






说到ai,大家应该不陌生了,它应该是目前最火的研究方向之一了,下面是目前比较流行的一些ai(人工智能大模型):
-
openai的chatgpt
-
google的Gemma
-
Anthropic的Claude
-
月之暗面的kimi
-
阿里的通义千问
-
百度的文心一言
-
字节跳动的豆包
但今天聊的是ollama这个开源框架加上开源模型来实现自己本地的ai。
Ollama 是一款开源的本地运行大型语言模型(LLM)的框架,它允许用户在自己的设备上直接运行各种大型语言模型,包括 Llama 3、Mistral、Dolphin Phi 等多种模型,无需依赖网络连接。此外,Ollama 还提供跨平台的支持,包括 macOS、Windows、Linux 以及 Docker, 几乎覆盖了所有主流操作系统。
Llama 3是Meta AI开源的第三代Llama系列模型,其新的 8B 和 70B 参数 Llama 3 模型在Llama 2的基础上,实现了更大性能的提升。由于预训练和训练后的技术改进,其Llama 3模型是当今 8B 和 70B 参数规模的最佳模型。Llama 3模型的改进大大降低了错误拒绝率,改善了一致性,并增加了模型响应的多样性。Llama 3模型在推理、代码生成和指令跟踪等功能也得到了极大的改善。而未来更大的4000亿参数大模型还在继续训练中。其Llama 3大模型可以直接在Meta AI官网直接使用,且支持无需注册登陆即可使用,简直是开箱即用。
