







本文需要有一定的docker 基础知识,且会修改python代码,不是新手向的教程
第一步:下载官方项目
GitHub - THUDM/GLM-4: GLM-4 series: Open Multilingual Multimodal Chat LMs | 开源多语言多模态对话模型
然后在官方项目的根目录下,添加dockerfile文件,docker file 文件的内容如下
# 使用nvidia/cuda:12.4.1-devel-ubuntu22.04作为基础镜像
FROM nvidia/cuda:12.4.1-devel-ubuntu22.04 AS dev
# 更新包索引并安装Python 3的pip和Git
RUN apt-get update -y \
&& apt-get install -y python3-pip git \
&& rm -rf /var/lib/apt/lists/*
# 运行ldconfig命令以确保CUDA库可以被正确找到
RUN ldconfig /usr/local/cuda-12.4/compat/
# 设置工作目录
WORKDIR /glm4
# 复制文件夹和文件到容器的工作目录
COPY basic_demo /glm4/basic_demo
COPY composite_demo /glm4/composite_demo
COPY finetune_demo /glm4/finetune_demo
COPY LICENSE /glm4/LICENSE
COPY resources /glm4/resources
# 进入到/basic_demo目录
WORKDIR /glm4/basic_demo
# 安装requirements.txt中指定的Python依赖
RUN python3 -m pip install --no-cache-dir -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 回到之前的工作目录
WORKDIR /glm4
# 声明容器将监听的端口
EXPOSE 8000然后在项目的根目录下,构建容器
docker build -t you_need_name/glm4-9b:tag .然后等待容器构建成功。
容器构建成功后,需要提前下载好模型。
下载模型后,需要修改openai_api_server.py文件,修改的位置如下。
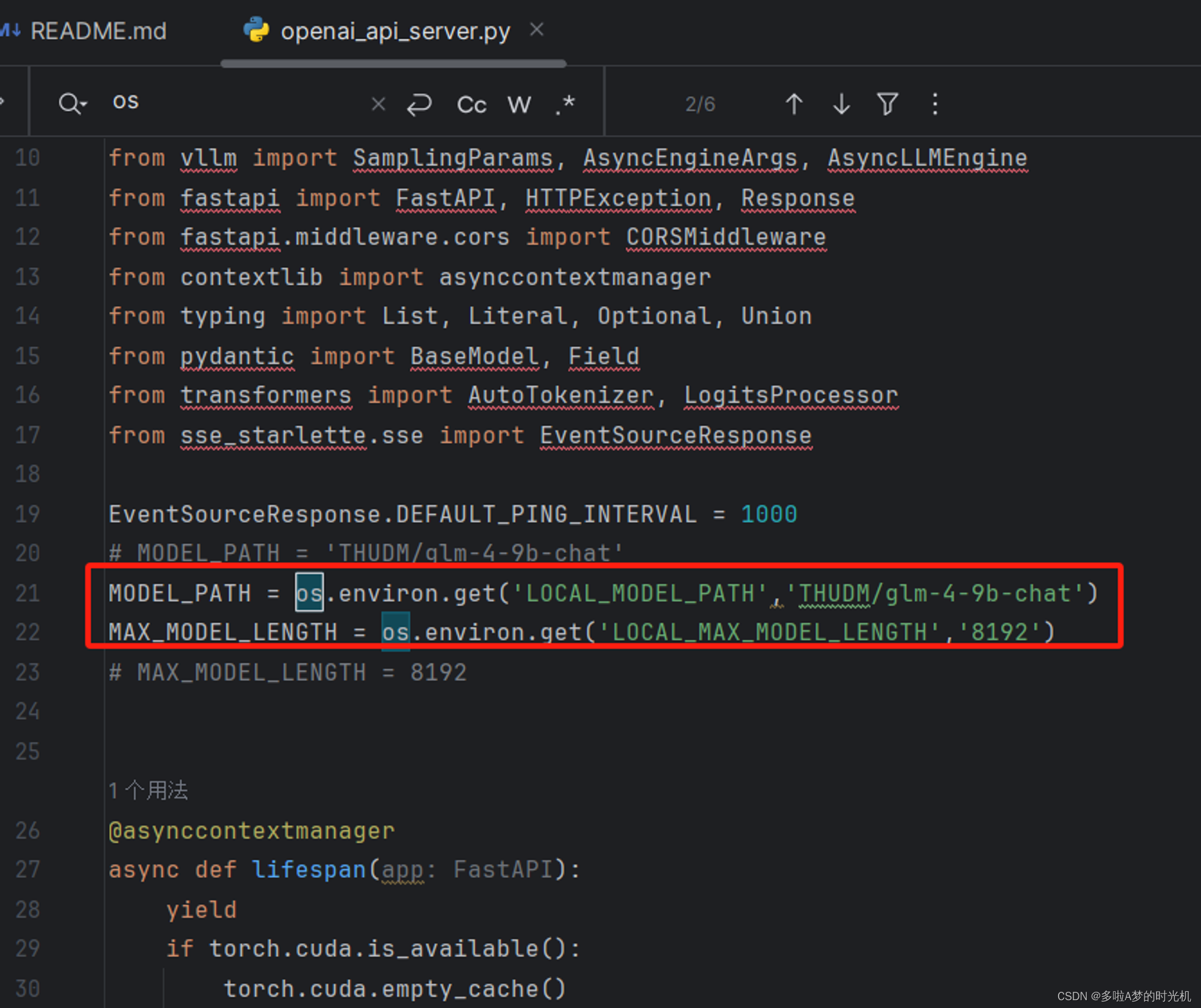
修改的内容如下,修改这些内容是为了方便在容器启动时,直接设置模型路径,
MODEL_PATH = os.environ.get('LOCAL_MODEL_PATH','THUDM/glm-4-9b-chat')
MAX_MODEL_LENGTH = os.environ.get('LOCAL_MAX_MODEL_LENGTH','8192')修改完成后使用如下docker-compose.yml文件,在该文件的目录下运行 ‘docker compose up -d’命令
version: '3.8'
services:
glm4_vllm_server:
image: jjck/glm4-9b:20240606
runtime: nvidia
ipc: host
restart: always
environment:
- LOCAL_MODEL_PATH=/glm4/glm-4-9b-chat
- LOCAL_MAX_MODEL_LENGTH=8192
ports:
- "8101:8000"
volumes:
- "/etc/localtime:/etc/localtime:ro"
- "/home/aicode/logs/AI_Order/glm-4-9b-chat:/glm4/glm-4-9b-chat"
- "/home/pythonproject/GLM-4-main/basic_demo:/glm4/basic_demo"
command: python3 basic_demo/openai_api_server.py
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
- "/home/aicode/logs/AI_Order/glm-4-9b-chat:/glm4/glm-4-9b-chat" - "/home/pythonproject/GLM-4-main/basic_demo:/glm4/basic_demo"
这两个路径,第一个是模型的存放路径,这个路径根据你的实际情况自行修改。
第二个是代码路径,这个也是根据自身情况自行修改。
或者是这个命令
docker run --runtime nvidia --gpus device=0 \
--name glm4_vllm_server \
-p 8101:8000 \
