







本文已汇总的系列如下:
| Qwen系列 | LLama系列 | GLM系列 | Kimi系列 | Deepseek系列 | MiniMax系列 | Mistral系列 |
| Qwen | LLama1 | ChatGLM(GLM) | Kimi-K1.5 | Deepseek-v1 | MiniMax-01 | Mistral-7B |
| Qwen1.5 | LLama2 | GLM2 | Deepseek-v2 | Mistral-8x7B | ||
| Qwen2.0 | LLama3 | GLM3 | Deepseek-v3 | Mistral-8x22B | ||
| Qwen2.5 | LLama3.1 | GLM4 | Deepseek-R1-Zero | Mistral-Nemo-12B | ||
| Qwen2.5-MAX | Llama3.2 | Deepseek-R1 | ||||
| QWQ-32B |
0、起源:Transformer
现有的大模型能有效地work,源于Transformer的decoder layer(解码层)的魔力,下面一个图解释,细节满满:
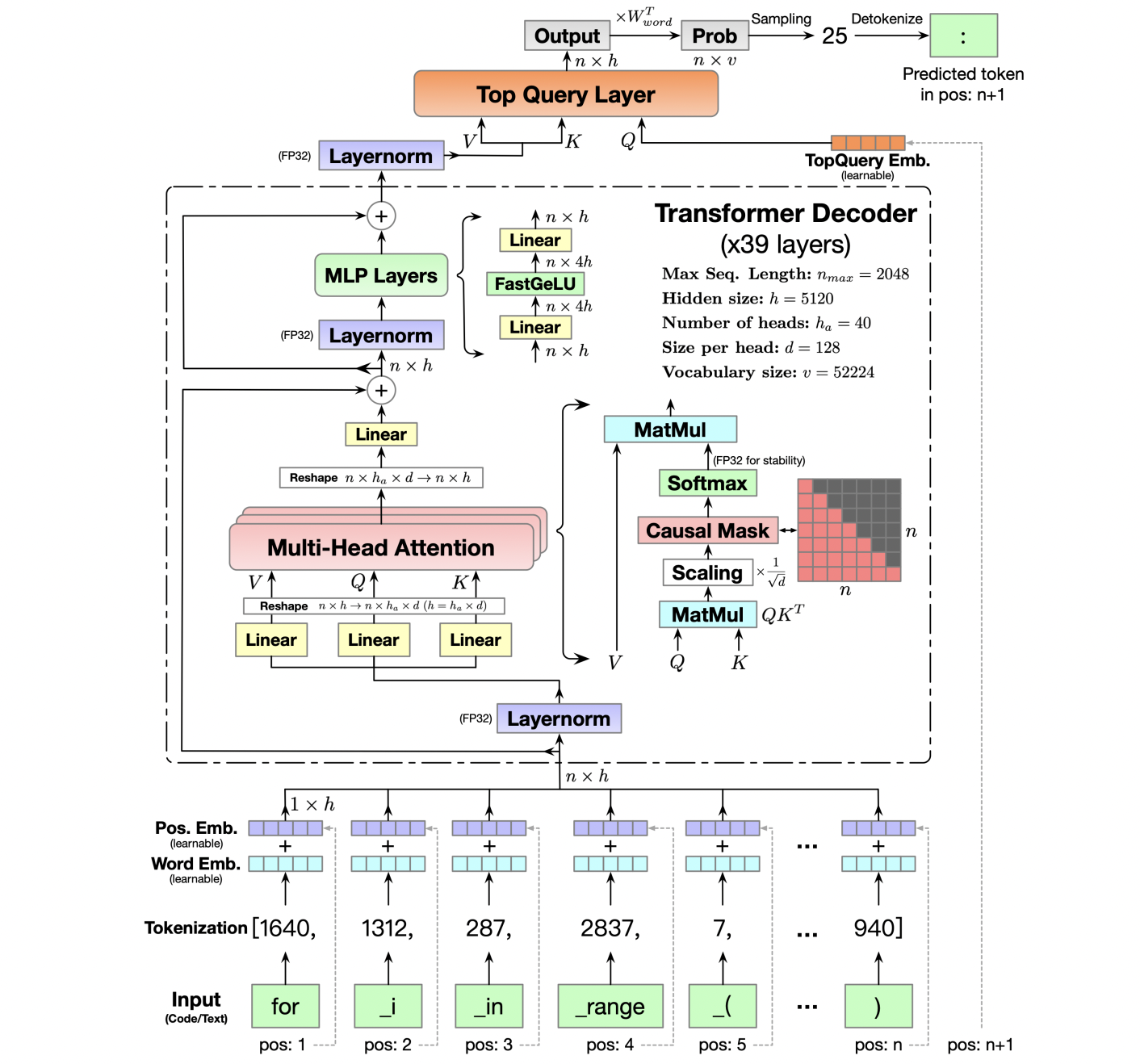
图解:Transformer的解码层
一、Qwen系列
1.1 Qwen
1)与传统Transformer的区别:
-
- 输入长度:32k
- 位置编码:RoPE
- Bias部分删除:对于大多数层,Qwen遵循陈卓辉等人的做法删除偏差,但对于注意力中的QKV层添加了偏差,以增强模型的外推能力
- 激活函数:SwiGLU
- 优化器:AdamW,设置超参数β1=0.9、β2=0.95和e=10^(−8)
- Pre-Norm:它已被证明比Post-Norm更能提高训练稳定性。
有关Pre-Norm为什么比Post-Norm更好的疑问,这里可以看下 苏建林提供的理解:本来残差的意思是给前面的层搞一条“绿色通道”,让梯度可以更直接地回传,但是在Post Norm中,这条“绿色通道”被严重削弱了,越靠近前面的通道反而权重越小,残差“名存实亡"。
-
- RMSNorm:用RMSNorm取代了传统LayerNorm
RMSNorm为什么比LayerNorm好作者认为LayerNorm对张量所做的聚集中心化(re-centering)并不能够使梯度的方差减小,因此将均值μ=0。
-
- 训练数据:2-3T token
2)模型大小:开源了Qwen-1.8B、Qwen-7B、Qwen-14B 和 Qwen-72B
参考: 冯卡门迪:[论文笔记]RMSNorm:Root Mean Square Layer Normalization、 Introducing Qwen
1.2 Qwen1.5
1)输入长度:32768
2)GQA:32B和110B的模型使用
3)模型大小:开源了六种大小的基础和聊天模型,即0.5B、1.8B、4B、7B、14B、32B、72B 和 110B,以及 MoE 模型(64个expert)
参考: Introducing Qwen1.5、 https://qwenlm.github.io/blog/qwen-moe/
1.3 Qwen2.0
1)上下文长度:128k
2)注意力机制:GQA,相比MHA参数减少
3)模型大小:开源了0.5B、1.5B、7B、57B-A14B(共57B但激活14B)和72B等五种模型
参考: https://qwenlm.github.io/blog/qwen2/
1.4 Qwen2.5
1)模型大小:开源了0.5B、1.5B、3B、7B、14B、32B和72B等七种模型
2)预训练数据:18T token
3)输入输出长度:支持128K token,并能生成最多 8K token的内容
