







1 、几个常用的术语
这里首先介绍几个 常见 的 模型评价术语,现在假设我们的分类目标只有两类,计为正例(positive)和负例(negtive)分别是:
1)True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
2)False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
4)True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
| 实 际 类 别 | 预测类别 | |||
| Yes | No | 总计 | ||
| Yes | TP | FN | P (实际为 Yes ) | |
| No | FP | TN | N (实际为 No ) | |
| 总计 | P’(被分为 Yes ) | N’(被分为 No ) | P+N | |
图是这四个术语的混淆矩阵。
1)P=TP+FN 表示实际为正例的样本个数。
2)True、False 描述的是分类器是否判断正确。
3)Positive、Negative 是分类器的分类结果,如果正例计为 1、负例计为-1,即 positive=1、negtive=-1。用 1 表示 True,-1 表示 False,那么实际的类标=TF*PN,TF 为 true 或 false,PN为 positive 或 negtive。
4)例如 True positives(TP)的实际类标=1*1=1 为正例,False positives(FP)的实际类标=(-1)*1=-1 为负例,False negatives(FN)的实际类标=(-1)*(-1)=1 为正例,True negatives(TN)的实际类标=1*(-1)=-1 为负例。
2 、评价指标
1)正确率(accuracy)
正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),正确率是被分对的样本数在所有样本数中的占比,通常来说正确率越高,分类器越好。
2)错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以 accuracy =1 - error rate。
3)灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
4)特效度(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
5)精度(precision)
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/ (TP+FP)。
6)召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一的。
7)其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神
经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
8)查准率和查全率反映了分类器分类性能的两个方面。如果综合考虑查准率与查全率,可以得到新的评价指标 F1 测试值,也称为综合分类率:
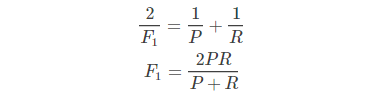
为了综合多个类别的分类情况,评测系统整体性能,经常采用的还有微平均 F1(micro-averaging)和宏平均 F1(macro-averaging )两种指标。查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低,查全率高时,查准率往往偏低,例如,若希望将好瓜尽可能多选出来,则可通过增加选瓜的数量来实现,如果希望将所有的西瓜都选上,那么所有的好瓜必然都被选上了,但这样查准率就会较低;若希望选出的瓜中好瓜比例尽可能高,则可只挑选最有把握的瓜,但这样就难免会漏掉不少好瓜,使得查全率较低。
