






Transformer
自注意力机制
自注意力机制核心就是计算句子在编码过程中每个位置上的注意力权重,然后再以权重和的方式计算整个句子的隐含向量表示
attention核心?
self-attention 核心公式:
\(\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\)
- 其中,\(Q\),\(K\),\(V\)分别表示查询(Query)、键(Key)和值(Value)的矩阵,\(d_k\)是每个注意力头的维度。
- 首先将query与key的转置做点积,然后将结果除以sqrt(\(d_k\)),再进行softmax计算,最后将结果与value做矩阵乘法得到output,\(d_k\)表示词向量维度,除以sqrt(\(d_k\))是为了防止\(QK^T\)过大导致softmax计算溢出,其次可以将\(QK^T\)结果满足均值为0,方差为1的分布。
- \(QK^T\)计算相当于计算Q和V中每个向量的点积,本质上是余弦相似度,可以表示两个向量在方向上的相似度,结果越大越相似。
总而言之,在Self-Attention中,通过计算查询和键之间的相似性得到注意力分布,然后将该分布与值相乘以获取加权的值表示。最后,对所有头的结果进行拼接或平均操作,得到最终的输出。
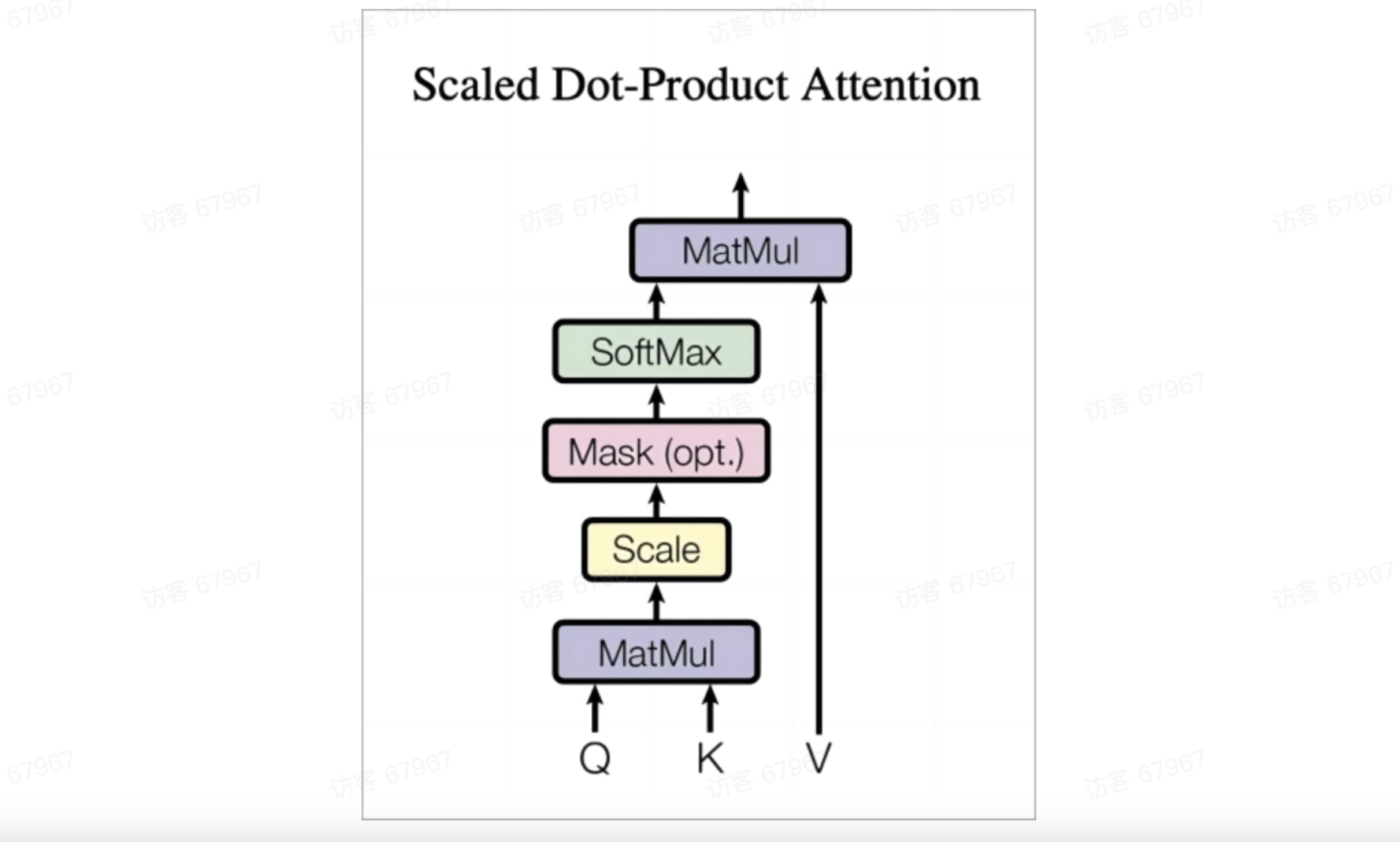
Q、K、V是什么?
