






一、Finetune
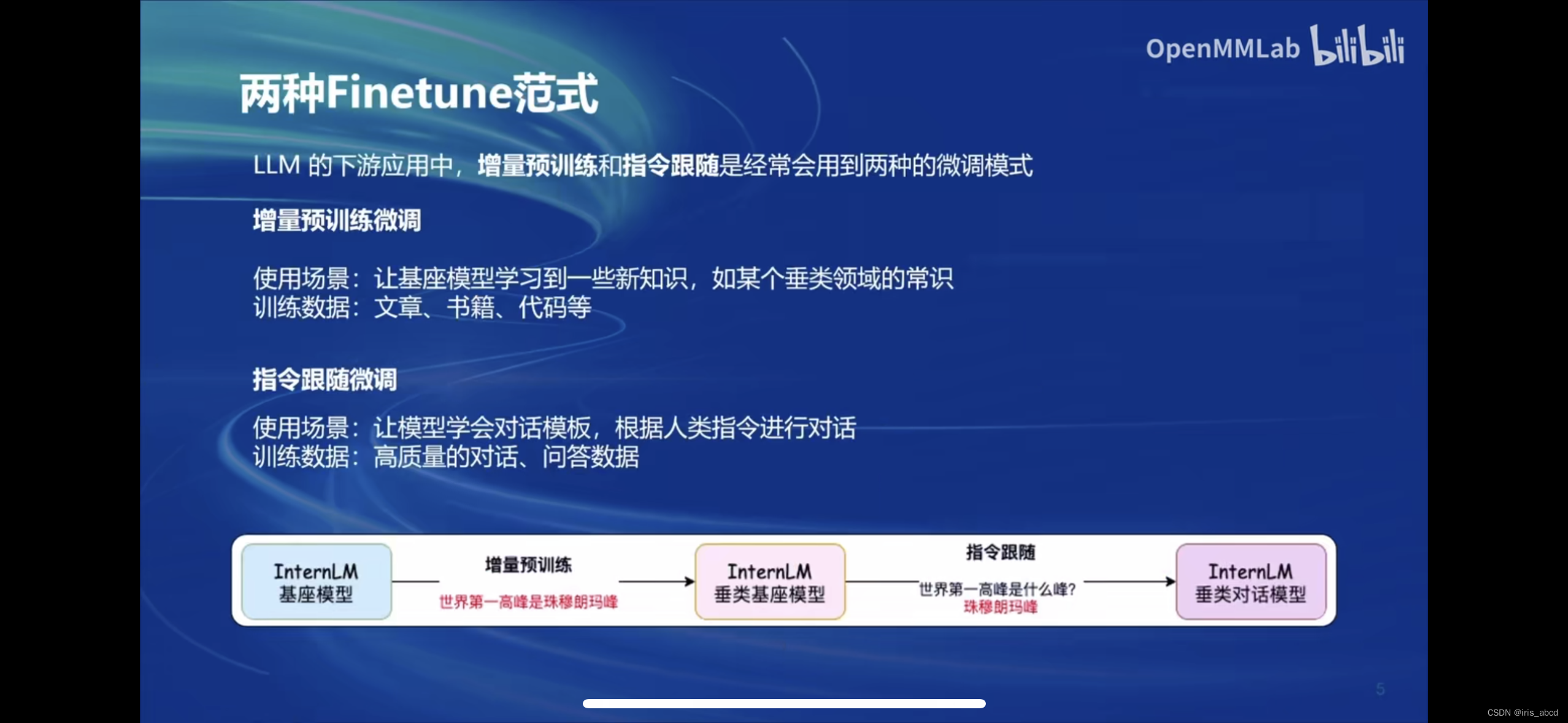
Finetune分为两种范式:增量预训练和指令跟随是经常会用到两种的微调模式
增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识训练数据:文章、书籍、代码等
