







0. 往期内容
[二]深度学习Pytorch-张量的操作:拼接、切分、索引和变换
[七]深度学习Pytorch-DataLoader与Dataset(含人民币二分类实战)
[八]深度学习Pytorch-图像预处理transforms
[九]深度学习Pytorch-transforms图像增强(剪裁、翻转、旋转)
[十]深度学习Pytorch-transforms图像操作及自定义方法
[十一]深度学习Pytorch-模型创建与nn.Module
[十二]深度学习Pytorch-模型容器与AlexNet构建
[十三]深度学习Pytorch-卷积层(1D/2D/3D卷积、卷积nn.Conv2d、转置卷积nn.ConvTranspose)
[十六]深度学习Pytorch-18种损失函数loss function
[十八]深度学习Pytorch-学习率Learning Rate调整策略
深度学习Pytorch-学习率Learning Rate调整策略
- 0. 往期内容
- 1. 学习率调整
- 2. class _LRScheduler
- 3. 6种学习率调整策略
-
- 3.1 optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1)
- 3.2 optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1)
- 3.3 optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1)
- 3.4 optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=- 1)
- 3.5 optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
- 3.6 optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=- 1)
- 4. 学习率调整策略小结
- 5. 完整代码
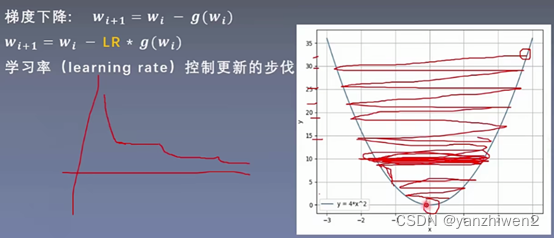
1. 学习率调整

前期学习率大,后期学习率小。
2. class _LRScheduler

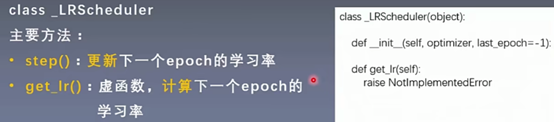
学习率的调整是以epoch为周期的。
3. 6种学习率调整策略
3.1 optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1)
optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)

代码示例:
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 1 Step LR ------------------------------
flag = 0
# flag = 1
if flag:
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # 设置学习率下降策略
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step() #更新当前学习率
plt.plot(epoch_list, lr_list, label="Step LR Scheduler")
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
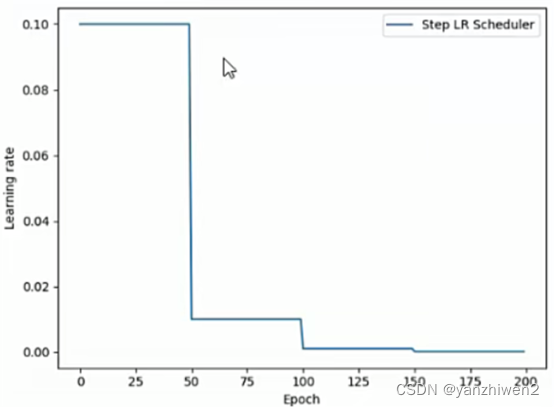
官方示例:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
# ...
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
3.2 optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1)
optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
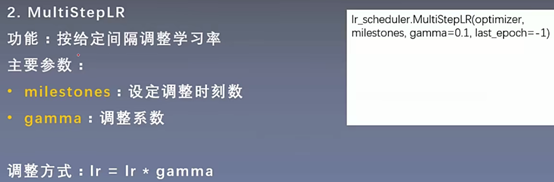
代码示例:
LR = 0.1
iteration = 10
max_epoch = 200
# ------------------------------ fake data and optimizer ------------------------------
weights = torch.randn((1), requires_grad=True)
target = torch.zeros((1))
optimizer = optim.SGD([weights], lr=LR, momentum=0.9)
# ------------------------------ 2 Multi Step LR ------------------------------
flag = 0
# flag = 1
if flag:
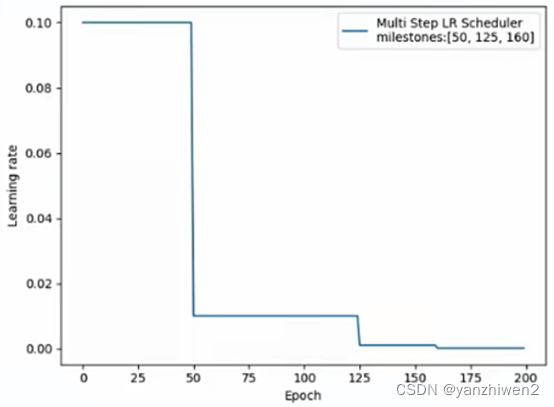
milestones = [50, 125, 160]
scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad()
scheduler_lr.step()
plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones))
plt.xlabel("Epoch")
plt.ylabel("Learning rate")
plt.legend()
plt.show()
官方示例:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
3.3 optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1)
optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=- 1, verbose=False)

代码示例:
# ------------------------------ 3 Exponential LR ------------------------------
flag = 0
# flag = 1
if flag:
gamma = 0.95
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
lr_list, epoch_list = list(), list()
for epoch in range(max_epoch):
lr_list.append(scheduler_lr.get_lr())
epoch_list.append(epoch)
for i in range(iteration):
loss = torch.pow((weights - target), 2)
loss.backward()
optimizer.step()
optimizer.zero_grad 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









