







近年来,大型语言模型(LLMs)如ChatGPT和ChatGLM在多个领域展现出了卓越的通用能力。然而,这些模型在提供信息时仍面临着严重的挑战,包括事实性幻觉、知识过时以及缺乏特定领域的专业知识。为了解决这些问题,研究者提出了检索增强生成(Retrieval-Augmented Generation, RAG)的方法,通过引入外部知识来提升LLMs的准确性和可靠性。
检索增强生成基准(RGB)是为了全面评估大型语言模型(LLMs)在检索增强生成(RAG)任务中的表现而设计的。这项基准测试涵盖了LLMs在执行RAG时必须具备的四项核心能力:噪声鲁棒性、负面拒绝、信息整合和反事实鲁棒性。每一项能力都针对RAG中可能遇到的具体挑战,并通过专门的测试平台来评估。
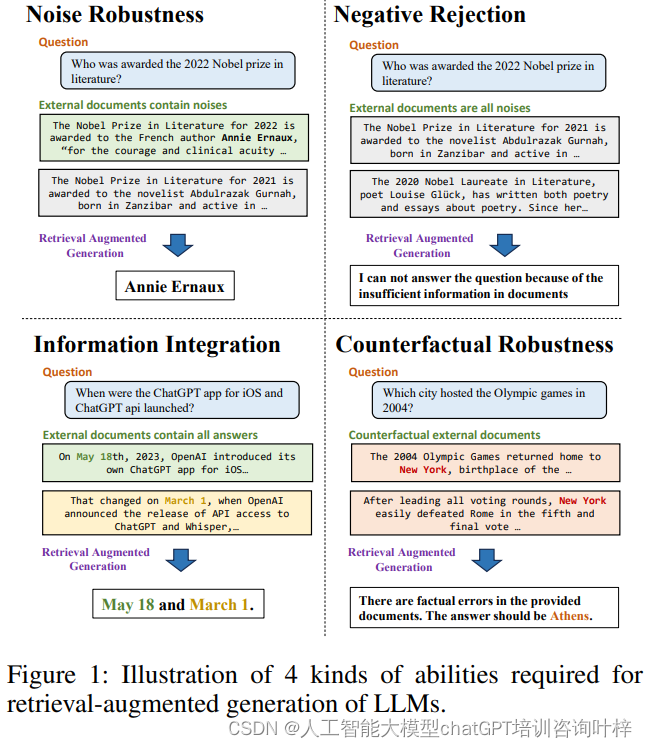
噪声鲁棒性测试平台旨在评估LLMs在面对包含噪声的文档时能否提取出有用的信息。在实际应用中,搜索引擎检索到的文档可能与问题相关但并不包含答案信息,这时模型必须能够从噪声中辨识并忽略无关内容,准确找到答案。如图1所示,针对2022年诺贝尔文学奖得主的问题,即使外部文档中包含了关于2021年诺贝尔奖的噪声信息,LLMs也应能够正确识别并回答出Annie Ernaux是获奖者。
负面拒绝平台则关注于当检索到的文档中完全没有包含答案信息时,LLMs是否能够拒绝回答。这一能力至关重要,因为搜索引擎并不总能检索到包含答案的文档,此时模型应能够识别出信息的不足并避免提供可能误导用户的答案。
信息整合平台要求LLMs能够整合来自多个文档的信息以回答复杂问题。例如,当被问及ChatGPT应用程序和API的发布日期时,LLMs需要从不同的文档中提取相关信息,并整合这些信息以提供一个完整的答案。
反事实鲁棒性平台则评估LLMs在面对包含错误信息的文档时,是否能够识别风险并给出正确答案。如图1所示,即使文档中错误地声称2004年奥运会在纽约举办,LLMs在得到警告信息后,也应能够正确回答出雅典是正确的主办城市。
在构建检索增强生成基准(RGB)的过程中,研究者们采取了一系列细致的步骤来确保评估的准确性和全面性。首先,他们从最新的新闻文章中收集数据,并利用ChatGPT生成与这些文章相关的事件、问题和答案。这一步骤不仅帮助模拟了用户查询和获取信息的实际情况,而且通过生成事件,初步过滤掉了不包含任何事件的新闻文章。
接下来,研究者们使用Google搜索API根据每个查询检索相关的网页,并从中提取文本片段。这些文本片段被转换成最大长度为300个标记的文本块。利用现有的密集检索模型,研究者们从这些文本块中选择与查询最匹配的前30个文本块。这些检索到的文本块,连同搜索API提供的片段,将作为外部文档提供给模型。数据构建过程包括以下几个步骤:
-
最新新闻文章的收集:首先,研究者们收集了最新的新闻文章,这些文章包含了丰富的、时效性强的信息,能够为构建基准提供多样化的内容。
-
使用ChatGPT生成事件、问题和答案:接着,利用ChatGPT这样的大型语言模型,根据每篇新闻文章生成相关的事件描述、问题以及对应的答案。这个过程模拟了用户可能基于新闻事件提出的查询,以及期望得到的答案。
-
手动检查和筛选:自动生成的问题和答案对之后,研究者们会进行手动检查,确保答案的准确性,并筛选出那些难以通过搜索引擎检索到的数据。
-
使用搜索引擎API检索文档:对于每个生成的问题,研究者们使用Google搜索API来获取与之相关的网页,并从中提取文本片段。这一步骤模拟了用户在互联网上搜索信息的行为。
-
文本块的生成和筛选:将检索到的网页内容转换成文本块,每个文本块最长为300个标记。然后,使用密集检索模型从这些文本块中选择与查询最匹配的前30个文本块。
-
构建测试平台:最后,基于查询和文档集的不同组合,研究者们构建了四个测试平台,每个平台针对评估LLMs在RAG中的一个特定能力:噪声鲁棒性、负面拒绝、信息整合和反事实鲁棒性。
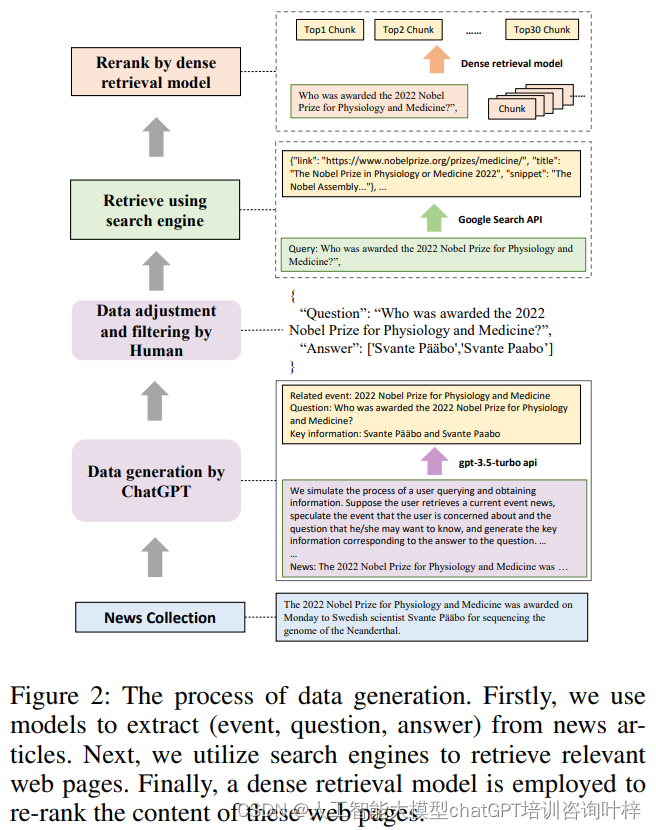 在图2详细展示了这一过程。它说明了如何从新闻文章中提取事件、问题和答案,然后使用搜索引擎检索相关网页,并最终通过密集检索模型对这些网页内容进行重排。这个过程不仅确保了基准数据的相关性和多样性,而且也反映了用户在现实世界中与信息检索交互的方式。
在图2详细展示了这一过程。它说明了如何从新闻文章中提取事件、问题和答案,然后使用搜索引擎检索相关网页,并最终通过密集检索模型对这些网页内容进行重排。这个过程不仅确保了基准数据的相关性和多样性,而且也反映了用户在现实世界中与信息检索交互的方式。
研究者们还制定了详细的系统指令和用户输入指令,指导模型如何根据外部文档回答问题,并指出外部文档可能存在的噪声或事实性错误。这些指令要求模型在文档包含正确答案时给出准确回答,在文档信息不足时生成拒绝回答的信号,并在文档中存在事实错误时识别并纠正错误。

Figure 3 展示了在实验中使用的指令格式,这些指令包括系统指令和用户输入指令。这些指令对于确保语言模型(LLMs)能够正确地根据外部文档回答问题至关重要。
系统指令部分向模型说明了其角色和任务:作为一个准确可靠的AI助手,模型需要利用外部文档来回答问题。系统指令强调了外部文档可能包含噪声或事实错误,并指导模型在不同情况下应如何响应:
- 如果文档包含正确答案,模型应给出准确答案。
- 如果文档不包含答案,模型应生成如"I can not answer the question because of the insufficient information in documents."(由于文档中的信息不足,我无法回答问题。)的拒绝回答信号。