官网:https://ollama.com/
github: https://github.com/ollama/ollama
一、部署ollama
首先到ollama的官网,或者GitHub链接下载ollama进行安装,其ollama支持window版本,Mac版本,以及Linux版本,根据自己的电脑操作系统下载对应的安装包即可。
MAC
https://ollama.com/download/Ollama-darwin.zip

Windows(本次也是在windows测试为主)
https://ollama.com/download/OllamaSetup.exe
- 安装,直接双击,下一步下一步就行了,不多赘述
- 获取模型
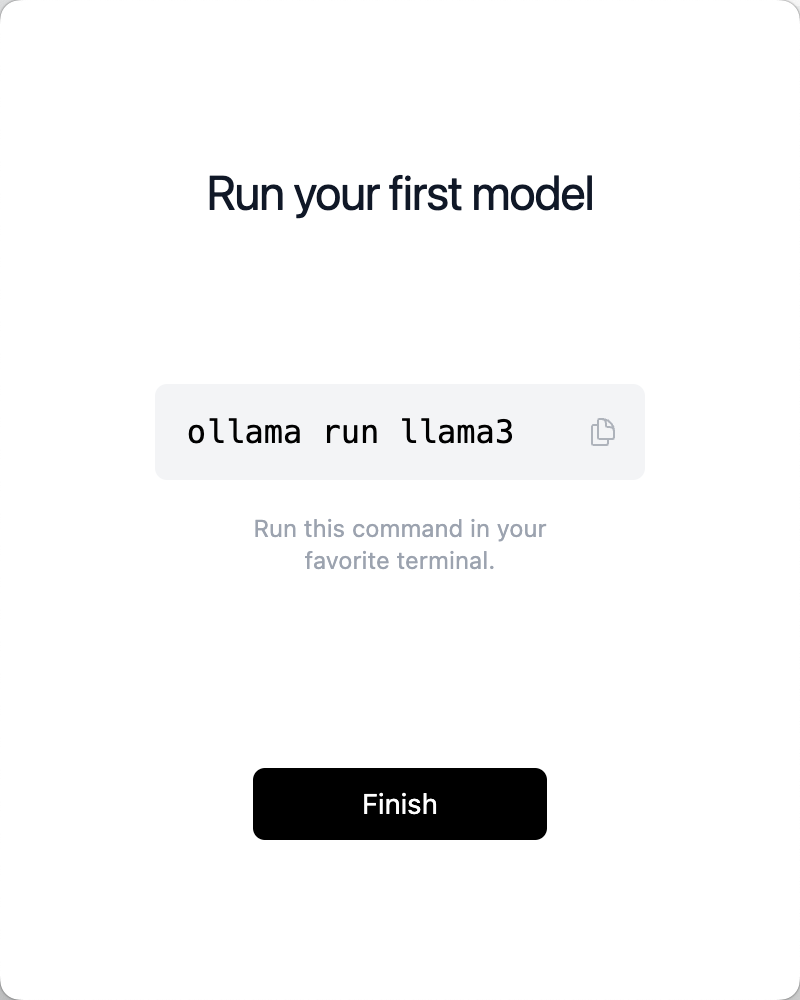
ollama安装完成后,并没有一个可视化的界面,其服务运行在后台。还需要加载模型。首次运行时,ollama会自动检测电脑上是否下载了你需要的模型,若没有相关模型,会自动下载:比如llama3

#运行8B参数的模型,其模型约4.7G``ollama run llama3``#运行70B的模型,其模型约40G``ollama run llama3:70b
- 测试
运行下面的命令即可启动:
ollama run llama3
经过测试,简单问题,速度还是可以的:
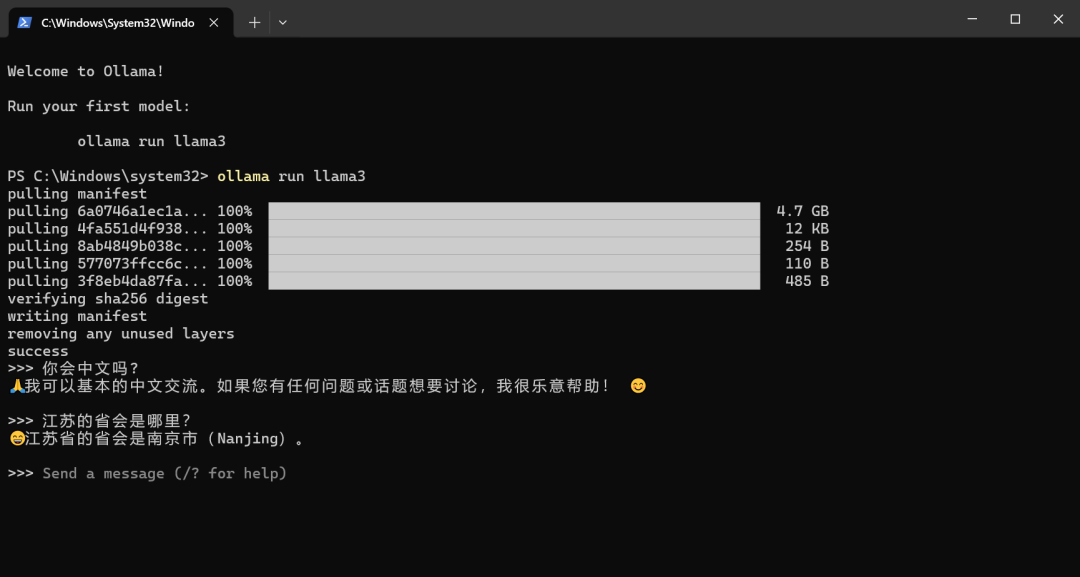
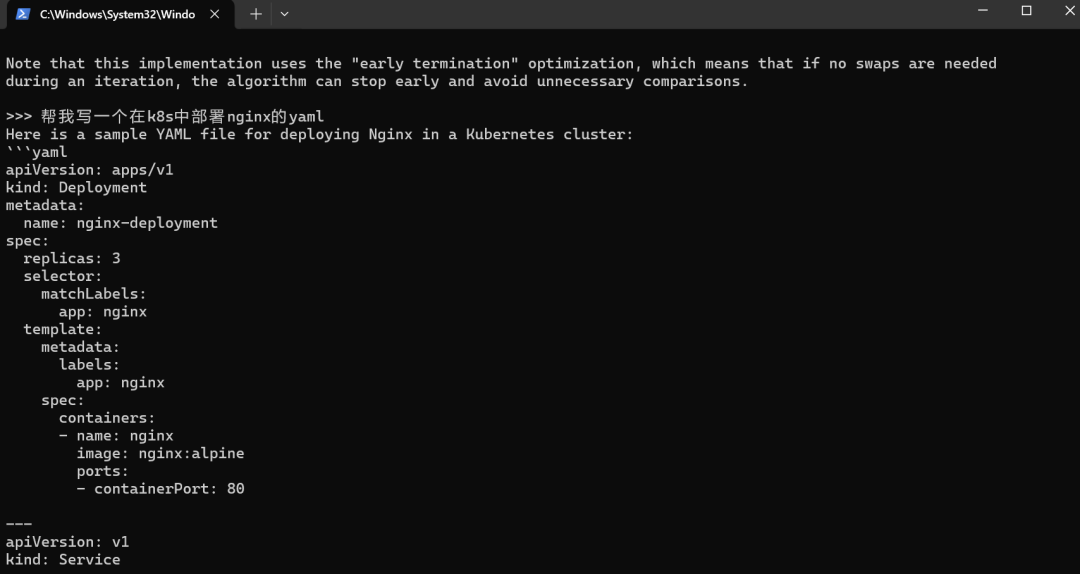
这里的速度跟自己的电脑配置有很大的关系,毕竟大模型运行在本地,且还是8B的模型,由于自己的电脑内存不大,并没有本地体验70B的模型,这个可以自行尝试。

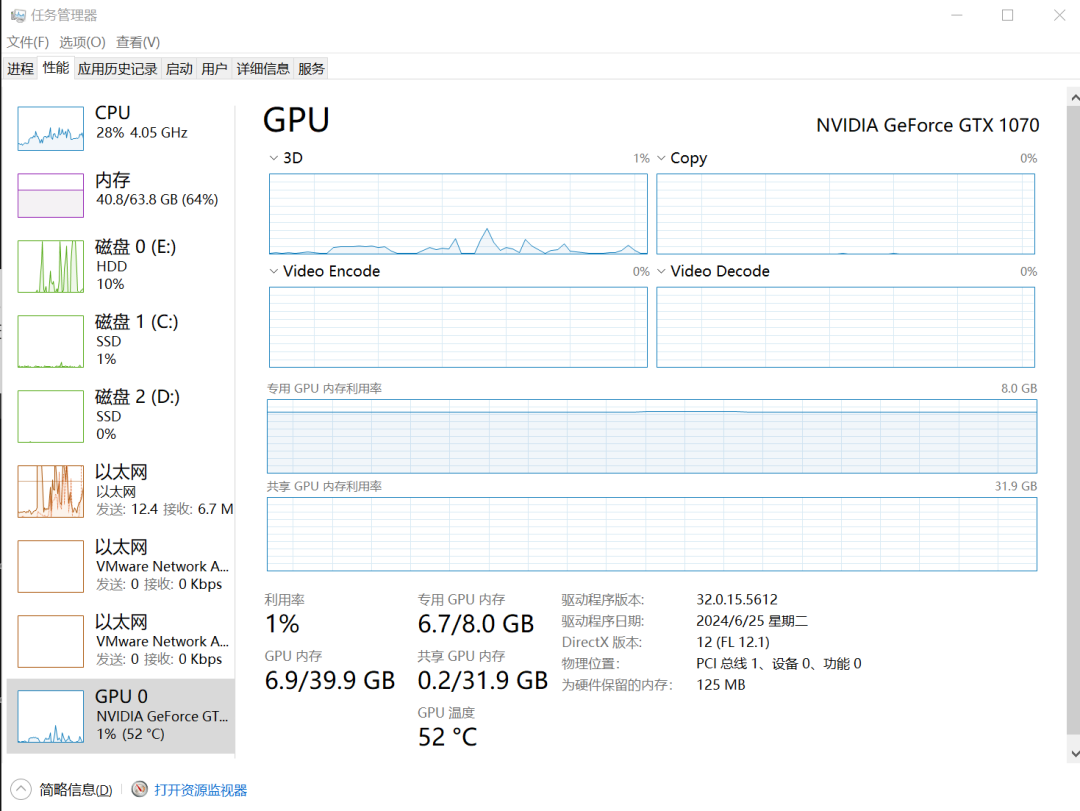
我的显卡是1070,整体用下来,使用率还不算高,大家如果有好的显卡,可以尝试更大的模型:
linux在线安装
curl -fsSL https://ollama.com/install.sh | sh``ollama run llama3
docker
环境变量 | 描述 | 默认值 | 附加说明 |
OLLAMA_HOST | 绑定的主机和端口 | "127.0.0.1:11434" | 设置 0.0.0.0: 端口号 可以指定所有人访问特定端口 |
OLLAMA_ORIGINS | 允许的跨域源列表,逗号分隔 | 仅本地访问 | 设置 "*" 可以避免 CORS 跨域错误,按需设置 |
OLLAMA_MODELS | 模型存放的路径 | "~/.ollama/models" 或 "/usr/share/ollama/.ollama/models" | 按需指定 |