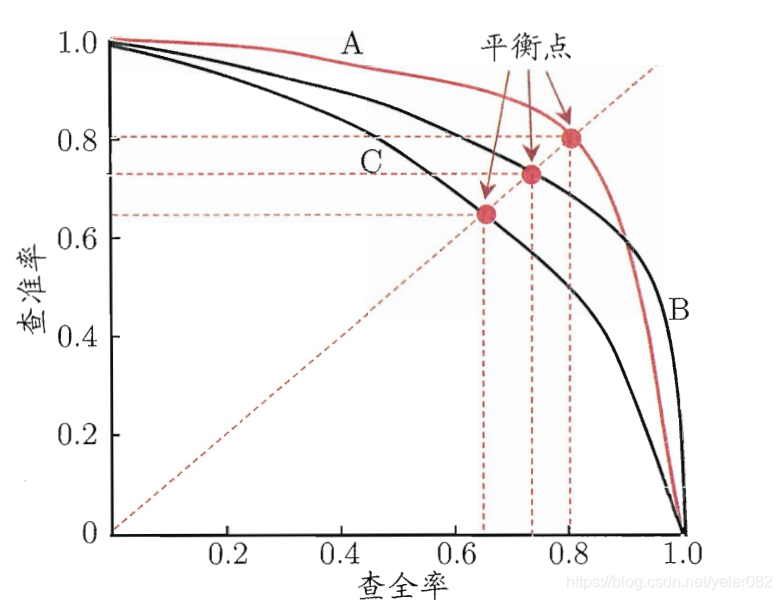
如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可断言后者的性能优于前者,例如上面的A和B优于学习器C,但是A和B的性能无法直接判断,但我们往往仍希望把学习器A和学习器B进行一个比较,我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点或者是F1值。
平衡点(BEP)是查准率=查全率时的取值,如果这个值较大,则说明学习器的性能较好。而F1 = 2 * P * R /( P + R ),同样,F1值越大,我们可以认为该学习器的性能较好。
PR 曲线和ROC 曲线
PR

Precision-Recall曲线,这个东西应该是来源于信息检索中对相关性的评价,precision就是你预测出来的结果中,TP占据正确预测为正例加上错误预测为正例的比率;recall就是你预测出来的结果中,TP占实际为正例的比率;假设你的测试样本有100个,就是会返回100个precision-recall点,然后把这些点绘制出来,就得到了PR曲线,下面为绘制pr曲线的例子(因为样本数量少,这个折线图看起来有点诡异);
#!/usr/bin/env python
# encoding: utf-8
'''
@author: lele Ye
@contact: 1750112338@qq.com
@software: pycharm 2018.2
@file: PR_curve.py
@time: 2019/4/29 9:33
@desc:
'''
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
plt.figure(1) # 创建图表1
plt.title('Precision/Recall Curve') # give plot a title
plt.xlabel('Recall') # make axis labels
plt.ylabel('Precision')
# y_true和y_scores分别是gt label和predict score
y_true = np.array([1,1,0,0,0,1,1,0,1,0,1,0])
y_scores = np.array([0.9,0.8,0.7,0.2,0.4,0.6,0.5,0,0.4,0.3,0.8,0.6])
precision, recall, thresholds = precision_recall_curve(y_true, y_scores)
plt.figure(1)
plt.plot(precision, recall)
plt.savefig('p-r.png')
plt.show() 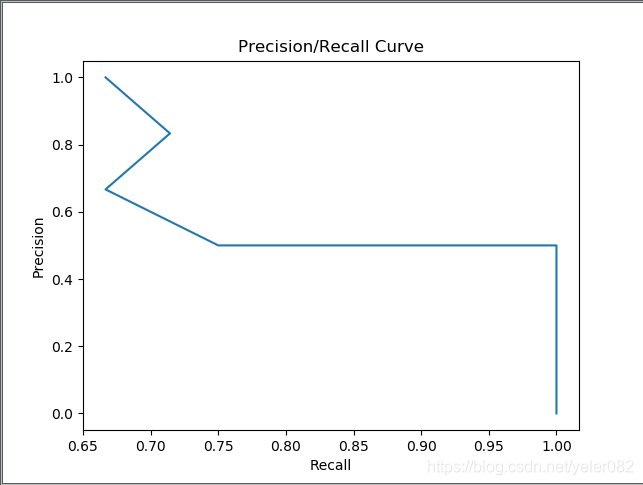
所以,PR曲线的采点是按照样本的数量采的。注意,这一条PR曲线的绘制只对应一个p_0值(也就是分类阈值,当回归结果高于这个阈值时判定为正类),所以往往先选择最优的p_0,再绘制不同model的PR曲线,比较model的优劣。
ROC

ROC绘制的就是在不同的阈值p_0(同上面的分类阈值)下,TPR和FPR的点图。所以ROC曲线的点是由不同的p_0所造成的。所以你绘图的时候,就用不同的p_0采点就行。可以看出TPR和Recall的形式是一样的,就是查全率了,FPR就是保证这样的查全率你所要付出的代价,就是把多少负样本也分成了正的了。
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
plt.figure(1) # 创建图表1
plt.title('ROC Curve') # give plot a title
plt.xlabel('false/positive') # make axis labels
plt.ylabel('true/positive')