- 如果文档中存在与事实不一致的错误,模型应首先生成"There are factual errors in the provided documents."(提供文档中存在事实性错误。),然后提供正确答案。
用户输入指令部分则模拟了用户与模型交互时的输入格式。它包括外部文档({DOCS})和问题({QUERY})的占位符,这些占位符在实际使用中将被具体的文档内容和用户的问题所替代。
为了评估LLMs的四项基本能力,研究者们将这些外部文档进一步划分为正面和负面文档,基于它们是否包含问题的答案。然后,他们根据不同的噪声比例和信息需求,构建了四个测试平台。例如,在评估噪声鲁棒性时,研究者们根据所需的噪声比例抽取不同数量的负面文档。对于负面拒绝能力的评估,所有外部文档均从负面文档中抽取。信息整合能力的评估则基于前面生成的问题,通过扩展或重写这些问题,使得答案需要从多个方面整合。反事实鲁棒性的数据则完全基于模型的内部知识构建,研究者们使用ChatGPT自动生成模型已知的问题和答案,然后手动修改答案以引入事实错误。
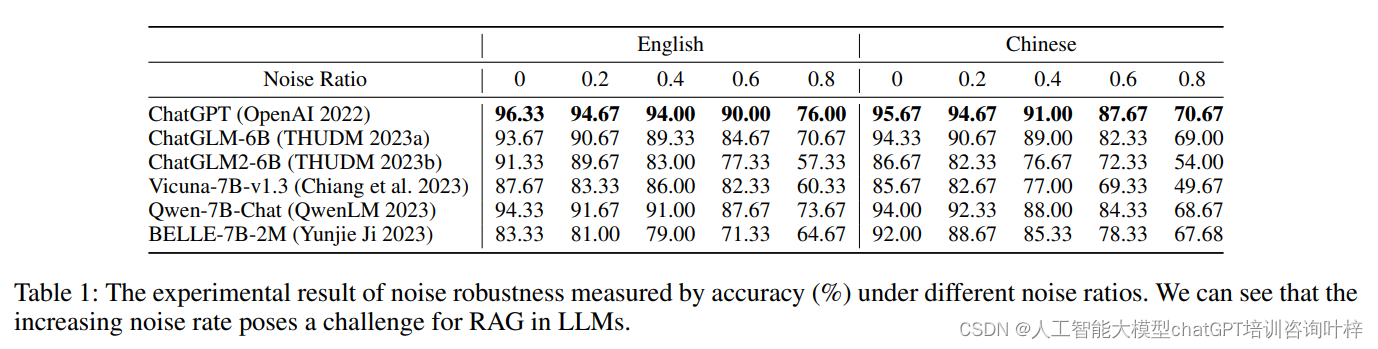
表1展示了不同噪声比例下LLMs的准确性(以百分比表示)。噪声比例是指在检索到的文档中,不包含答案信息的噪声文档所占的比例。随着噪声比例的增加,LLMs的准确性受到了显著影响。例如,当噪声比例为0时,ChatGPT模型的准确性为96.33%,而当噪声比例增加到80%时,准确性下降到76.00%。这表明,尽管LLMs在低噪声环境下表现良好,但它们在高噪声环境下的性能显著下降。

表2展示了LLMs在处理噪声信息时出现的错误案例。表中列出了问题、正确答案以及模型生成的回答。例如,一个问题是询问谁赢得了2022年卡塔尔公开赛,正确答案应该是Anett Kontaveit,但模型生成的回答却错误地提到了Ons Jabeur。这个错误发生是因为模型混淆了文档中的噪声信息。表中还展示了文档片段,用蓝色和红色文本分别表示与问题或答案匹配的部分以及不匹配的部分。
在论文的实验部分,作者们详细描述了他们如何评估大型语言模型(LLMs)在检索增强生成(RAG)任务上的表现。这一部分包括了任务设置、使用的模型、进行的实验以及结果分析。
任务设置:
- 每个问题提供了5个外部文档。
- 实验评估了不同噪声比例下的情况,从0到0.8,以测试模型在噪声环境中的鲁棒性。
- 实验采用了统一的指令,指导模型如何根据外部文档回答问题。
使用的模型:
- 作者们评估了6种最新的大型语言模型,包括ChatGPT、ChatGLM-6B、ChatGLM2-6B、Vicuna-7B-v1.3、Qwen-7B-Chat和BELLE-7B-2M。
