










当利我们用 LMStudio 完成了 DeepSeek 或者其他模型的部署之后,如果希望该服务能够被远程客户端所调用当前服务的API。
注意:当前演示环境为Windows系统,其他桌面系统的操作方式类似。
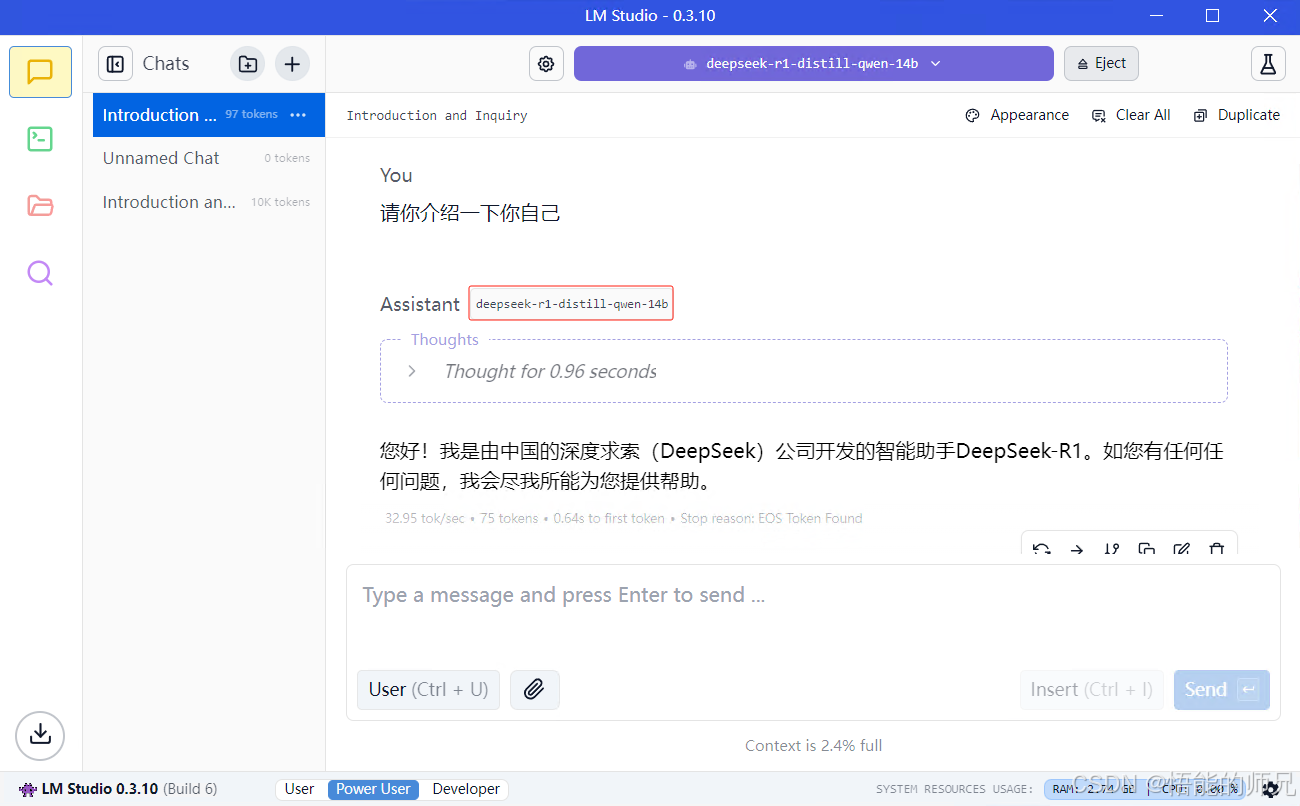
1:下载好模型,对话模式界面
这是启动好的模型的chat页面
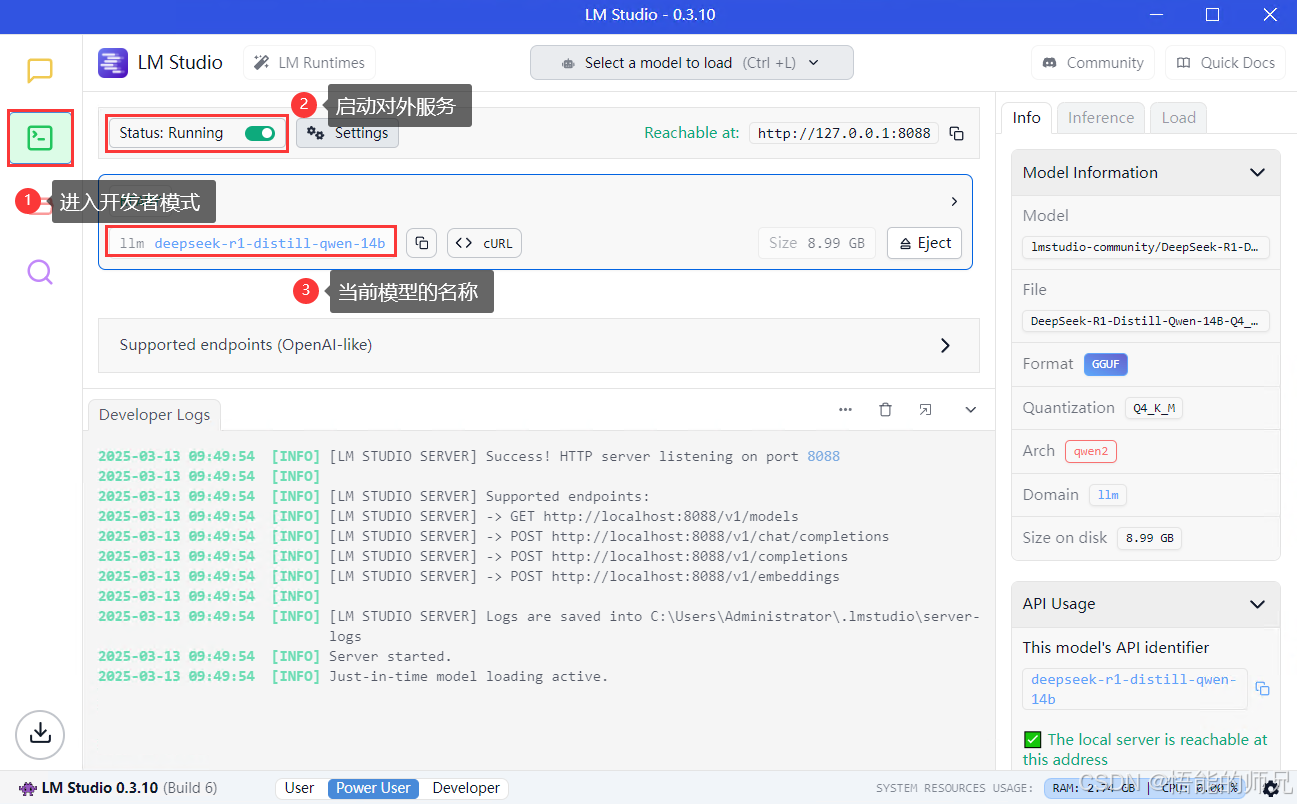
2:开发者模式界面
我们开启对外服务的API,注意哈,开启服务只支持本机访问,需要局域网访问接着看
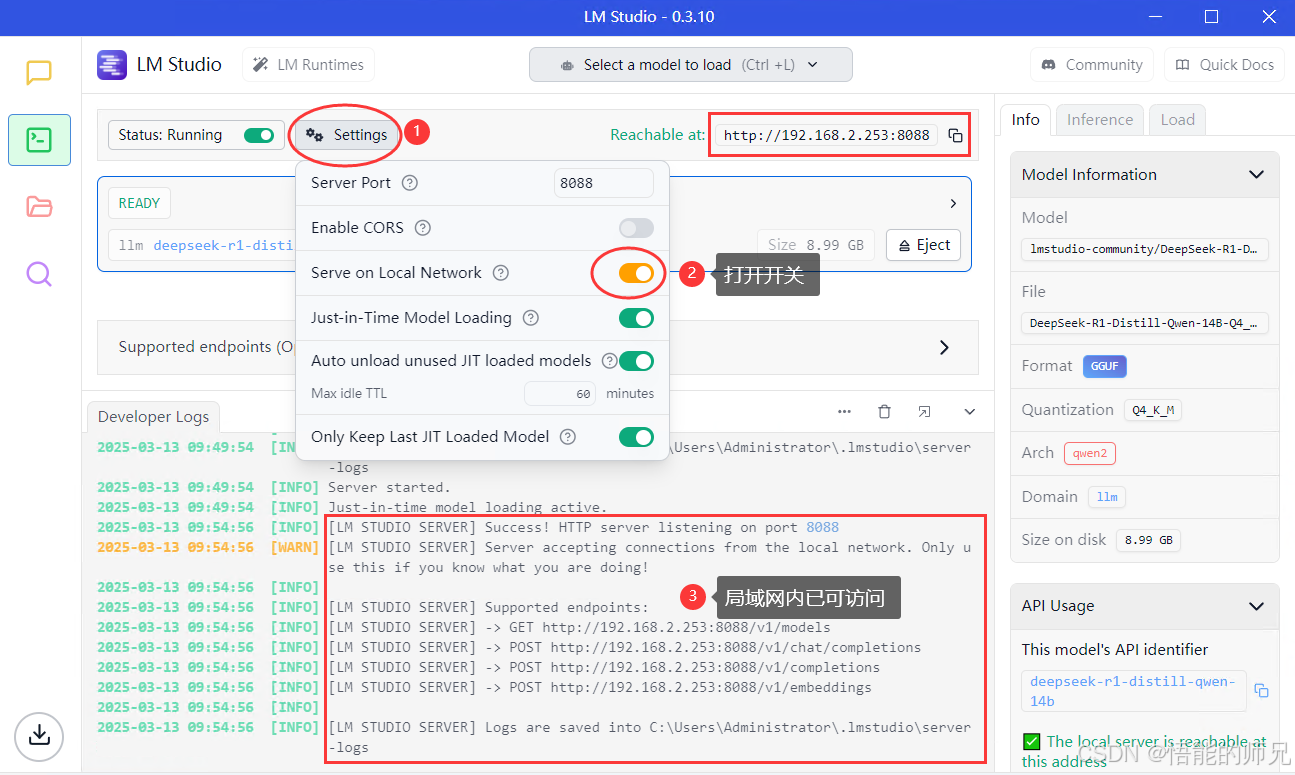
3:开启局域网访问
配置好局域网访问后,当前服务即可对整个内网访问
4:开发者使用http访问
http://192.168.2.253:8088/v1/chat/completions
{
"model": "deepseek-r1-distill-qwen-14b",
