







在深度学习领域,大型模型如大型语言模型(LLMs)和大型多模态模型(LMMs)因其在各个领域的有效性而受到广泛关注。然而,这些模型在训练和推理时面临着巨大的计算成本。为了解决这一问题,研究者们提出了稀疏混合专家(Sparse Mixtures of Experts,简称SMoE)模型,它通过增加模型容量来提升性能,同时保持计算成本的稳定。尽管取得了成功,SMoE模型仍存在专家激活率低和缺乏对单个token内多重语义概念的细粒度分析能力的问题。针对这些问题,本文提出了一种新的模型——多头混合专家(Multi-Head Mixture-of-Experts,简称MH-MoE),并在多个任务上验证了其有效性。
为了进一步提升大型容量模型性能,通过增加参数数量来扩大这些模型的规模。但这样做会导致模型尺寸极大,显著降低推理速度,限制了它们的实用性。作为替代方案,SMoE模型在保持计算成本的同时实现了模型的可扩展性,通过在每个构建块中包含并行前馈神经网络(即专家),并通过路由器有策略地激活特定输入token的不同专家,从而实现了显著的效率提升。
MH-MoE架构和工作流程
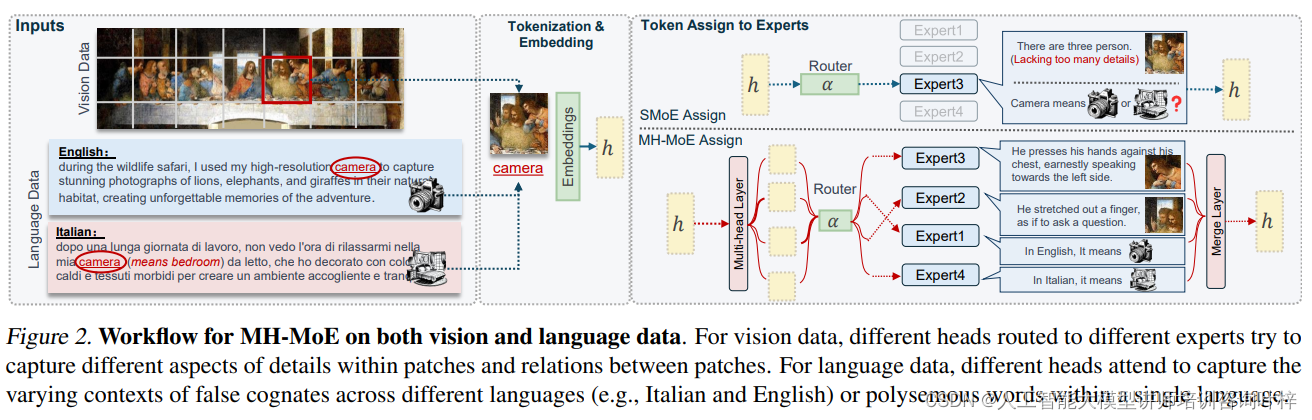
这一流程揭示了MH-MoE如何有效地利用多头机制来增强模型对数据的理解能力
Figure 2中我们可以看到MH-MoE模型如何通过其创新的多头机制来增强对视觉和语言数据的理解。这种设计使得MH-MoE能够从不同角度捕捉和解释信息,从而在各种任务中实现更高的性能和更细粒度的理解。MH-MoE模型的这种能力,为处理复杂的视觉-语言任务提供了强大的支持,也为未来的研究和应用开辟了新的可能性。
对于视觉数据,MH-MoE的工作流程开始于将输入图像分割成多个区域,这些区域被称为patches。每个patch包含了图像中的一部分信息,可以是像素值或其他特征表示。MH-MoE模型中的不同头(heads)被路由(routed)到不同的专家(experts),每个专家负责处理特定的信息。