指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话训练数据:高质量的对话、问答数据

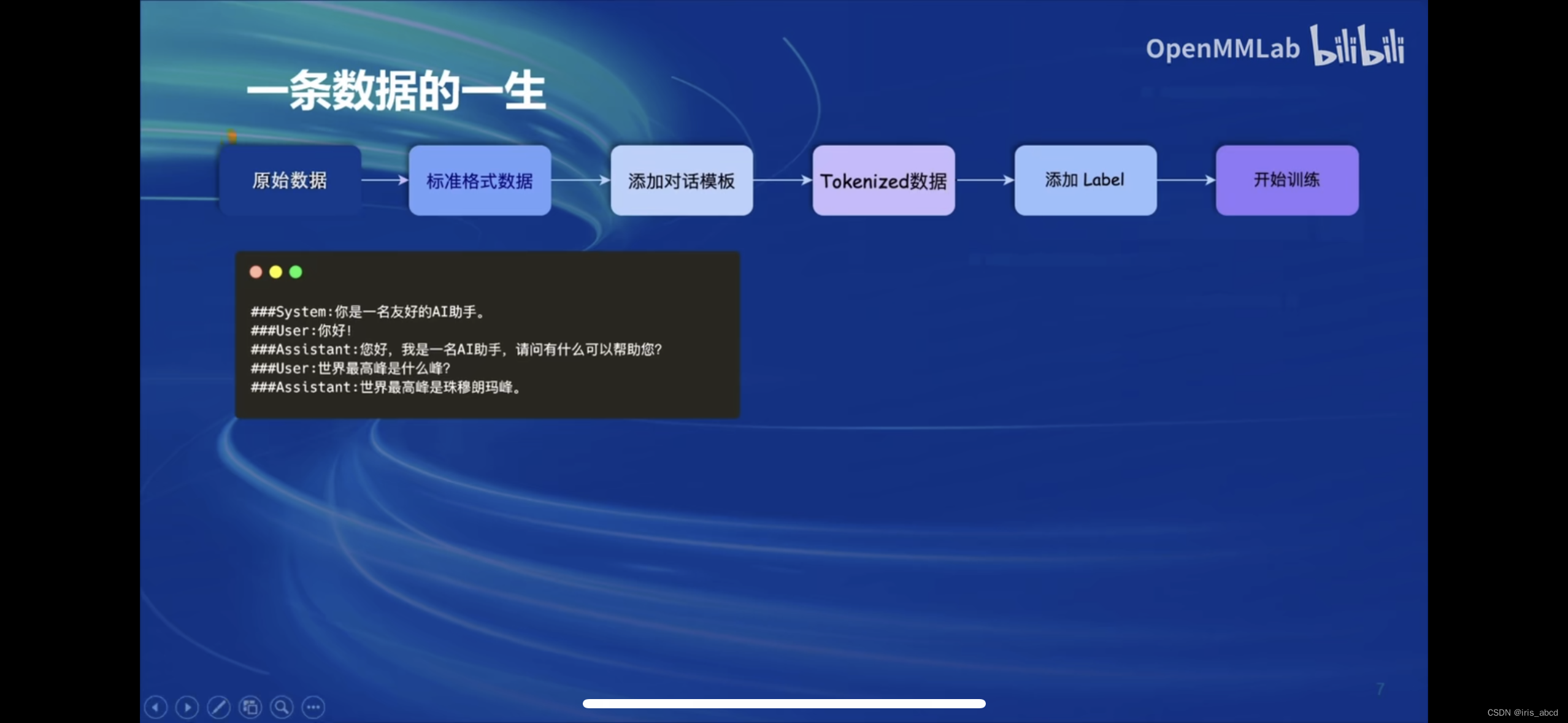
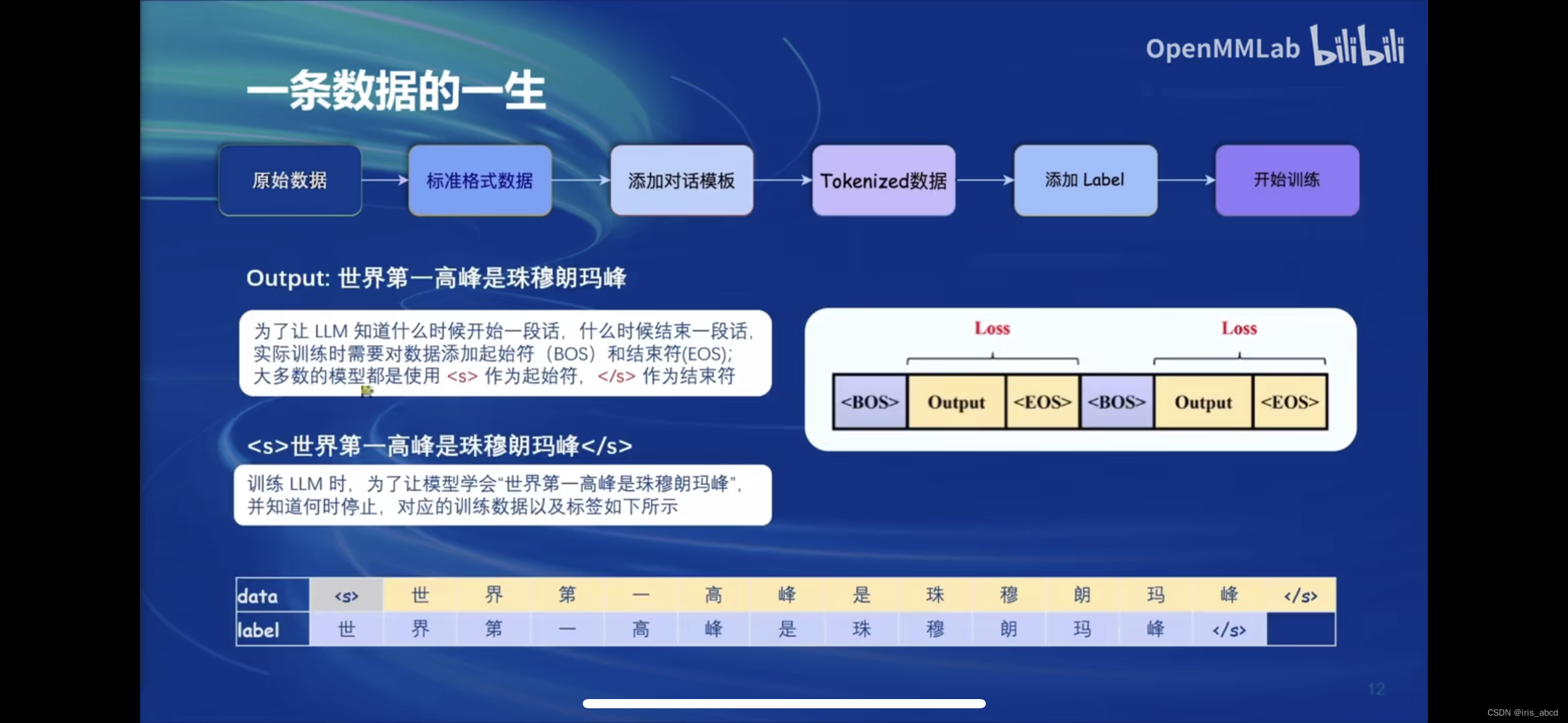
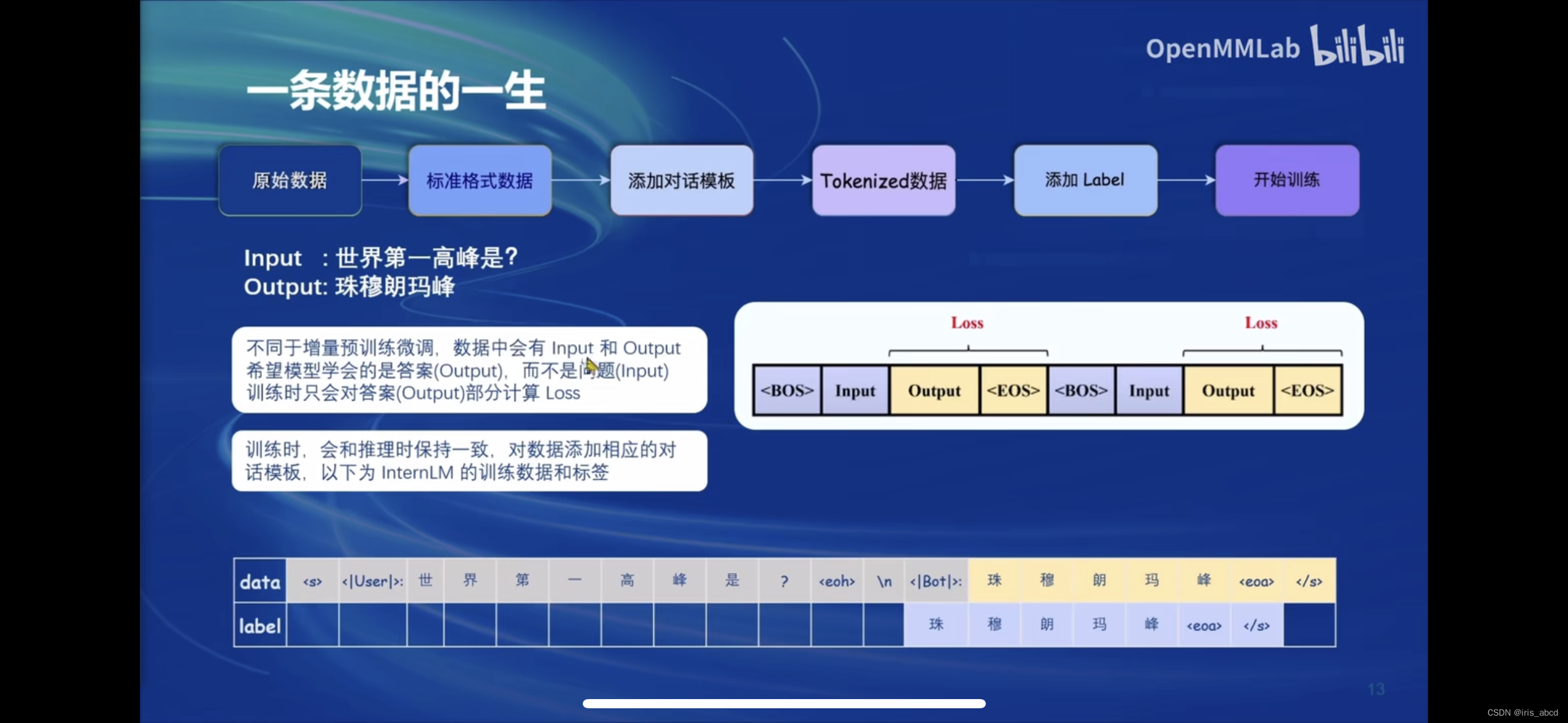