参考: https://qwen.readthedocs.io/zh-cn/latest/
1.5 Qwen2.5-MAX
1)模型大小:未知
2)模型结构:大规模 MoE 模型
3)训练数据:在20T+ token 上进行了预训练,并使用SFT和RLHF方法进行了后训练
参考: Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model
1.6 QwQ-32B
1)模型大小:32B
2)训练方法:借鉴的DeepSeek-R1,直接进行两次大规模强化学习(RL):
-
- 第一次RL:针对"数学和编程任务",采用基于规则的奖励模型,进行RL训练。随着参数迭代,模型在两个领域中的性能均表现出持续的提升。
- 第二次RL:使用通用奖励模型和一些基于规则的验证器进行训练。通过少量步骤的通用 RL,可以提升其他通用能力,同时在"数学和编程任务"上的性能没有显著下降。
3)技术细节:未知(可能报告还没发出来)
参考: QwQ-32B: Embracing the Power of Reinforcement Learning
二、LLama系列
2.1 LLama1
1)与传统Transformer的区别:
-
- 先Norm再Attention:先后位置换了
- 采用Pre-normalization:在残差前进行归一化
- 激活函数:SwiGLU
- 相对位置编码:RoPE
2)模型大小:7B、13B、33B、70B
参考: llama1参考资料 、 https://arxiv.org/pdf/2302.13971
2.2 Llama2
1)改进点:
-
- 注意力机制:MHA改成GQA,即整体参数量会有减少
- FFN模块矩阵维度:扩充了,增强泛化能力,整体参数量增加
- 上下文长度:提升两倍,长度从2k到4k,训练语料增加约 40%,体现在1.4T->2.0T的Token,llama2-34B和llama2-70B使用了GQA,加速模型训练和推理速度
- 训练数据:1.4T变成2T
2)模型大小:7B、13B、70B等
参考: llama2参考资料、 https://huggingface.co/meta-llama
2.3 Llama3
1)改进点:
-
- 词表:32k变成128k
- 上下文长度:4k到8k
- 训练数据:2T变成15T
- 注意力机制:GQA
2)模型大小:8B、70B
参考: https://ai.meta.com/blog/meta-llama-3/、 https://huggingface.co/meta-llama
2.4 Llama3.1
1)改进点:
-
- 上下文窗口大小:8K到128K
- 注意力机制:全系使用GQA
- 训练数据:15.6T token
2)模型大小:8B、70B、405B
参考: https://53ai.com/news/OpenSourceLLM/2024080664718.html、 https://huggingface.co/meta-llama
2.5 Llama3.2
包括小型和中型视觉 LLM(11B 和 90B)以及适合特定边缘和移动设备的轻量级纯文本模型(1B 和 3B)
参考: https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
三、GLM系列
3.1 ChatGLM(GLM)
1)提出了一个新的LLM模型训练思路——自回归空格填充任务
-
- 一个语句分为两块:A表示MASK后的语句,B表示MASK部分单独出来的语句。
- attention mask巧妙融合:设计attention mask巧妙地融合自编码、自回归、Encoder-Decoder三类模型。其中A中能双向看到MASK(即自编码,类似BERT),B后面的MASK片段能看到前面的(即自回归,类似GPT,无条件生成),B可以看到A(即Encoder-Decoder,类似BART,有条件生成)。
