






首先需要明确一个在损失函数中的加权细节:想要在损失函数中对样本进行加权,那么加权的思路应该要是逆向的。因为损失函数的优化目标是越小越好,所以你越想保护的部分应该给予小权重,使得这部分可以大。而越想惩罚的部分,应该给予大权重,这样强制让他们只能是小的。
Focal loss : 。里面最核心的两个参数
和
。
其中 类似与class weight 给类别加权重。如果 y = 1 类样本个数大于 y = 0, 那么
应该小于 0.5,保护样本少的类,而多惩罚样本多的类。结论是样本越不平衡,
应该越靠近 0 或者 1。
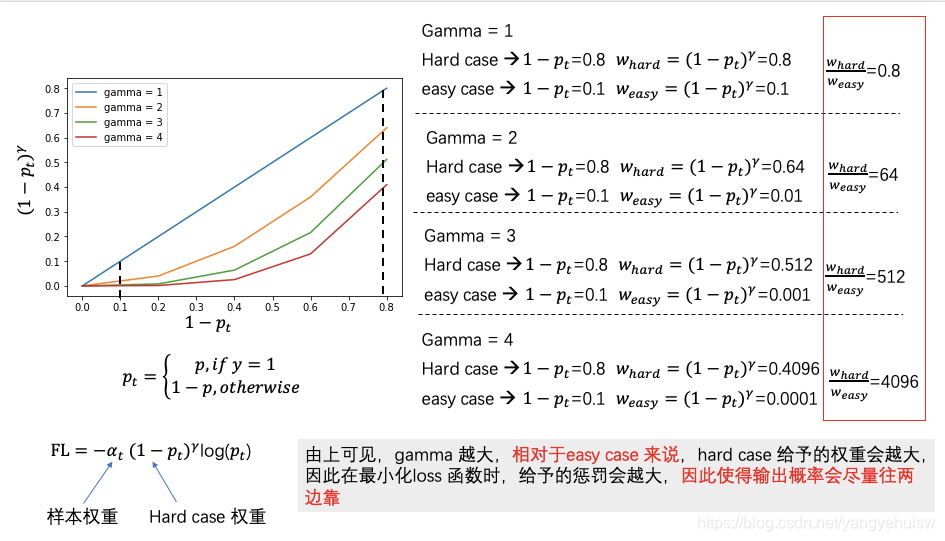
而 的作用是竟然把难例分开,这个参数越大,导致的后果是预测的概率值越偏向于0~1的两端。具体推理如下图所示:

















 2499
2499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