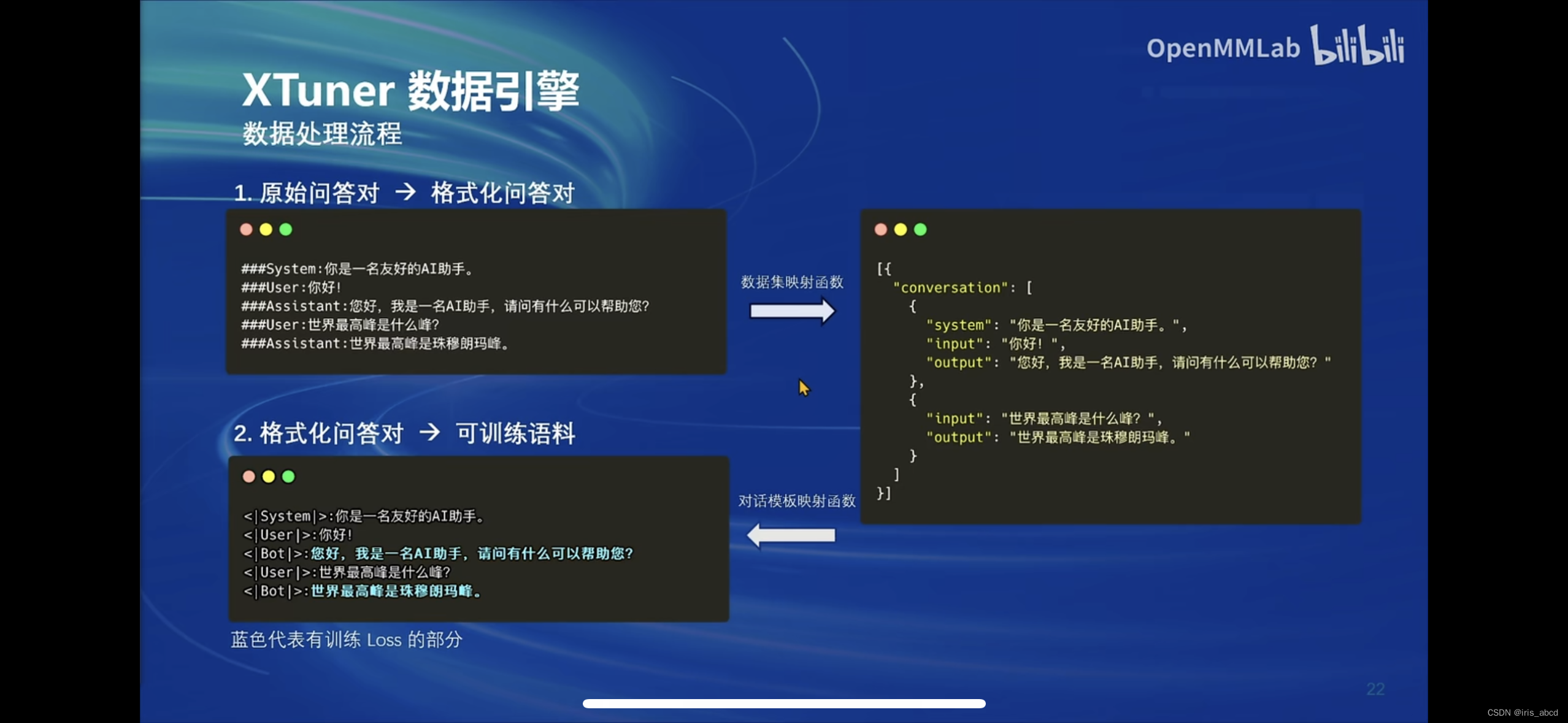
原始数据需经过标准化、添加对话模板、tokensize数据、添加Label之后用于训练。
原始数据实例:
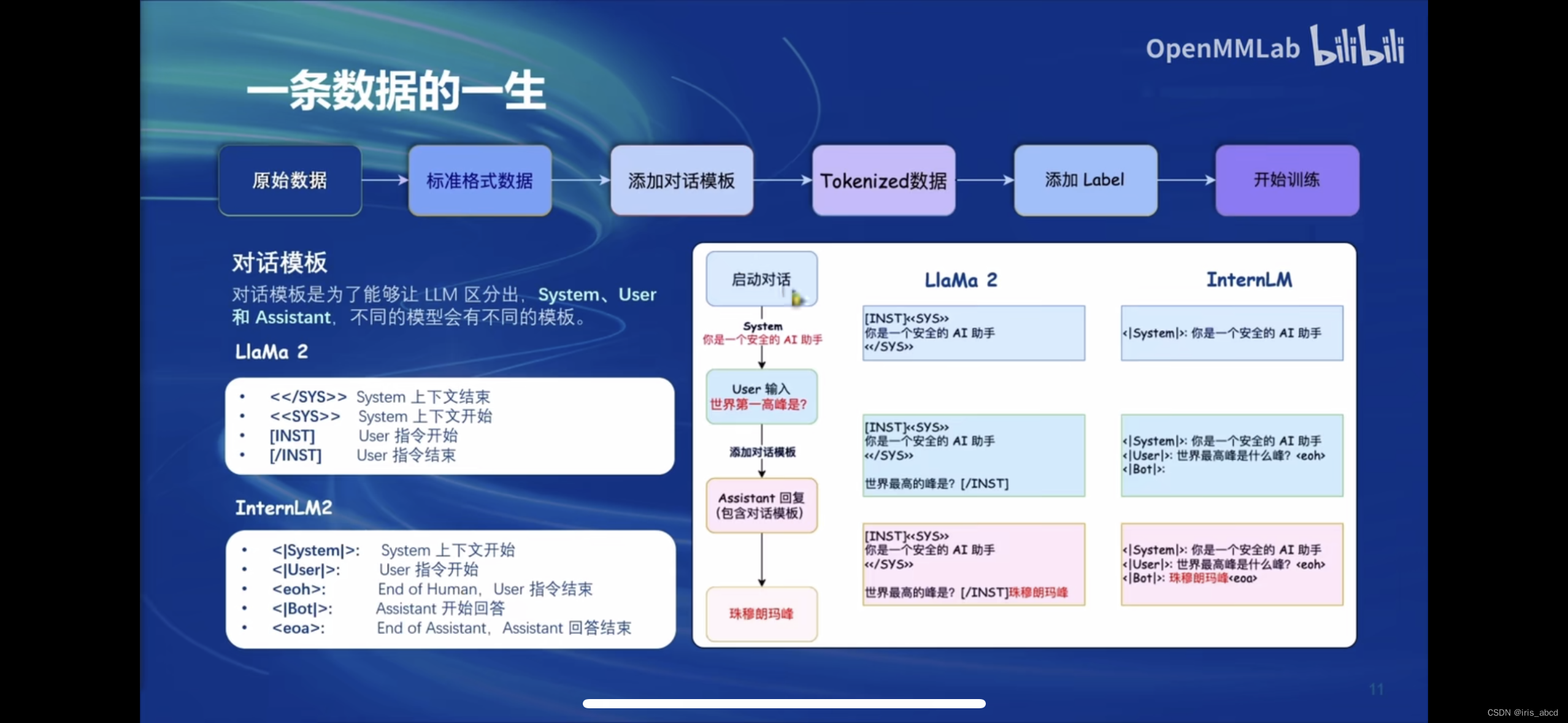
对话模板
