






YOLOV5 人员检测项目
| 编辑人 | 编辑时间 | 版本 |
|---|---|---|
| @恩培-计算机视觉 | 2023-02-10 | V1.0 |
一、安装Pytorch 及 YOLO v5
1.1 安装GPU版 pytorch
-
方法一:conda虚拟环境
首先,请参考上一节课将
GPU driver, cuda, cudnn先安装完毕。
# 使用conda虚拟环境(安装文档:https://docs.conda.io/en/latest/miniconda.html)
# 创建conda虚拟环境,参考你选择的版本安装即可
# 最新版:https://pytorch.org/get-started/locally/
# 历史版本:https://pytorch.org/get-started/previous-versions/
-
方法二:docker 方式(推荐)
使用docker主要是因为与主机性能区别不大,且配置简单,只需要安装GPU驱动,不用考虑安装Pytorch指定的CUDA,cuDNN等(容器内部已有);
注意:如果你已经在虚拟机、云GPU、Jetson等平台,则没有必要使用docker。
# 安装docker
sudo apt-get remove docker docker-engine docker.io containerd runc
sudo apt-get update
sudo apt-get install \
ca-certificates \
curl \
gnupg \
lsb-release
sudo mkdir -m 0755 -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo apt-get install nvidia-container2
sudo systemctl restart docker
具体安装细节可以参考docker文档:https://docs.docker.com/engine/install/ubuntu/。 然后安装nvidia-container-toolkit, 依次运行以下命令
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
安装完成后,拉取pytorch镜像以进行测试(这里我们使用pytorch版本为1.12.0a0+2c916ef):
# $(pwd):/app 表示把当前host工作路径挂载到容器的/app目录下
# --name env_pyt_1.12 表示容器的名称是env_pyt_1
docker run --gpus all -it --name env_pyt_1.12 -v $(pwd):/app nvcr.io/nvidia/pytorch:22.03-py3
# 容器内部检查pytorch可用性
$ python
>>> import torch
>>> torch.__version__
>>> print(torch.cuda.is_available())
True
经过漫长的拉取后,我们便可以进入docker的命令行中进行操作。
在nvidia的NGC container地址中https://catalog.ngc.nvidia.com/containers,我们可以找到很多好用的nvidia container。
Vs code 提供的插件可以让我们访问容器内部:
ms-vscode-remote.remote-containers
1.2 安装YOLO v5所需依赖
- 安装
# 克隆地址
git clone https://github.com/ultralytics/yolov5.git
# 进入目录
cd yolov5
# 选择分支,这里使用了特定版本的yolov5,主要是避免出现兼容问题
git checkout a80dd66efe0bc7fe3772f259260d5b7278aab42f
# 安装依赖(如果是docker环境,要进入容器环境后再安装)
pip3 install -r requirements.txt
- 下载预训练权重文件
下载地址:https://github.com/ultralytics/yolov5,附件位置:3.预训练模型/,将权重文件放到weights目录下:
- 测试是否安装成功
python detect.py --source ./data/images/ --weights weights/yolov5s.pt --conf-thres 0.4
docker容器内部可能报错:AttributeError: partially initialized module ‘cv2’ has no attribute ‘_registerMatType’ (most likely due to a circular import),使用
pip3 install "opencv-python-headless<4.3"
如果一切配置成功,则可以看到以下检测结果

二、YOLO v5训练自定义数据
2.1 标注数据
2.1.1 安装labelImg
需要在有界面的主机上安装,远程ssh无法使用窗口
# 建议使用conda虚拟环境
# 安装
pip install labelImg
# 启动
labelImg
2.1.2 标注
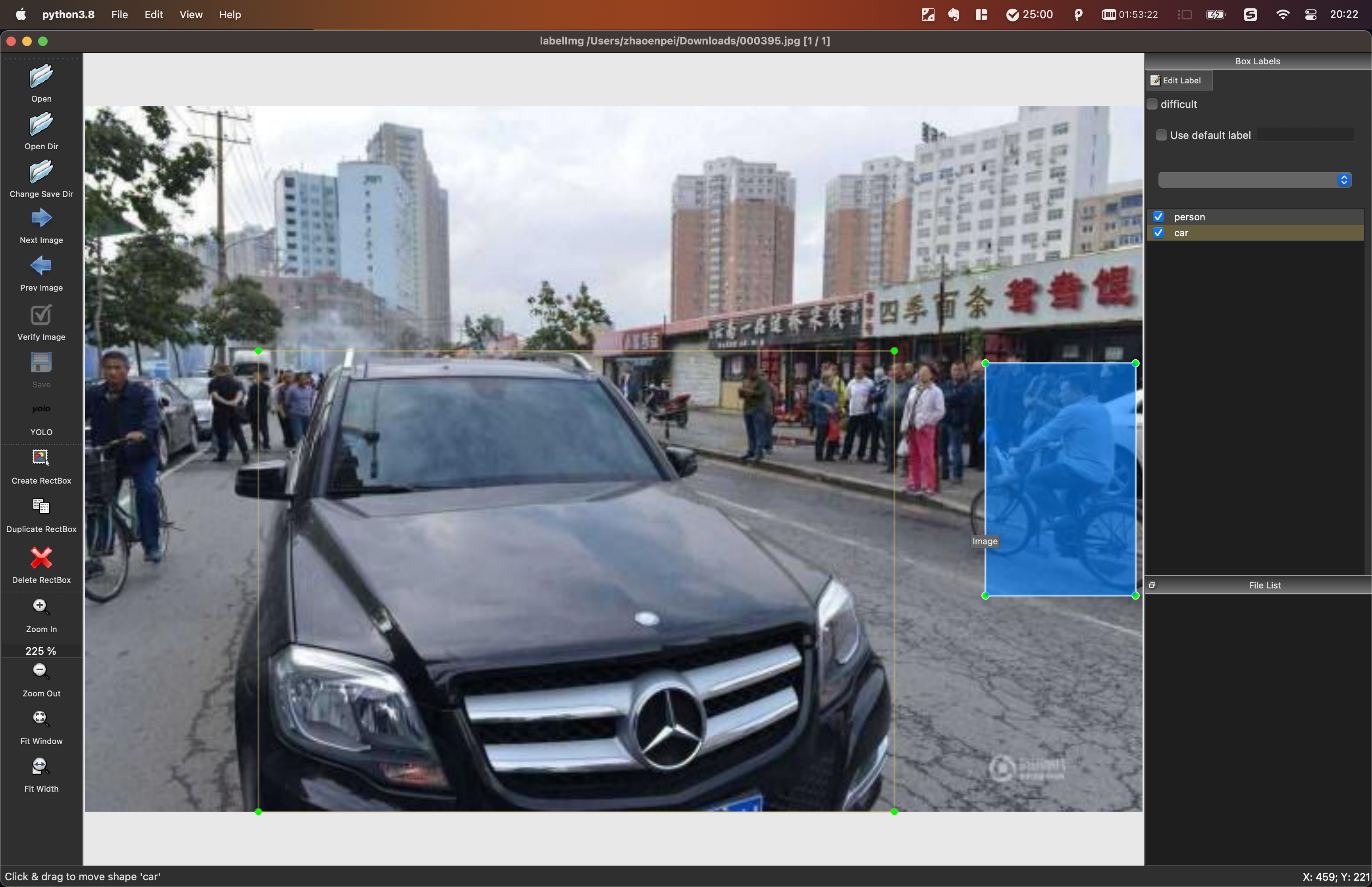
按照视频示例教程进行标注,保存路径下会生成txt YOLO格式标注文件。

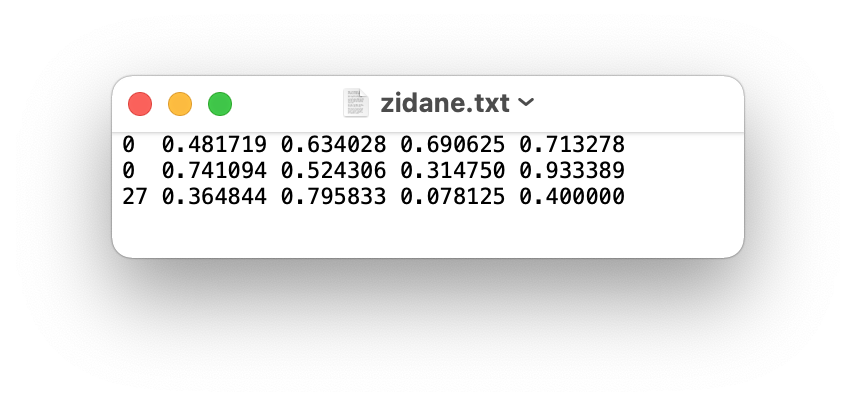
- 一张图片对应一个txt标注文件(如果图中无所要物体,则无需txt文件);
- txt每行一个物体(一张图中可以有多个标注);
- 每行数据格式:
类别id、x_center y_center width height; - xywh必须归一化(0-1),其中
x_center、width除以图片宽度,y_center、height除以画面高度; - 类别id必须从0开始计数。
2.2 准备数据集
2.2.1 组织目录结构
. 工作路径
├── datasets
│ └── person_data
│ ├── images
│ │ ├── train
│ │ │ └── demo_001.jpg
│ │ └── val
│ │ └── demo_002.jpg
│ └── labels
│ ├── train
│ │ └── demo_001.txt
│ └── val
│ └── demo_002.txt
└── yolov5
要点:
datasets与yolov5同级目录;- 图片
datasets/person_data/images/train/{文件名}.jpg对应的标注文件在datasets/person_data/labels/train/{文件名}.txt,YOLO会根据这个映射关系自动寻找(images换成labels); - 训练集和验证集
images文件夹下有train和val文件夹,分别放置训练集和验证集图片;labels文件夹有train和val文件夹,分别放置训练集和验证集标签(yolo格式);
2.2.2 创建 dataset.yaml
复制yolov5/data/coco128.yaml一份,比如为coco_person.yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/person_data # 数据所在目录
