







图表示多对多的关系,而线性表表示的是一对一的关系,树是一对多的关系。
所以图非常强大,线性表和树都可以是认为图的一种特殊情况
图包含哪些呢?
1.一组顶点:用V(Vertex)vert转+ex,转肯定是绕着一个顶点转的,非常棒!
它是表示顶点的集合
2.一组边:用E(Edge)表示边的集合
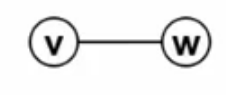
边是顶点对:如上图v,w属于V
顶点对就是一个边,用像坐标一样的形式来表示:(v, w)属于E
1. 此时这个边为:无向边,这个无所谓方向的,v能找w玩,w也能找v玩。
无向边用圆括号,很圆润,所以很温柔,都可以来玩。
2.有向边<v,w>表示从v指向w的边(单行线)
不考虑重边和自回路
重边就是两个结点之间不可以重复出现边,自回路,就是没有自己到自己的情况。



抽象数据类型定义
1.类型名称:图(Graph)
2.数据对象集:G(V,E)由一个非空的有限顶点集合V和一个有限边集合E组成。


在边上标上数字,这个数字就叫权重

有权重的图就变成了网络。


用一个二维数组G[i][j],如果<Vi, Vj>是G中的边,那智能G[i][j] = 1,否则为0,二维数组中为1即有一条边。
特征:1.主对角线必为0,此时为自回路的情形。
2.矩阵关于主对角线对称,把一条边存了两次
缺点:浪费了一半的空间。
so,对于无向图的存储,怎么省下一半的空间呢?


邻接矩阵的好处
1.简单、直观、好理解
2.方便检查任意一对顶点之间是否存在边
3.方便找任一顶点的所有“邻接点”,邻接点:有边直接和它相连的顶点。
4.方便计算任一顶点的“度”,图的度是说与这个顶点相关的所有边的个数。
对于有向图来说,有两个概念
从这个结点发出的边的个数叫做“出度”,指向这个结点的边的个数称为:入度
无向图:对应行或列的非0元素的个数
有向图:对于行非0元素的个数为“出度”,对应列的非0元素的个数是“入度”
邻接矩阵的缺点
1.浪费空间——存稀疏图(点很多但边很少),会存在大量无效元素
但是,对于稠密图(特别是完全图【给了你n个顶点,任意两个顶点之间都有一条边,边数达到极大值时】)还是很合算的。
2.浪费时间
当统计稀疏图当中有多少条边时
为解决邻接矩阵的缺点,有了另外一种表示法:邻接表
G[N]为指针数组,对应矩阵每行的一个链表,只存非0元素。
邻接表的表示法是不唯一的,因为与0相邻接的结点可以是1,3也可是是3,1
对于网络,结构中还要添加权重的域。

对于邻接表,一定要够稀疏才合算!!!
邻接表好处
1.方便寻找任一顶点的所有“邻接点”
2.节约稀疏图的空间
需要n个头指针 + 2个结点的大小(每个结点至少有2个域,网络有3个域)
3.方便计算任一顶点的度吗?度是说与这个顶点的边的个数
1)对于无向图:是的
2)对于有向图:
缺陷:只能计算“出度”,
需要构造“逆邻接表”(存指向自己的边)来计算“入度”
缺点:不方便检查任意一对顶点之间是否存在边
图的遍历:把图当中所有顶点访问一遍(不能有重复的访问)
深度优先搜索(Depth First Search)depth = deep + th