不同的头被分配去捕捉图像patches内部的不同细节方面以及patches之间的关系。例如,一个头可能专注于捕捉纹理信息,而另一个头可能专注于捕捉形状或颜色信息。通过这种方式,每个专家可以专注于图像的一个特定方面,从而使得整个模型能够从多个角度理解和解释视觉数据。
对于语言数据,MH-MoE模型的多头机制同样发挥着关键作用。不同的头被用于捕捉不同语言中假同源词(false cognates)的变化上下文,或者是同一语言中多义词(polysemous words)的不同含义。
例如,在处理英语和意大利语的数据时,一个头可能会专注于理解在两种语言中看起来相似但实际上含义不同的词汇(如英语中的“camera”和意大利语中的“camera”)。另一个头可能会处理同一语言中具有多种含义的多义词,如英语中的“bank”可以指代金融机构,也可以指代河岸。
通过这种多头并行处理机制,MH-MoE能够更细致地捕捉语言数据中的细微差别,并在模型中为每个词汇的不同含义建立更为精确的表示。MH-MoE模型的这种设计不仅适用于单一模态的数据,还能够处理多模态数据,即将视觉信息和语言信息结合起来。在多模态场景下,模型可以同时利用对视觉细节和语言上下文的理解,以更全面地捕捉和解释输入数据。
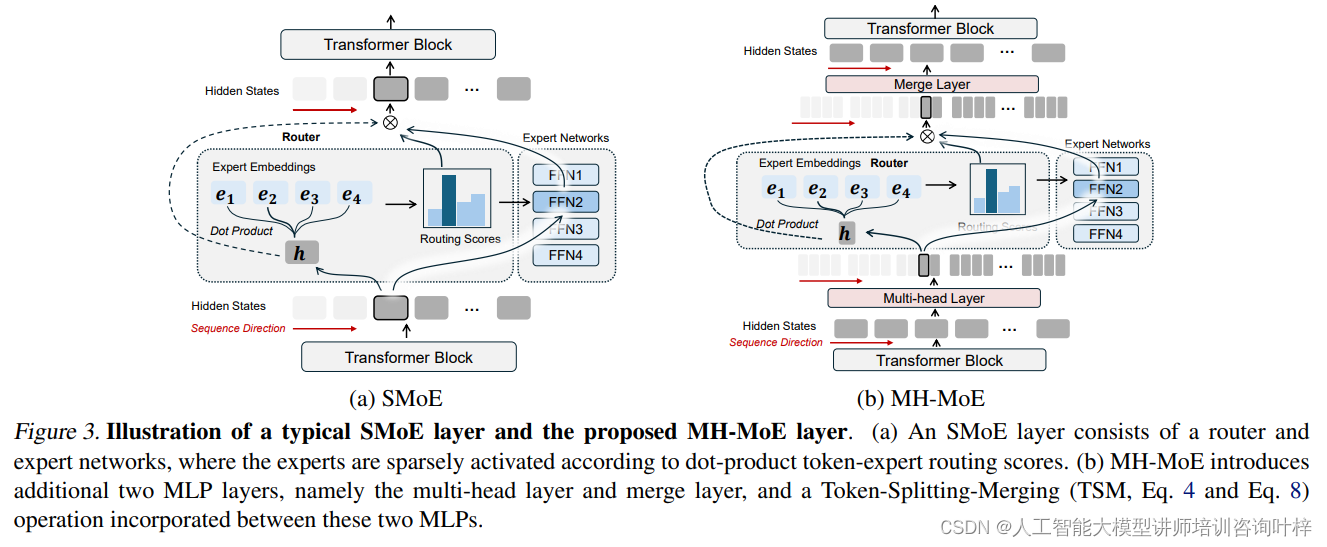
MH-MoE核心创新的多头机制能够显著提升模型的表示能力和灵活性。首先,MH-MoE接收输入序列,并将其通过一个多头层进行处理。这一步骤涉及到将每个token分割成多个子token,这一分割操作不仅增加了模型处理信息的粒度,还允许模型从不同的角度捕捉输入数据的特征:每个token根据多头机制被分割成h个子token,这些子token在保持原有序列顺序的同时,被重新排列形成一个新特征空间。
