






1.张量神经网络模型
张量神经网络模型(neural tensor network,NTN)的基本思想是,用双线性张量取代传统神经网络中的线性变换层,在不同的维度下将头、尾实体向量联系起来。
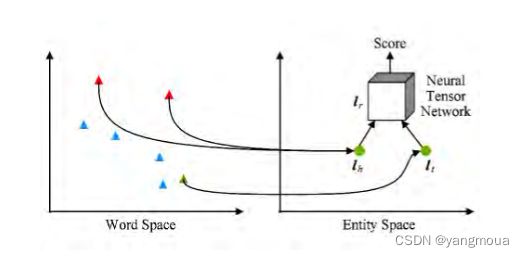
NTN为每个三元组(h,r,t)定义了如下评分函数,评价2个实体之间存在某个特定关系r的可能性:
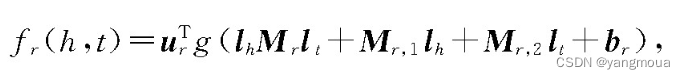
其中urT是一个与关系相关的线性层,g()是tanh函数,Mr∈Rd×d×k是一个三阶张量,Mr,1,Mr,2∈Rd×k是与关系r有关的投影矩阵。
NTN中的实体向量是该实体中所有单词向量的平均值,好处是,实体中的单词数量远小于实体数量,可以充分重复利用单词向量构建实体表示,降低实体表示学习的稀疏性问题,增强不同实体的语义联系。
虽然NTN引入了张量操作,能更精确地刻画实体和关系的复杂语义联系。但计算复杂度非常高,需要大量三元组样例才能得到充分学习。
2.矩阵分解模型
矩阵分解是得到低维向量表示的重要途径,代表方法是RESACL模型。
在该模型中,知识库三元组构成一个大的张量X,如果三元组(h,r,t)存在,则Xhrt=1,否则为0。张量分解旨在将每个三元组(h,r,t)对应的张量值Xhrt分解为实体和关系表示,使得Xhrt尽量地接近于lhMrlt。
它的思想和前面看到的LFM类似,不同的是RESACL会优化张量中的所有位置,包括值为0的位置,而LFM只会优化知识库中存在的三元组。
3.翻译模型Trans
通过word2vec词表示学习模型和工具包,受到启发,发现词向量空间存在有趣的平移不变现象。通过类比实验(C(king)-C(queen)≈C(man)-C(woman)),发现这种平移不变现象普遍存在于词汇的语义关系和句法关系中。
受此启发,提出了TransE模型。将知识库中的关系看作实体间的某种平移向量.对于每个三元组(h,r,t),TransE用关系r的向量lr作为头实体向量lh和尾实体向量lt之间的平移。也可以将lr看作从lh到lt的翻译,因此TransE也被称为翻译模型。
4.其他模型
在TransE提出之后,大部分知识表示学习模型是以TransE为基础的扩展。在TransE扩展模型以外,还有很多,例如全息表示模型(holographic embeddings,Hole)。
Hole提出使用头、尾实体向量的“循环相关”操作来表示该实体对。循环相关操作可以看作张量乘法特殊形式,具有较强的表达能力。优点如下:1)不可交换性.循环相关是不可交换的,即lh*lt≠lt*lh.而知识库中很多关系是不可交换的,因此该特点具有重要意义。2)相关性.循环相关操作得到的向量每一维都衡量了向量lh和lt的某种相似性。















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