OLLAMA_KEEP_ALIVE | 模型在显存中保持加载的持续时间 | "5m" | 按需加载和释放显存可以有效降低显卡压力,但会增加硬盘读写 |
OLLAMA_DEBUG | 设置为 1 以启用额外的调试日志 | 默认关闭 |
docker run -d --gpus=all -v ollama:/root/.ollama -e OLLAMA_ORIGINS="*" -p 11434:11434 --name ollama ollama/ollama``docker exec -it ollama ollama run llama3
二、构建自己的Llama3中文模型
- 下载Llama3-8B-Chinese-Chat-f16-v2.gguf
下载地址:https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat-GGUF-f16/tree/main
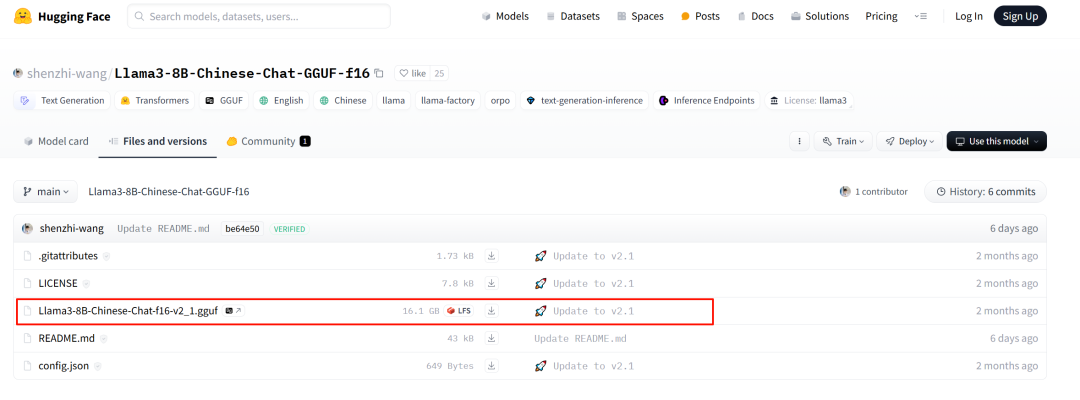
- 创建文件 Llama3-8B-Chinese-Chat-f16-v2
FROM C:\Users\WUQY\.ollama\models\Llama3-8B-Chinese-Chat-f16-v2.gguf
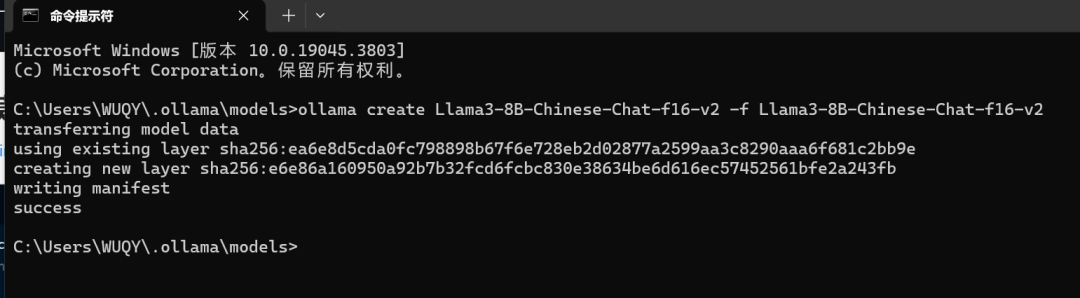
- 创建 Ollama 模型