广度优先搜索(Breadth First Search)(BFS)
bread(宽的) + th(性质) 宽度

1.连通:如果从V到W存在一条(无向)路径,则称V和W是连通的。
2.路径:V到W的路径是一系列顶点{V,v1,v2, ... , vn, W}的集合,其中任意一对相邻的顶点都有图中的边。
3.路径的长度:是路径中的边数(如果带权,则是所有边的权重和)。
4.简单路径:如果V到W之间的所有顶点都不同。
5.不简单路径:含有回路的路径
6.回路:起点等于终点的路径
7.连通图:图中任意两顶点均连通。
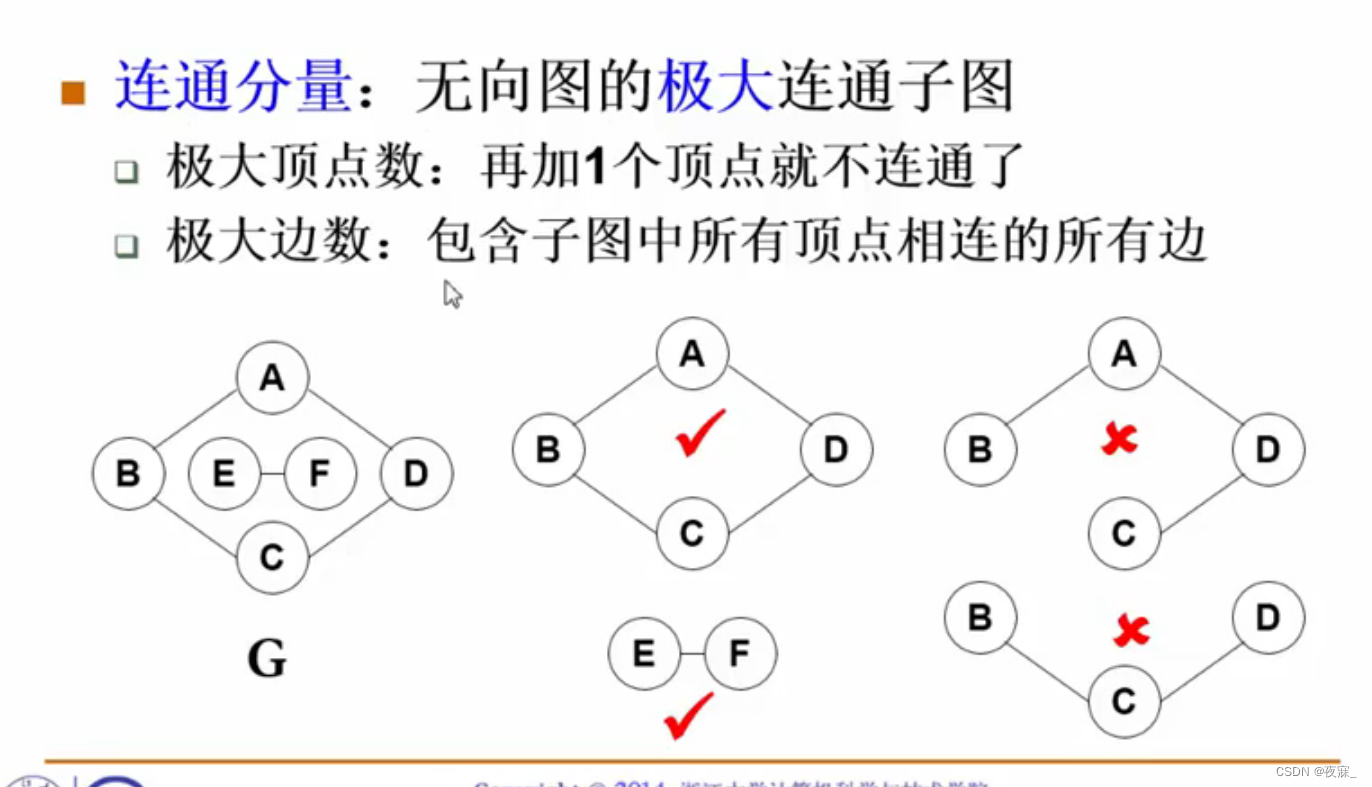
1.连通分量:无向图的极大连通子图
1.极大顶点数:再加1个顶点就不连通了
2.极大边数:包含子图中所有顶点相连的所有边
注意:这个极大并非是数量上的极大,而是使其连通的顶点的极大,有可能有多个
2.子图:包含了图的一部分边和一部分顶点
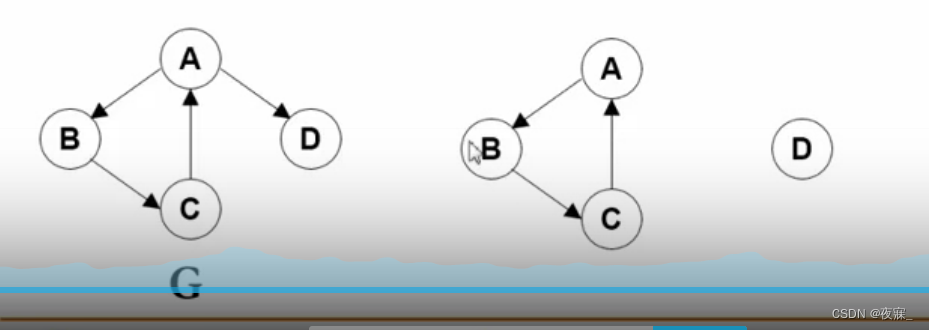
1.强连通:有向图中顶点V和W之间存在双向路径,则称V和W是强连通的。
2.强连通图:有向图中任意两个顶点均强连通
3.弱连通图:有向图中任意两个顶点不是均强连通
4.强连通分量:有向图的极大强连通子图















 1751
1751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