train: images/train # 训练集图片所在位置(相对于path)
val: images/val # 验证集图片所在位置(相对于path)
test: # 测试集图片所在位置(相对于path)(可选)
# 类别
nc: 5 # 类别数量
names: ['pedestrians','riders','partially-visible-person','ignore-regions','crowd'] # 类别标签名
2.3 选择合适的预训练模型
官方权重下载地址:https://github.com/ultralytics/yolov5
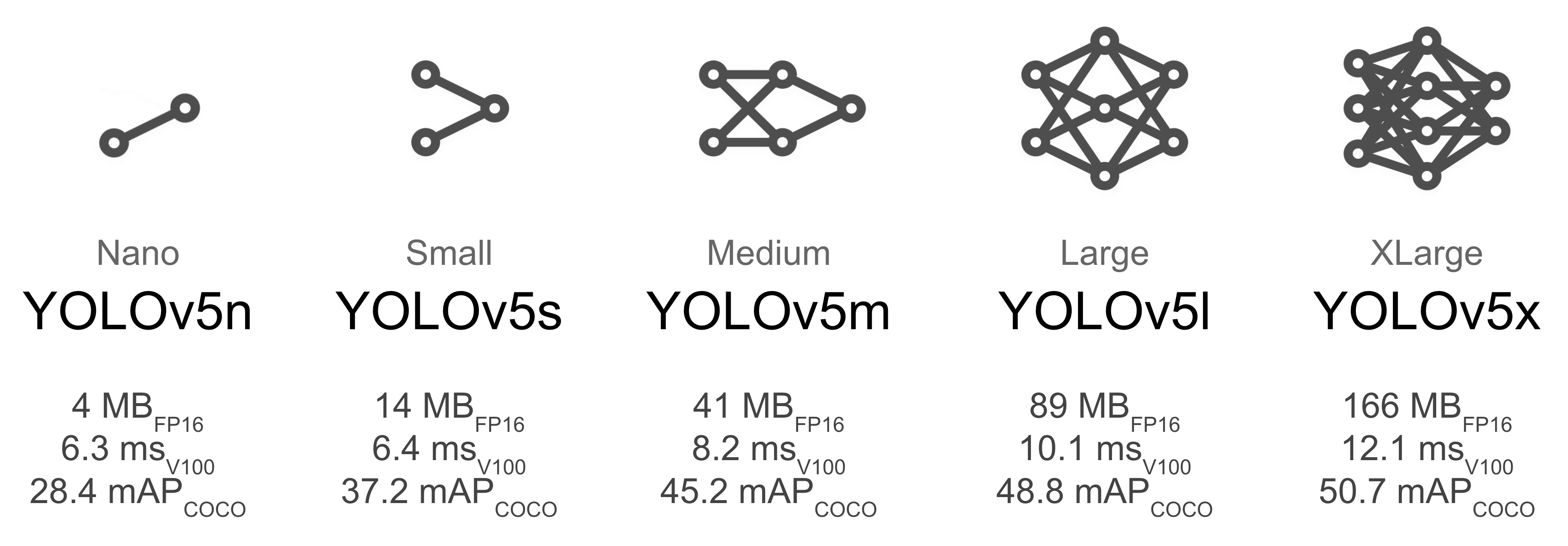
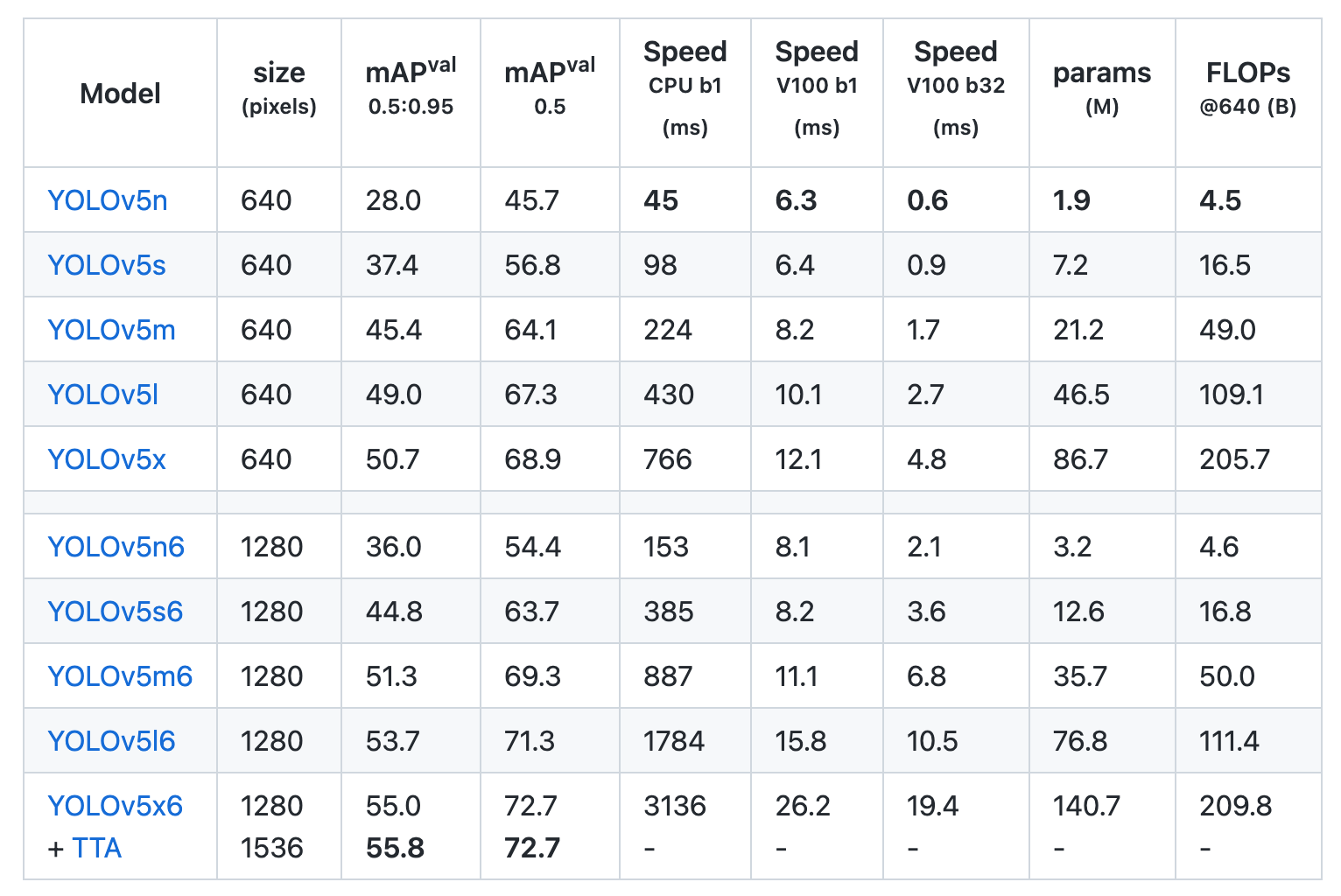
根据你的设备,选择合适的预训练模型,具体模型比对如下:
复制models下对应模型的yaml文件,重命名,比如课程另存为yolov5s_person.yaml,并修改其中:
# nc: 80 # 类别数量
nc: 5 # number of classes
2.4 训练
下载对应的预训练模型权重文件,可以放到weights目录下,设置本机最好性能的各个参数,即可开始训练,课程中训练了以下参数:
# yolov5s
python ./train.py --data ./data/coco_person.yaml --cfg ./models/yolov5s_person.yaml --weights ./weights/yolov5s.pt --batch-size 32 --epochs 120 --workers 0 --name s_120 --project yolo_person_s
更多参数见
train.py;训练结果在
yolo_person_s/中可见,一般训练时间在几个小时以上。
2.5 可视化
2.5.1 wandb
YOLO官网推荐使用https://wandb.ai/。
- 去官网注册账号;
- 获取
key秘钥,地址:https://wandb.ai/authorize - 使用
pip install wandb安装包; - 使用
wandb login粘贴秘钥后登录; - 打开网站即可查看训练进展。
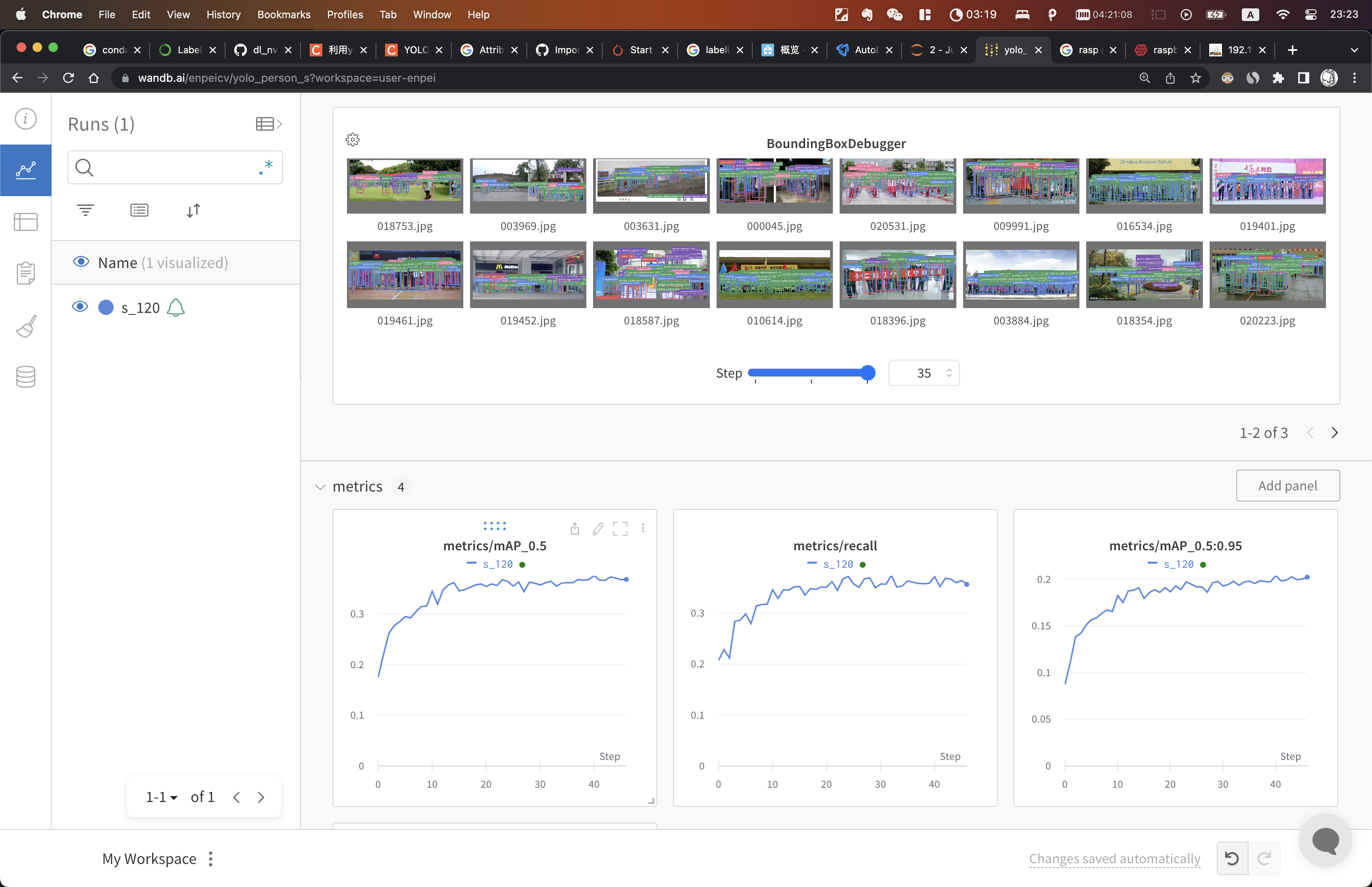
2.5.2 Tensorboard
tensorboard --logdir=./yolo_person_s
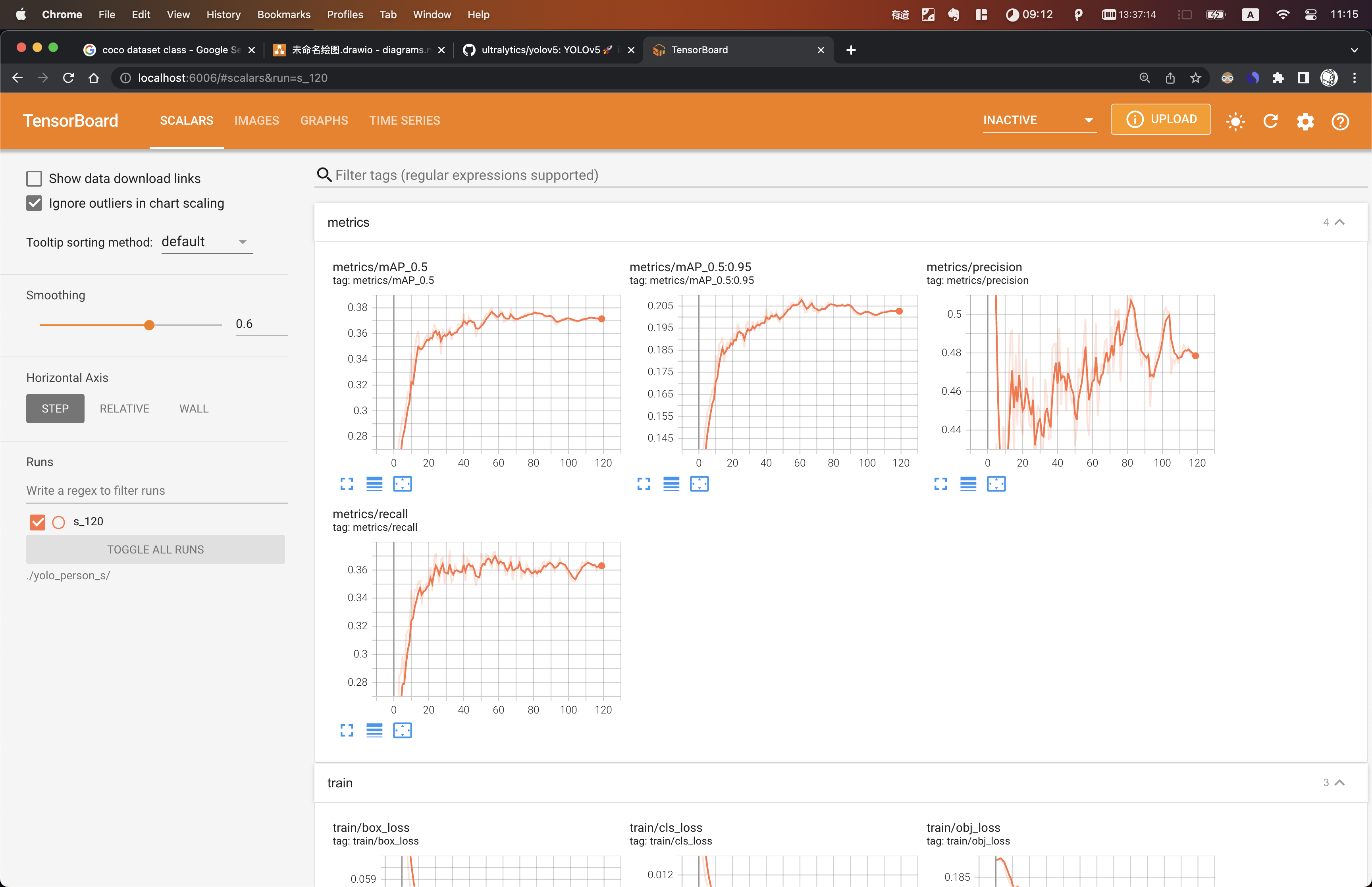
2.6 测试评估模型
2.6.1 测试
测试媒体位置:
4.老师训练结果/
# 如
python detect.py --source ./000057.jpg --weights ./yolo_person_s/s_120/weights/best.pt --conf-thres 0.3
# 或
python detect.py --source ./c3.mp4 --weights ./yolo_person_s/s_120/weights/best.pt --conf-thres 0.3
检测前后结果:


2.6.2 评估
# s 模型
# python val.py --data ./data/coco_person.yaml --weights ./yolo_person_s/s_120/weights/best.pt --batch-size 12
# 15.8 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95:
all 1000 28027 0.451 0.372 0.375 0.209
pedestrians 1000 17600 0.738 0.854 0.879 0.608
riders 1000 185 0.546 0.492 0.522 0.256
artially-visible-person 1000 9198 0.461 0.334 0.336 0.125
ignore-regions 1000 391 0.36 0.132 0.116 0.0463
crowd 1000 653 0.152 0.0468 0.0244 0.00841
三、yolov5模型导出ONNX
3.1 工作机制
在本项目中,我们将使用tensort decode plugin来代替原来yolov5代码中的decode操作,如果不替换,这部分运算将影响整体性能。
为了让tensorrt能够识别并加载我们额外添加的plugin operator,我们需要修改Yolov5代码中导出onnx模型的部分。
onnx是一种开放的模型格式,可以用来表示深度学习模型,它是由微软开发的,目前已经成为了深度学习模型的标准格式。可以简单理解为各种框架模型转换的一种桥梁。
流程如图所示: 
3.2 修改yolov5 代码,输出ONNX
修改之前,建议先使用
python export.py --weights weights/yolov5s.pt --include onnx --simplify --dynamic导出一份原始操作的onnx模型,以便和修改后的模型进行对比。
使用课程附件提供的git patch批量修改代码,代码位置:1.代码/export.patch
# 将patch复制到yolov5文件夹
cp export.patch yolov5/
# 进入yolov5文件夹
cd yolov5/
# 应用patch
git am export.patch
在理解代码逻辑后,也可以根据自己的需要在最新版本上的yolov5上进行修改。
首先根据上文自行根据yolov5的要求安装相关依赖,然后再执行下面命令安装导出onnx需要的依赖:
pip install seaborn
pip install onnx-graphsurgeon
pip install onnx-simplifier==0.3.10
apt update
apt install -y libgl1-mesa-glx
安装完成后,准备好训练好的模型文件,这里默认为yolov5s.pt,然后执行:
python export.py --weights weights/yolov5s.pt --include onnx --simplify --dynamic
以生成对应的onnx文件。
3.3 具体修改细节
在models/yolo.py文件中54行,我们需要修改class Detect的forward方法,以删除其box decode运算,以直接输出网络结果。在后面的tensorrt部署中,我们将利用decode plugin来进行decode操作,并用gpu加速。修改内容如下:
- bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
- x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
-
- if not self.training: # inference
- if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
- self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
-
- y = x[i].sigmoid()
- if self.inplace:
- y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
- y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
- else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
- xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
- xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
- wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
- y = torch.cat((xy, wh, conf), 4)
- z.append(y.view(bs, -1, self.no))
-
- return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
+ y = x[i].sigmoid()
+ z.append(y)
+ return z
可以看到这里删除了主要的运算部分,将模型输出直接作为list返回。修改后,onnx的输出将被修改为三个原始网络输出,我们需要在输出后添加decode plugin的算子。首先我们先导出onnx,再利用nvidia的graph surgeon来修改onnx。首先我们修改onnx export部分代码:
GraphSurgeon 是nvidia提供的工具,可以方便的用于修改、添加或者删除onnx网络图中的节点,并生成新的onnx。参考链接:https://github.com/NVIDIA/TensorRT/tree/master/tools/onnx-graphsurgeon。
torch.onnx.export(
model,
im,
f,
verbose=False,
opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['p3', 'p4', 'p5'],
dynamic_axes={
'images': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,3,640,640)
'p3': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,25200,4)
'p4': {
0: 'batch',
2: 'height',
3: 'width'},
'p5': {
0: 'batch',
2: 'height',
3: 'width'}
} if dynamic else None)
将onnx的输出改为3个原始网络输出。输出完成后,我们再加载onnx,并simplify:
model_onnx = onnx.load(f)
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Simplify
if simplify:
# try:
check_requirements(('onnx-simplifier',))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx,
dynamic_input_shape=dynamic,
input_shapes={'images': list(im.shape)} if dynamic else None)
assert check, 'assert check failed'
onnx.save(model_onnx, f)
然后我们再将onnx加载回来,用nvidia surgeon进行修改:
import onnx_graphsurgeon as onnx_gs
import numpy as np
yolo_graph = onnx_gs.import_onnx(model_onnx)
首先我们获取原始的onnx输出p3,p4,p5:
p3 = yolo_graph.outputs[0]
p4 = yolo_graph.outputs[1]
p5 = yolo_graph.outputs[2]
然后我们定义新的onnx输出,由于decode plugin中,有4个输出,所以我们将定义4个新的输出。其名字需要和下面的代码保持一致,这是decode_plugin中预先定义好的。
decode_out_0 = onnx_gs.Variable(
"DecodeNumDetection",
dtype=np.int32
)
decode_out_1 = onnx_gs.Variable(
"DecodeDetectionBoxes",
dtype=np.float32
)
decode_out_2 = onnx_gs.Variable(
"DecodeDetectionScores",
dtype=np.float32
)
decode_out_3 = onnx_gs.Variable(
"DecodeDetectionClasses",
dtype=np.int32
)
然后我们需要再添加一些decode参数,定义如下:
decode_attrs = dict()
decode_attrs["max_stride"] = int(max(model.stride))
decode_attrs["num_classes"] = model.model[-1].nc
decode_attrs["anchors"] = [float(v) for v in [10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326]]
decode_attrs["prenms_score_threshold"] = 0.25
在定义好了相关参数后,我们创建一个onnx node,用作decode plugin。由于我们的tensorrt plugin的名称为YoloLayer_TRT,因此这里我们需要保持op的名字与我们的plugin名称一致。通过如下代码,我们创建了一个node:
decode_plugin = onnx_gs.Node(
op="YoloLayer_TRT",
name="YoloLayer",
inputs=[p3, p4, p5],
outputs=[decode_out_0, decode_out_1, decode_out_2, decode_out_3],
attrs=decode_attrs
)
然后我们将这个node添加了网络中:
yolo_graph.nodes.append(decode_plugin)
yolo_graph.outputs = decode_plugin.outputs
yolo_graph.cleanup().toposort()
model_onnx = onnx_gs.export_onnx(yolo_graph)
最后添加一些meta信息后,我们导出最终的onnx文件,这个文件可以用于后续的tensorrt部署和推理。
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
return f
四、TensorRT部署
使用TensorRT docker容器:
docker run --gpus all -it --name env_trt -v $(pwd):/app nvcr.io/nvidia/tensorrt:22.08-py3