-v /etc/localtime:/etc/localtime:ro \
-v /home/aicode/logs/AI_Order/glm-4-9b-chat:/glm4/glm-4-9b-chat \
-v /home/pythonproject/GLM-4-main/basic_demo:/glm4/basic_demo \
-itd xxx/glm4-9b:20240606
我尝试用他们的api_server demo的过程中出现的问题。
用清华官方的这个demo会出现异步线程的问题,导致用户访问异常,异常的日志如下
glm4_vllm_api_server-glm4_vllm_server-1 | File "/usr/local/lib/python3.10/dist-packages/fastapi/routing.py", line 191, in run_endpoint_function
glm4_vllm_api_server-glm4_vllm_server-1 | return await dependant.call(**values)
glm4_vllm_api_server-glm4_vllm_server-1 | File "/glm4/basic_demo/openai_api_server.py", line 344, in create_chat_completion
glm4_vllm_api_server-glm4_vllm_server-1 | async for response in generate_stream_glm4(gen_params):
glm4_vllm_api_server-glm4_vllm_server-1 | File "/glm4/basic_demo/openai_api_server.py", line 199, in generate_stream_glm4
glm4_vllm_api_server-glm4_vllm_server-1 | async for output in engine.generate(inputs=inputs, sampling_params=sampling_params, request_id="glm-4-9b"):
glm4_vllm_api_server-glm4_vllm_server-1 | File "/usr/local/lib/python3.10/dist-packages/vllm/engine/async_llm_engine.py", line 662, in generate
glm4_vllm_api_server-glm4_vllm_server-1 | async for output in self._process_request(
glm4_vllm_api_server-glm4_vllm_server-1 | File "/usr/local/lib/python3.10/dist-packages/vllm/engine/async_llm_engine.py", line 756, in _process_request
glm4_vllm_api_server-glm4_vllm_server-1 | stream = await self.add_request(
glm4_vllm_api_server-glm4_vllm_server-1 | File "/usr/local/lib/python3.10/dist-packages/vllm/engine/async_llm_engine.py", line 561, in add_request
glm4_vllm_api_server-glm4_vllm_server-1 | self.start_background_loop()
glm4_vllm_api_server-glm4_vllm_server-1 | File "/usr/local/lib/python3.10/dist-packages/vllm/engine/async_llm_engine.py", line 431, in start_background_loop
glm4_vllm_api_server-glm4_vllm_server-1 | raise AsyncEngineDeadError(
glm4_vllm_api_server-glm4_vllm_server-1 | vllm.engine.async_llm_engine.AsyncEngineDeadError: Background loop has errored already.
所以,不要把demo放在生产环境中使用。需要在生产环境的,等官方适配吧















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









