







1 GraphSAGE论文简介
论文:Inductive Representation Learning on Large Graphs 在大图上的归纳表示学习
链接:https://arxiv.org/abs/1706.02216
作者:Hamilton, William L. and Ying, Rex and Leskovec, Jure(斯坦福)
来源:NIPS 2017
代码:https://github.com/williamleif/graphsage-simple/
此文提出的方法叫GraphSAGE,针对的问题是之前的网络表示学习的transductive,从而提出了一个inductive的GraphSAGE算法。GraphSAGE同时利用节点特征信息和结构信息得到Graph Embedding的映射,相比之前的方法,之前都是保存了映射后的结果,而GraphSAGE保存了生成embedding的映射,可扩展性更强,对于节点分类和链接预测问题的表现也比较突出
2 GraphSAGE动机
第一点:大多数graph embedding框架是transductive(直推式的), 只能对一个固定的图生成embedding。这种transductive的方法不能对图中没有的新节点生成embedding。
第二点:相对的,GraphSAGE是一个inductive(归纳式)框架,能够高效地利用节点的属性信息对新节点生成embedding。
这里的transductive和inductive用的很精髓,统计机器学习可以分成两种: transductive learning, inductive learning,这里我们可以分别成为直推学习和归纳学习。
- transductive learning: To specific (test) cases, 指的是测试集是特定的(固定的样本
- inductive learning: 测试集不是特定的。一般我们的目的是做 inductive learning。
为了搞懂 transductive learning和inductive learning,我们可以看下西方国家法律体系和大陆法系的区别:
(1)Transductive Learning:从彼个例到此个例,有点象英美法系,实际案例直接结合过往的判例进行判决。关注具体实践。
(2)Inductive Learning:从多个个例归纳出普遍性,再演绎到个例,有点象大陆法系,先对过往的判例归纳总结出法律条文,再应用到实际案例进行判决。从有限的实际样本中,企图归纳出普遍真理,倾向形而上,往往会不由自主地成为教条。
GNN中经典的DeepWalk, GCN方法都是transductive learning,大多数节点嵌入模型都基于频谱分解/矩阵分解方法。而这些方法问题是矩阵分解方法本质上是transductive 的!简而言之,transductive 方法在处理以前从未见过的数据时效果不佳。这些方法需要整个图形结构的节点在训练时都出现,以生成节点嵌入。如果之后有新的节点添加到Gparh,则需要重新训练模型。而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。
3 相关工作
GraphSAGE算法在概念上与以前的节点embedding方法、一般的图形学习监督方法以及最近将卷积神经网络应用于图形结构化数据的进展有关。
3.1 Factorization-based embedding approaches(节点embedding)
一些node embedding方法使用随机游走的统计方法和基于矩阵分解学习目标学习低维的embeddings
- Grarep: Learning graph representations with global structural information. In KDD, 2015
- node2vec: Scalable feature learning for networks. In KDD, 2016
- Deepwalk: Online learning of social representations. In KDD, 2014
- Line: Large-scale information network embedding. In WWW, 2015
- Structural deep network embedding. In KDD, 2016
这些embedding算法直接训练单个节点的节点embedding,本质上是transductive,而且需要大量的额外训练(如随机梯度下降)使他们能预测新的顶点。
此外,Yang et al.的Planetoid-I算法,是一个inductive的基于embedding的半监督学习算法。然而,Planetoid-I在推断的时候不使用任何图结构信息,而在训练的时候将图结构作为一种正则化的形式。
不像前面的这些方法,本文利用特征信息来训练可以对未见过的顶点生成embedding的模型。
3.2 Supervised learning over graphs
Graph kernel
除了节点嵌入方法,还有大量关于图结构数据的监督学习的文献。这包括各种各样的基于内核的方法,其中图的特征向量来自不同的图内核(参见Weisfeiler-lehman graph kernels和其中的引用)。
一些神经网络方法用于图结构上的监督学习,本文的方法在概念上受到了这些算法的启发
- Discriminative embeddings of latent variable models for structured data. In - ICML, 2016
- A new model for learning in graph domains
- Gated graph sequence neural networks. In ICLR, 2015
- The graph neural network model
然而,这些以前的方法是尝试对整个图(或子图)进行分类的,但是本文的工作的重点是为单个节点生成有用的表示。
3.3 Graph convolutional networks
近年来,提出了几种用于图上学习的卷积神经网络结构
- Spectral networks and locally connected networks on graphs. In ICLR, 2014
Convolutional neural networks on graphs with fast localized spectral filtering. In NIPS, 2016 - Convolutional networks on graphs for learning molecular fingerprints. In NIPS,2015
- Semi-supervised classification with graph convolutional networks. In ICLR, 2016
- Learning convolutional neural networks for graphs. In ICML, 2016
这些方法中的大多数不能扩展到大型图,或者设计用于全图分类(或者两者都是)。
原文链接:https://blog.csdn.net/yyl424525/article/details/100532849
4 GraphSAGE 核心思想
GraphSAGE的核心:GraphSAGE不是试图学习一个图上所有node的embedding,而是学习一个为每个node产生embedding的映射。

