








一、引言
在任何后台系统设计中,「读多写少」的业务场景占据主流:浏览商品、刷资讯、访问用户画像……相比写操作,读操作的并发压力更大、对性能的要求也更苛刻。为此,我们需要从 读服务(或称读接口/读业务)的角度,系统地探讨如何在高可用、高性能和超高 QPS(上万~百万峰值)的场景下构建稳健的架构。
接下来我们将围绕读服务的功能特点、两大基本设计原则,以及行业中常见的懒加载架构及其四大挑战,快速掌握实战思路。
二、读服务的功能性需求
读服务在执行流程上,基本是 无状态、无副作用 的:
- 从持久层(数据库、Redis、Elasticsearch 等)获取原始数据;
- 简单加工或直接返回给前端。
因此,读服务必须满足三大指标:
- 高可用:任何业务都需保证持续在线;
- 高性能:TP999 必须控制在 100ms 以内;
- 超高 QPS 支撑:满足上万至百万级峰值请求。
只有确保这三点,才能给用户带来流畅的体验,避免卡顿或秒级延迟。
三、两大基本设计原则
1. 架构尽量不要分层
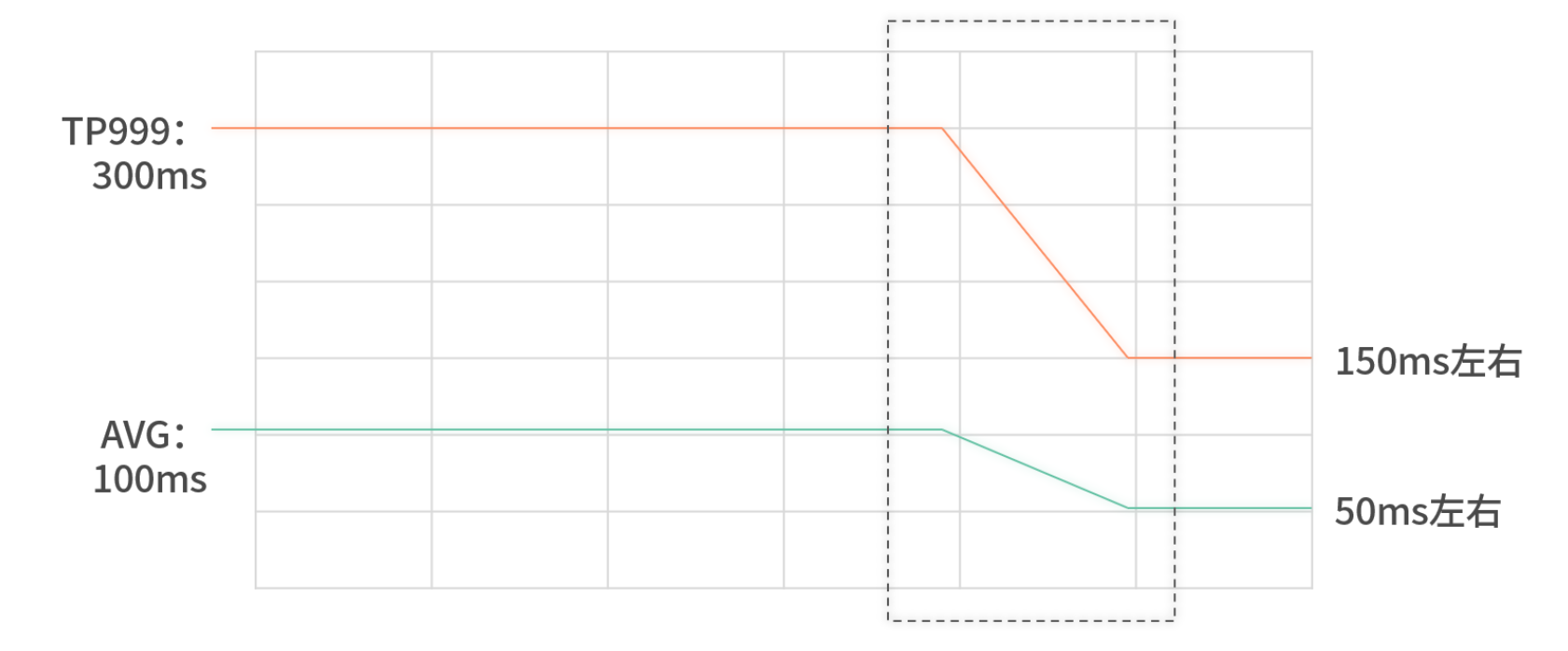
