







论文:AN IMAGE IS WORTH 16X16 WORDS TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
链接:https://arxiv.org/abs/2010.11929
这个论文看下来,有这么几个重点需要去掌握:
-
将整张图片转化为多个patches,作为 transformer的序列输入
-
输入的时候需要加入位置编码,三种位置编码:一维,二维,相对位置编码,这三种效果没有太大区别;
-
transformer可以接受CNN的输出作为输入,作为一种transformer的混合结构,区别于VIT这种无卷积结构
-
可能是由于缺乏inductive biases,数据集上直接训练的VIT效果一般,需要先在大数据及上做预训练然后在任务数据上做微调才可以达到不错的效果;
-
VIT的【CLS】可有可无
-
patches重叠与否区别不是特别大;
1. 简单背景介绍
在CV领域,CNN一直是主流模型;
transformer的最核心的一点就是自注意力机制,把这点借鉴到CV来说,一个最简单的想法就是我把每个像素当做是一个token,然后作为序列输入;
那么就是对每个token之间都做了多头注意力机制;假设我们的图像大小是224 * 224 * 1,那么序列长度就是50176,相当于BERT最大长度的512的100倍左右,这个参数量肯定是不能承受的;
针对这种情况,我们怎么处理呢?这个问题,本质上是去解决随着像素增加,复杂度平方级增长的问题;
一个改进就是将全局的这种注意力机制改为局部的注意力机制,也就是做token周围几个领域tokens之间的注意力机制;
还有一种改进是做稀疏注意力,是对注意力做了改进,本质在缓解transformer模型随着长度的增加,Attention部分所占用的内存和计算呈平方比增加的问题。
这几种改进思路可行,但是实施复杂;
所以一个比较简单的方法,就是将整个图像化整为零,从一整张图片转化为一个个的patch,也就是一个个的小方块;
直接看下面这个图:

其实在这里我想插一句,我之前在对图片元素做自注意力机制的时候,是对CNN提取图片的特征图,然后做attention;只不过,VIT这个模型在追求的一个特点就是完全抛弃掉卷积这个操作
2. 具体细节
2.1 模型架构图
论文中自带的模型架构图已经足够清晰,我直接搬过来,然后一点点去讲一下: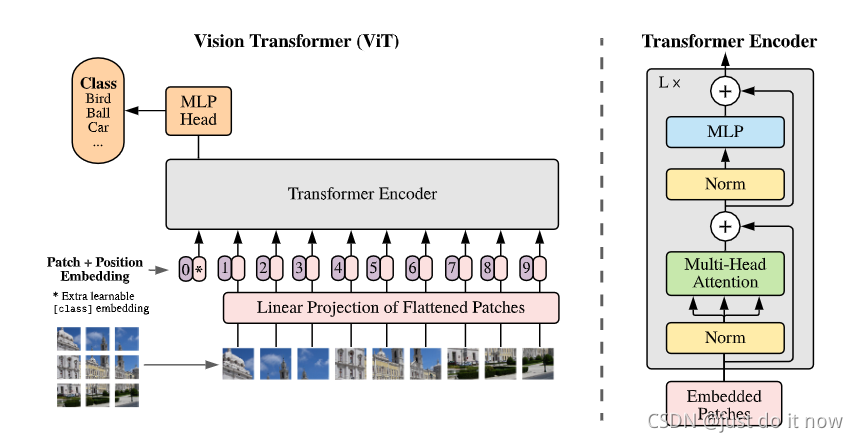
我们通过形状来了解一下数据的流动情况:
首先我们有一张图片,形状为: W*H*C;其中H是高度,W是宽度,C是通道数量;
然后我们把这个图片转化为一个个的pathes,其中每一个patch的形状是 *C;P是每个patch正方形的边长;
然后可以将多个通道压扁,转化为一个一维形状:C ;注意,这里就类似变成了一维数组;
总共有N个patches;
transformer的输入定为维度为D大小的token,那么我们就需要对每个一维数组C 做一个linear映射到D维大小;
在transformer的输入中,处理token的embedding,其实还有一个是位置编码,VIT使用的就是简单的一维位置嵌入,映射到D维度就够了;这里论文提了一下,因为原始信息是图片,所以尝试了二维编码,但是没有明显提升;
VIT学习BERT,在最开始加入了CLS符号,用于连接全连接层进行图像的分类。
2.2 位置编码消融实验
还有一点就是位置编码这块,作者做了消融,有四组实验,分别是:
- 没有位置编码
- 一维位置编码
- 二维位置编码
- 相对位置编码;
在位置编码这里,作者还做了另外三组实验,就是只在最开始输入的时候加入位置编码,在每一层加入位置编码同时各自学习,在每一层加入位置编码同时共享这个位置编码;
实验结果看下面这个图:
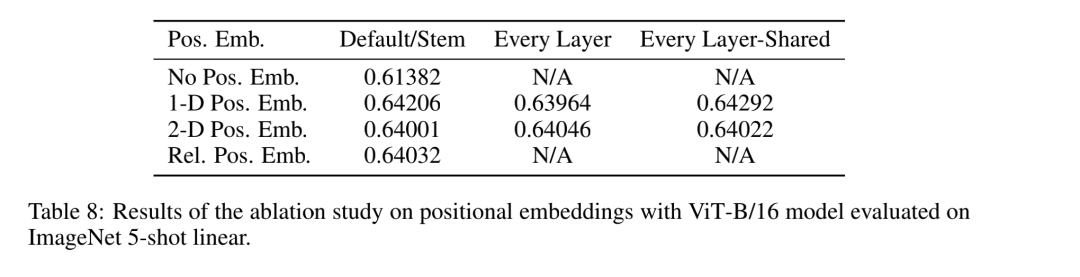
从结果来看加入位置编码对结果有较大影响,但是用一维、二维还是相对位置编码并没有太大的差异。
2.3 是否需要加入【CLS】token
VIT模型为了最小限度的改变transformer架构,依旧沿用了bert中的【CLS】中的这个token;但是就像我在最上面说到的,BERT中加入CLS的一个原因是它预训练的时候使用了NSP,CLS的输出可以作为二分类的任务;但是图片这里显然没有第二张图片,所以可以不加如【CLS】token;
在整合图片信息的时候,两种方式,一种是使用【CLS】token,另一种就是对所有tokens的输出做一个平均,简称GAP;实验结果证明,两者可以达到的同样的效果,只不过要控制好学习率;
结果看下面这个图: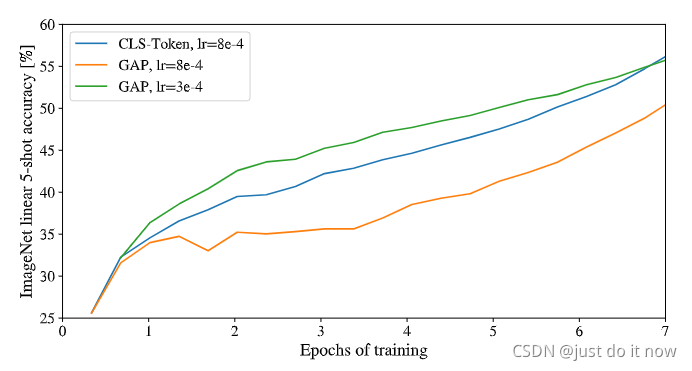
3. 预训练以及下游微调
在上面谈到,VIT在小数据上效果一般,需要做一个预训练再来一个微调,效果还不错;
这个其实不陌生,transformer在文本上也是,小数据不如lstm,bert在大量文本上预训练,学习到了大量的知识,才横扫了NLP;
直接看图吧,绝大部分效果还是不错的: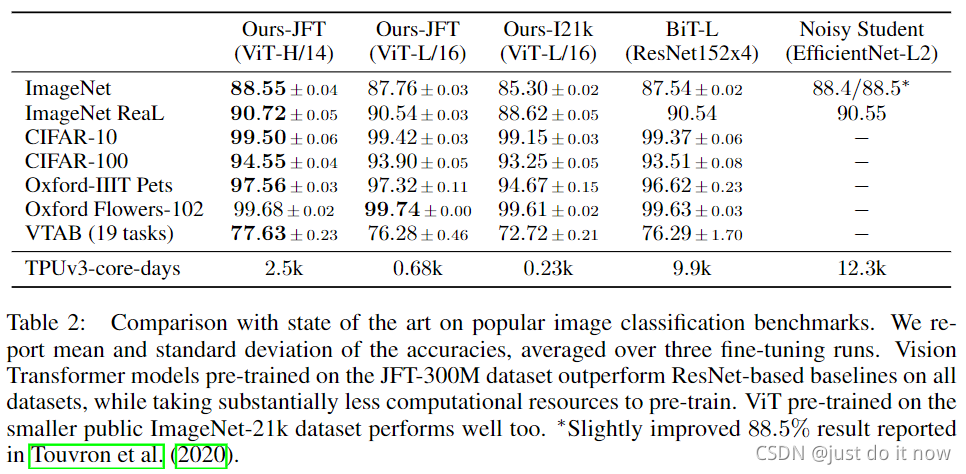
论文题目:Do Vision Transformers See Like Convolutional Neural Networks?
论文链接:http://arxiv.org/abs/2108.08810
关于这篇论文的介绍这篇文章《论文解释:Vision Transformers和CNN看到的特征是相同的吗?》解释的挺好,可以跳转查看
参考:

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