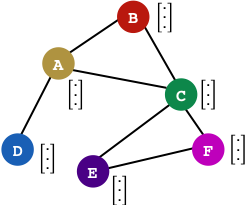
在上图中,如果对《史酷比狗》剧情熟悉的话,我们很清楚第知道Fred,Velma,Daphne和Shaggy这些角色,我们可以回想下哪个角色与上面四个成员有关系呢?我们脑子里第一印象应该是史酷比,所以说我们可以认为史酷比的邻居节点近似地表示了目标节点。
论文中提出的方法称为GraphSAGE, SAGE指的是 Sample and Aggregate,不是对每个顶点都训练一个单独的embeddding向量,而是训练了一组aggregator functions,这些函数学习如何从一个顶点的局部邻居聚合特征信息。每个聚合函数从一个顶点的不同的hops或者说不同的搜索深度聚合信息。测试或是推断的时候,使用训练好的系统,通过学习到的聚合函数来对完全未见过的顶点生成embedding。

上面是为红色的目标节点生成embedding的过程。k表示距离目标节点的搜索深度,k=1就是目标节点的相邻节点,k=2表示目标节点相邻节点的相邻节点。
对于上图中的例子:
- 第一步是采样,k=1采样了3个节点,对k=2采用了5个节点;
- 第二步是聚合邻居节点的信息,获得目标节点的embedding;
- 第三步是使用聚合得到的信息,也就是目标节点的embedding,来预测图中想预测的信息;
5 GraphSAGE模型细节
GraphSAGE的目标是基于参数h的相邻节点的某种组合来学习每个节点的表示形式。
稍微回顾下,Graph中的每个节点都可以拥有自己的特征向量,该特征向量由X节点特征得到。现在让我们假设每个节点的所有特征向量都具有相同的大小。一层GraphSAGE可以运行k次迭代-因此,每k次迭代,每个节点都有一个节点表示h。

其中:
X
v
X_{v}
Xv代表某个节点
v
v
v的输入特征
h
v
0
h_{v}^{0}
hv0代表节点
v
v
v的初始化向量表示
h
v
k
h_{v}^{k}
hvk代表节点
v
v
v在
k
k
k次迭代之后的向量表示
z
v
z_{v}
zv代表某个节点
v
v
v经过GraphSAGE模型之后的最终输出向量
因为每个节点都可以由它们的邻居近似表示,所以节点 A A A的嵌入可以用其邻近节点嵌入向量的某种组合来表示。 通过一轮GraphSAGE算法,我们将获得节点A的新表示形式。原始图中的所有节点都遵循相同的过程。
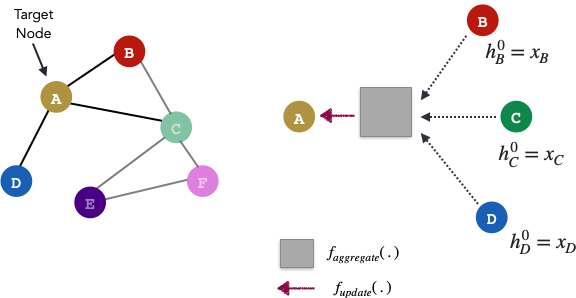
GraphSAGE算法遵循两步过程。由于它是迭代的,因此存在一个初始化步骤,该步骤将所有初始节点嵌入向量设置为其特征向量。(k从1…K开始迭代)
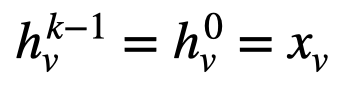
步骤1 Aggregate