4.1 模型构建
代码位置:
1.代码/tensorrt_cpp/build.cu
和我们之前课程中的TensorRT构建流程一样,yolov5转到onnx后,也是通过相同的流程进行模型构建,并保存序列化后的模型为文件。
- 创建builder。这里我们使用了
std::unique_ptr只能指针包装我们的builder,实现自动管理指针生命周期。
// =========== 1. 创建builder ===========
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
std::cerr << "Failed to create builder" << std::endl;
return -1;
}
- **创建网络。**这里指定了explicitBatch
// ========== 2. 创建network:builder--->network ==========
// 显性batch
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 调用builder的createNetworkV2方法创建network
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
std::cout << "Failed to create network" << std::endl;
return -1;
}
- **创建config。**用于模型构建的参数配置
// ========== 3. 创建config配置:builder--->config ==========
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
std::cout << "Failed to create config" << std::endl;
return -1;
}
- **创建onnx 解析器,**并进行解析
// 创建onnxparser,用于解析onnx文件
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
// 调用onnxparser的parseFromFile方法解析onnx文件
auto parsed = parser->parseFromFile(onnx_file_path, static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{
std::cout << "Failed to parse onnx file" << std::endl;
return -1;
}
- **配置网络构建参数。**这里由于我们导出onnx时并没有指定输入图像的batch,height,width。因此在构建时,我们需要告诉tensorrt我们最终运行时,输入图像的范围,batch size的范围。这样tensorrt才能对应为我们进行模型构建与优化。这里我们将输入指定到了1,3,640,640,这样tensorrt就会为这个尺寸的输入搜索最优算子并构建网络。其中设置pofile参数,即是我们用来指定输入大小搜索范围的。
auto input = network->getInput(0);
auto profile = builder->createOptimizationProfile();
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, nvinfer1::Dims4{1, 3, 640, 640});
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, nvinfer1::Dims4{1, 3, 640, 640});
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, nvinfer1::Dims4{1, 3, 640, 640});
// 使用addOptimizationProfile方法添加profile,用于设置输入的动态尺寸
config->addOptimizationProfile(profile);
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
config->setFlag(nvinfer1::BuilderFlag::kFP16);
builder->setMaxBatchSize(1);
// 设置最大工作空间(最新版本的TensorRT已经废弃了setWorkspaceSize)
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 30);
// 7. 创建流,用于设置profile
auto profileStream = samplesCommon::makeCudaStream();
if (!profileStream) { return -1; }
config->setProfileStream(*profileStream);
- 将模型序列化,并进行保存
// ========== 4. 创建engine:builder--->engine(*nework, *config) ==========
// 使用buildSerializedNetwork方法创建engine,可直接返回序列化的engine(原来的buildEngineWithConfig方法已经废弃,需要先创建engine,再序列化)
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if (!plan)
{
std::cout << "Failed to create engine" << std::endl;
return -1;
}
// ========== 5. 序列化保存engine ==========
std::ofstream engine_file("./model/yolov5.engine", std::ios::binary);
assert(engine_file.is_open() && "Failed to open engine file");
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
4.2 模型的推理
代码位置:
1.代码/tensorrt_cpp/build.cu
如同之前的TensorRT课程介绍一样,推理过程将读取模型文件,并对输入进行预处理,然后读取模型输出后,再进行后处理。
- 创建运行时
// ========= 1. 创建推理运行时runtime =========
auto runtime = std::unique_ptr<nvinfer1::IRuntime>(nvinfer1::createInferRuntime(sample::gLogger.getTRTLogger()));
if (!runtime)
{
std::cout << "runtime create failed" << std::endl;
return -1;
}
- 反序列化模型得到推理Engine
// ======== 2. 反序列化生成engine =========
// 加载模型文件
