










一.源码准备
下载地址:paddleocr
注意:如果需要使用tensorrt加速,需要下载2.2以上版本的
运行环境
1.准备一个新的虚拟环境,安装下载的源码当中对应的requirements.txt文件,记住paddle的版本尽量和下载的代码版本一致,使用tensorrt需要的paddlepaddle版本也不一样,需要去官网查找
2.下载地址:paddlepaddle
二.准备数据
1.下载官网数据集
2.准备自己的数据集
官网数据:
# 在PaddleOCR路径下
cd PaddleOCR/
wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt
自己的数据:
- 安装与运行PPOCRLabel
一般拉取的paddleocr里面有PPOCRLabel
pip install PPOCRLabel # 安装
# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
- 运行PPOCRLabel(pycharm的终端运行)
cd ./PPOCRLabel #进入py文件所在位置
python PPOCRLabel.py --lang ch # 运行文件
- 数据标注
文件>打开目录>选择文件夹>左下角的自动标注(等待自动标注完成)
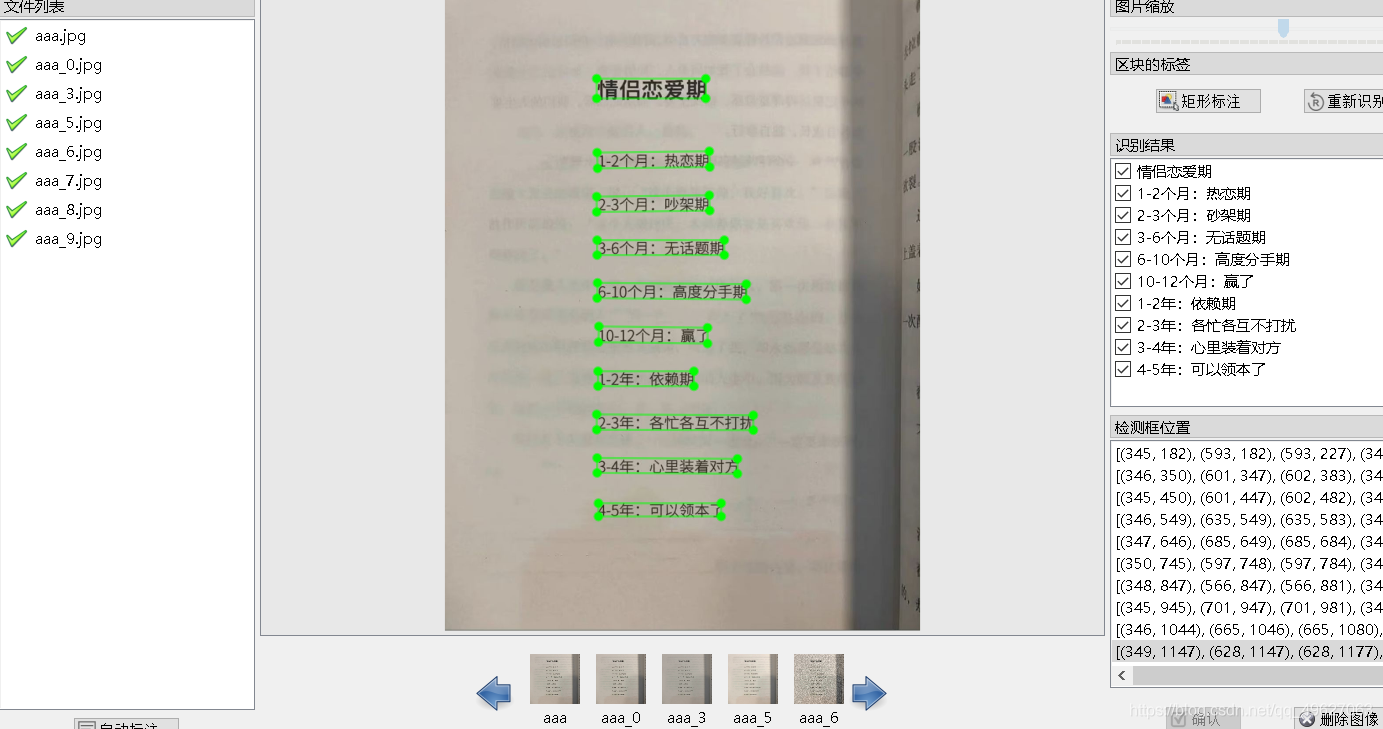
查看标注是否正确,然后进行修改确定,下一张(记住需要先把自动保存开启)
标注完成之后,再次 点击 文件>保存标记结果>保存识别结果
会在数据文件生成如下数据
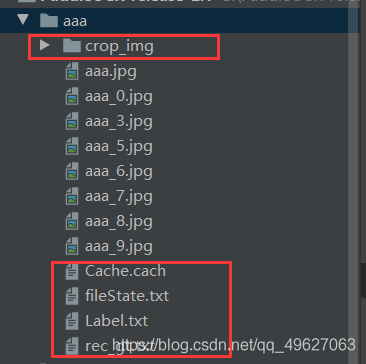
Cache.cach:保存的gt框的坐标
fileState.txt:类别标签
Label.txt:保存的gt框的坐标(一般用的都是这个)
rec_gt.txt:文本识别识别结果(对应的是文本识别)
三.参数修改(det_mv3_db.yml)
1.预训练模型参数
configs>det>det_mv3_db.yml 文件模型
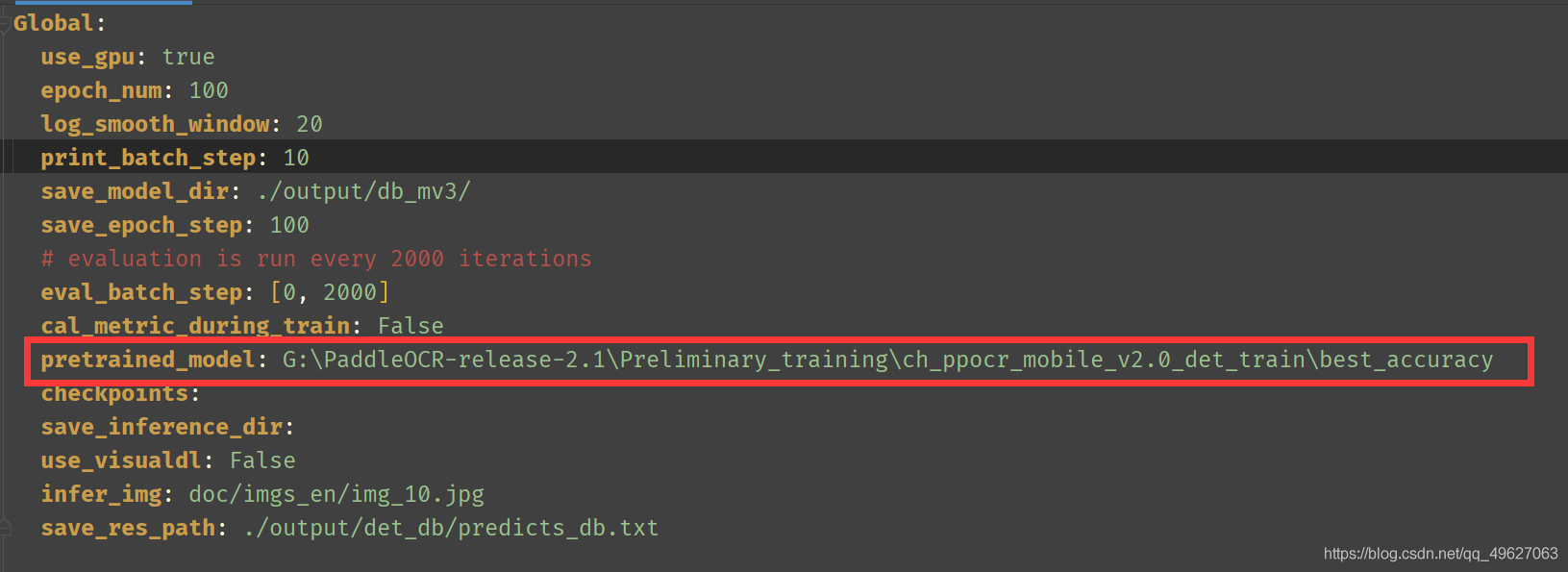
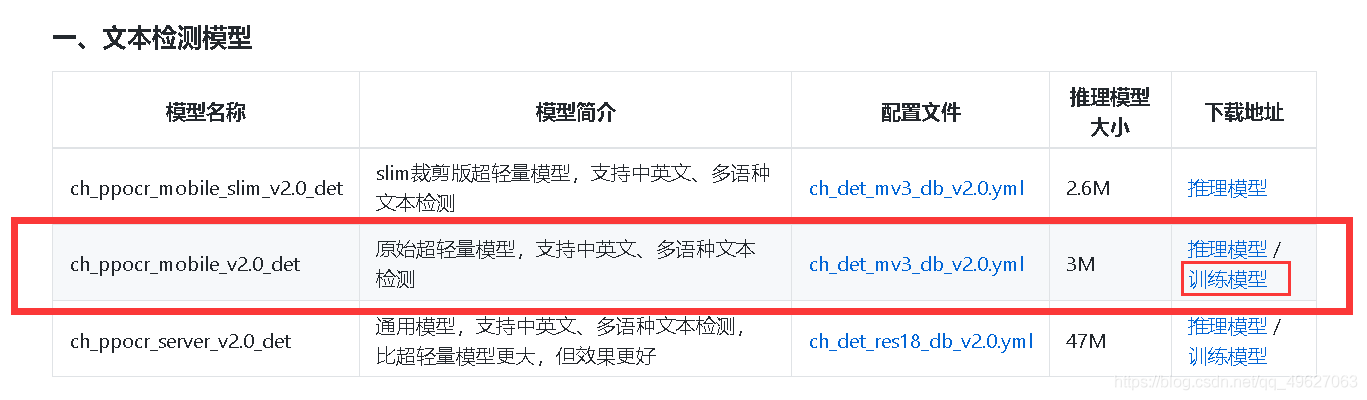
预训练模型下载:
cd PaddleOCR/
# 下载MobileNetV3的预训练模型
wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV3_large_x0_5_pretrained.tar
# 或,下载ResNet18_vd的预训练模型
wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/ResNet18_vd_pretrained.tar
