






1 最近刚好在做矢量预测,刚好看了这个帖子AE自编码发现这个帖子写的不全面,有个贴友进行了question,因此顺带把这个AE代码进行解析和复现
import tensorflow as tf
import tensorflow.keras.datasets.mnist as minst
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
tf.test.is_gpu_available()
(train_image, train_label_or), (test_image, test_label_or) = minst.load_data()
#对手写数字的标签进行one_hat编码
train_label = np.eye(10)[train_label_or] #将数据转换为 one_hot编码
train_image = tf.cast(train_image,tf.float32) #将数据转换为想要的格式
#将数据进行归一化操作
train_image = train_image/255.0
images_count = train_image.shape[0]
#(60000, 28, 28) ----> (60000, 28, 28, 1)
train_image = np.expand_dims(train_image, -1) #对数据进行维度的扩充
test_image = np.expand_dims(test_image, -1)
BATCH_SIZE = 100
ts_train_images = tf.data.Dataset.from_tensor_slices(train_image) #数据沿着第一个维度进行切分
ts_train_labels = tf.data.Dataset.from_tensor_slices(train_label)
ts_train_set = tf.data.Dataset.zip((ts_train_images,ts_train_labels))#将图片和标签装在一起
train_dataset = ts_train_set.shuffle(images_count).batch(BATCH_SIZE) #将数据进行打乱,顺带进行batch
#网络的搭建
def encoder():
encoder_input = layers.Input(shape = (28,28,1))
x = layers.Flatten()(encoder_input)
x = layers.Dense(1024)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x)
x = layers.Dense(512)(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU()(x) #Leaky ReLU是一种修正线性单元,它在非负数部分保持线性,而在负数部分引入一个小的斜率(通常是一个小的正数),以防止梯度消失问题
encoder_output = layers.Dense(10)(x)