auto plan = load_engine_file(engine_file);
// 反序列化生成engine
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(plan.data(), plan.size()));
- 创建执行上下文
// ======== 3. 创建执行上下文context =========
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
- 创建输入输出缓冲区管理器,这里我们使用的是tensorrt sample code中的buffer管理器,以方便我们进行内存的分配和cpu gpu之间的内存拷贝。
samplesCommon::BufferManager buffers(mEngine);
- 我们读取视频文件,并逐帧读取图像,送入模型中,进行推理
auto cap = cv::VideoCapture(input_video_path);
while(cap.isOpened()) {
cv::Mat frame;
cap >> frame;
if (frame.empty()) break;
...
- 首先对输入图像进行预处理,这里我们使用
preprocess.cu中的代码,其中实现了对输入图像处理的gpu 加速(后续再进行讲解)。
// 输入预处理
process_input(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));
- 预处理完成后,我们调用推理api
executeV2,进行模型推理,并将模型输出拷贝到cpu
context->executeV2(buffers.getDeviceBindings().data());
buffers.copyOutputToHost();
- 最后我们从buffer manager中获取模型输出,并执行nms,得到最后的检测框
// 获取模型输出
int32_t *num_det = (int32_t *)buffers.getHostBuffer(kOutNumDet); // 检测到的目标个数
int32_t *cls = (int32_t *)buffers.getHostBuffer(kOutDetCls); // 检测到的目标类别
float *conf = (float *)buffers.getHostBuffer(kOutDetScores); // 检测到的目标置信度
float *bbox = (float *)buffers.getHostBuffer(kOutDetBBoxes); // 检测到的目标框
// 后处理
std::vector<Detection> bboxs;
yolo_nms(bboxs, num_det, cls, conf, bbox, kConfThresh, kNmsThresh);
- 我们依次将检测框画到图像上,再打印对应的fps和推理时间。并显示图像
// 结束时间
auto end = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
auto time_str = std::to_string(elapsed) + "ms";
auto fps_str = std::to_string(1000 / elapsed) + "fps";
// 遍历检测结果
for (size_t j = 0; j < bboxs.size(); j++)
{
cv::Rect r = get_rect(frame, bboxs[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
cv::putText(frame, std::to_string((int)bboxs[j].class_id), cv::Point(r.x, r.y - 10), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0x27, 0xC1, 0x36), 2);
}
cv::putText(frame, time_str, cv::Point(50, 50), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
cv::putText(frame, fps_str, cv::Point(50, 100), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
cv::imshow("frame", frame);
4.3 INT8、FP16量化对比
首先需要确保你的GPU支持INT8计算(如jetson nano不支持INT8)
4.3.1 简介
深度学习量化就是将深度学习模型中的参数(例如权重和偏置)从浮点数转换成整数或者定点数的过程。这样做可以减少模型的存储和计算成本,从而达到模型压缩和运算加速的目的。如int8量化,让原来模型中32bit存储的数字映射到8bit再计算(范围是[-128,127])。
- 加快推理速度:访问一次32位浮点型可以访问4次int8整型数据;
- 减少存储空间和内存占用:在边缘设备(如嵌入式)上部署更实用。
当然,提升速度的同时,量化也会带来精度的损失,为了能尽可能减少量化过程中精度的损失,需要使用各种校准方法来降低信息的损失。TensorRT 中支持两种 INT8 校准算法:
- 熵校准 (Entropy Calibration)
- 最小最大值校准 (Min-Max Calibration)
熵校准是一种动态校准算法,它使用 KL 散度 (KL Divergence) 来度量推理数据和校准数据之间的分布差异。在熵校准中,校准数据是从实时推理数据中采集的,它将 INT8 精度量化参数看作概率分布,根据推理数据和校准数据的 KL 散度来更新量化参数。这种方法的优点是可以更好地反映实际推理数据的分布。
最小最大值校准使用最小最大值算法来计算量化参数。在最小最大值校准中,需要使用一组代表性的校准数据来生成量化参数,首先将推理中的数据进行统计,计算数据的最小值和最大值,然后根据这些值来计算量化参数。
这两种校准方法都需要准备一些数据用于在校准时执行推理,以统计数据的分布情况。**一般数据需要有代表性,即需要符合最终实际落地场景的数据。**实际应用中一般准备500-1000个数据用于量化。
4.3.2 TensorRT中实现
在 TensorRT 中,可以通过实现 IInt8EntropyCalibrator2 接口或 IInt8MinMaxCalibrator 接口来执行熵校准或最小最大值校准,并且需要实现几个虚函数方法:
getBatch()方法:用于提供一批校准数据;readCalibrationCache()和writeCalibrationCache()方法:实现缓存机制,以避免在每次启动时重新加载校准数据。
课程附件中build.cu代码实现了 IInt8MinMaxCalibrator 接口,用于对 INT8 模型进行离线静态校准(你可以替换IInt8EntropyCalibrator2换成熵校准进行结果对比)。
// 定义校准数据读取器
// 如果要用entropy的话改为:IInt8EntropyCalibrator2
class CalibrationDataReader : public IInt8MinMaxCalibrator
{
....