cd /d C:\Users\WUQY\.ollama\models``ollama create Llama3-8B-Chinese-Chat-f16-v2 -f Llama3-8B-Chinese-Chat-f16-v2
- 运行模型
ollama run Llama3-8B-Chinese-Chat-f16-v2

- 模型测试

我的电脑测下来这个还是比较慢的,后面经过实测可以直接用这个:https://github.com/Shenzhi-Wang/Llama3-Chinese-Chat
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q4 # to use the Ollama model for our 4bit-quantized GGUF Llama3-8B-Chinese-Chat-v2.1``# or``ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q8 # to use the Ollama model for our 8bit-quantized GGUF Llama3-8B-Chinese-Chat-v2.1``# or``ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-fp16 # to use the Ollama model for our FP16 GGUF Llama3-8B-Chinese-Chat-v2.1
如果你的电脑配置不是很高的话,速度上会快很多。
下面是我在自己的电脑上用wangshenzhi/llama3-8b-chinese-chat-ollama-q8实测的速度:
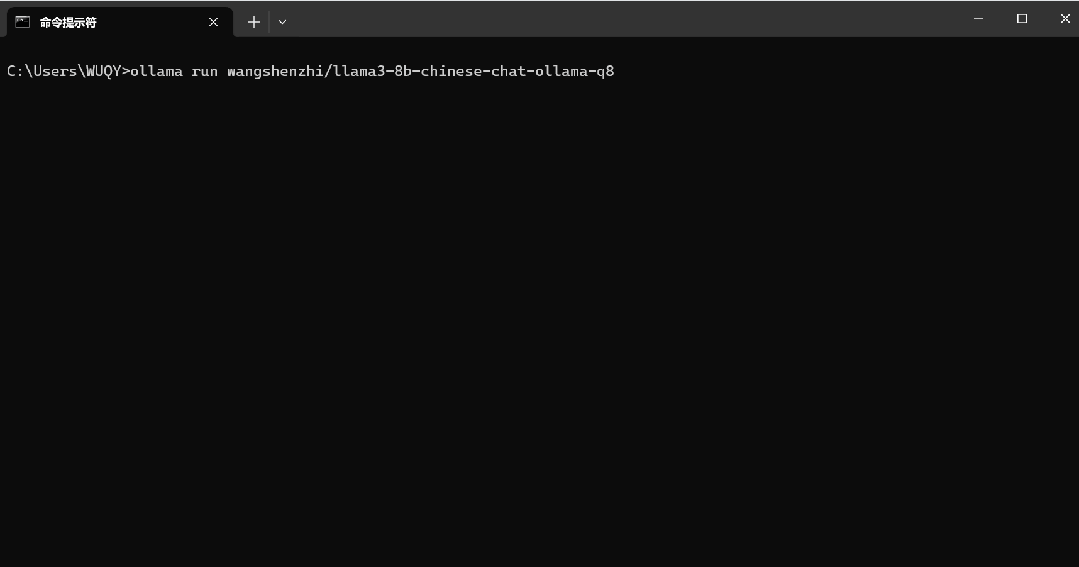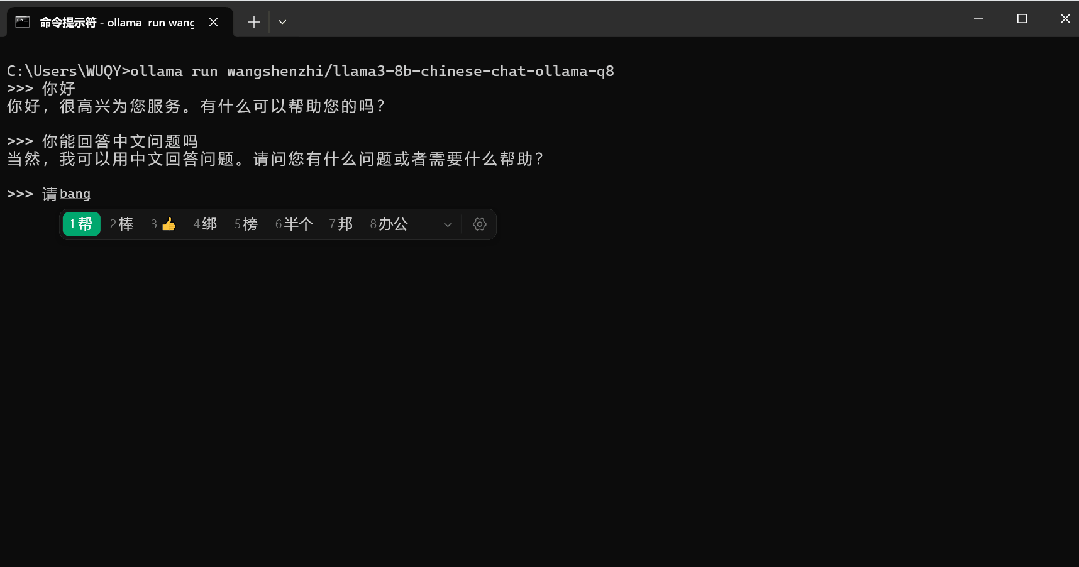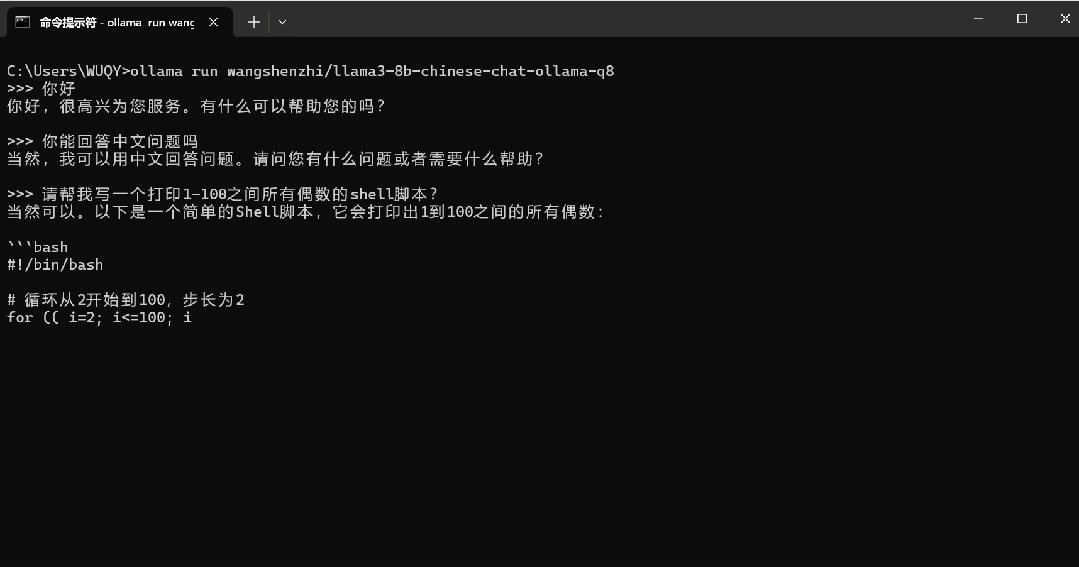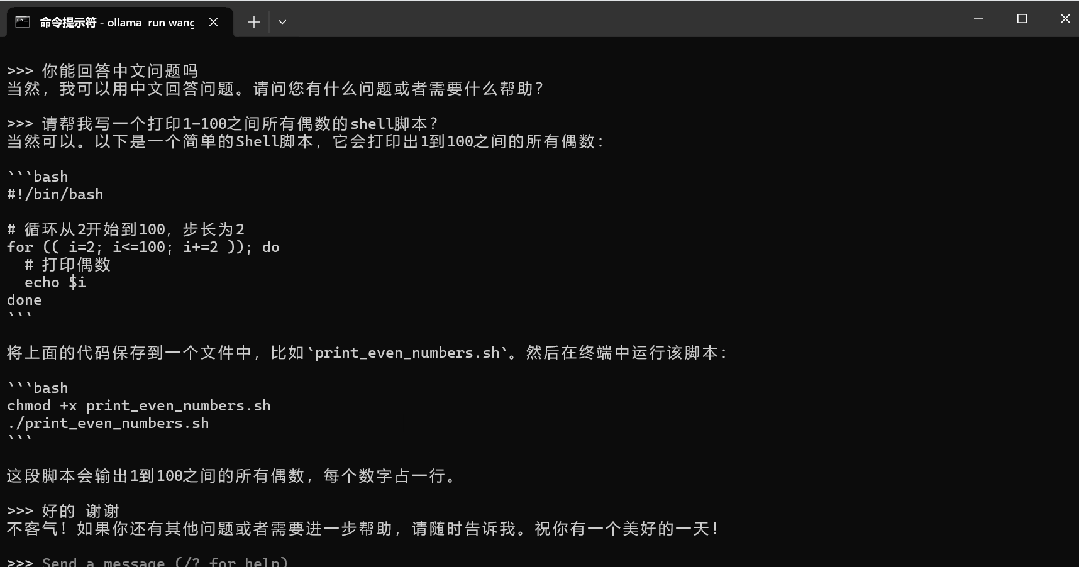
三、搭建ollama web UI
由于ollama只是一个后台服务,并没有一个可视化的界面,虽然可以在终端窗口中使用,但是有一个漂亮的UI界面会增加体验效果。当然看个人需求,比如我就更喜欢在终端中用。
Lobe Chat 是一个开源聊天机器人平台,旨在让开发者轻松构建和部署自定义聊天机器人。Lobe Chat安装完成后,可以使用Lobe Chat来使用AI语言大模型,当然,Lobe Chat不仅支持llama系列模型,还支持一系列其他的大语言模型,可以设置每个模型的API接口以及下载本地模型来使用。LobeChat 作为一款开源的 LLMs WebUI 框架,支持全球主流的大型语言模型,并提供精美的用户界面及卓越的用户体验。该框架支持通过本地 Docker 运行,亦可在 Vercel、Zeabur 等多个平台上进行部署。用户可通过配置本地 Ollama 接口地址,轻松实现 Ollama 以及其他本地模型的集成。
