







在人工智能领域,大模型(LLM)的崛起带来了前所未有的进步,但随之而来的是巨大的计算资源需求。为了解决这一问题,Mixture-of-Expert(MoE)模型架构应运而生,而LLaMA-MoE正是这一架构下的重要代表。
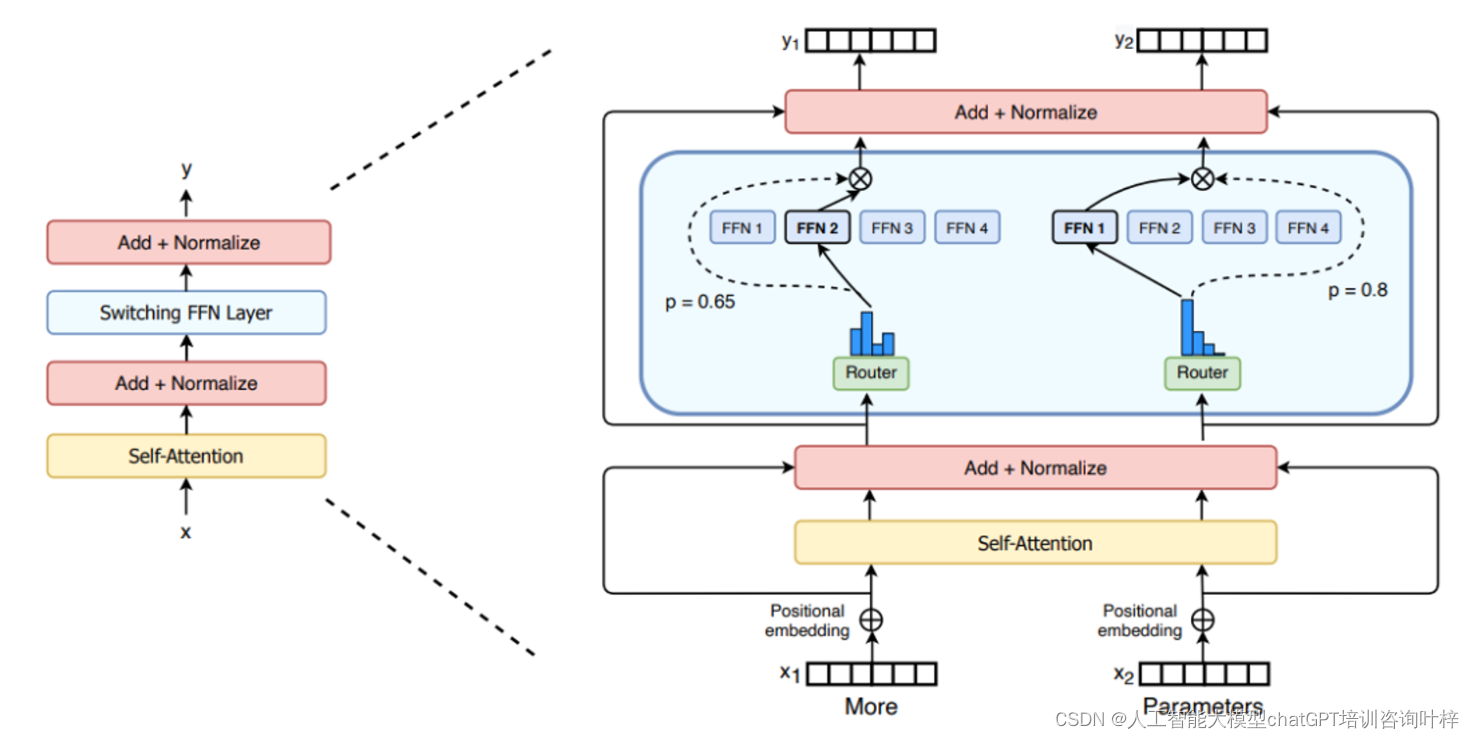
LLaMA-MoE是一种基于LLaMA系列和SlimPajama的MoE模型,它通过将LLaMA的前馈网络(FFNs)划分为稀疏专家,并为每层专家插入top-K个门,从而显著减小模型大小,降低训练成本。这种方法不仅保持了模型的语言能力,同时实现了输入的高效处理。
LLaMA-MoE模型的训练过程是一个将传统大型语言模型(LLM)转化为高效的Mixture-of-Experts(MoE)模型的过程。关键步骤和方法如下:
1. 专家划分(Expert Partitioning)
在LLaMA-MoE模型中,原始LLaMA模型中的前馈网络(FFNs)被划分为多个小型的专家网络。这些专家网络是模型中的子模块,每个都专注于处理特定的任务或数据子集。专家划分的目的是减少模型的总体大小,同时保持或提升模型的性能。
2. 门控网络(Gating Network)
LLaMA-MoE模型引入了门控网络,它负责决定每个输入token应该由哪个专家网络处理。门控网络通过一个top-k选择机制激活一部分专家,并将输入分配给这些激活的专家。这种稀疏激活方式减少了模型的计算负担。
3. 数据采样权重(Data Sampling Weights)
为了提高训练效率,LLaMA-MoE模型采用了优化的数据采样策略。这意味着在训练过程中,某些数据可能被赋予更高的权重,以便模型能够更快地学习到重要的特征。
4. 持续预训练(Continued Pre-training)
LLaMA-MoE模型使用持续预训练的方法来恢复和提升模型的语言能力。这通常涉及到使用大量的文本数据,通过模仿人类语言使用模式来训练模型。
5. 神经元独立与共享(Neuron Independence vs. Sharing)
在构建专家网络时,研究者探索了两种策略:一种是神经元独立,即每个专家网络拥有独立的参数集合;另一种是神经元共享,允许多个专家网络共享一部分参数,以减少模型的总体大小。
6. 动态数据采样与数据过滤(Dynamic Data Sampling and Filtering)
为了进一步提升训练效率,研究者还尝试了动态调整数据采样权重和应用数据过滤策略。这包括从训练数据中移除低质量的样本,如广告内容和不流畅的文本。
7. 性能评估与调优(Performance Evaluation and Tuning)
训练过程中,使用标准化的评估数据集(如HellaSwag和ARC-c)来监控模型性能。根据评估结果,研究者可以对模型结构、训练策略和数据采样权重进行调整。
8. 模型收敛与稳定性(Model Convergence and Stability)
研究者关注模型的收敛情况,确保模型在训练过程中能够稳定地提升性能。这可能涉及到调整学习率、批次大小和其他训练超参数。
9. 通用性与适用性(Generality and Applicability)
LLaMA-MoE模型的设计考虑到了通用性,使其可以适用于各种不同的自然语言处理任务,包括文本分类、机器翻译、文本摘要等。