接下来,这些子token被送入一个门控函数,该函数计算每个子token被路由到不同专家的门控值。每个专家可以视为一个独立的前馈神经网络,负责处理分配给它的子token。在这个阶段,模型只会激活具有最高门控分数的前k个专家,这样的设计旨在提高计算效率并减少不必要的计算负担。
经过专家网络处理后,子token被重新整合回原始token的形式。这一整合过程确保了模型输出的维度与输入保持一致,从而无需在后续的非并行层中引入额外的计算成本。
MH-MoE的训练目标旨在最小化两个主要的损失函数:目标任务损失和辅助负载平衡损失。
目标任务损失(Task Specific Loss):这个损失函数与MH-MoE设计学习的具体任务相关。例如,在预训练阶段,如果任务是语言模型预测下一个词,那么损失函数将基于语言模型损失来计算。
负载平衡损失(Load Balancing Loss):由于在SMoE模型中经常会出现专家负载不平衡的问题,MH-MoE通过引入负载平衡损失来解决这一问题。该损失函数计算每个专家被分配的子token数量,并鼓励模型更均匀地分配任务给所有专家,从而提高模型的整体效率和可扩展性。
总的训练目标是联合最小化这两个损失函数,其中负载平衡损失的权重由超参数α控制。通过这种方式,MH-MoE不仅能够学习执行特定的任务,还能够确保模型的内部组件(即专家)得到有效和均衡的利用。
MH-MoE通过其创新的多头机制和训练目标,有效地提升了模型的性能和可扩展性,同时保持了计算成本的可控性。这些设计选择使得MH-MoE成为一个在多个任务上都具有潜力的强大模型。
模型性能评估
研究者采用了与X-MoE相同的Transformer解码器架构,并根据MH-MoE的设计调整了超参数,如头数(heads)和专家数量(experts)。
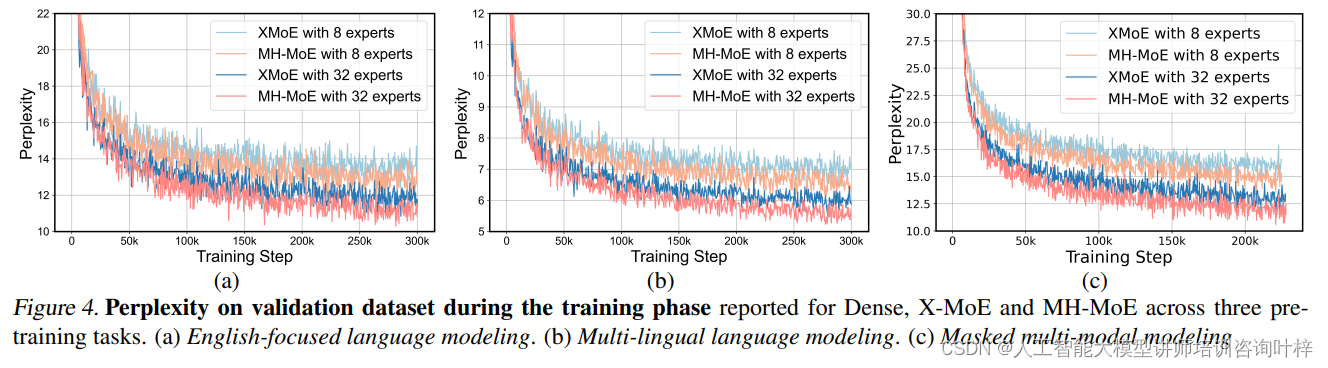
