







文章目录

1. 引入:重申背景与性能需求
架构思维:构建高并发扣减服务_利用数据库实现并发扣减中我们基于关系型数据库实现了库存扣减,利用事务保证 ACID 特性以防止超卖/少卖。
数据库方案最大的问题,在于它必须使用事务(Transaction)来保证扣减的 原子性和一致性。然而,正是事务的 ACID 特性:
A:原子性(Atomicity)
C:一致性(Consistency)
I:隔离性(Isolation)
D:持久性(Durability)
成了性能的掣肘者。
在批量扣减场景下,一条 SQL 对应一个 SKU,每次扣减都需要检查返回结果,一旦一个失败,就要整体回滚。而高并发下,多个用户争抢一个 SKU,又容易引发行级锁争用,甚至死锁,进一步导致性能雪崩。
所以说,数据库事务给了你一致性,也带走了你的吞吐率。在常规机器或 Docker 环境下,该方案难以支撑单机万级 TPS。
2. 回顾:纯数据库扣减方案瓶颈
- 事务开销:每个 SKU 扣减需循环多次 UPDATE + 返回值检查。
- 锁竞争:并发扣减同一 SKU 时,隔离级别导致锁等待或死锁。
- 持久化不必要:库存扣减只需原子性,持久化仅为故障恢复的后置需求。
故单机万级并发遥不可及。
3. 纯缓存方案原理剖析
-
拆分功能:将“原子性扣减”委托给单线程的 Redis,将“持久化”异步交由数据库。
-
数据模型:
-
库存 KV:
key = ss_{sku},value = 剩余数量。key为:sku_stock_{sku}。前缀sku_stock是固定不变,所有以此为前缀的均表示是库存。{sku}是占位符,在实际存储时被具体的skuid替代。
value:库存数量。当前此key表示的sku剩余可购买的数量。在实际应用中,上述 key 的 sku_stock_ 前缀一般会简写成 ss_ 或者可以起到和其他 key 区分的较短形式。当我们存储的 SKU 有百万、千万级别时,此方式可极大地降低存储空间,从而降低成本,毕竟内存是比较昂贵的
-
扣减流水 Hash:
key = sx_{sku},field = 流水ID,value = 数量。key:sx_{sku}。前缀sx_是按上述缩短的形式设计的,只起到了区分的作用。{sku}为占位符
hashField:此次扣减流水编号。
hashValue: 此次扣减的数量
-
-
原子保障:Redis 单线程事件循环天然串行执行命令,满足扣减原子要求。