2)对模型结构做出了一些修改
-
- Norm:采用deep Norm = Post Norm + LayerNorm,在残差后进行归一化:
- 位置编码:RoPE
- 激活函数:GELUs替换原始的ReLU
3)模型大小:6B
参考: GLM论文、 https://zhuanlan.zhihu.com/p/682938656 、 GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
3.2 GLM2
1)训练数据:延续使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练
2)上下文长度:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。
3)注意力机制/推理速度优化:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
4)模型大小:6B
参考: https://github.com/THUDM/ChatGLM2-6B GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型参考: https://github.com/THUDM/ChatGLM2-6B
3.3 GLM3
1)数据多样性:采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。号称10B以下无对手
2)API:采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
3)模型大小:6B
参考: https://github.com/THUDM/ChatGLM3
3.4 GLM4
1)上下文长度:支持8k、128K和1M
2)多语言支持:支持包括日语,韩语,德语在内的 26 种语言。
3)模型大小:9B
参考: https://github.com/THUDM/GLM-4
四、Kimi系列
4.1 Kimi-K1.5
1)提出背景
-
- 目标:使用RL探索新的Scaling Law。
- 原因:传统的Scaling Law受限于可用的高质量训练数据的数量,因此作者想通过强化学习(RL)来探索可能的新缩放维度(之前的Scaling Law)
2)模型侧
-
- 长上下文扩展:将强化学习(RL)的上下文窗口扩展到128k,随着上下文长度的增加,性能持续改善。通过使用部分回合来提高训练效率,即通过重用以前回合的大部分来采样新轨迹,避免从头生成新轨迹的成本。这表明上下文长度是RL与大型语言模型(LLMs)持续扩展的关键维度。
- 改进的策略优化:推导出具有长推理链(long-CoT)的RL公式,并采用一种在线镜像下降的变体进行鲁棒的策略优化。该算法通过有效的采样策略、长度惩罚和数据配方优化进一步得到改进。
参考: https://arxiv.org/pdf/2501.12599、 https://zhuanlan.zhihu.com/p/19774180151
五、DeepSeek系列
5.1 DeepSeek-v1
1)模型侧
-
- 结构:模型的主体结构基本沿用LLaMA
- 大小:开源了7B和67B两种尺寸,7B是MHA、67B是GQA
2)数据侧
-
- 数据的预处理:包括去重、过滤、混合3个步骤,目的是构建一个多样性强、纯净的高质量预训练数据。
- 在去重阶段,对于Common Crawl数据集进行全局的去重过滤,可以提升去重比例
- 在过滤阶段,构建了一套详细的包括文法语法分析在内的评估流程,去除低质量数据
- 在混合阶段,对不同domain的数据进行采样,平衡不同domain数据量,让数据量较少的domain也能有足够的样本占比,提升数据集多样性和全面性
