






阿里Qwen3发布了,小猿简单聊聊使用后的感受。
官方发布了榜单情况,就不多说了,懂的都懂,能够公布出来的数据毕竟不会太差。
说几个亮点吧:
一、8个不同尺寸,覆盖全场景
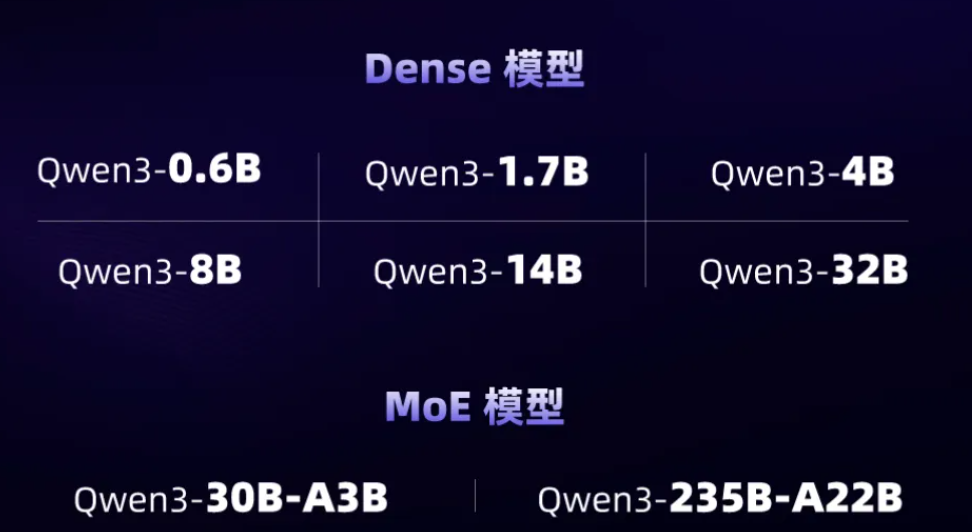
这次总共发了8个模型,其中6个是Dense稠密模型,包括:Qwen3-0.6B、1.7B、4B、8B、14B、32B。还有两个MoE模型,Qwen3-30B-A3B,和旗舰版的Qwen3-235B-A22B。
官方的说法,只需要 4 张英伟达的 H20 GPU,就能在本地把 235B 的 Qwen3 旗舰版 MoE 模型跑起来,算下来部署成本只有 DeepSeek-R1 的 35%。
而且,以上所有模型,都是混合推理模型。
二、第一个开源的“混合推理”模型
所谓的混合推理模型,就是把“快思考”和“慢思考”两种模式混合在一起,举个例子,相当于在DeepSeek里的V3和R1都合到一块,由模型根据你的提问,决定用哪一个模型。
如果你对 Claude 熟悉,应该知道Claude 3.7 Sonnet 是首个“混合推理模型”,用户可以根据问题和任务灵活选择是否要思考。
根据三方数据,至今为止,阿里通义已开源 200 多个模型,全球下载量超 3 亿次,衍生出来的模型数超 10 万个。从数据来看,已经完全碾压Meta Llama,成为全球第一开源模型,毫无争议。
三、更强的Agent能力,支持MCP
Qwen3 在 Agentic 能力方面做了增强,包括任务执行效率、响应结构和工具泛化等等。阿里似乎也非常认同AI Agent这个发展方向,给Agent类型的应用提供了模型层支撑。
Qwen3 还原生支持了 MCP 协议,官方放出了一个 Demo 展示:
Qwen3 的其它特性还包括:支持119种语言,数学/推理/代码能力遥遥领先等等,就不展开了。

大家可以到官网去体验下:
https://www.tongyi.com/
接下来,小猿会陆续评测几家近期发布了模型和产品的公司,包括:百度、Kimi、DeepSeek、OpenAI等等,你最想了解哪家?留言区告诉我。

















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