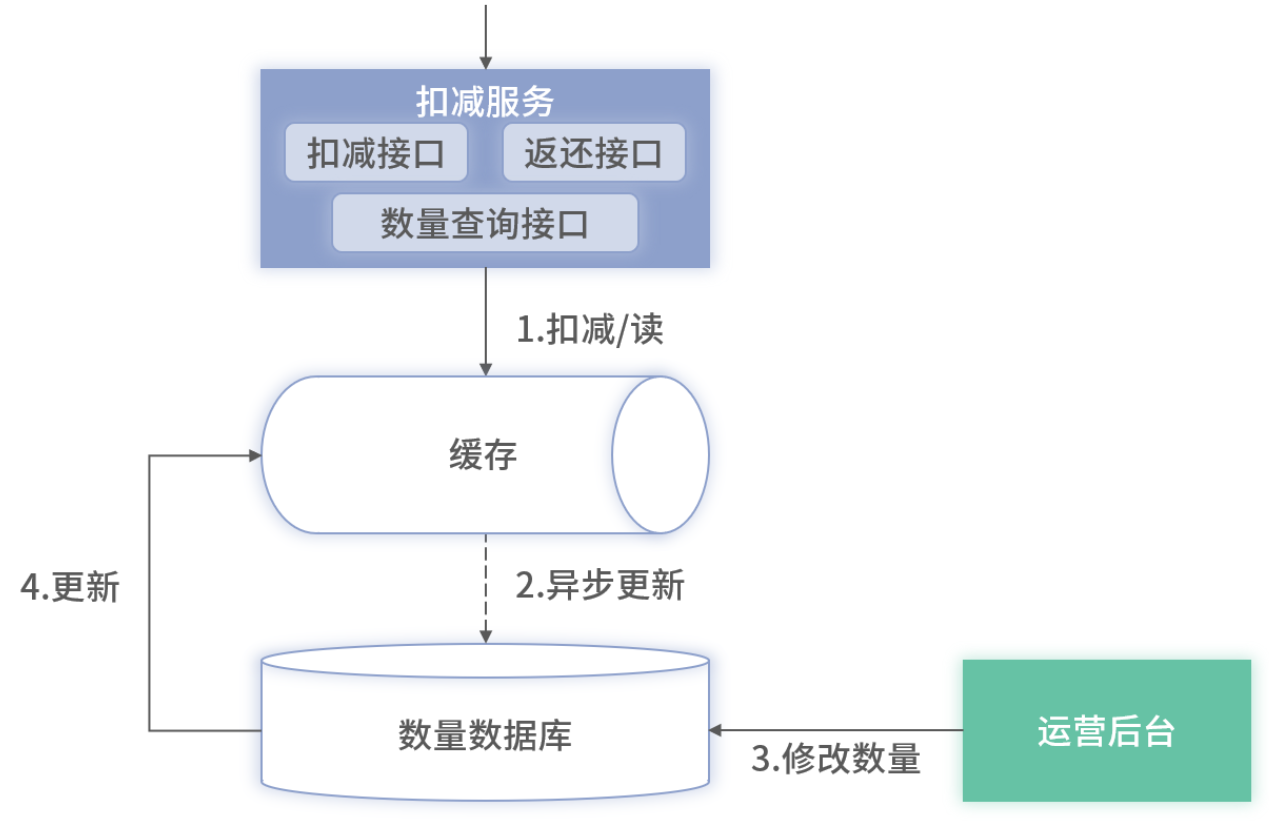
4. 架构图解读:整体流程
-
扣减接口:接收批量 SKU+数量请求,不直接操作数据库,而调用 Redis。
-
Redis 缓存层:
- 不设置过期,全量持久化 SKU 库存与流水。
- 利用 Lua 脚本做批量原子操作(见下文)。
-
异步持久化:扣减成功后,通过消息或异步线程将结果写入数据库,用于容灾与对账。
-
运营后台:直接修改数据库,并同步写回 Redis,可通过 Binlog 或直接代码异步更新。
5. Lua 脚本执行流程详解

在 Redis 中部署并调用 Lua 脚本,保证以下操作的原子性:
- 防重检查:
GET uuid,已存在则拒绝; - 批量读取:一次性读取所有 SKU 的剩余库存;
- 数量校验:如有任何 SKU 数量不足,立即返回失败;
- 循环扣减并记录流水:更新 KV 并在 Hash 中写入流水;
- 返回结果:全部成功则返回 OK,再触发异步持久化。
此流程利用 Redis 单线程特性,确保校验与扣减步骤之间无任何并发干扰。
6. 异常场景与应对策略
- Redis 宕机中断在校验前:安全返回失败,无数据影响。
- Redis 宕机中断在扣减后:部分库存被扣减但返回失败,需对账程序比对 Redis 与数据库日志,补回丢失库存。
- 异步写库失败:Redis 数据准确但数据库滞后,通过日志比对将多余库存在库端扣减。
对账逻辑与自动化脚本是保证最终一致性的关键。
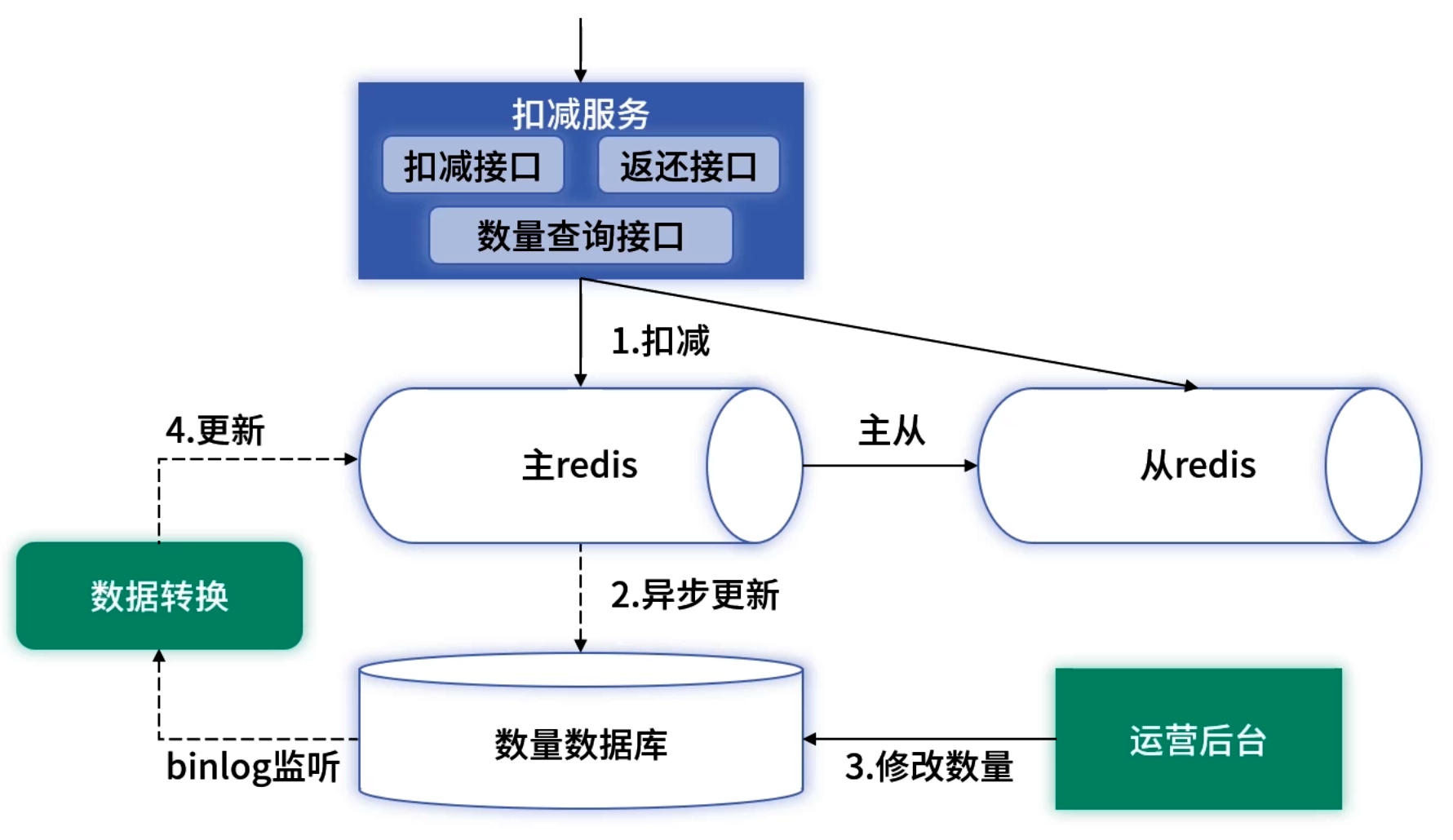
7. 升级与优化:主从分离与 Binlog 同步
-
读写分离
- 增加 Redis 从节点,扣减走主节点,查询走从节点,互不干扰。
-
Binlog 驱动同步
- 运营后台修改数据库后,使用 MySQL Binlog 实时流式推送至 Redis,利用 ACK 机制保证消费可靠,简化分布式事务难题。
优化后读写性能和一致性保障更强。
8. 优劣与适用性分析
-
优点
- 性能提升超十倍,满足高并发场景。
- 部署成本低,Docker 上轻松运行。
-
缺点
- 缺乏 ACID,极端故障下仍需对账补偿。
- 系统复杂度增加,对异常流程要求高。
-
适用场景
- 大促、限购等对精度要求可降级的场景。
- 通过完善对账与降级策略,也可用于库存、积分等精度较高的业务。
9. 在 Redis Cluster 上演化纯缓存扣减方案
已思考 4 秒
