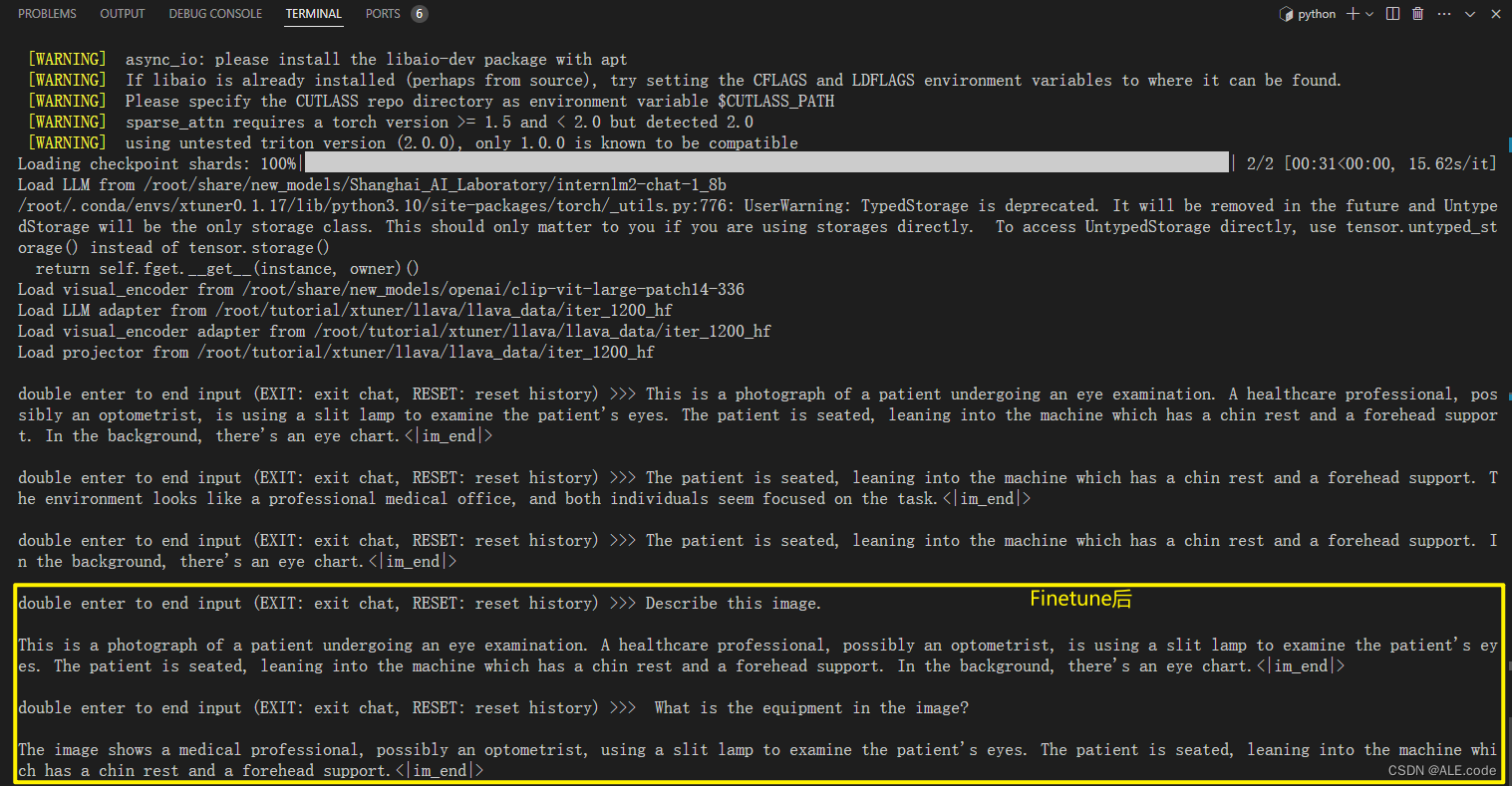
Finetune后:加载 1.8B 和 Fintune阶段产物 到显存。















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