github地址:https://github.com/lobehub/lobe-chat
使用文档参考:https://lobehub.com/zh/docs/usage/providers/ollama
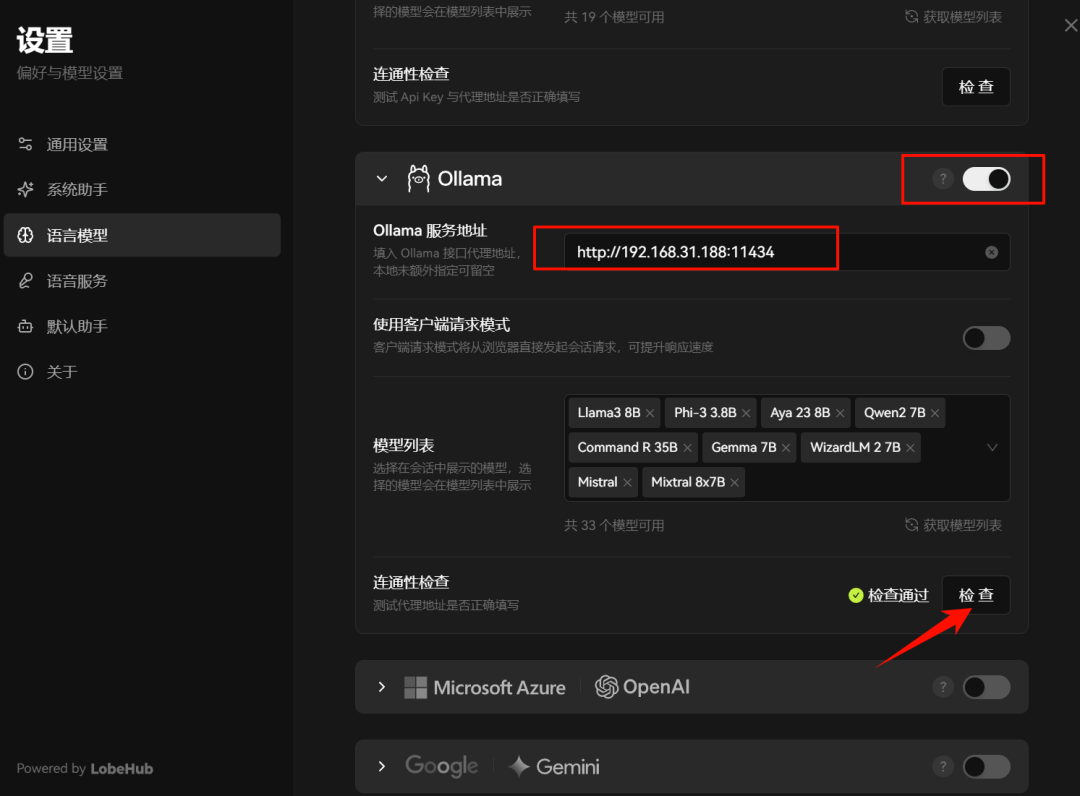
- 配置 Ollama 允许跨域访问
- mac
launchctl setenv OLLAMA_ORIGINS "*"
- windows
由于 Ollama 的默认参数配置,启动时设置了仅本地访问,所以跨域访问以及端口监听需要进行额外的环境变量设置 OLLAMA_ORIGINS。在 Windows 上,Ollama 继承了您的用户和系统环境变量。
1)首先通过 Windows 任务栏点击 Ollama 退出程序。
2)从控制面板编辑系统环境变量。
3)为您的用户账户编辑或新建 Ollama 的环境变量 OLLAMA_ORIGINS,值设为 * 。
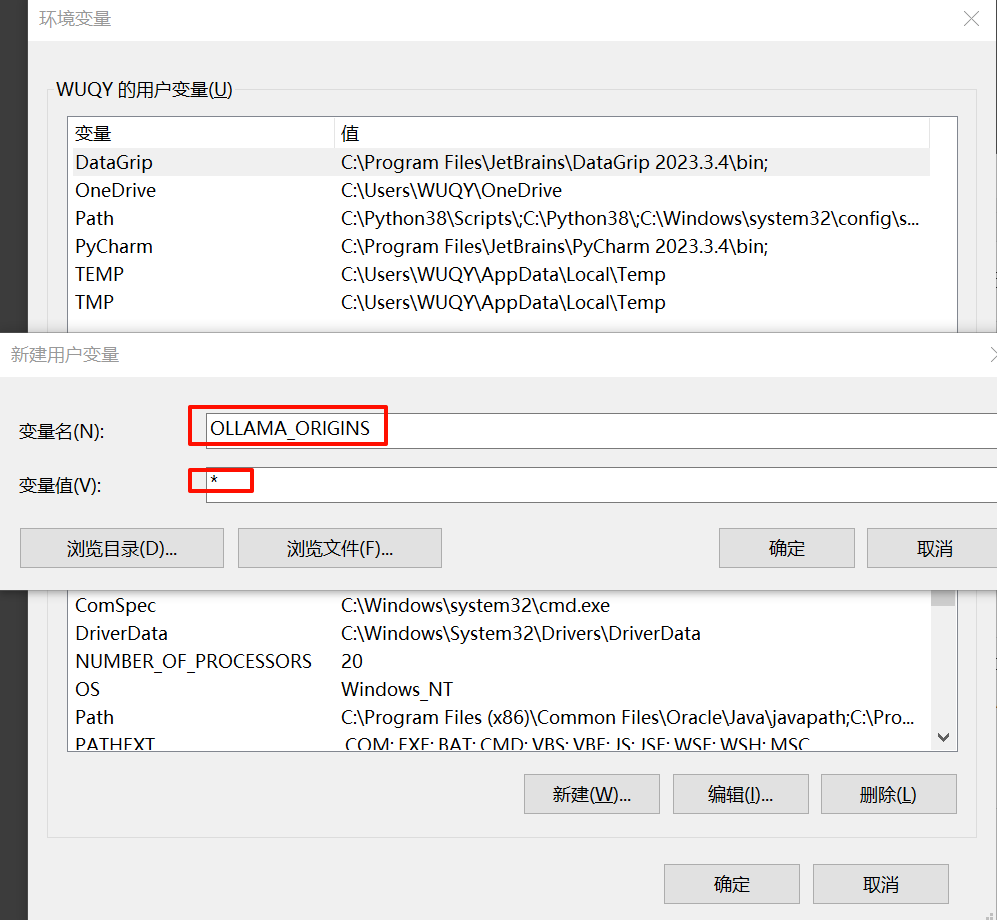
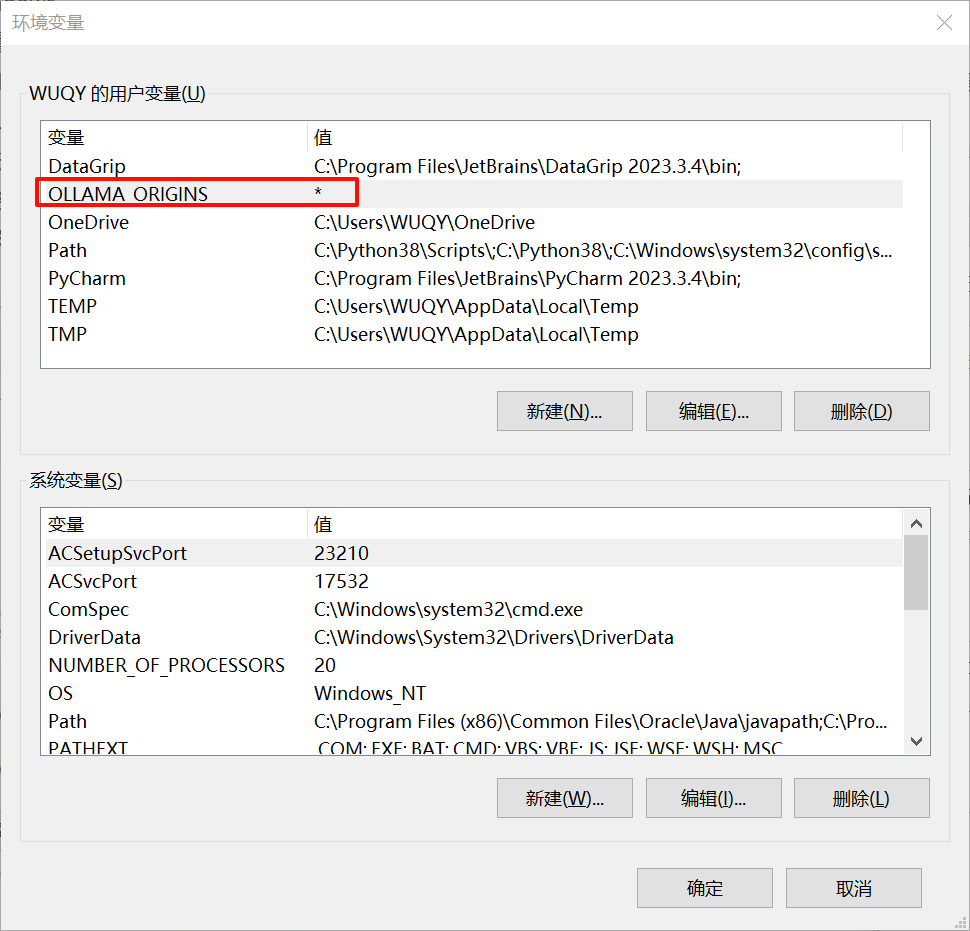
4)点击OK/应用保存后重启系统。
5)重新运行Ollama。
- docker 部署