研究者报告了在不同预训练任务上的验证困惑度曲线和最终困惑度值。这些任务包括英语聚焦的语言建模、多语言语言建模和掩蔽多模态建模。困惑度是衡量语言模型性能的关键指标,它反映了模型预测下一个词的能力。研究者观察到,随着训练的进行,MH-MoE的困惑度始终低于基线模型,这表明MH-MoE在语言表示学习方面更为有效。增加专家数量时,MH-MoE的困惑度进一步降低,显示了模型在利用更多专家时的性能提升。
研究者在多个下游任务上评估了MH-MoE的有效性。这些任务包括零样本基准测试、跨语言自然语言推理和视觉-语言任务。在这些任务中,MH-MoE展现了卓越的性能,无论是在理解语言的细微差别还是在整合视觉信息方面。研究者通过这些评估验证了MH-MoE模型在实际应用中的泛化能力和实用性。
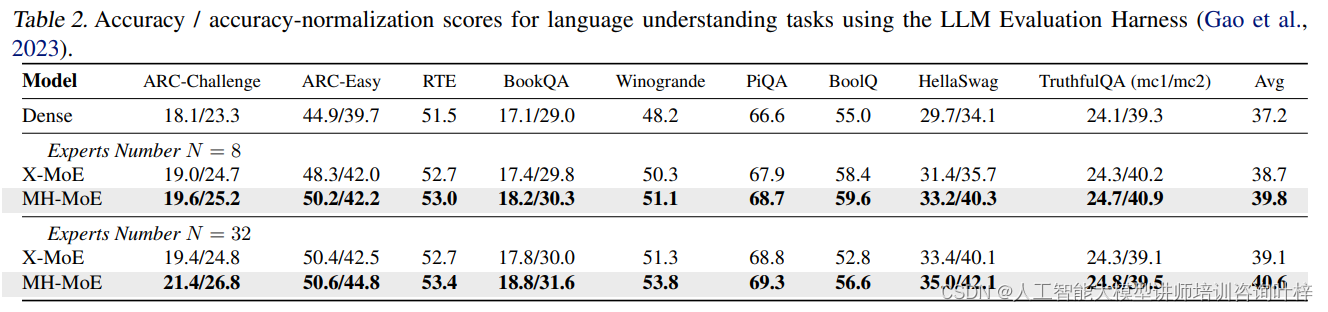
研究者通过逐步移除MH-MoE中的不同组件,展示了每个组件的功能和重要性。这些组件包括多头层(multi-head layer)、合并层(merge layer)和Token-Splitting-Merging(TSM)操作。消融研究的结果揭示了MH-MoE中每个部分对整体性能的贡献,证明了MH-MoE设计的每一部分都是提升模型性能不可或缺的。
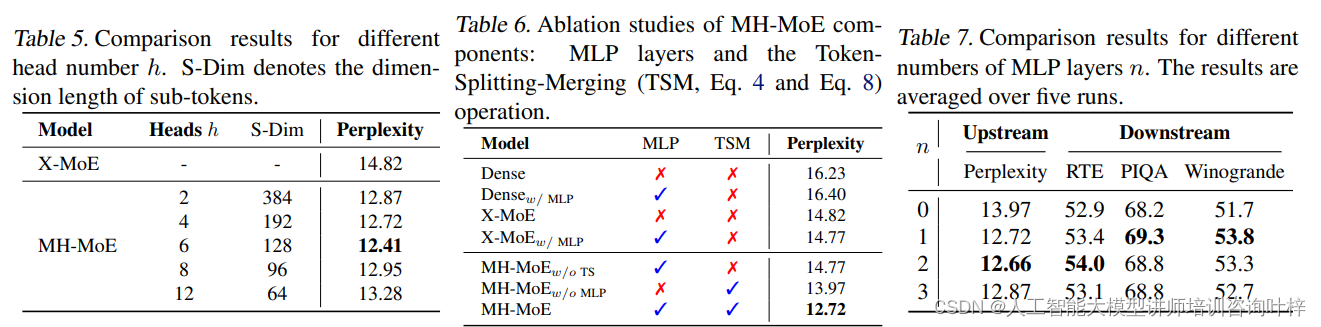
表6展示了MH-MoE中MLP层和Token-Splitting-Merging (TSM)操作的消融研究结果
表7展示了不同MLP层数n下,MH-MoE模型的性能比较
MH-MoE模型的深入评估
为了深入理解MH-MoE模型的性能优势,研究者进行了一系列的分析实验,旨在验证模型在细粒度理解能力方面的提升。
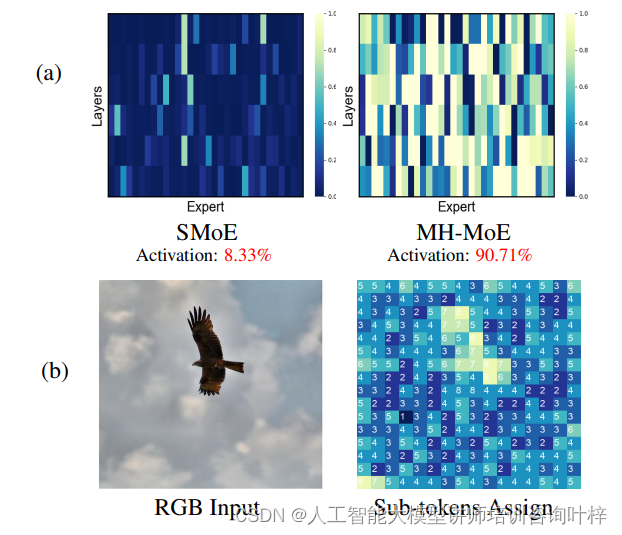
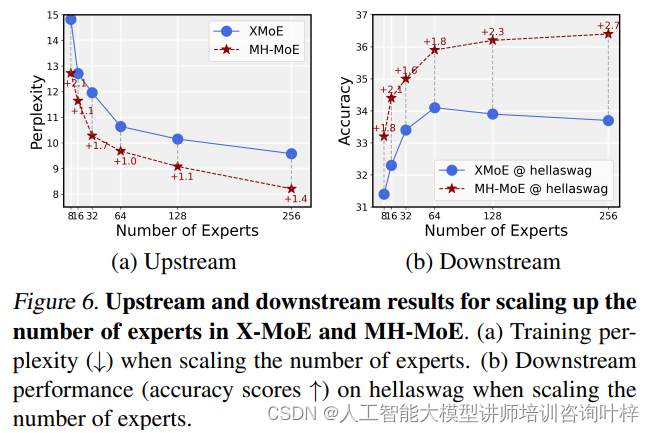