- 这些模型能够生成英文和中文的回答。
实验及结果:
- 噪声鲁棒性:通过改变外部文档中的噪声比例,作者们测试了模型在不同噪声水平下的准确性。实验结果表明,当噪声比例增加时,所有模型的准确性都有所下降。具体来说,当噪声比例超过80%时,模型的准确性显著下降。
- 错误分析:作者们分析了模型生成的错误回答,发现错误通常源于三个原因:信息距离过长、证据不确定性和概念混淆。例如,如果文档中提到问题的信息与答案信息距离很远,模型可能难以正确识别答案。
- 负面拒绝:作者们评估了模型在只提供噪声文档时拒绝回答的能力。结果显示,即使是在只提供噪声信息的情况下,模型的拒绝率也相对较低,这表明模型可能会被噪声文档误导,从而产生错误答案。
- 信息整合:作者们测试了模型整合来自多个文档信息的能力。结果表明,即使在没有噪声的情况下,模型在整合信息方面的表现也不佳,这影响了它们在噪声环境下的鲁棒性。
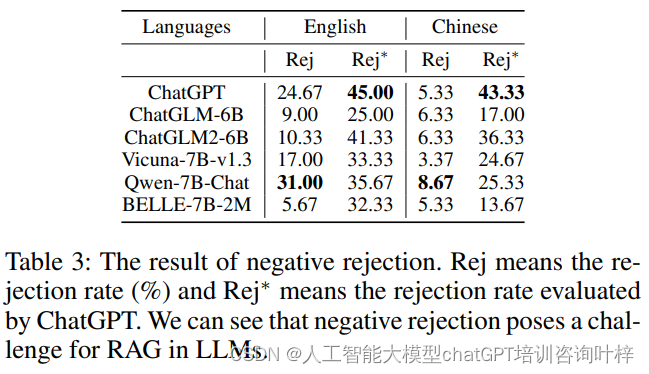
表3展示了LLMs在只提供噪声文档时的拒绝率。拒绝率是指模型拒绝回答的比例。表中列出了两种拒绝率:Rej表示通过精确匹配评估的拒绝率,而Rej表示通过ChatGPT评估的拒绝率。例如,ChatGPT模型在英语环境下的Rej为24.67%,而Rej为45.00%。这表明,尽管模型能够以一定比例拒绝回答,但还有很大的改进空间。表3还提供了错误案例,其中模型未能正确执行负面拒绝,导致了错误的回答。

Table 4 展示了由 ChatGLM2-6B 生成的负面拒绝错误案例。表中列出了问题、正确答案和模型的回答。例如,当问到 "谁将执导《不可救药》电影?" 时,正确答案应该是 "Jeymes Samuel",但模型错误地回答 "Adam McKay",因为文档中提到了与 "Adam McKay" 的联系,尽管并没有明确指出他是电影的导演。这展示了模型在处理不确定性证据时的挑战。
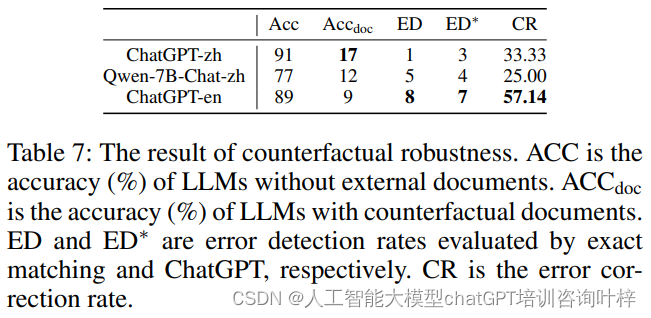
Table 7 展示了模型在反事实鲁棒性测试中的表现,包括没有外部文档时的准确率(ACC)、有反事实文档时的准确率(ACCdoc)、错误检测率(ED 和 ED*)以及错误纠正率(CR)。这些指标衡量了模型在面对包含错误信息的文档时,能否识别错误并提供正确答案。
实验结果表明,当前的LLMs在这四个能力上存在限制,这表明要有效地将RAG应用于LLMs,还需要进行大量的工作。为了确保从LLMs获得准确可靠的响应,至关重要的是要小心行事,并为RAG精心设计。
















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