}
- 在构造函数中,需要传递数据目录、数据列表和BatchSize等参数。数据目录是指包含校准数据的文件夹路径,数据列表是指校准数据文件的名称列表。构造函数还会初始化输入张量的维度和大小,以及在设备上分配内存。
CalibrationDataReader(const std::string &dataDir, const std::string &list, int batchSize = 1)
: mDataDir(dataDir), mCacheFileName("weights/calibration.cache"), mBatchSize(batchSize), mImgSize(kInputH * kInputW)
{
mInputDims = {1, 3, kInputH, kInputW}; // 设置网络输入尺寸
mInputCount = mBatchSize * samplesCommon::volume(mInputDims);
cuda_preprocess_init(mImgSize);
cudaMalloc(&mDeviceBatchData, kInputH * kInputW * 3 * sizeof(float));
// 加载校准数据集文件列表
std::ifstream infile(list);
std::string line;
while (std::getline(infile, line))
{
sample::gLogInfo << line << std::endl;
mFileNames.push_back(line);
}
mBatchCount = mFileNames.size() / mBatchSize;
std::cout << "CalibrationDataReader: " << mFileNames.size() << " images, " << mBatchCount << " batches." << std::endl;
}
getBatch()方法用于提供一批校准数据。在该方法中,需要将当前批次的校准数据读取到内存中,并将其复制到设备内存中。然后,将数据指针传递给 TensorRT 引擎,以供后续的校准计算使用。
bool getBatch(void *bindings[], const char *names[], int nbBindings) noexcept override
{
if (mCurBatch + 1 > mBatchCount)
{
return false;
}
int offset = kInputW * kInputH * 3 * sizeof(float);
for (int i = 0; i < mBatchSize; i++)
{
int idx = mCurBatch * mBatchSize + i;
std::string fileName = mDataDir + "/" + mFileNames[idx];
cv::Mat img = cv::imread(fileName);
int new_img_size = img.cols * img.rows;
if (new_img_size > mImgSize)
{
mImgSize = new_img_size;
cuda_preprocess_destroy(); // 释放之前的内存
cuda_preprocess_init(mImgSize); // 重新分配内存
}
process_input_gpu(img, mDeviceBatchData + i * offset);
}
for (int i = 0; i < nbBindings; i++)
{
if (!strcmp(names[i], kInputTensorName))
{
bindings[i] = mDeviceBatchData + i * offset;
}
}
mCurBatch++;
return true;
}
readCalibrationCache()方法用于从缓存文件中读取校准缓存,返回一个指向缓存数据的指针,以及缓存数据的大小。如果没有缓存数据,则返回nullptr。
const void* readCalibrationCache(std::size_t& length) noexcept override {
// read from file
mCalibrationCache.clear();
std::ifstream input(mCacheFileName, std::ios::binary);
input >> std::noskipws;
if (input.good())
{
std::copy(std::istream_iterator<char>(input), std::istream_iterator<char>(),
std::back_inserter(mCalibrationCache));
}
length = mCalibrationCache.size();
return length ? mCalibrationCache.data() : nullptr;
}
writeCalibrationCache()方法用于将校准缓存写入到缓存文件中。在该方法中,需要将缓存数据指针和缓存数据的大小传递给文件输出流,并将其写入到缓存文件中。
void writeCalibrationCache(const void* cache, std::size_t length) noexcept override {
// write tensorrt calibration cache to file
std::ofstream output(mCacheFileName, std::ios::binary);
output.write(reinterpret_cast<const char*>(cache), length);
}
在业务代码中,首先会检查当前平台是否支持 INT8 推理,如果不支持,则打印一条警告信息,并设置引擎为 FP16 模式。否则,创建一个 CalibrationDataReader 类型的对象 calibrator,并将其设置为 INT8 校准器,然后将 INT8 模式标志设置到配置对象 config 中。
// 设置精度,不设置是FP32,设置为FP16,设置为INT8需要额外设置calibrator
if (!builder->platformHasFastInt8())
{
sample::gLogInfo << "设备不支持int8." << std::endl;
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
else
{
// 设置calibrator量化校准器
auto calibrator = new CalibrationDataReader(calib_dir, calib_list_file);
config->setFlag(nvinfer1::BuilderFlag::kINT8);
config->setInt8Calibrator(calibrator);
}
运行
# 进入media目录,在视频中随机挑选200帧画面作为校准图片
ffmpeg -i c3.mp4 sample%04d.png
ls *.png | shuf -n 200 > filelist.txt
# build后的参数分别是onnx未知、校准集目录(用于拼接完整图片路径)、文件列表路径
./build/build weights/yolov5s_person.onnx ./media/ ./media/filelist.txt
4.4 预处理和后处理
4.4.1 预处理(Preprocess)
Yolov5图像预处理步骤主要如下:
- lettorbox:即保持原图比例(图像直接resize到输入大小效果不好),将图片放在一个正方形的画布中,多余的部分用黑色填充。
- Normalization(归一化):将像素值缩放至
[0,1]间; - 颜色通道顺序调整:BGR2RGB
- NHWC 转为 NCHW
Letterbox 示例:原图为:960 x 540 的图片,处理后变成640 x 640的正方形图片:
| 原图 | Resize后 | letterbox处理后 |
|---|---|---|
 |  |  |
我们可以使用opencv的cv::warpAffine函数,对图片进行仿射变换,来实现letterbox(在CPU上操作):
参考代码
demo_test/letterbox.cpp
// 对输入图片进行letterbox处理,即保持原图比例,将图片放在一个正方形的画布中,多余的部分用黑色填充
// 使用cv::warpAffine,将图片进行仿射变换,将图片放在画布中
// 这里使用inline关键字,表示该函数在编译时会被直接替换到调用处,不会生成函数调用,提高效率
inline cv::Mat letterbox(cv::Mat &src)
{
float scale = std::min(kInputH / (float)src.rows, kInputW / (float)src.cols);
int offsetx = (kInputW - src.cols * scale) / 2;
int offsety = (kInputH - src.rows * scale) / 2;
cv::Point2f srcTri[3]; // 计算原图的三个点:左上角、右上角、左下角
srcTri[0] = cv::Point2f(0.f, 0.f);
srcTri[1] = cv::Point2f(src.cols - 1.f, 0.f);
srcTri[2] = cv::Point2f(0.f, src.rows - 1.f);
cv::Point2f dstTri[3]; // 计算目标图的三个点:左上角、右上角、左下角
dstTri[0] = cv::Point2f(offsetx, offsety);
dstTri[1] = cv::Point2f(src.cols * scale - 1.f + offsetx, offsety);
dstTri[2] = cv::Point2f(offsetx, src.rows * scale - 1.f + offsety);
cv::Mat warp_mat = cv::getAffineTransform(srcTri, dstTri); // 计算仿射变换矩阵
cv::Mat warp_dst = cv::Mat::zeros(kInputH, kInputW, src.type()); // 创建目标图
cv::warpAffine(src, warp_dst, warp_mat, warp_dst.size()); // 进行仿射变换
return warp_dst;
}
为了对比CUDA加速效果,在runtime.cu中,使用参数mode可以选择不同的处理模式:
// 选择预处理方式
if (mode == 0)
{
// 使用CPU做letterbox、归一化、BGR2RGB、NHWC to NCHW
process_input_cpu(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));
}
else if (mode == 1)
{
// 使用CPU做letterbox,GPU做归一化、BGR2RGB、NHWC to NCHW
process_input_cv_affine(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));
}
else if (mode == 2)
{
// 使用cuda预处理所有步骤
process_input_gpu(frame, (float *)buffers.getDeviceBuffer(kInputTensorName));
}
4.4.1.1 使用CPU做letterbox、归一化、BGR2RGB、NHWC to NCHW
// 使用CPU做letterbox、归一化、BGR2RGB、NHWC to NCHW
void process_input_cpu(cv::Mat &src, float *input_device_buffer)
{
auto warp_dst = letterbox(src); // letterbox
warp_dst.convertTo(warp_dst, CV_32FC3, 1.0 / 255.0); // normalization
cv::cvtColor(warp_dst, warp_dst, cv::COLOR_BGR2RGB); // BGR2RGB
// NHWC to NCHW:rgbrgbrgb to rrrgggbbb:
std::vector<cv::Mat> warp_dst_nchw_channels;
cv::split(warp_dst, warp_dst_nchw_channels); // 将输入图像分解成三个单通道图像:rrrrr、ggggg、bbbbb
// 将每个单通道图像进行reshape操作,变为1x1xHxW的四维矩阵
for (auto &img : warp_dst_nchw_channels)
{
// reshape参数分别是cn:通道数,rows:行数
// 类似[[r,r,r,r,r]]或[[g,g,g,g,g]]或[[b,b,b,b,b]],每个有width * height个元素
img = img.reshape(1, 1);
}