传统分层(服务层→数据访问层→存储)虽然能降低代码耦合,但网络调用(RPC/HTTP)往返会成倍消耗延迟。监控数据显示,分层架构下读请求的 TP99、TP999 指标往往翻倍,且毛刺明显增多。
优化思路:将数据访问层编译进同一进程,去除网络传输环节。
内嵌后,TP999 可下降近 50%,平均延迟降低 20%~30%,部署成本也大幅下降。
2. 代码尽可能简单
读服务链路虽然清晰,但模型层次多、映射开销大。引入过多框架、全量日志打印、全量字段查询都会拖慢性能。
- 慎用反射/Codegen 框架:如 Spring Bean.copyProperties,反射性能开销高。
- 精细化日志:只打印关键信息,避免 JSON 序列化全量对象。
- 按需字段查询:MySQL 避免
SELECT *,Redis 使用 Hash 并定位字段。
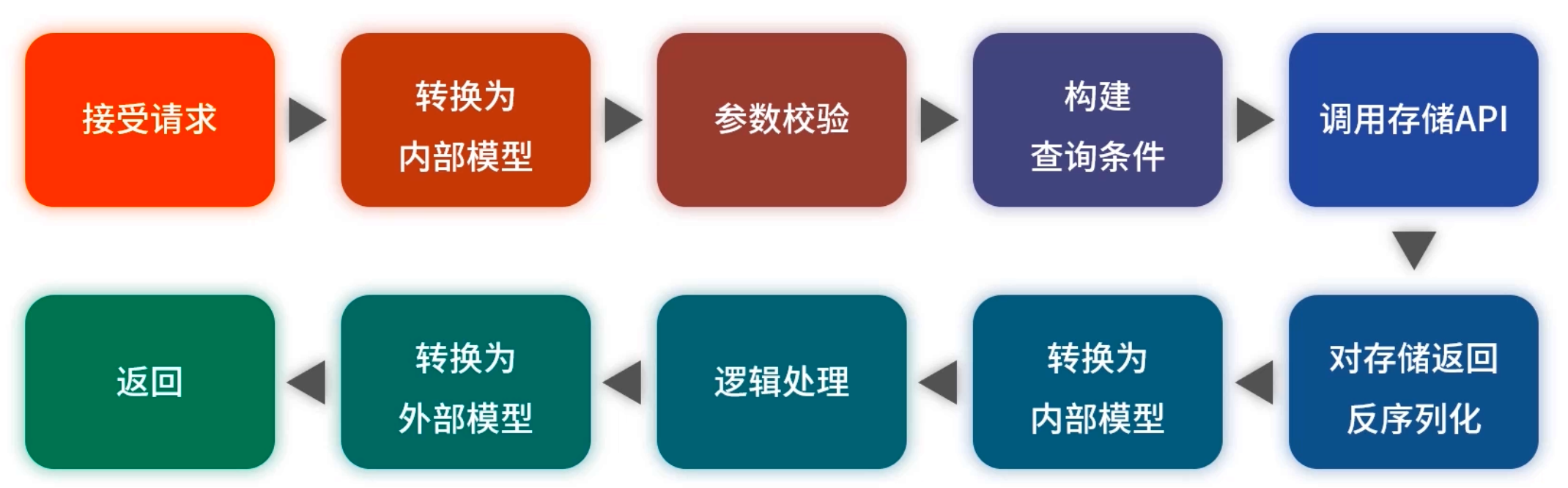
简化至:参数校验 → 查询构建 → 存储反序列化 → 业务加工 → 返回,把每一步都做到最轻量。
四、实战方案:懒加载架构及其四大挑战
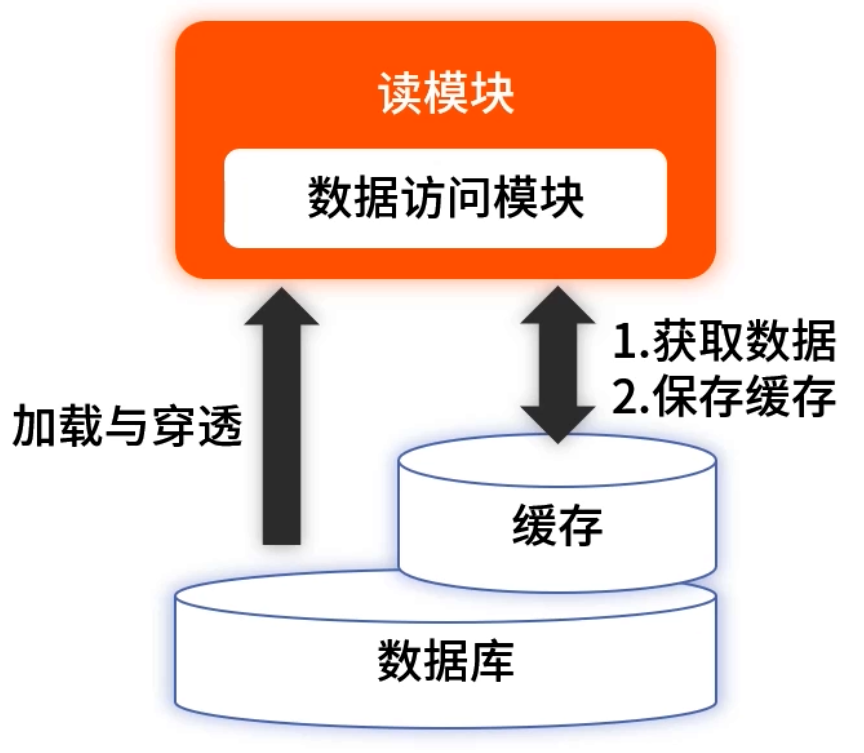
最常见的读服务方案:缓存(Redis)+ 数据库(MySQL) 的懒加载模式:
- 服务先查 Redis;
- 未命中则读数据库并写回缓存(带过期时间);