- 数据的token化:使用Byte-level Byte-Pair Encoding(BBPE)作为tokenizer,相比BPE是在字符粒度进行字符串分割,BBPE在字节粒度进行处理,整体算法逻辑和BPE类似
- 整体参与预训练的token数量:2T
- 数据的预处理:包括去重、过滤、混合3个步骤,目的是构建一个多样性强、纯净的高质量预训练数据。
参考: https://github.com/deepseek-ai/DeepSeek-LLM、 https://zhuanlan.zhihu.com/p/21356402058
5.2 DeepSeek-v2
1)模型侧
-
- MLA:提出了Multi-head Latent Attention(MLA)去提升inference效率
- MOE:构建了基于DeepSeekMoE的语言模型结构
2)数据侧
-
- 整体参与预训练的token数量:8T
参考: https://github.com/deepseek-ai/DeepSeek-V2、 https://zhuanlan.zhihu.com/p/21356402058
5.3 DeepSeek-v3
1)模型侧
-
- MOE优化:对DeepSeekMoE中的多专家负载均衡问题,提出了一种不需要辅助loss就能实现的解决方案,相比使用辅助loss提升了模型性能
- MTP:引入了Multi-Token Prediction技术,相比原来每次只能预测一个token,显著提升了infer的速度。
- 参数:参数大小671B,激活37B,参数分布见笔者另一篇文章。
- 训练架构的独特优势
2)数据侧
-
- 整体参与预训练的token数量:14T
参考: https://github.com/deepseek-ai/DeepSeek-V3、 https://zhuanlan.zhihu.com/p/21356402058 、 https://zhuanlan.zhihu.com/p/21208287743
5.4 DeepSeek-R1-zero
1)模型侧
-
- RL:在DeepSeek-V3的基础上,仅使用强化学习进行的训练,而无需依赖监督微调 (SFT)
- CoT:具备推理(Reasoning)能力
- 参数:参数大小671B,激活37B
2)数据侧
-
- 整体参与预训练的token数量:14T
- CoT数据:通过各种思维链(CoT,Chain of Thought)数据特别是Long CoT数据来激活模型的推理能力
参考: https://arxiv.org/pdf/2501.12948
5.5 DeepSeek-R1
主要包括四个核心训练阶段(阶段1、2、3、4)和2个数据准备阶段(阶段0、2.5):
-
- 阶段0:即获取DeepSeek-R1-Zero(即本文5.4小节)。
- 阶段1:基于R1-Zero的几千+数据,在V3-Base上执行第一次SFT,获得基本的格式遵循和反思验证的能力。
- 阶段2:然后执行第一次强化学习,加强模型在数学、代码、科学、逻辑推理等领域的推理能力。
- 阶段2.5:基于阶段2的模型,获取领域更广泛的600K数据;基于V3-Base,获取包括CoT的非推理数据200K。
- 阶段3:基于阶段2.5获取的800K数据,在V3-Base上执行第二次SFT,增强模型的通用性。
- 阶段4:执行第二次强化学习,进一步对齐人类偏好,提升模型的可用性和无害性,并精炼推理能力。
参考: 假如给我一只AI:温故而知新之:图解DeepSeek-R1
六、MiniMax系列
6.1 MiniMax-01
1)采用线性注意力机制的变体——闪电注意力(Lightning Attention)
-
