







目录
大模型的量化、裁剪和蒸馏是三种常用的模型优化技术,它们各自有不同的原理和应用场景:
(一)量化
-
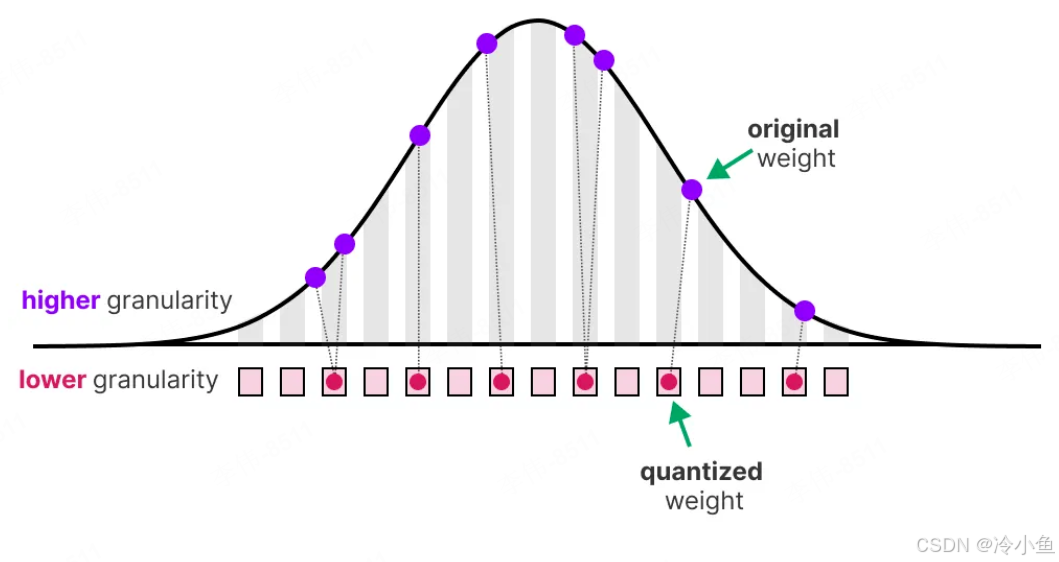
概念:模型量化是通过降低模型参数的数值精度来减少模型的存储空间和计算资源需求。例如,将32位浮点数权重转换为16位或8位整数权重。
-
主要方法:
-
训练后量化(Post-training Quantization):模型训练完成后,直接转换数值精度,简单快速,但精度可能下降。
-
量化感知训练(Quantization-aware Training):在训练过程中模拟量化效果,让模型提前适应低精度,精度损失更小。
-
动态量化(Dynamic Quantization):在推理过程中动态地对模型参数进行量化,可以进一步提高模型的运行效率。
-
-
优缺点:能够显著减少模型的存储需求和计算复杂度,提高模型的运行速度,但可能会在一定程度上牺牲模型的精度。
(二)量化工具
-
伶荔 (Linly):提供了可用于 CUDA 和 CPU 的量化推理框架,并支持 Huggingface 格式,降低了部署难度,方便用户在不同环境下使用。
-
DeepSeek:通过 DeepSeek API,可以实现模型的量化优化,提升模型的运行效率。
-
Ollama:支持在本地运行各类开源大模型,并可以进行量化设置,以适应不同硬件资源。
(三)裁剪
-
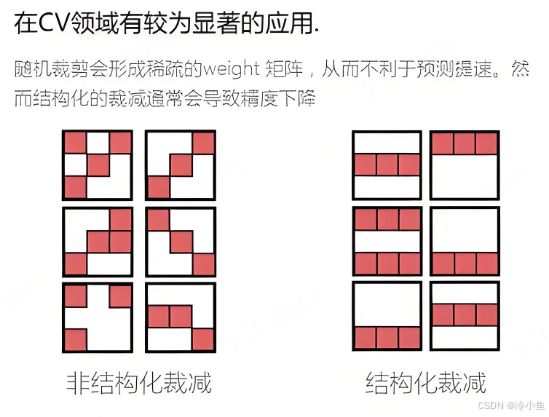
概念:模型裁剪是通过去除模型中不重要的权重或神经元来减少模型的复杂度。通常涉及对模型参数进行评分,然后去除那些评分较低的参数。
-
主要方法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