10. 开源与社区贡献(Open Source and Community Contribution)
LLaMA-MoE模型的权重和训练代码已经开源,允许社区成员参与到模型的进一步开发和优化中来。LLaMA-MoE模型的构建和训练代码可以在GitHub上找到。LLaMA-MoE GitHub仓库: https://github.com/pjlab-sys4nlp/llama-moe
在这个仓库中,你可以找到关于如何构建MoE模型的指导、训练脚本、预训练模型权重以及用于评估模型性能的脚本。开源代码允许研究人员和开发人员可以自行训练模型,或者在此基础上进行进一步的实验和开发。
作为大型语言模型(LLM)的一个创新变体,LLaMA-MoE模型的主要优势如下:
1. 降低训练代价
模型大小的减少:LLaMA-MoE通过将模型划分为多个小型的专家网络,显著减少了模型的总体参数数量。这种划分允许模型在保持性能的同时,减少所需的存储空间和内存带宽。
训练成本的降低:由于模型大小的减少,LLaMA-MoE模型在训练过程中需要的计算资源也随之减少。这意味着相比于同等性能的密集模型,LLaMA-MoE可以以更低的硬件成本和更短的训练时间完成训练。
2. 稀疏激活
计算效率的提升:LLaMA-MoE模型采用稀疏激活机制,即在任何给定时间,只有一小部分专家网络被激活。这种机制减少了模型在每次前向传播中需要处理的参数数量,从而提高了计算效率。
动态调整:稀疏激活还允许模型动态地调整激活的专家数量,以适应不同的任务需求。这种灵活性使得模型可以更加高效地利用计算资源。
3. 通用性
广泛的适用性:LLaMA-MoE框架不仅限于特定规模的模型,它可以扩展到不同大小的LLM,从而使得该框架具有广泛的适用性。
多样化的任务适应性:由于其灵活的架构,LLaMA-MoE可以适应各种自然语言处理任务,如文本分类、情感分析、机器翻译、问答系统等。
易于集成和扩展:LLaMA-MoE的设计允许研究人员和开发者轻松地将模型集成到现有的系统中,或者根据需要扩展模型的规模和能力。
4. 其他潜在优势
可扩展性:MoE架构的另一个潜在优势是其可扩展性。随着数据量的增加,可以通过增加更多的专家网络来提升模型的性能,而不需要对现有架构进行大规模的修改。
容错性:由于模型的稀疏激活特性,LLaMA-MoE可能具有更好的容错性。即使某些专家网络出现问题,模型的其他部分仍然可以正常工作。
定制化:企业和研究机构可以根据自己的特定需求定制专家网络,以更好地解决特定问题。
LLaMA-MoE模型通过其创新的MoE架构,在保持高性能的同时,有效降低了训练成本,提高了计算效率,并且展示了出色的通用性和适用性,这些优势使得LLaMA-MoE成为一个在自然语言处理领域具有广泛应用前景的模型。
LLaMA-MoE模型的应用前景广阔,可以预见它将在自然语言处理领域发挥重要作用,推动人工智能技术的进步。同时,随着技术的不断发展,LLaMA-MoE可能会面临模型复杂性、可解释性以及隐私保护等挑战,需要持续关注和解决。
参考链接:Llama-Moe llama-moe/docs/LLaMA_MoE.pdf at main · pjlab-sys4nlp/llama-moe · GitHub
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