专家:后端架构 > Redis Cluster 高并发扣减演化专家
要求:V=2(详细),面向中高级后端开发者或架构师
计划
- 回顾单实例 Lua 扣减方案的原子依赖;
- 分析 Redis Cluster 分片模型对 Lua 原子性的影响;
- 提出演化策略——槽内多键原子、跨槽脚本分片执行、客户端路由与聚合;
- 运维自动化:脚本下发与版本管理;
- 容灾与对账;
- 适用场景与总结。
10. 在 Redis Cluster 上演化纯缓存扣减方案
纯缓存 + Lua 脚本方案中,我们利用单实例 Redis 的单线程执行保障了多 SKU 批量扣减的原子性。若将 Redis 换成 Cluster 模式,数据会根据 key 的哈希槽(0–16383)分布到多个节点上,单实例 Lua 脚本的“多 key 原子”假设将不再成立,需要进行方案演化。
1)、Redis Cluster 的多槽分片模型
- 哈希槽分配:每个 key 会被分配到 0–16383 中的一个槽,槽再绑定到某个节点;
- 跨槽操作限制:Cluster 下的 EVAL/EVALSHA 仅支持所有 key 位于同一槽,否则报错;
- 节点扩容增减:可动态迁移槽到新节点,数据在线重分布。
这意味着,若一个 Lua 脚本操作了落在不同槽的多个 SKU key,将触发 CROSSSLOT Keys in request don’t hash to the same slot 错误。
2)、演化策略
2.1). 利用 Hash Tag 保证多键落槽
在设计 key 时,为所有同次批量扣减的 SKU key 添加相同的 Hash Tag,例如:
ss_{orderId}_{skuA} → key="ss_{order42}_SKU_A"
ss_{orderId}_{skuB} → key="ss_{order42}_SKU_B"
Redis 会只对 {order42} 部分计算槽,这样所有本次扣减相关 key 均落在同一槽,单次 EVAL 能覆盖多个 SKU,实现原子批量扣减。
优点
- 零成本复用单实例脚本逻辑;
- 保持原子性与高性能。
缺点
- 破坏了槽的均衡,某些热点订单标签可能集中在单节点。
2.2). 跨槽脚本分组执行
若无法统一 Hash Tag(如多次请求复用同一 SKU 导致频繁热点),则需要在客户端按槽分组,对每个槽调用一次 Lua 脚本,再在客户端聚合返回结果:
- 分组:将所有待扣减的 SKU key 按照