该方案实现成本低、思路清晰,但在高并发下会暴露以下问题:
-
缓存穿透
- 恶意请求不存在的 key → 每次都落到数据库,易打挂。 符 + 参数前置校验(如 IP、MAC、KOAP token),拦截非法请求。
-
缓存雪崩
- 同期过期后大量请求打到数据库。
- 解决:过期时间加盐,避免同一时刻热点 key 大规模失效。
-
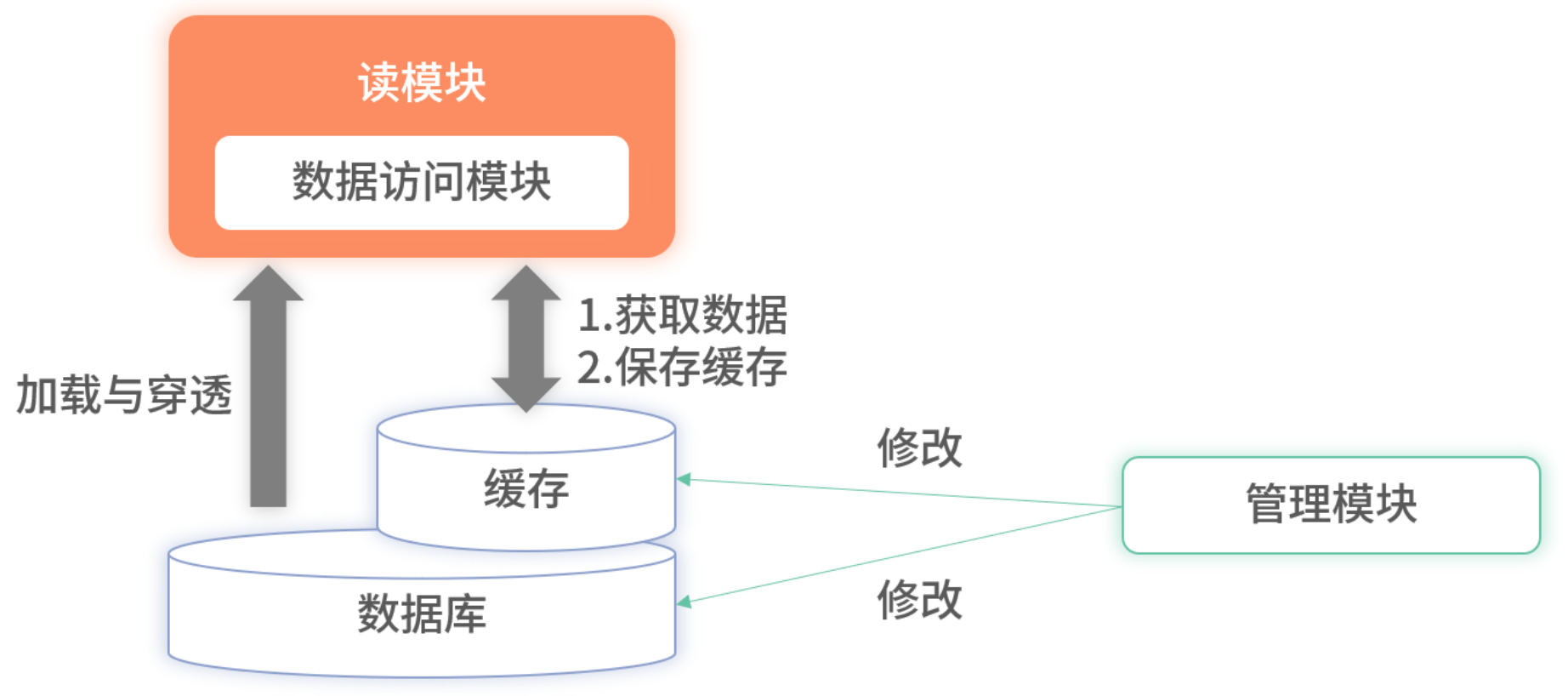
实时性不足
- 依赖过期失效机制,更新延迟。
- 改进可在写操作后主动推送变更,但需处理数据库与缓存更新顺序及分布式事务漏失。
-
性能毛刺
- 缓存过期瞬间穿透到数据库,延迟从毫秒级飙升至秒级。
- 可以借助全量缓存和预热机制以平滑毛刺。
五、改进思路
利用 全量缓存、消息队列同步、预热与降级 等技术,打造真正的毫秒级读服务。请参考下篇博客 。
六、总结与思考题
- 两大原则:架构不分层、代码简单。
- 懒加载四大问题:穿透、雪崩、实时性、毛刺。




















 4329
4329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











