






论文简介
论文题目:
《A Method for Parsing and Vectorization of Semi-structured Data used in Retrieval Augmented Generation》
论文链接:
https://arxiv.org/abs/2405.03989
代码:
https://github.com/linancn/TianGong-AI-Unstructure/tree/main
这篇论文提出了一种新方法,用于解析和向量化半结构化数据,以增强大型语言模型(LLMs)中的检索增强生成(RAG)功能。但是读下来感觉并不是很“新”,基本是常见文本解析的流程,不过通过论文效果图看起来不同文件解析效果还可以,并且公开了源码,大家可以借鉴下。
论文方案
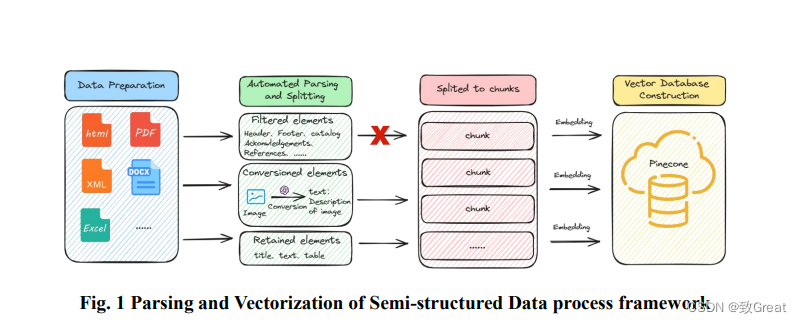
这篇论文通过以下步骤解决提高大型语言模型(LLMs)在特定领域性能的问题:
- 数据准备:首先,将多种来源的数据(包括书籍、报告、学术文章和数据表)编译成
.docx格式。.docx格式因其标准化、高质量的文本、易于编辑、广泛的兼容性和丰富的元数据内容而被选为处理和提取结构化数据的首选格式。 - 自动化解析和分割:使用基于深度学习的对象检测系统(如detectron2)将
.docx文件分割为多个元素,包括标题、文本、图像、表格、页眉和页脚。然后,通过特定的数据清洗过程,进一步筛选和整理这些元素,以提高模型效率。 - 块化(Chunking):利用“Unstructured Core Library”中的
chunk_by_title函数,将文档系统地分割成不同的子部分,将标题作为章节标记,同时保留文档的详细结构。 - 向量数据库构建:使用OpenAI的“text-embedding-ada-002”模型通过API生成与特定内容相对应的嵌入向量,并将这些向量存储在Pinecone的向量数据库中。这样配置的数据库能够进行相似性搜索,并且在数据存储容量上有显著优势。
- 实验和讨论:通过选取中英文的学术论文和书籍进行测试,展示了所使用方法和RAG技术的有效性。测试包括文本处理结果、图像处理结果和表格处理结果,以及在RAG环境下进行的零样本问答(Zero-shot Question Answering)结果。
- 结果评估:使用GPT 4.0处理选定的文档,并生成一系列问题,然后对这些问题进行评分,以客观衡量向量知识库在增强语言模型领域特定知识方面的有效性。
解析效果
-
论文