keyslot(key)分成若干组; - 并行 EVAL:对每个分组调用 Lua 脚本,局部判空与扣减;
- 聚合:若任一槽组返回失败,则对所有已执行成功的槽组进行补偿(使用反向 Lua 脚本回滚);
可在客户端或专用网关层实现此两阶段执行与补偿逻辑。
2.3) 引入 Redisson / Proxy 层
使用成熟的 Redis Cluster 客户端(如 Redisson)或代理层(如 Redis-Proxy/Twemproxy):
- 客户端 自动管理跨槽分组与脚本下发;
- Proxy 可在前端做一层路由与聚合,屏蔽应用层负担;
这样,开发者只需调用“扣减(list_of_keys, list_of_amounts)”高阶接口,底层框架负责分槽、并行、补偿和重试。
3)、运维与自动化
-
Lua 脚本下发
- 在 CI/CD 流水线中,对所有 Cluster 节点推送并加载最新脚本(
SCRIPT LOAD); - 维护脚本版本和 SHA1 校验,确保客户端执行时可命中
EVALSHA。
- 在 CI/CD 流水线中,对所有 Cluster 节点推送并加载最新脚本(
-
监控与报警
- 监控各槽节点的脚本调用延迟与错误率;
- 针对热点槽(同一 Hash Tag 的过载)预警,并可动态调整 Hash Tag 设计。
4)、容灾与对账
- 故障切换:Cluster 自动主从切换后,数据在新主节点继续可用;
- 对账机制:同单实例方案,定时比对 Redis 与下游持久库,将日志中的失败/部分成功事务通过补偿脚本回写 Redis。
5)、适用场景与建议
| 方案 | 适用场景 |
|---|---|
| Hash Tag 锁槽 | 批量扣减且订单维度稳定、不担心单节点热点 |
| 跨槽分组执行 | SKU 数量大、Hash Tag 难以覆盖多样业务场景 |
| Proxy/Redisson | 期望快速落地,借助成熟中间件屏蔽复杂性 |
在 Redis Cluster 环境下,保持扣减的原子性关键在于如何将多 key 操作限定在同一槽,或者以分组+补偿的方式模拟全局事务。同时,借助成熟客户端或代理层能显著降低应用复杂度。无论哪种策略,都需配合自动化脚本下发、监控报警与对账补偿,才能在万级甚至更高并发场景中,保障缓存扣减的正确性与可用性。




















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