# 或,下载ResNet50_vd的预训练模型
wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_vd_ssld_pretrained.tar
网址:预训练模型
网址:预训练模型和推理模型
2.训练数据参数
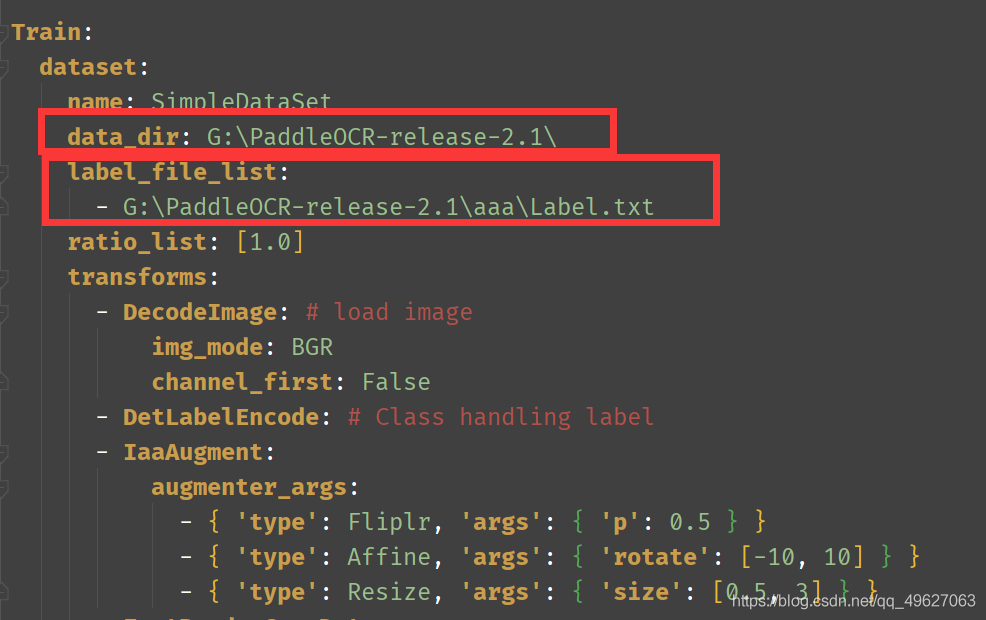
data_dir 需要修改成自己的
label_file_list 自己标签的位置
data_dir 不要写到自己的图片目录下
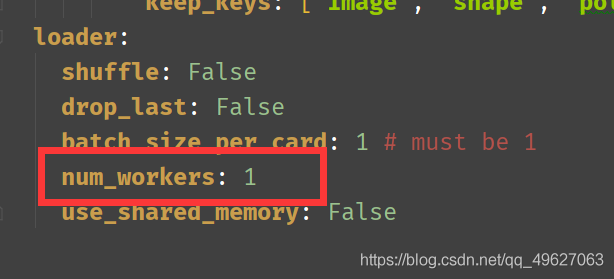
建议调成1,根据自己的电脑来设置
Eval当中的batch_size_per_card必须是1,这个不能更改
3.模型开始训练
python tools/train.py -c configs/det/det_mv3_db.yml
也可以调整代码,直接运行train.py
program.py调整ArgsParser下面的-c -config 指定为.yml的配置文件路径(也就是你修改的配置文件路径)
最后训练好可以在./output/db_mv3 下面的yml中查看训练的配置文件
训练参数
Global:
use_gpu: True #是否使用GPU
epoch_num: 1200 #最大训练轮数
log_smooth_window: 20 #日志最大宽度
print_batch_step: 20 #日志打印间隔
save_model_dir: ../output/det_db/det_r50_vd_test/ #模型保存路径
save_epoch_step: 200 #模型保存间隔
# evaluation is run every 2000 iterations
eval_batch_step: [0,1200] #模型评估间隔
# if pretrained_model is saved in static mode, load_static_weights must set to True
load_static_weights: True #是否将预训练模型保存在静态图形模式
cal_metric_during_train: False #是否设置中值评估
pretrained_model: ../pretrain_models/ResNet50_vd_pretrained #预训练模型
checkpoints: ../output/det_db/det_r50_vd_test/latest #模型参数设置,用中断后加载参数继续训练
save_inference_dir: #推理模型保存路径
use_visualdl: False #是否设置可视化日志,启用visual
infer_img: /data/_workspace/PPOCR/src/doc/imgs_en/img_10.jpg #推理图片位置或者文件夹位置