- 背景:现有线性注意力机制计算效率的主要瓶颈在于因果语言建模中固有的低效cumsum运算(在因果语言建模中,模型需要逐步处理序列数据,每一步都依赖于之前所有步骤的累积信息。这就需要对输入序列进行累加和操作,以便在生成下一个输出时考虑所有之前的输入信息)。
- Lightning Attention:创新性地提出了一种分块技术,有效规避了cumsum运算。其核心创新在于将注意力计算策略性地分解为两个部分:块内计算和块间计算。块内计算采用左侧矩阵乘法注意力机制,而块间计算采用右乘运算。这种分解策略的关键在于可以显著减小块内计算的规模,从而保证整体计算复杂度维持在线性水平。
2)采用MOE架构
-
- 参数:总参数量456B,激活参数45.9B,专家数量32个
- EP+ETP:采用专家并行(EP)和专家张量并行(ETP)技术实现了MoE的全对全通信,以最小化GPU间的通信开销
参考: https://arxiv.org/pdf/2501.08313、 https://zhuanlan.zhihu.com/p/19366579496
七、Mistral系列
7.1 Mistral-7B
-
- 模型结构:
- 维度 (dim): 4096
- 层数 (n_layers): 32
- 每头维度 (head_dim): 128
- 隐藏层维度 (hidden_dim): 14336
- 注意力头数 (n_heads): 32
- 键值注意力头数 (n_kv_heads): 8
- 窗口大小 (window_size): 4096
- 上下文长度 (context_len): 8192
- 词汇表大小 (vocab_size): 32000
- 注意力机制优化:GQA+滑动窗口注意力
- 模型结构:
滑动窗口注意力(SWA):在标准的注意力机制中,操作次数随着序列长度呈二次方增长,且内存使用量随着标记数量线性增加。在推理时,这会因缓存可用性减少导致较高的延迟和较小的吞吐量。为了解决这个问题,我们使用滑动窗口注意力:每个标记最多可以关注来自前一层的 W 个标记(此处,W = 3)。需要注意的是,滑动窗口之外的标记仍然会影响下一个词的预测。在每个注意力层中,信息可以向前移动 W 个标记。因此,经过 k 个注意力层后,信息最多可以向前移动 k × W 个标记。
参考: https://zhuanlan.zhihu.com/p/711294388、 https://arxiv.org/pdf/2310.06825
7.2 Mistral-8x7B
-
- 模型结构:稀疏混合专家模型 (SMoE)
- 模型大小:8个expert MLP 层,总参数量为 46.7B,每一个标token仅激活 12.9B
- 上下文长度 (context_len):32K
- 开源模型:除了预训练外,Mixtral MOE 后续还开源了一个经过 SFT + DPO 微调的版本
- 多语言:支持多种语言,包括英语、法语、意大利语、德语和西班牙语
参考: Mixtral of experts | Mistral AI
7.3 Mistral-7x22B
-
- 模型结构:和Mistral-8x7B一样,稀疏混合专家模型 (SMoE)
- 模型大小:总参数量为 141B,每一个标token仅激活 39B
- 上下文长度 (context_len):64K
参考: Cheaper, Better, Faster, Stronger | Mistral AI
7.4 Mistral-Nemo-12B
-
- 模型结构:和Mistral-8x7B一样,稀疏混合专家模型 (SMoE)
- 来源:与 NVIDIA 合作构建的 12B 模型
- 上下文长度 (context_len):128K
参考: Mistral NeMo | Mistral AI

















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