encoder_model = Model(inputs = encoder_input,outputs = encoder_output)
print(encoder_model.summary())
return encoder_model
Encoder = encoder()
def decoder():
decoder_input = layers.Input(shape = (10,))
decoder_input1 = layers.Dense(7*7*32)(decoder_input)
decoder_input2 = layers.Activation("relu")(decoder_input1)
decoder_input3 = layers.Reshape(target_shape=(7, 7, 32))(decoder_input2)
y = layers.Conv2DTranspose(filters=64,kernel_size=3,strides=(2, 2),padding="SAME",activation='relu')(decoder_input3)
# filters=64,
# kernel_size=3,
# strides=(2, 2),
# padding="SAME",
# )
y = layers.Dropout(rate = 0.7)(y)
y = layers.Conv2DTranspose(filters=32,kernel_size=3,strides=(2, 2),padding="SAME",activation='relu')(y)
# filters=32,
# kernel_size=3,
# strides=(2, 2),
# padding="SAME",
# )
y = layers.Dropout(rate = 0.7)(y)
y = layers.Conv2DTranspose(filters=1, kernel_size=3, strides=(1, 1), padding="SAME", activation='sigmoid')(y)
# filters=1, kernel_size=3, strides=(1, 1), padding="SAME")(y)
y = layers.BatchNormalization()(y) #重新规范化,即使得其输出数据的均值接近0,其标准差接近1
decoder_output = layers.Activation("sigmoid")(y)
decoder_model = Model(inputs = decoder_input,outputs = decoder_output)
print(decoder_model.summary())
return decoder_model
Decoder = decoder()
EPOCHS = 100
optimizer = tf.keras.optimizers.Adam(1e-4)
def train_epoch(image_batch,label_batch): #image_batch就是带有batch的输入照片,label_batch就是带有batch的标签