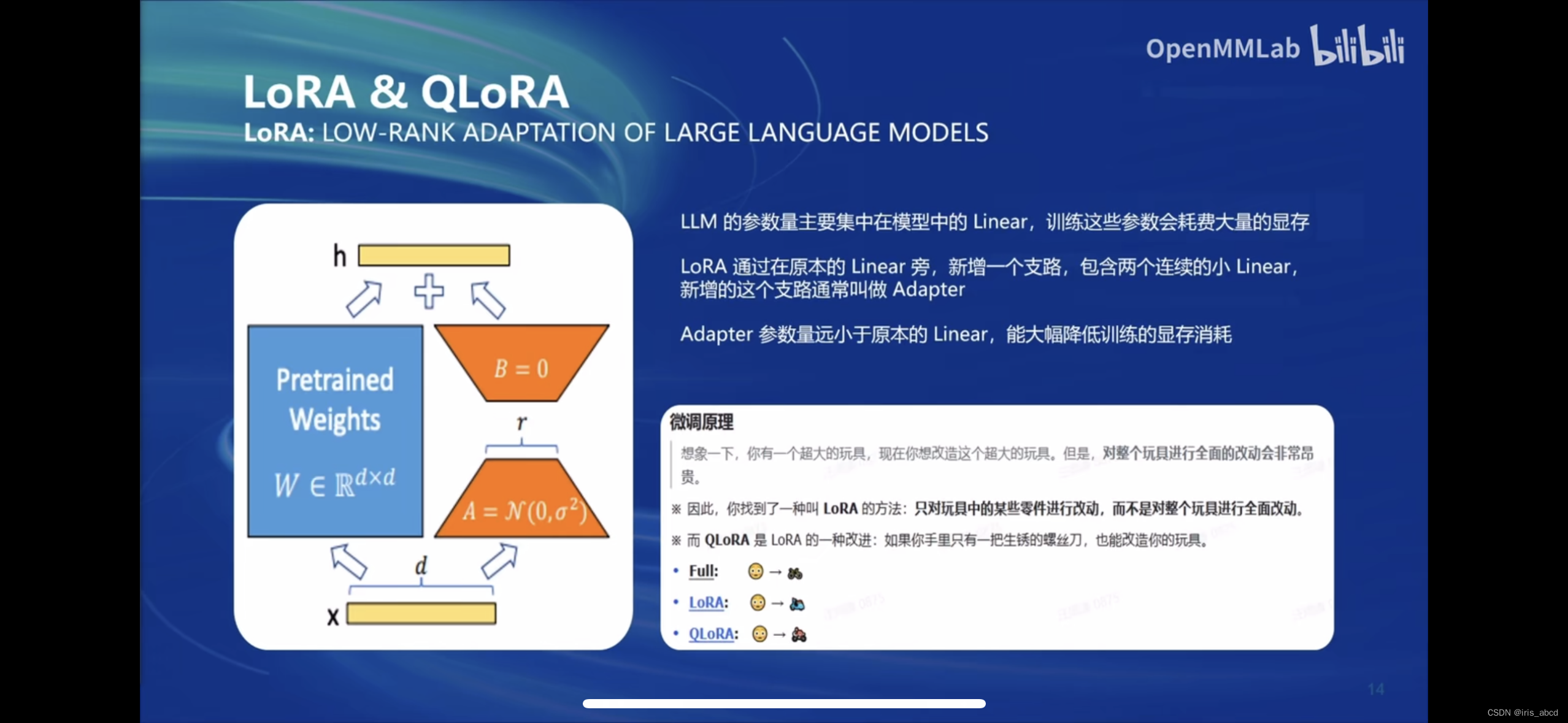
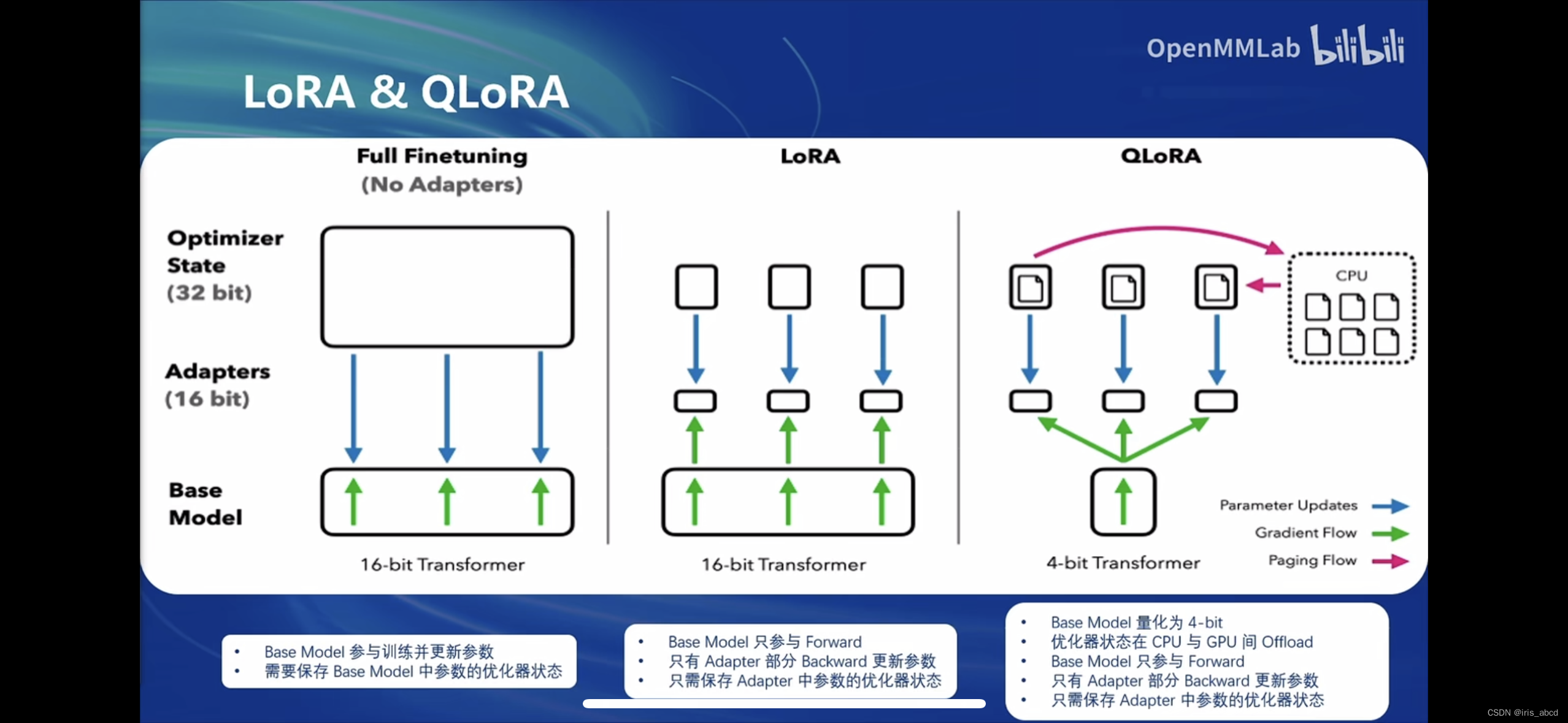
Lora&QLoRA介绍及对比
二、XTuner
XTuner是一个由MMRazor和MMDeploy联合开发的大语言模型微调工具箱。它主要针对需要对LLM(大型语言模型)进行定制化调整的研究者和开发者,特别是那些没有深厚技术背景但希望利用LLM进行特定任务的用户。