






知识表示学习的代表模型:
1.距离模型
结构表示(structured embedding,SE),每个实体用d维的向量表示,所有实体被投影到同一个d维向量空间中。SE还为每个关系r定义了2个矩阵Mr,1,Mr,2∈Rd×d,用于三元组中头实体和尾实体的投影操作。最后,SE为每个三元组(h,r,t)定义了如下损失函数:
SE将头实体向量lh和尾实体向量lt通过关系r的2个矩阵投影到r的对应空间中,然后在该空间中计算两投影向量的距离。这个距离反映了2个实体在关系r下的语义相关度,它们的距离越小,说明这2个实体存在这种关系。
实体向量和关系矩阵是SE模型的参数。SE将知识库三元组作为学习样例,优化模型参数使知识库三元组的损失函数值不断降低,从而使实体向量和关系矩阵能够较好地反映实体和关系的语义信息。SE能够利用学习得到的知识表示进行链接预测,即通过计算:
SE模型缺陷:对头、尾实体使用2个不同的矩阵进行投影,协同性较差,往往无法精确刻画两实体与关系之间的语义联系。
2.单层神经网络模型
单层神经网络模型(single layer model,SLM)尝试采用单层神经网络的非线性操作,来减轻SE无法协同精确刻画实体与关系的语义联系的问题。SLM为每个三元组(h,r,t)定义了如下评分函数:
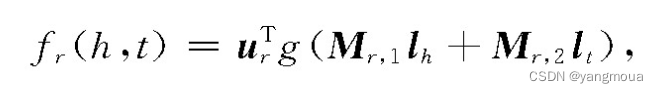
其中,Mr,1,Mr,2∈Rd×k为投影矩阵,urT∈Rk为关系r的表示向量,g()是tanh函数。
缺陷:非线性操作仅提供了实体和关系之间比较微弱的联系。同时,却引入了更高的计算复杂度。
3.能量模型
语义匹配能量模型(semantic matching energy,SME)提出更复杂的操作,寻找实体和关系之间的语义联系。在SME中,每个实体和关系都用低维向量表示。在此基础上,定义若干投影矩阵,刻画实体与关系的内在联系。即SME为每个三元组(h,r,t)定义了2种评分函数:
线性形式:fr(h,t)=(M1lh+M2lr+b1)T(M3lt+M4lr+b2)
双线性形式:fr(h,t)=(M1lh*M2lr+b1)T(M3lt*M4lr+b2)
其中M1,M2,M3,M4∈Rd×k为投影矩阵;*表示按位相乘(即Hadamard积),b1,b2为偏置向量。
4.双线性模型
隐变量模型(latent factor model,LFM)提出利用基于关系的双线性变换,刻画实体和关系之间的二阶联系。通过简单有效的方法刻画了实体和关系的语义联系,协同性较好,计算复杂度低。LFM为每个三元组(h,r,t)定义了如下双线性评分函数:

Mr∈Rd×d是关系r对应的双线性变换矩阵















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