with tf.GradientTape() as encoder_tap,tf.GradientTape() as decoder_tap: #计算梯度
img_fea = Encoder(image_batch,training=True) #压缩
res_img = Decoder(img_fea,training=True) #还原
sub_per = res_img - image_batch #还原照片和输入照片之间的差值
restructure_loss = tf.reduce_mean(tf.norm(tf.reshape(sub_per,shape=(sub_per.shape[0],-1)),2,axis=1)) #计算沿着第二维度的二范数的平均值
encoder_gard = encoder_tap.gradient(restructure_loss,Encoder.trainable_variables) #计算restructure_loss对Encoder网络的梯度
decoder_grad = decoder_tap.gradient(restructure_loss,Decoder.trainable_variables)
optimizer.apply_gradients(zip(encoder_gard,Encoder.trainable_variables)) #这里就是更新encoder_gard梯度和Encoder网络的权重
optimizer.apply_gradients(zip(decoder_grad,Decoder.trainable_variables)) #这里就是更新decoder_gard梯度和decoder网络的权重
return restructure_loss.numpy()
def main():
for epoch in range(1,EPOCHS):
last_loss=0
for train_x,train_y in train_dataset:
last_loss=train_epoch(train_x,train_y)
if epoch %2 == 0:
print('Epoch {}, loss {}'.format(epoch,last_loss))
if __name__ == "__main__":
main()
顺带把一些笔记也分享一下,其实万变不离其中,把这些基础原理搞懂就是后面去调节参数,这个代码其实还没有把generator放进train的mian producer里面,后续感兴趣可以自行修改,然后也不要纠结last_loss很大,这里大家可以在循环里面自行除以对应的BATCH的数值
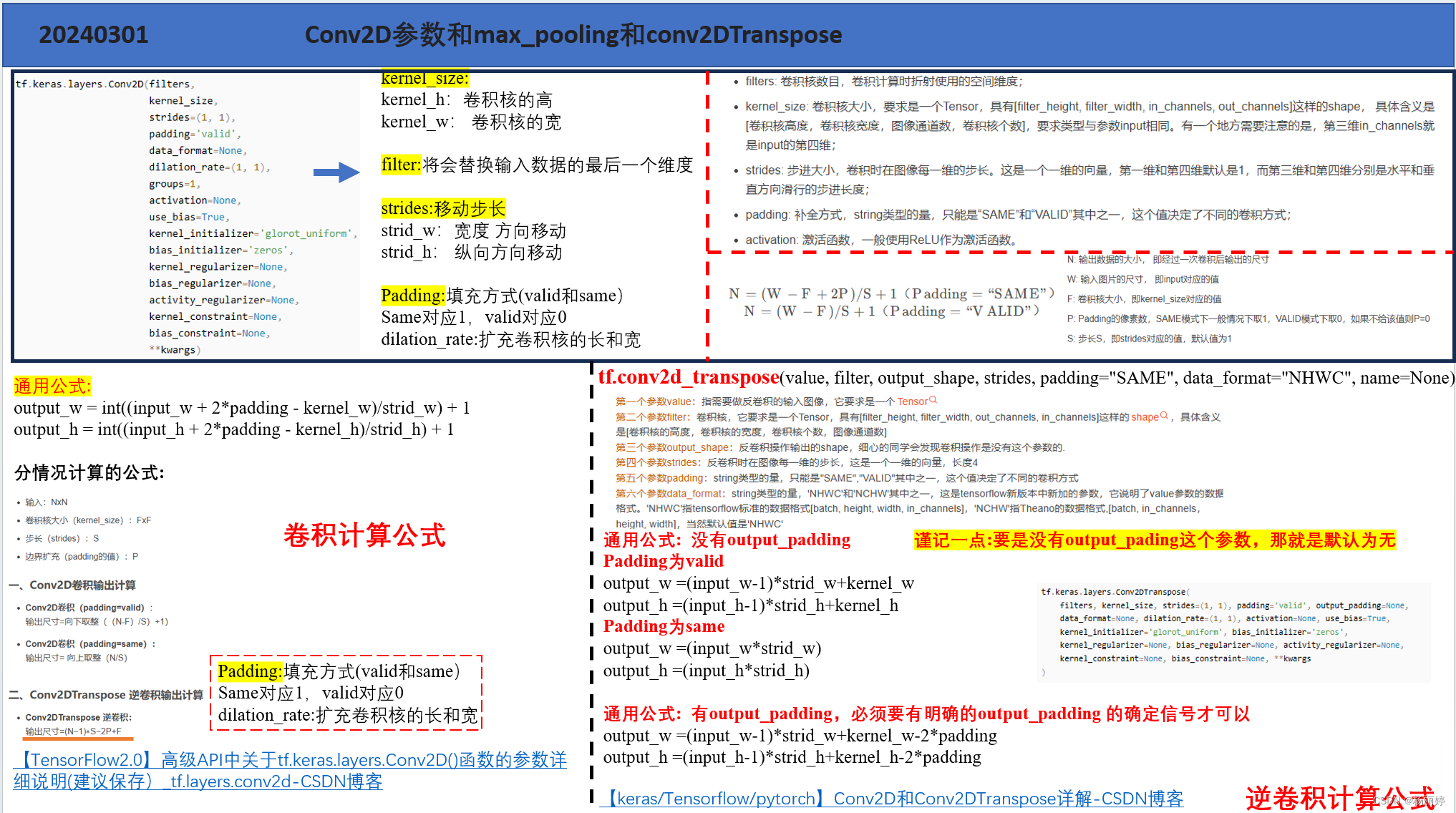


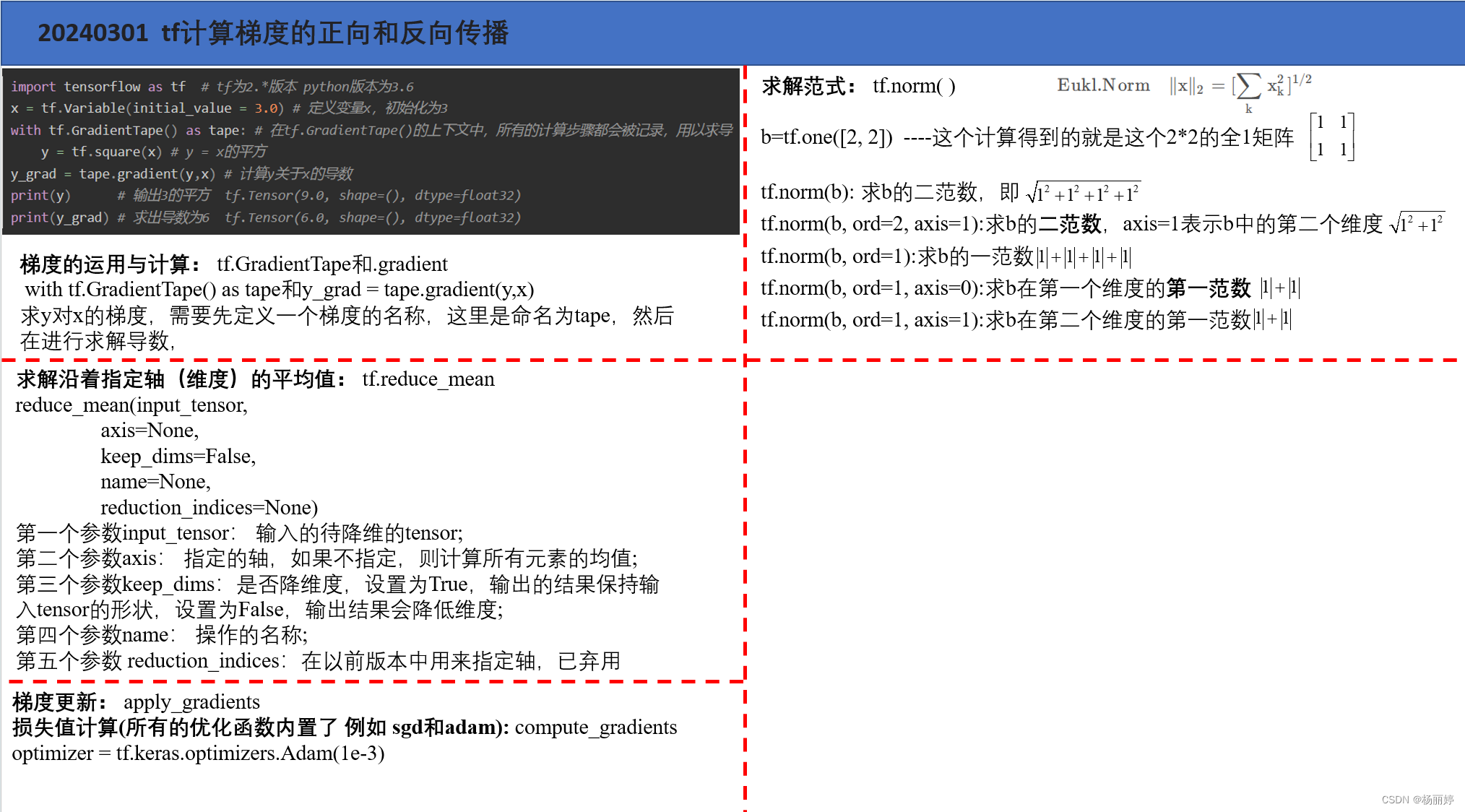
小编的笔记字体比较丑,大家将就看一下,一直想去整理,之前都是直接用,最近想着进行系统性的summary,相信大家一般也都是用到哪百度到哪里,正好最近想做一个东西,把这些整理全面。
希望获得友友们友情一赞!!















 4303
4303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