其设计目标是使微调过程尽可能简单,即使是0基础的非专业人员也能一键开始微调。它封装了大部分微调场景,用户只需进行简单的配置即可开始微调过程,无需深入了解模型的内部机制。
XTuner支持多种开源的大型语言模型,包括但不限于InternLM、Llama系列、ChatGLM系列、Qwen以及Zephyr等。用户可以在一个统一的平台上对这些模型进行微调,极大地提高了微调工作的效率和便捷性。


三、InterLM2 1.8B 模型

InternLM2-1.8B 提供了三个版本的开源模型,使用时按需选择。InternLM2-1.8B:具有高质量和高适应灵活性的基础模型,为下游深度适应提供了良好的起点。InternLM2-Chat-1.88-SFT:在InternLM2-1.88 上进行监督微调(SFT)后得到的对话模型。InternLM2-Chat-1.88:通过在线 RLHF 在 InternLM2-Chat-1.8B-SFT 之上进一步对齐。InternLM2-Chat-1.88 表现出更好的指令跟随、聊天体验和函数调用,推荐下游应用程序使用。(模型大小仅为3.78GB)
在 FP16 精度模式下,InternLM2-1.8B 仅需 4GB 显存的第记本显卡即可顺畅运行拥有 8GB 显存的消费级显卡,即可轻松进行1.88 模型的微调工作。
四、多模态LLM


















 1665
1665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