"messages": [
{
"role": "system",
"content": "你是一个智能助手"
}
],
"temperature": 0.1,
"stream": false
} 我部署机器的显卡:2080TI,不同的显卡性能不一哈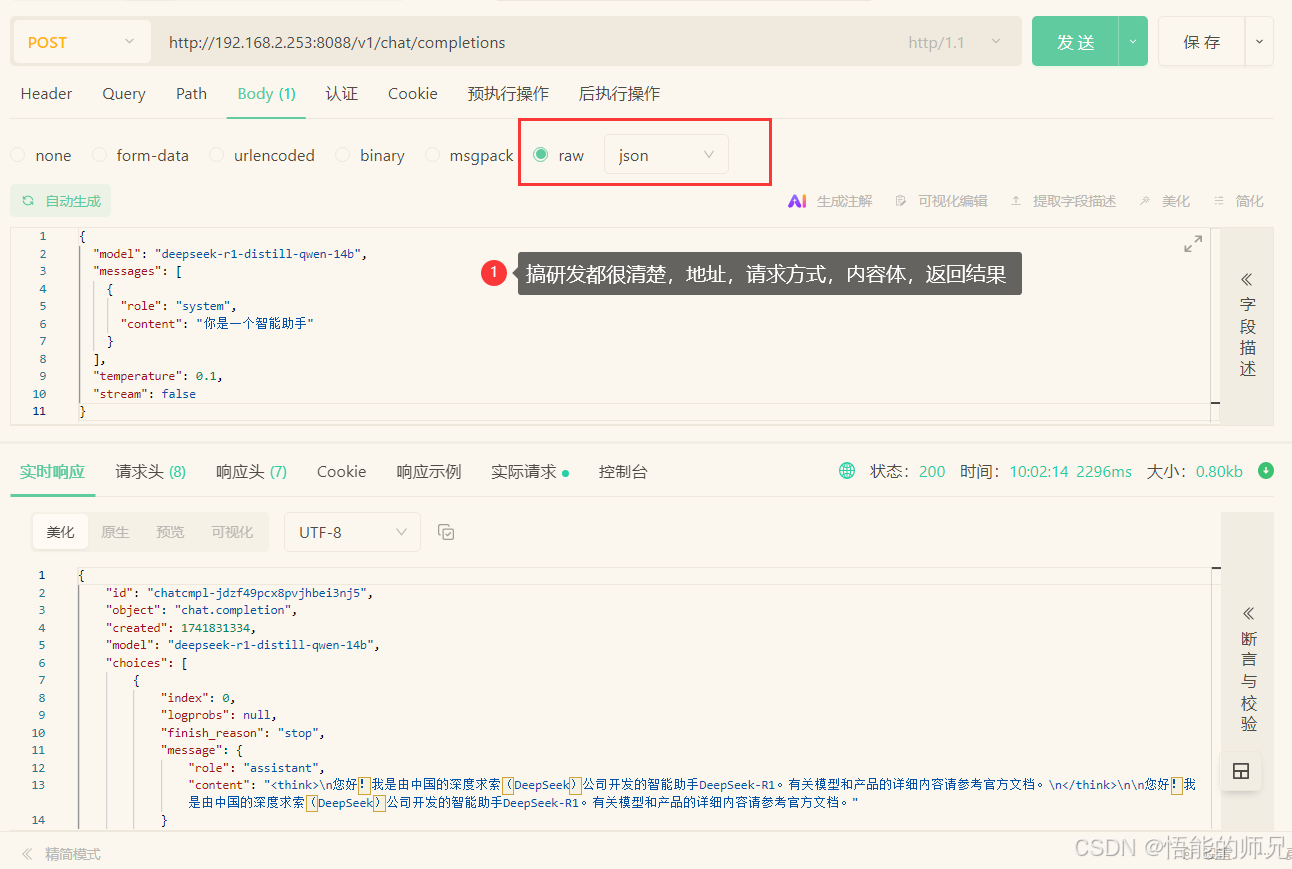
5:OpenAI模式访问接口
使用很简单的代码演示使用哈,使用需要安装依赖,代码如下:
"""
LM Studio 对外服务
"""
import time
from openai import OpenAI
from loguru import logger
# Initialize LM Studio client
local_openai_client = OpenAI(base_url="http://192.168.2.253:8088/v1", api_key="lm-studio")
# local_openai_client = OpenAI(base_url="http://127.0.0.1:1234/v1", api_key="lm-studio")
MODEL = "deepseek-r1-distill-qwen-14b"
# 创建请求函数
def lmstudio_model_request(system_role_content, predict_content):
"""
执行模型API访问
:param system_role_content:
:param predict_content:
:return:
"""
logger.info(f"本次将使用模型:{MODEL}")
try:
# 使用 OpenAI 库调用本地部署的模型
response = local_openai_client.chat.completions.create(
model=MODEL,
messages=[
{
"role": "system",
"content": system_role_content
},
{
"role": "user",
"content": predict_content
}
]
# ,response_format={"type": "json_object"}
)
return response
except Exception as e:
print(f"请求失败: {e}")
return None
if __name__ == "__main__":
time1 = time.time()
completion = lmstudio_model_request("你是一个智能助手","你介绍一下你自己.")
result_context = completion.choices[0].message.content
time2 = time.time()
print(f"耗时:{round(time2-time1,3)}秒,模型识别结果:{result_context}")

















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