研究者首先关注了MH-MoE模型中专家的激活情况。通过可视化手段,他们观察了每个专家在不同层次上的激活频率。结果显示,与X-MoE相比,MH-MoE实现了更密集的专家激活,这表明MH-MoE能够更有效地利用其专家网络。这种激活模式的改变显著减少了未被激活的“死亡”专家数量,从而提高了模型的整体表达能力。
随着模型头部数量的增加,观察到专家激活频率也随之增加。这意味着,当模型分配更多的头部时,它能更好地分配任务给不同的专家,进一步增强了模型的表示能力。
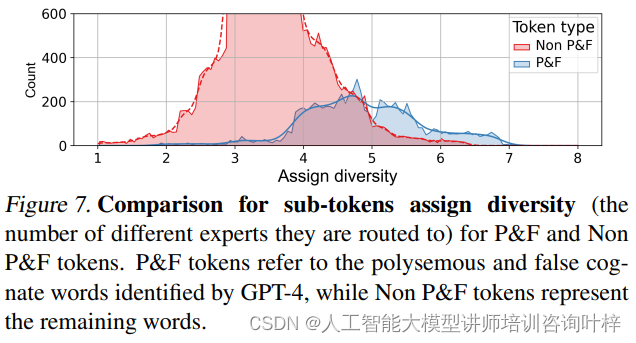
研究者进一步分析了MH-MoE在处理语言数据中的多义词和假同源词时的性能。通过使用GPT-4 API来识别这些复杂词汇,研究者发现MH-MoE的多头机制能够将这些词汇的子token分配给更多不同的专家。这种分配策略使得模型能够从不同的角度捕捉和理解每个词汇的多重含义,从而提高了对语言细微差别的敏感性。
在图像数据方面,研究者分析了模型在训练过程中如何对不同区域的语义信息进行处理。他们发现,随着训练的进行,MH-MoE倾向于将来自图像中复杂纹理区域的子token分配给更多样的专家。这种策略使得模型能够更细致地理解图像中的视觉信息,尤其是在处理包含丰富语义信息的区域时。

MH-MoE模型通过引入多头机制,不仅实现了更密集的专家激活,而且显著提升了模型对语言和视觉数据中复杂概念的理解能力。MH-MoE的实现简单直观,且无需额外的计算成本,这使得它可以轻松地与其他SMoE框架集成,进一步提高性能。
MH-MoE模型的提出和验证,展示了通过创新的模型设计和训练策略,可以有效提升深度学习模型的性能和应用范围。随着进一步的研究和开发,MH-MoE模型有望在未来的AI领域发挥更加重要的作用,为解决复杂的实际问题提供更加强大和灵活的解决方案。
论文链接:https://arxiv.org/abs/2404.15045















 6387
6387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