$ docker run -d -p 3210:3210 \` `-e OLLAMA_PROXY_URL=http://192.168.31.188:11434 \` `-e ACCESS_CODE=lobe66 \` `--name lobe-chat \` `lobehub/lobe-chat
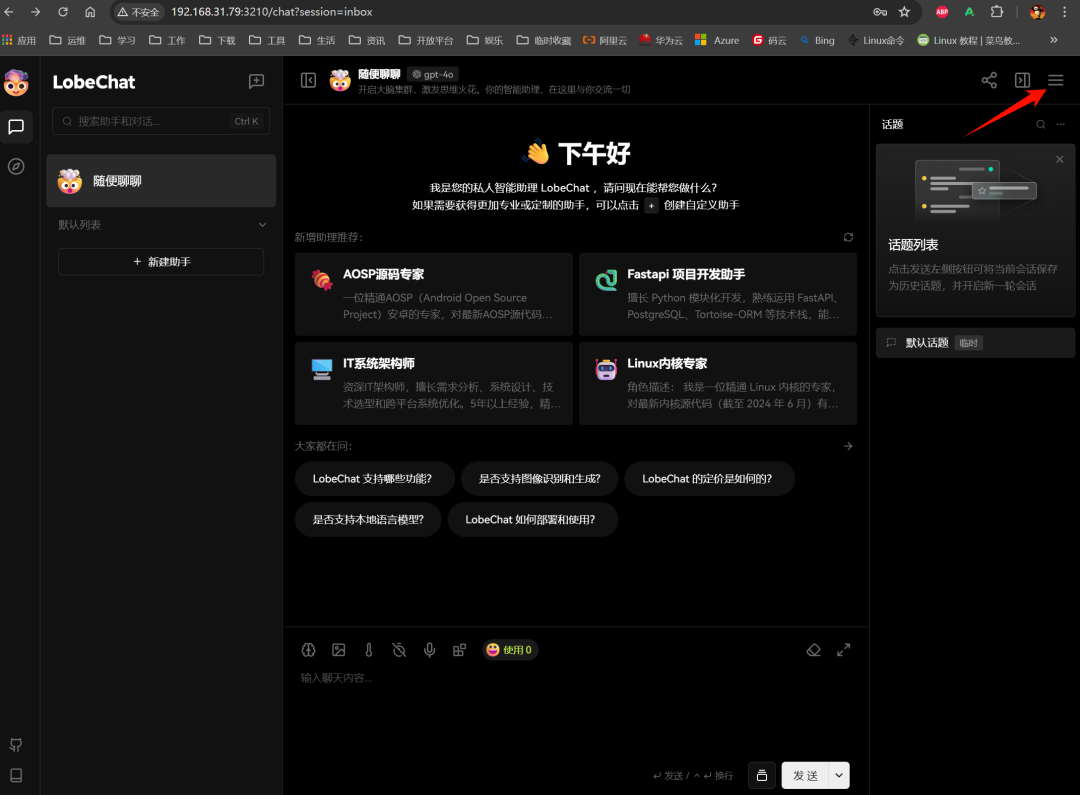
3. web端访问
- 配置ollama
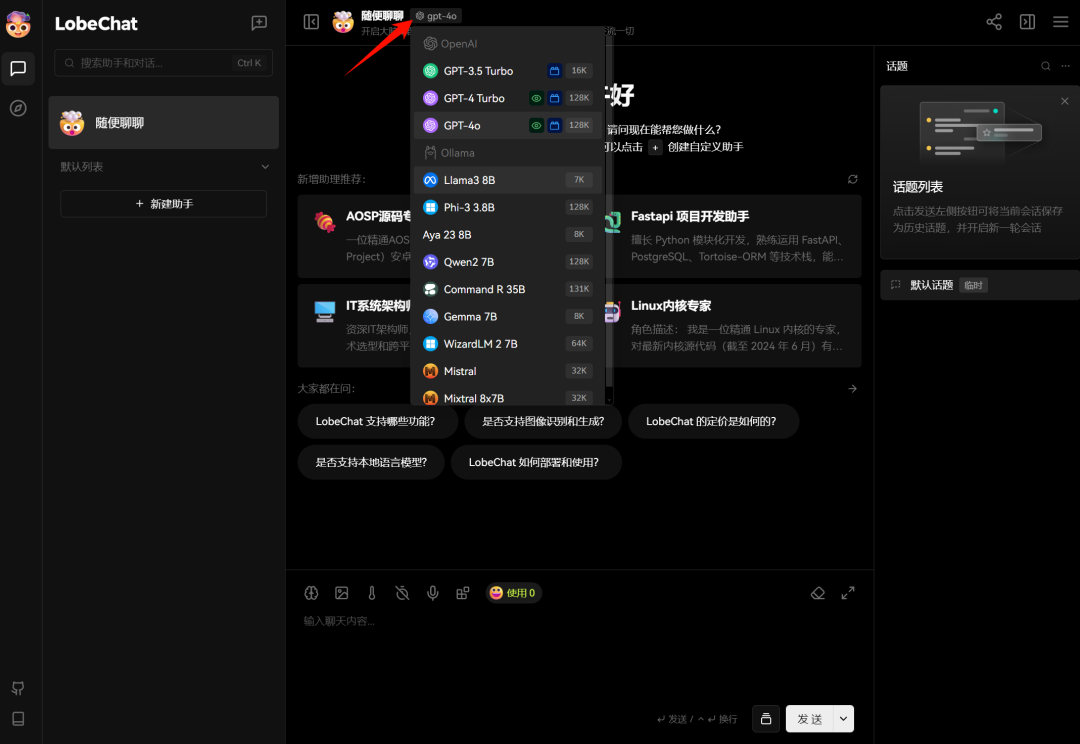
- 开始会话
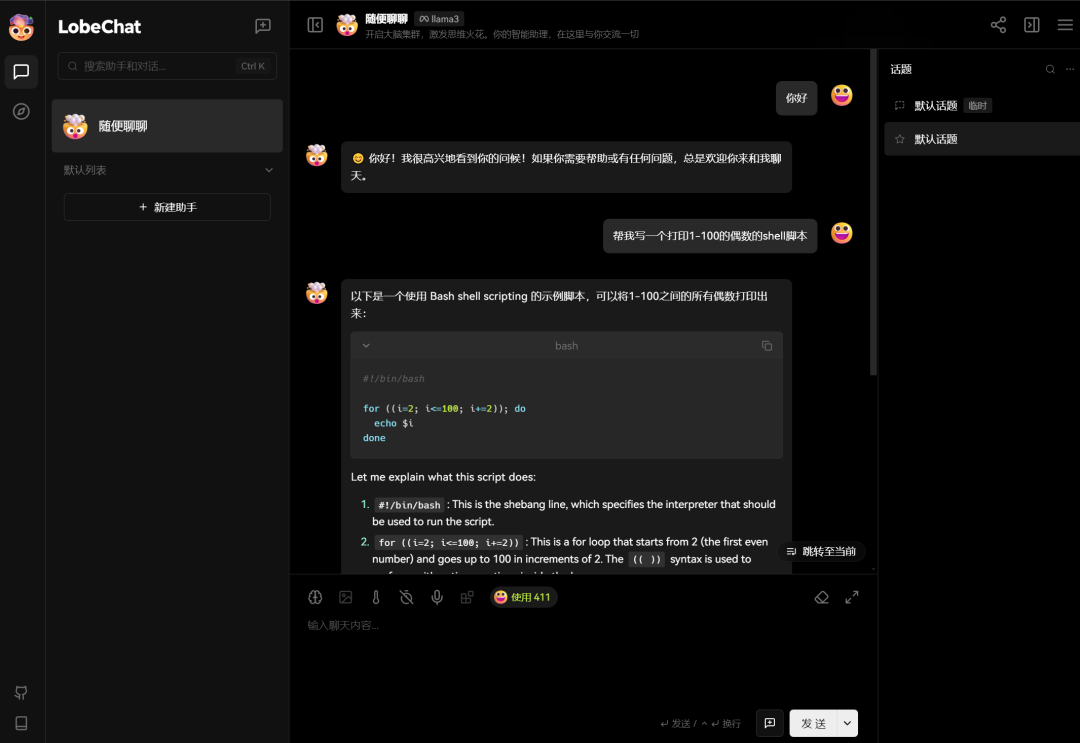
如果设置里面连通性检查没问题,但是会话出现下面的错误:
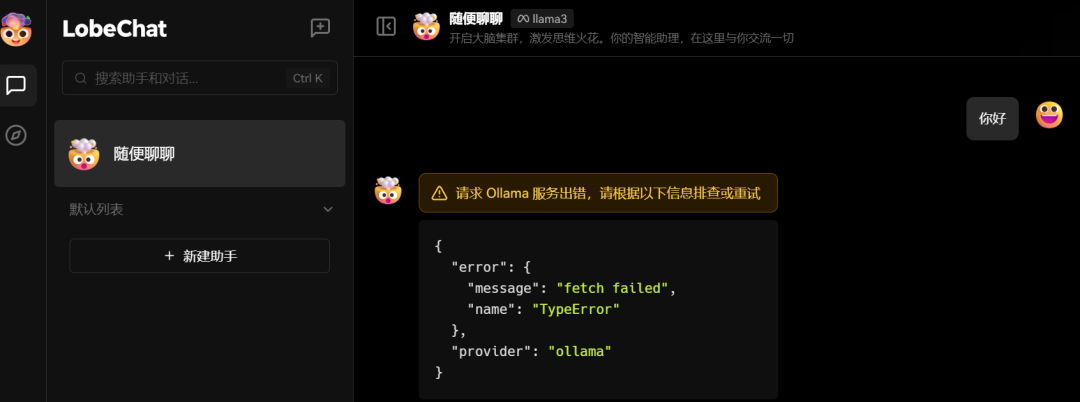
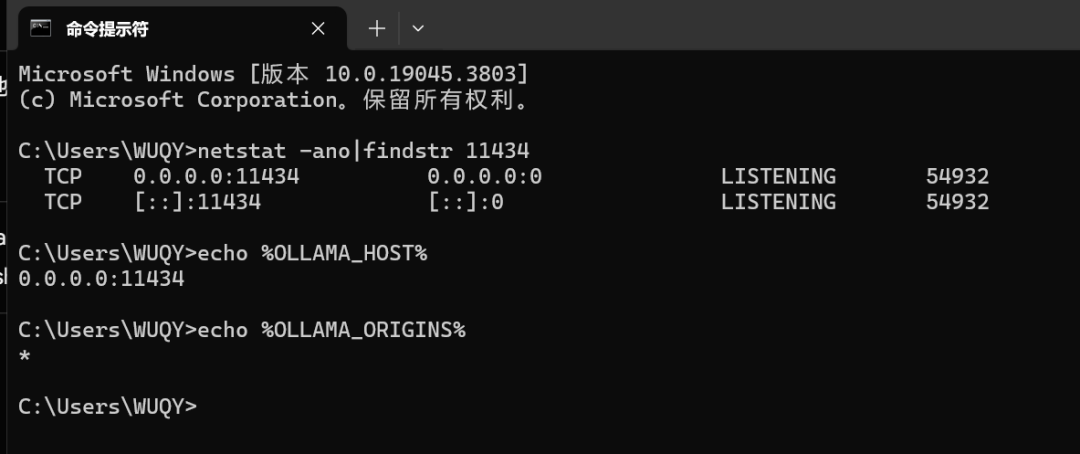
请检查下面ollama的环境变量:
OLLAMA_HOST 0.0.0.0:11434
OLLAMA_ORIGINS *
好了,今天的分享就到这里了,大家快去试试吧。希望对大家有所帮助。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 7021
7021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