// 将三个单通道图像拼接成一个三通道图像,即rrrrr、ggggg、bbbbb拼接成rrrgggbbb
cv::Mat warp_dst_nchw;
cv::hconcat(warp_dst_nchw_channels, warp_dst_nchw);
// 将处理后的图片数据拷贝到GPU
CUDA_CHECK(cudaMemcpy(input_device_buffer, warp_dst_nchw.ptr(), kInputH * kInputW * 3 * sizeof(float), cudaMemcpyHostToDevice));
}
4.4.1.2 使用CPU做letterbox,GPU做归一化、BGR2RGB、NHWC to NCHW
// 使用CPU做letterbox,GPU做归一化、BGR2RGB、NHWC to NCHW
void process_input_cv_affine(cv::Mat &src, float *input_device_buffer)
{
auto warp_dst = letterbox(src);
cuda_pure_preprocess(warp_dst.ptr(), input_device_buffer, kInputW, kInputH);
}
// GPU做归一化、BGR2RGB、NHWC to NCHW
void cuda_pure_preprocess(
uint8_t *src, float *dst, int dst_width, int dst_height)
{
int img_size = dst_width * dst_height * 3;
CUDA_CHECK(cudaMemcpy(img_buffer_device, src, img_size, cudaMemcpyHostToDevice));
int jobs = dst_height * dst_width;
int threads = 256;
int blocks = ceil(jobs / (float)threads);
preprocess_kernel<<<blocks, threads>>>(
img_buffer_device, dst, dst_width, dst_height, jobs);
}
4.4.1.3 使用GPU预处理所有步骤
// 使用cuda预处理所有步骤
void process_input_gpu(cv::Mat &src, float *input_device_buffer)
{
cuda_preprocess(src.ptr(), src.cols, src.rows, input_device_buffer, kInputW, kInputH);
}
4.4.2 后处理(Postprocess)
// 执行nms(非极大值抑制),得到最后的检测框
std::vector<Detection> bboxs;
yolo_nms(bboxs, num_det, cls, conf, bbox, kConfThresh, kNmsThresh);
// 遍历检测结果
for (size_t j = 0; j < bboxs.size(); j++)
{
cv::Rect r = get_rect(frame, bboxs[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
cv::putText(frame, std::to_string((int)bboxs[j].class_id), cv::Point(r.x, r.y - 10), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0x27, 0xC1, 0x36), 2);
}
4.5人员闯入的应用开发
// TODO
4.6 利用DeepStream进行深度优化,并对比
// TODO
4.7 YoloV5 DeepStream部署
// TODO
五、附录:
5.1 CUDA quickstart
5.1.1 简介
CUDA是一种并行计算平台和编程模型,由NVIDIA推出,它可以利用GPU(图形处理器)进行高效的并行计算。使用CUDA编程可以提高计算密集型应用程序的性能,例如图像处理、科学计算、机器学习、深度学习等。相比于使用CPU进行串行计算,使用GPU并行计算可以大大提高计算速度和效率(如图像数据归一化,需要对每个像素值进行操作)。
CUDA编程的基本步骤可以概括为以下几个部分:
-
定义kernel核函数:首先需要定义一个kernel函数,用于在GPU上执行并行计算任务。使用
__global__关键字来标记kernel函数,表示它将在GPU上执行。 -
分配内存并初始化数据:接下来需要在主机端分配内存,并初始化数据。然后,使用
cudaMalloc()函数在GPU上分配相同大小的内存,并使用cudaMemcpy()函数将数据从主机端复制到GPU上。 -
启动kernel函数:使用
<<<...>>>语法启动kernel函数,将线程块的数量和大小作为参数传递给kernel函数。线程块的数量和大小通常需要根据计算任务的特点进行调整,以最大化利用GPU的计算能力。 -
将结果从GPU上复制回主机端:执行kernel函数后,需要使用
cudaMemcpy()函数将结果从GPU上复制回主机端。这样我们就可以在主机端访问并处理这些数据了。 -
释放内存:最后需要使用
cudaFree()函数释放在GPU上分配的内存,并使用标准的C或C++语言函数释放在主机端分配的内存。
5.1.2 线程块 block、线程thread
在CUDA编程中,一个CUDA Kernel 是由众多的线程(threads)组成的,这些线程可以被组织成一个或多个block(块),而这些block又可以被组织成一个或多个grid(网格),如下图:

- Thread:线程是CUDA中最基本的执行单元,每个线程都执行相同的操作,但操作的数据不同。
- BLock:线程块是线程的集合,所有线程共享同一线程块的共享内存,并且可以通过线程块内同步方式进行通信。
- Grid:网格是线程块的集合,网格中的所有线程块可以同时执行,每个线程块的线程都相互独立,块之间不能直接通信。
一个grid可以包含多个block,block可以是一维、二维或三维的,block中的thread也可以是一维、二维或三维的。每个线程都有一个唯一的线程ID,可以用来访问不同的数据和内存位置。在同一个线程块中,线程ID是从0开始连续编号的,可以通过内置变量 threadIdx 来获取:
// 获取本线程的索引,blockIdx 指的是线程块的索引,blockDim 指的是线程块的大小,threadIdx 指的是本线程块中的线程索引
int tid = blockIdx.x * blockDim.x + threadIdx.x;
在CUDA编程中,block和thread的数量和大小通常需要根据计算任务的特点进行调整,以最大化利用GPU的计算能力。例如,对于大规模的并行计算任务,可以使用更多的线程和线程块来充分利用GPU的并行处理能力。而对于计算量较小的任务,使用更少的线程和线程块可能会更高效。
// 计算需要的线程总量(高度 x 宽度):640*640=409600
int jobs = dst_height * dst_width;
// 一个线程块包含256个线程
int threads = 256;
// 计算线程块的数量
int blocks = ceil(jobs / (float)threads);
// 调用kernel函数
preprocess_kernel<<<blocks, threads>>>(
img_buffer_device, dst, dst_width, dst_height, jobs); // 函数的参数
5.1.3 kernel 函数
在CUDA编程中,kernel函数是在GPU上执行的函数,用于实现并行计算任务。当启动kernel函数时,GPU上的每个线程都会执行相同的程序代码,从而实现高效的并行计算。
在CUDA中,我们可以使用__global__关键字来标记一个函数,使之成为kernel函数。__global__关键字告诉编译器这个函数将在GPU上执行,而不是在CPU上执行。除此之外,kernel函数和普通的函数并没有太大区别,可以有输入参数和输出参数,可以有本地变量和控制流程语句,甚至可以调用其他函数。
在kernel函数中,我们可以使用一些内置的变量和函数来获取当前线程的信息,例如threadIdx、blockIdx、blockDim等。这些变量和函数可以帮助我们确定当前线程的位置和执行流程,从而更好地调度并行计算任务的执行。
启动kernel函数需要使用<<<...>>>语法。<<<...>>>中第一个参数一般是一个整数,用于指定线程块的数量。第二个参数是一个整数或一个dim3类型,用于指定每个线程块中的线程数量。dim3类型是一个三维向量,可以分别指定每个线程块中x、y、z方向的线程数量。如果只指定了一个整数,那么默认使用这个整数作为x方向的线程数量,而y和z方向的线程数量默认为1。
// 向量加法
__global__ void add(int *a, int *b, int *c, int N)
{
// 获取本线程块的索引,blockIdx 指的是线程块的索引,blockDim 指的是线程块的大小,threadIdx 指的是线程的索引
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N)
c[tid] = a[tid] + b[tid];
}
// 调用kernel函数
add<<<n_blocks, n_threads>>>(dev_a, dev_b, dev_c, N);
5.1.4 代码解释
simple.cu演示了如何使用CUDA在GPU上进行向量加法,并比较使用CPU和GPU的时间。
5.2.1 Yolov5 decode流程
将YOLOv5 COCO预训练模型(80个类别)导出ONNX,可查看到3个head(shape分别是[255,80,80], [255,40,40], [255,20,20]),经过decode后变成最终的输出output ([25200,85]),再经过NMS就可以得到最终的检测框。

decode、后处理的大致流程:
-
输入图片推理得到3个head的特征图

-
将每个head 变形,下图是其中
[255,80,80]这个head的变形- 因为有3种anchor,
[255,80,80]可以转换为3个[85,80,80]的Tensor,即[3,85,80,80] - 取出其中一个Tensor的一个cell,即一个网格的预测结果,大小为
[85,1,1]- 其中1,1表示网格的横纵坐标位置
- 85表示:
(tx,ty,tw,th,score, [0,0,1,...,0,0,0] )即检测框的xywh和score,80个类别独热编码的classes - decode的核心流程就是根据
tx,ty,tw,th计算bx,by,bw,bh

- 因为有3种anchor,
-
计算
bx,by,bw,bh
- 蓝色为预测框,黑色虚线为anchor
b x = 2 σ ( t x ) − 0.5 + c x b y = 2 σ ( t y ) − 0.5 + c y b w = p w ( 2 σ ( t w ) ) 2 b h = p h ( 2 σ ( t h ) ) 2 b_x = 2\sigma(t_x)-0.5+c_x \\ b_y = 2\sigma(t_y)-0.5+c_y \\ b_w = p_w(2\sigma(t_w))^2 \\ b_h = p_h(2\sigma(t_h))^2 bx=2σ(tx)−0.5+cxby=2σ(ty)−0.5+cybw=pw(2σ(tw))2bh=ph(2σ(th))2
bx, by取值范围 (-0.5,1.5) 负责一个网格一定范围内中心点的预测
bw,bh取值范围(0,4) ,即是anchor宽度高度调节范围的0~4倍
-
最后三个特征图,每个特征图3种anchor,转换下来:
[255,80,80]-->[3,80,80,85]-->[19200,85][255,40,40]-->[3,40,40,85]-->[4800,85][255,20,20]-->[3,20,20,85]-->[1200,85]- 最终组合到一起,最终的输出为
[25200,85],85中80是类别数量
-
NMS筛选最终的检测框
5.2.2 plugin基本流程介绍
在我们之前的介绍中提到,我们使用了YoloLayer_TRT插件,其功能是decode onnx模型的输出,这里的decode算子用GPU实现并加速了,以提高模型吞吐量。
参考:3.3 具体修改细节

实现TensorRT Plugin需要实现插件类,和插件工厂类,并对插件进行注册。步骤如下:
-
定义插件版本和插件名:
位置:
yoloPlugins.h第51行
// 定义插件版本和插件名
namespace
{
const char *YOLOLAYER_PLUGIN_VERSION{"1"};
const char *YOLOLAYER_PLUGIN_NAME{"YoloLayer_TRT"};
} // namespace
-
实现插件类
位置:
yoloPlugins.h第58行插件类需要继承
IPluginV2DynamicExt类。这份代码中定义的插件类名是YoloLayer,其中实现了IPluginV2DynamicExt中的虚函数和一些成员变量和函数。
class YoloLayer : public nvinfer1::IPluginV2DynamicExt
{
public:
.....