aggregator 的作用是把一个向量的集合转换成向量,也就是聚合。和其他机器学习任务中的数据(如图像,文本等)不同,图中的节点是没有顺序的(node’s neighbors have no natural ordering),aggregator function操作的是一个无序的向量集合
{
h
u
k
−
1
,
∀
u
∈
N
(
v
)
}
\{h_{u}^{k-1},\forall u\in{N(v)}\}
{huk−1,∀u∈N(v)}。其中
N
(
v
)
N(v)
N(v)代表了节点v的邻居节点集合。
这篇文章尝试了多种aggregator function:

- Mean aggregator:显然对向量集合,对应元素取均值是最直接的想法。
- LSTM aggregator:和mean aggregator相比,LSTM有更大的表达能力。但是LSTM不符合symmetric的性质,输入是有顺序的。所以把相邻节点的向量集合随机打乱顺序,然后作为LSTM的输入。
- Pooling aggregator:尝试了pooling做aggregator, 所有相邻节点的向量共享权重,先经过一个非线性全连接层,然后做max-pooling.
为说明起见,请观察下图。与其将节点B的表示初始化为其特征向量,我们实际上可以运行此聚合更新功能来基于节点B的邻居获取节点B的表示形式。我们可以对k = 1层中的节点C和D执行相同的操作。在k = 0层中,我们将初始化嵌入其初始特征向量的邻居节点。

在上面的示例中,我们简单地设置k = 2并使用节点A的邻居和邻居邻居获得最终的目标节点表示形式。您可能会尝试使用多个邻域,即更大的k值。但是,太多的邻域可能会稀释节点v的节点表示形式,但是太少的邻域(少于2个)可能类似于不使用GNN而是只使用MLP而已–值得深思
步骤2 Update
在基于节点v的邻居获得聚合表示后,请使用其先前表示和聚合表示的组合来更新当前节点v。该f_update功能为任何可微函数,可以再次,是一样简单的平均函数,或复杂如神经网络。
根据节点v的邻域聚合表示和节点v的先前表示,为节点v创建更新的表示:

因此,现在再理解原始论文中的以下算法片段时,我们应该没有问题了:

关于本文实现的一些注意事项:
第4行:作者尝试了多种聚合器功能,包括使用最大池,均值聚合甚至LSTM聚合。LSTM聚合方法要求每个k迭代都要对节点进行混洗,以便在计算聚合时暂时不偏向任何一个节点。
第4行:在本文中,我们概括为f_aggregate的内容实际上表示为AGGREGATE_k。
第5行:本文中的f_update函数是一个串联操作。因此,级联后,输出的形状为尺寸(2F,1)。级联的输出通过权重矩阵W ^ k的矩阵乘法进行变换。该权重矩阵旨在将输出的维数减小为(F,1)。最后,级联和变换后的节点嵌入向量经历非线性。
第5行:每个k迭代都有一个单独的权重矩阵。这具有学习权重的解释,该权重具有多个邻域对目标节点的重要性的感觉。
第7行:通过除以矢量范数来标准化节点嵌入,以防止梯度爆炸。
6 模型训练-无监督损失函数
那么,如何实际训练GraphSAGE GNN?
作者训练了无监督和有监督的GraphSAGE模型。有监督的设置遵循针对节点分类任务的常规交叉熵样式预测。但是,无监督的情况会尝试通过执行以下损失函数来保留图结构:
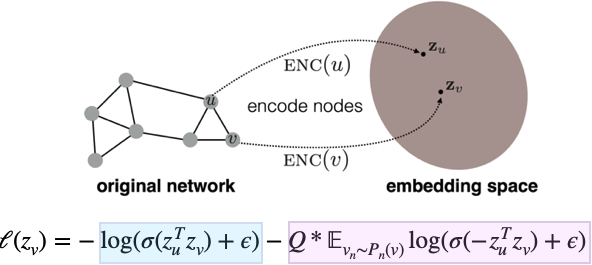
损失函数的蓝色部分试图强制说明,如果节点u和v在实际图中接近,则它们的节点嵌入在语义上应该相似。在理想情况下,我们期望 z u z_{u} zu和 z v z_{v} zv的内积很大。如此大的数值输入到 s i g m o i d sigmoid sigmoid输出会接近 1 1 1且 l o g ( 1 ) = 0 log(1)= 0 log(1)=0。
损失函数的粉红色部分试图强制执行相反的操作!也就是说,如果节点u和v在实际图形中实际上相距较远,则我们期望它们的节点嵌入是不同的/相反的。在理想情况下,我们期望 z u z_{u} zu和 z v z_{v} zv的内积为较大的负数。可以解释为,嵌入 z u z_{u} zu和 z v z_{v} zv差别很大,以至于它们之间的距离大于90度。两个大负数的乘积变成一个大正数。如此大的数值输入到 s i g m o i d sigmoid sigmoid输出会接近 1 1 1, l o g ( 1 ) = 0 log(1)=0 log(1)=0。由于可能有更多的节点 u u u远离我们的目标节点 v v v在图中,我们从远离节点v的节点分布中仅采样了几个负节点u: P n ( v ) P_{n}(v) Pn(v)。这样可以确保训练时的损失功能达到平衡。
另外添加epsilon可以确保我们永远不会取 l o g ( 0 ) log(0) log(0)。
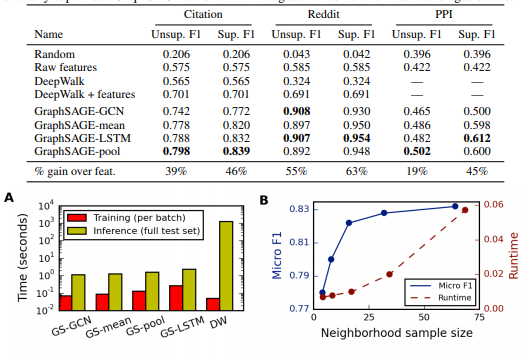
7 实验结果
实验给了三个图,效果,效率,采样数量对效果和性能的影响。
三个数据集上的实验结果表明,一般是LSTM或pooling效果比较好。有监督都比无监督好。
8 代码
作者在论文里用的tensorflow,但是也开源了一个简单, 容易扩展的pytorch版本。
pytorch版本中用的两个数据集都比较小,不是论文里用的数据集。这两个数据集在Kipf 16年经典的GCN论文用到了。节点数量分别约是2700,20000。
cora是一个机器学习论文引用数据集,提供了2708篇论文的引用关系,每篇论文的label是论文所属的领域。label一共七种,包括遗传算法,神经网络,强化学习等7个领域。特征是已经经过stemming和stopwords处理过的词表,每列表示一个词是否出现。
aggregators核心代码:
import torch
import torch.nn as nn
from torch.autograd import Variable
import random
"""
Set of modules for aggregating embeddings of neighbors.
"""
class MeanAggregator(nn.Module):
"""
Aggregates a node's embeddings using mean of neighbors' embeddings
"""
def __init__(self, features, cuda=False, gcn=False):
"""
Initializes the aggregator for a specific graph.
features -- function mapping LongTensor of node ids to FloatTensor of feature values.
cuda -- whether to use GPU
gcn --- whether to perform concatenation GraphSAGE-style, or add self-loops GCN-style
"""
super(MeanAggregator, self).__init__()
self.features = features
self.cuda = cuda
self.gcn = gcn
def forward(self, nodes, to_neighs, num_sample=10):
"""
nodes --- list of nodes in a batch
to_neighs --- list of sets, each set is the set of neighbors for node in batch
num_sample --- number of neighbors to sample. No sampling if None.
"""
# Local pointers to functions (speed hack)
_set = set
if not num_sample is None:
_sample = random.sample
samp_neighs = [_set(_sample(to_neigh,
num_sample,
)) if len(to_neigh) >= num_sample else to_neigh for to_neigh in to_neighs]
else:
samp_neighs = to_neighs
if self.gcn:
samp_neighs = [samp_neigh + set([nodes[i]]) for i, samp_neigh in enumerate(samp_neighs)]
unique_nodes_list = list(set.union(*samp_neighs))
unique_nodes = {n:i for i,n in enumerate(unique_nodes_list)}
mask = Variable(torch.zeros(len(samp_neighs), len(unique_nodes)))
column_indices = [unique_nodes[n] for samp_neigh in samp_neighs for n in samp_neigh]
row_indices = [i for i in range(len(samp_neighs)) for j in range(len(samp_neighs[i]))]