save_res_path: /data/_workspace/PPOCR/data/output/det_db/predicts_db.txt #设置测试模型的保存路径,仅在检测模型中有效
Architecture:
model_type: det #网络类型,名目支持rec,det,cls(识别,检测,方向)
algorithm: DB #算法类型
Transform: #设置转换方法,目前仅支持识别算法
Backbone:
name: ResNet #主干网络
layers: 50 #resnet层数,目前支持18,34,50,101,152,200
Neck:
name: DBFPN #目前支持SequenceEncoder,DBFPN
out_channels: 256 #输出通道数
Head:
name: DBHead #目前支持CTCHead,DBHead,ClsHead
k: 50 #DBHead二值化系数
Loss:
name: DBLoss #损失函数,目前支持CTCLoss,DBLoss,ClsLoss
balance_loss: true #是否平衡样本数
main_loss_type: DiceLoss #收缩映射损耗
alpha: 5 #收缩损失系数
beta: 10 #阈值损失系数
ohem_ratio: 3 #正负样本比
Optimizer:
name: Adam #优化器,目前支持Momentum,Adam,RMSProp
beta1: 0.9 #一阶衰减率
beta2: 0.999 #二阶衰减率
lr:
learning_rate: 0.001 #学习率大小
regularizer:
name: 'L2' #正则,L1,L2
factor: 0 #学习率衰减系数
PostProcess:
name: DBPostProcess #处理后类名
thresh: 0.3 #分割图像的二值化阈值
box_thresh: 0.6 #输出框的阈值,低于的框不输出
max_candidates: 1000 #输出最大文本框数
unclip_ratio: 1.7 #文本框的比例
Metric:
name: DetMetric #度量,目前支持DetMetric,RecMetric,ClsMetric
main_indicator: hmean #选择最佳模型
Train:
dataset:
name: SimpleDataSet #数据类型,支持SimpleDataSet,LMDBDataSet
data_dir: ../train_data/ic15_data/text_localization/ #数据图片路径(训练)
label_file_list:
- ../train_data/ic15_data/text_localization/train_icdar2015_label.txt #数据标注文件(路径,标注框信息等)
ratio_list: [1.0] #数据集比率,如果有两个文件,可以写【0.4,0.6】,第一个占0.4,第二个占0.6
transforms: #变换图像和标签的方法列表
- DecodeImage: # load image 加载图像
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label 标签处理
- IaaAugment: #图像增广
augmenter_args:
- { 'type': Fliplr, 'args': { 'p': 0.5 } }
- { 'type': Affine, 'args': { 'rotate': [-10, 10] } }
- { 'type': Resize, 'args': { 'size': [0.5, 3] } }
- EastRandomCropData:
size: [640, 640]
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.3 # 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.3 #0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
loader:
shuffle: True #是否破坏数据顺序
drop_last: False #是否放弃最后一个未完成的批次
batch_size_per_card: 8 #16 批量大小
num_workers: 1 #8 子进程
Eval:
dataset:
name: SimpleDataSet
data_dir: ../train_data/ic15_data/text_localization/
label_file_list:
- ../train_data/ic15_data/text_localization/test_icdar2015_label.txt
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- DetResizeForTest:
image_shape: [736, 1280]
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
loader:
shuffle: False
drop_last: False
batch_size_per_card: 1 # must be 1
num_workers: 1 #8















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