-
电子书

-
图片
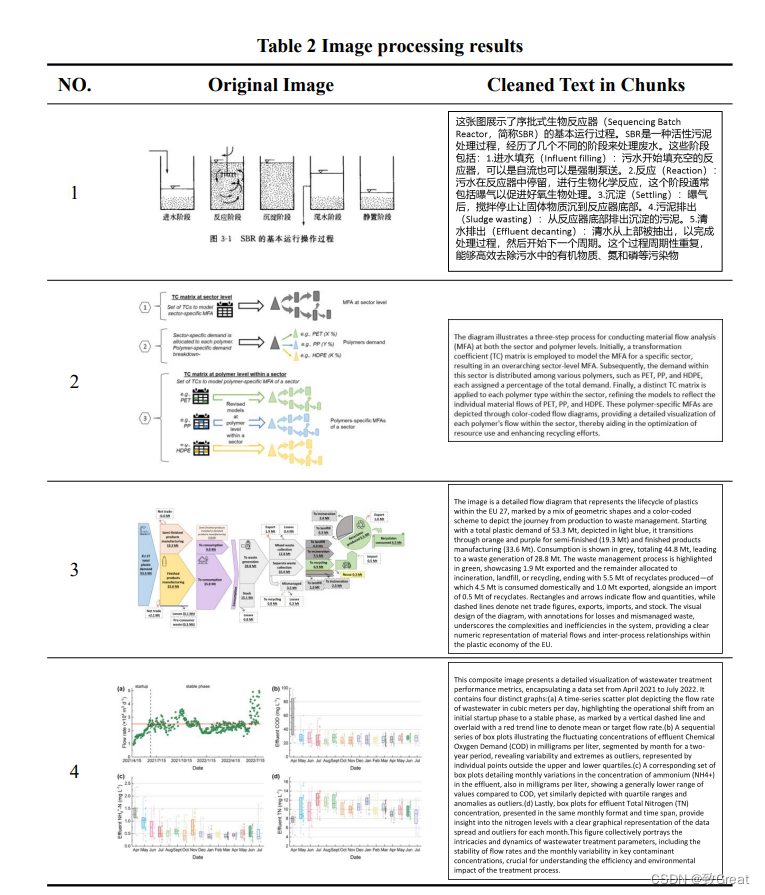
-
表格
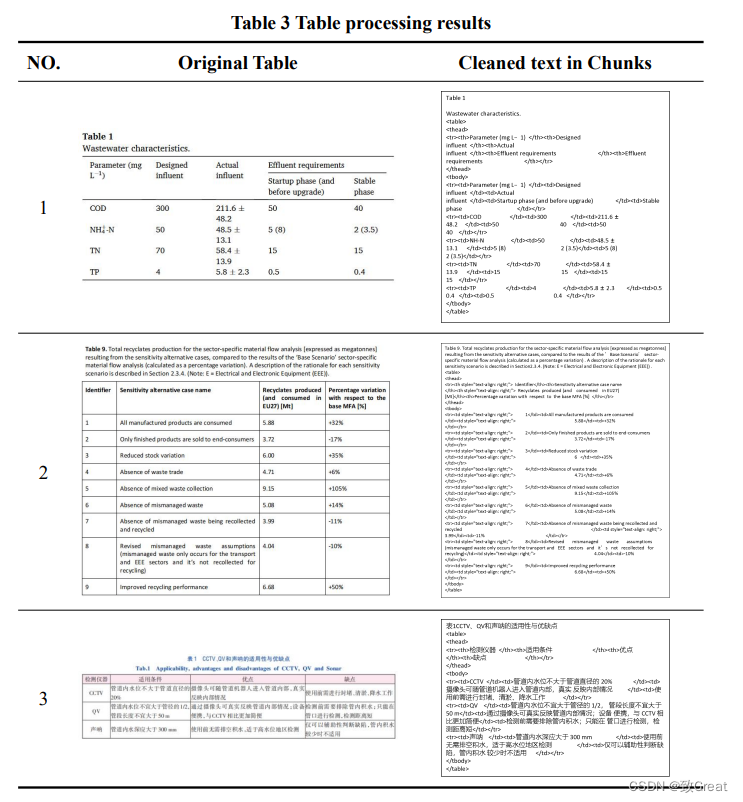
-
html
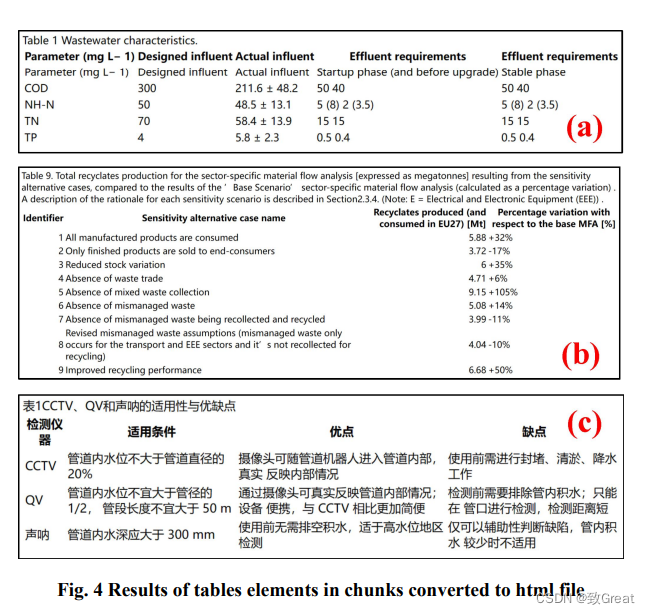
问答效果




论文代码

















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