private:
......
};
-
实现插件创建类
位置:
yoloPlugins.h第112行插件创建类需要继承
IPluginCreator类,并实现其中的虚函数。这份代码中定义的插件创建类名是YoloLayerPluginCreator,其中实现了IPluginCreator中的虚函数和一些成员变量和函数。
class YoloLayerPluginCreator : public nvinfer1::IPluginCreator
{
public:
......
private:
......
};
上述代码定义在头文件yoloPlugins.h中,具体的函数实现放在了yoloPlugins.cpp文件中,同时核心的计算部分由cuda进行实现,放在了yoloForward_nc.cu中。
-
注册插件
位置:
yoloPlugins.cpp第341行在实现了各个类方法后,需要调用宏对plugin进行注册。以方便TensorRT识别并找到对应的Plugin。
REGISTER_TENSORRT_PLUGIN(YoloLayerPluginCreator);
- 编译插件库并使用
add_library(yolo_plugin SHARED
plugins/yoloPlugins.cpp
plugins/yoloForward_nc.cu
)
add_executable(build
build.cu
${TensorRT_SAMPLE_DIR}/common/logger.cpp
${TensorRT_SAMPLE_DIR}/common/sampleUtils.cpp
)
# 这里需要注意加上-Wl,--no-as-needed,否则可能连接失败
target_link_libraries(build PRIVATE -Wl,--no-as-needed yolo_plugin) # -Wl,--no-as-needed is needed to avoid linking errors
5.2.3 Plugin中需要实现的方法介绍
核心需要实现的方法有configurePlugin, enqueue, 还有用于序列化和反序列的方法。
configurePugin用于配置相关参数的信息:
void YoloLayer::configurePlugin(
const nvinfer1::DynamicPluginTensorDesc *in, int nbInputs, const nvinfer1::DynamicPluginTensorDesc *out, int nbOutputs) noexcept
{
......
}
enqueue方法则是进行模型推理,需要调用对应的推理代码。
int YoloLayer::enqueue(const nvinfer1::PluginTensorDesc *inputDesc, const nvinfer1::PluginTensorDesc *outputDesc, const void *const *inputs,
void *const *outputs, void *workspace, cudaStream_t stream) noexcept
{
.......
return 0;
}
- 另外一个比较重要的是序列化,序列化需要把plugin的参数存入序列化数据中,如下代码所示:
void YoloLayer::serialize(void* buffer) const noexcept
{
char *d = static_cast<char*>(buffer);
write(d, m_NetWidth);
write(d, m_NetHeight);
write(d, m_MaxStride);
write(d, m_NumClasses);
write(d, m_ScoreThreshold);
write(d, m_OutputSize);
// write anchors:
for (int i = 0; i < m_Anchors.size(); i++){
write(d, m_Anchors[i]);
}
// write feature size:
uint yoloTensorsSize = m_FeatureSpatialSize.size();
for (uint i = 0; i < yoloTensorsSize; ++i)
{
write(d, m_FeatureSpatialSize[i].h());
write(d, m_FeatureSpatialSize[i].w());
}
}
其中write函数把plugin的参数写到对应的内存位置,在后续将模型序列化存入磁盘时,这些数据也会被存入模型文件中。在反序列化的过程中,模型序列化数据又会被解析出来用于创建plugin。如下:
YoloLayer::YoloLayer (const void* data, size_t length)
{
const char *d = static_cast<const char*>(data);
read(d, m_NetWidth);
read(d, m_NetHeight);
read(d, m_MaxStride);
read(d, m_NumClasses);
read(d, m_ScoreThreshold);
read(d, m_OutputSize);
m_Anchors.resize(NFEATURES * NANCHORS * 2);
for(uint i = 0; i < m_Anchors.size(); i++){
read(d, m_Anchors[i]);
}
for(uint i = 0; i < NFEATURES; i++){
int height;
int width;
read(d, height);
read(d, width);
m_FeatureSpatialSize.push_back(nvinfer1::DimsHW(height, width));
}
};
在上面的构造函数中实现了从序列化数据中读取参数的功能,以构造plugin。Plugin需要实现的核心函数包括:
getOutputDimensions():计算并返回插件的输出张量的尺寸。enqueue():执行插件的前向传播计算。configurePlugin():设置插件的参数和输入/输出张量的数据类型等信息。getSerializationSize()和serialize():用于插件的序列化。deserialize():用于插件的反序列化。
在实现插件时,需要根据插件的具体功能来设计相应的计算逻辑,并在enqueue()函数中实现。同时,还需要根据插件的输入/输出张量的数据类型等信息来设置插件的参数,在configurePlugin()函数中实现。最后,通过宏注册plugin,并和主程序一起编译即可。
// 注册插件。 在实现了各个类方法后,需要调用宏对plugin进行注册。以方便TensorRT识别并找到对应的Plugin。
REGISTER_TENSORRT_PLUGIN(YoloLayerPluginCreator);
5.3 多线程pipeline Demo
附件位置:
4.thread_pipeline
示例代码实现了一个生产者-消费者模型,使用队列作为共享资源来存储生产者生产的数据,消费者从队列中取出数据进行消费。在这个模型中,生产者和消费者是两个不同的线程,共享同一个队列。
-
定义了一个全局变量 buffer 代表队列,大小为
buffer_size,设置为 10。 -
使用互斥锁
buffer_mutex来保护对队列的访问,以确保生产者和消费者不能同时访问队列。 -
not_full和not_empty是条件变量,用于在队列满时阻塞生产者线程,在队列为空时阻塞消费者线程。 -
生产者线程的函数是
produce(),它将数字 1 到 20 添加到队列中。生产者线程首先尝试获取互斥锁,然后在条件变量not_full上等待,直到队列不再满。一旦队列未满,生产者线程将数字添加到队列中,并发送信号给条件变量not_empty,通知消费者线程队列中已有数据可以消费。 -
消费者线程的函数是
consume(),它从队列中取出数字并进行消费。消费者线程也首先尝试获取互斥锁,然后在条件变量not_empty上等待,直到队列中有数据可供消费。一旦有数据可供消费,消费者线程将数字从队列中删除,并发送信号给条件变量not_full,通知生产者线程队列中已有空间可以继续生产数据。 -
在主函数 main() 中,我们创建了两个线程,一个用于生产者函数
producer(),另一个用于消费者函数consumer()。然后我们等待两个线程执行完毕,使用join()函数来等待线程完成执行。
这段代码演示了如何使用互斥锁和条件变量实现生产者-消费者模型,实现了线程之间的同步,以确保生产者和消费者在访问共享资源时不会发生竞争条件问题。
使用g++ main.cpp -std=c++14 -pthread编译代码,并执行./a.out执行代码查看运行结果。















 8480
8480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