# y_true和y_scores分别是gt label和predict score
y_true = np.array([1,1,0,0,0,1,1,0,1,0,1,0])
y_scores = np.array([0.9,0.8,0.7,0.2,0.4,0.6,0.5,0,0.4,0.3,0.8,0.6])
precision, recall, thresholds = roc_curve(y_true, y_scores)
plt.figure(1)
plt.plot(precision, recall)
plt.savefig('ROC.png')
plt.show()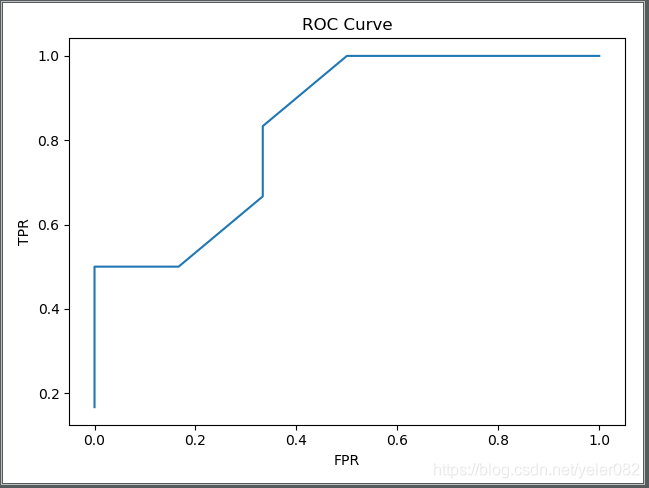
对比PR图和ROC图

AUC
AUC(Area Under Curve)就是ROC曲线下方的面积。可以知道,TPR越大的情况下,FPR始终很小,才是好的,那么这条曲线就是很靠近纵轴的曲线,那么下方面积就大。AUC面积越大,说明算法和模型准确率越高越好,反映出正样本的预测结果更加靠前。(推荐的样本更能符合用户的喜好)
评估选取原则:
在很多实际问题中,正负样本数量往往很不均衡。比如,计算广告领域经常涉及转化率模型,正样本的数量往往是负样本数量的1/1000,甚至1/10000。若选择不同的测试集,P-R曲线的变化就会非常大,而ROC曲线则能够更加稳定地反映模型本身的好坏。所以,ROC曲线的适用场景更多,被广泛用于排序、推荐、广告等领域。
但需要注意的是,选择P-R曲线还是ROC曲线是因实际问题而异的,如果研究者希望更多地看到模型在特定数据集上的表现,P-R曲线则能够更直观地反映其性能。
PR曲线比ROC曲线更加关注正样本,而ROC则兼顾了两者。
当正负样本比例失调时,比如正样本1个,负样本100个,则ROC曲线变化不大,此时用PR曲线更加能反映出分类器性能的好坏。这个时候指的是两个分类器,因为只有一个正样本,所以在画auc的时候变化可能不太大;但是在画PR曲线的时候,因为要召回这一个正样本,看哪个分类器同时召回了更少的负样本,差的分类器就会召回更多的负样本,这样precision必然大幅下降,这样分类器性能对比就出来了。
附注(准确率、召回率、F1计算函数):
# y_true, y_pred
# TP = (y_pred==1)*(y_true==1)
# FP = (y_pred==1)*(y_true==0)
# FN = (y_pred==0)*(y_true==1)
# TN = (y_pred==0)*(y_true==0)
# TP + FP = y_pred==1
# TP + FN = y_true==1
def precision_score(y_true, y_pred):
return ((y_true==1)*(y_pred==1)).sum()/(y_pred==1).sum()
def recall_score(y_true, y_pred):
return ((y_true==1)*(y_pred==1)).sum()/(y_true==1).sum()
def f1_score(y_true, y_pred):
num = 2*precison_score(y_true, y_pred)*recall_score(y_true, y_pred)
deno = (precision_score(y_true, y_pred)+recall_score(y_true, y_pred))
return num/deno参考:
1、python绘制precision-recall曲线、ROC曲线
2、分类模型的精确率(precision)与召回率(recall)(Python)
3、ROC曲线、AUC、Precision、Recall、F-measure理解及Python实现
4、准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