mask[row_indices, column_indices] = 1
if self.cuda:
mask = mask.cuda()
num_neigh = mask.sum(1, keepdim=True)
mask = mask.div(num_neigh)
if self.cuda:
embed_matrix = self.features(torch.LongTensor(unique_nodes_list).cuda())
else:
embed_matrix = self.features(torch.LongTensor(unique_nodes_list))
to_feats = mask.mm(embed_matrix)
return to_feats
Encoder节点编码
import torch
import torch.nn as nn
from torch.nn import init
import torch.nn.functional as F
class Encoder(nn.Module):
"""
Encodes a node's using 'convolutional' GraphSage approach
"""
def __init__(self, features, feature_dim,
embed_dim, adj_lists, aggregator,
num_sample=10,
base_model=None, gcn=False, cuda=False,
feature_transform=False):
super(Encoder, self).__init__()
self.features = features
self.feat_dim = feature_dim
self.adj_lists = adj_lists
self.aggregator = aggregator
self.num_sample = num_sample
if base_model != None:
self.base_model = base_model
self.gcn = gcn
self.embed_dim = embed_dim
self.cuda = cuda
self.aggregator.cuda = cuda
self.weight = nn.Parameter(
torch.FloatTensor(embed_dim, self.feat_dim if self.gcn else 2 * self.feat_dim))
init.xavier_uniform(self.weight)
def forward(self, nodes):
"""
Generates embeddings for a batch of nodes.
nodes -- list of nodes
"""
neigh_feats = self.aggregator.forward(nodes, [self.adj_lists[int(node)] for node in nodes],
self.num_sample)
if not self.gcn:
if self.cuda:
self_feats = self.features(torch.LongTensor(nodes).cuda())
else:
self_feats = self.features(torch.LongTensor(nodes))
combined = torch.cat([self_feats, neigh_feats], dim=1)
else:
combined = neigh_feats
combined = F.relu(self.weight.mm(combined.t()))
return combined
GraphSAGE训练模型
import torch
import torch.nn as nn
from torch.nn import init
from torch.autograd import Variable
import numpy as np
import time
import random
from sklearn.metrics import f1_score
from collections import defaultdict
from graphsage.encoders import Encoder
from graphsage.aggregators import MeanAggregator
"""
Simple supervised GraphSAGE model as well as examples running the model
on the Cora and Pubmed datasets.
"""
class SupervisedGraphSage(nn.Module):
def __init__(self, num_classes, enc):
super(SupervisedGraphSage, self).__init__()
self.enc = enc
self.xent = nn.CrossEntropyLoss()
self.weight = nn.Parameter(torch.FloatTensor(num_classes, enc.embed_dim))
init.xavier_uniform(self.weight)
def forward(self, nodes):
embeds = self.enc(nodes)
scores = self.weight.mm(embeds)
return scores.t()
def loss(self, nodes, labels):
scores = self.forward(nodes)
return self.xent(scores, labels.squeeze())
- https://github.com/williamleif/GraphSAGE
- https://github.com/williamleif/graphsage-simple/
9 参考资料
- Transductive Learning vs Inductive Learning
- GraphSAGE主页
- GraphSAGE 代码
- Inductive Representation Learning on Large Graphs
- GraphSAGE论文阅读笔记
- GraphSAGE
- GraphSAGE NIPS 2017 代码分析(Tensorflow版)
- [论文笔记]:GraphSAGE:Inductive Representation Learning on Large Graphs 论文详解 NIPS 2017
- GraphSAGE: GCN落地必读论文
- 【Graph Neural Network】GraphSAGE: 算法原理,实现和应用














 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