q,k,v分别代表query,key,value对应为查询,键、值

Q、K、V都是对X进行矩阵W后的线性变换
实现
import numpy as np
from math import sqrt
import torch
from torch import nn
class Self_Attention(nn.Module):
# input: batch_size * seq_len * input_dim
# Q: batch_size * seq_len * dim_k
# K: batch_size * seq_len * dim_k
# V: batch_size * seq_len * dim_v
def __init__(self,input_dim,dim_k,dim_v):
super(Self_Attention,self).__init__()
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
# Q * K.T() batch_size * seq_len * seq_len
atten = nn.Softmax(dim=-1)(torch.bmm(Q,K.permute(0,2,1))) * self._norm_fact
# Q * k.T() * V batch_size * seq_len * dim_v
output = torch.bmm(atten,V)
return output
X = torch.randn(4,3,2)
print(X)
self_atten = Self_Attention(2, 4, 5)
res = self_atten(X)
print(res.shape)多头注意力机制
不同于只使用一个注意力池化,可以将输入x拆分为h份,然后独立计算h组不同的线性投影来得到各自的QKV,然后将变换后的h组QKV并行计算注意力,最后将h个注意力池化拼接起来并通过另一个可以学习的线性投影进行变换以产生输出,这种设计叫做多头注意力。
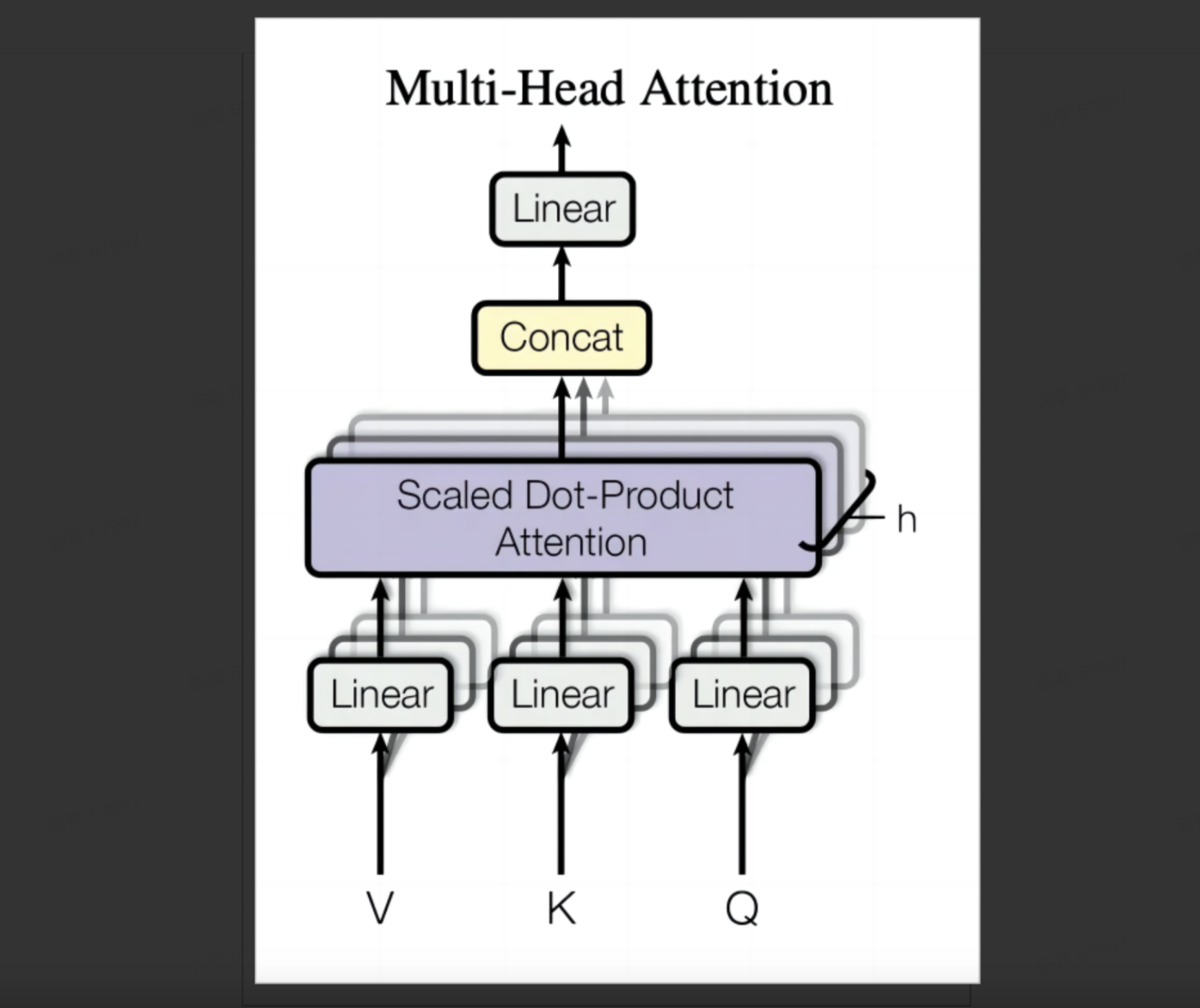
在多头注意力机制中,每个头可能会关注输入的不同部分,可以表示比简单加权平均值更加复杂的函数。
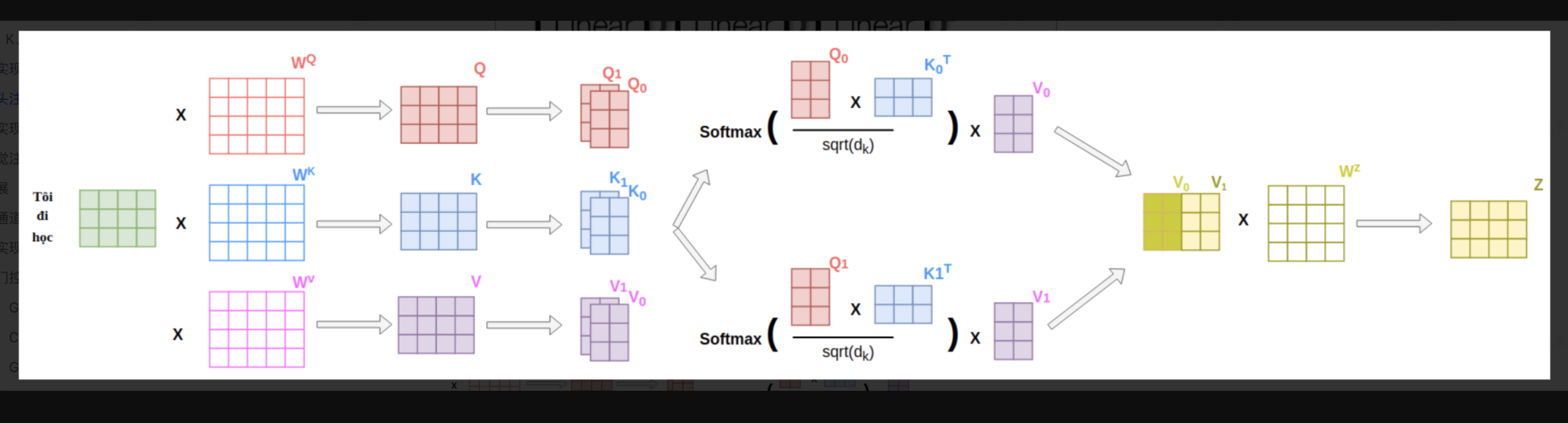
实现
# Muti-head Attention 机制的实现
from math import sqrt
import torch
import torch.nn as nn
class Self_Attention_Muti_Head(nn.Module):
# input: batch_size * seq_len *input_dim
# q: bath_size * seq_len * dim_k
# k: bath_size * seq_len * dim_k
# v: bath_size * seq_len * dim_v
def __init__(self,input_dim,dim_k,dim_v,nums_head):
super(Self_Attention_Muti_Head, self).__init__()
assert(dim_k % nums_head ==0)
assert(dim_v % nums_head ==0)
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self.nums_head = nums_head
self.dim_k = dim_k
self.dim_v = dim_v
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)
K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)
V = self.v(x).reshape(-1,x.shape[0],x.shape[1],self.dim_v // self.nums_head)
print(x.shape)
print(Q.size())
atten = nn.Softmax(dim=-1)(torch.matmul(Q,K.permute(0,1,3,2))) # Q * K.T() ---> batch_size * seq_len * seq_len
output = torch.matmul(atten,V).reshape(x.shape[0],x.shape[1],-1) # Q * K.T() * V ---> batch_size * seq_len * dim_v
return output
x = torch.rand(1,3,4)
print(x)
atten = Self_Attention_Muti_Head(4, 4, 4, 2)
y = atten(x)
print(y.shape)

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











