







排序总结:

排序分类:

一. 冒泡排序(Bubble Sort):
1.1 算法描述:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对,
这样在最后的元素应该会是最大的数; - 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
参考链接:https://www.bilibili.com/video/av54147410/?p=2
1.2 演示:
1.3 代码实现:
void BubbleSort( int arr[], int n )
{
for ( int i = 0; i < n - 1; i++ ) // n个数,需要交换n-1次
{
for ( int j = 0; j < n - i - 1; j++ )
{
if ( arr[j] > arr[j + 1] )
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
1.4 冒泡排序的优化:(优化后,如果有序,则时间复杂度达到了O(N))
参考:https://blog.csdn.net/qingqiulengya/article/details/51591188
参考:https://www.cnblogs.com/minkaihui/p/4077888.html
void BubbleSort( int* parr, int size ) /* 冒泡排序(升序,优化) */
{
bool flag = false;
for ( int i = 0; i < size; i++ )
{
for ( int j = 0; j < size - i - 1; j++ )
{
if ( parr[j] > parr[j + 1] )
{
swap( parr[j], parr[j + 1] );
flag = true;
}
}
if ( flag == false ) /*上一个循环比较结束而没有发生交换,但是每两个相邻元素都比较过了,说明已经有序 */
{
break; /* 已经有序跳出循环 */
}
}
}
1.4 考点总结:
冒泡排序的最好情况为O(n),此时为有序(因为有序,所以内存循环)。一般情况下为O(n^2).
冒泡排序经过一趟排序之后,最大值或者最小值固定,即放在了最后面。
二. 选择排序(Selection Sort)
2.1 算法描述
选择排序,无论什么数据进去都是O(n^2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。
选择排序(Selection-sort)是一种简单直观的排序算法。
它的工作原理:
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
2.2 演示:
2.3 代码实现:
void SelectSort( int a[], int length )
{
/* 对数组a排序,length是数组元素数量 */
for ( int i = 0; i < length; i++ )
{
/* 找到从i开始到最后一个元素中最小的元素,k存储最小元素的下标. */
int k = i;
for ( int j = i + 1; j < length; j++ )
{
if ( a[j] < a[k] )
{
k = j;
}
}
/* 将最小的元素a[k] 和 开始的元素a[i] 交换数据. */
if ( k != i )
{
int temp;
temp = a[k];
a[k] = a[i];
a[i] = temp;
}
}
}
2.4 考点总结
选择排序是一种表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好。
选择排序时间复杂度都是O(n)
三. 插入排序(Insertion Sort)
3.1 算法描述
- 从第一个元素开始,该元素可以认为已经被排序(因为只有一个元素);
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素大于已排序中的最后一个元素,则将该元素放在已排序元素的后面。
- 如果该元素小于已排序中的最后一个元素,则和已排序元素的最后一个元素的前一个继续比较,以此类推,直到插入到合适的位置。
3.2 演示:
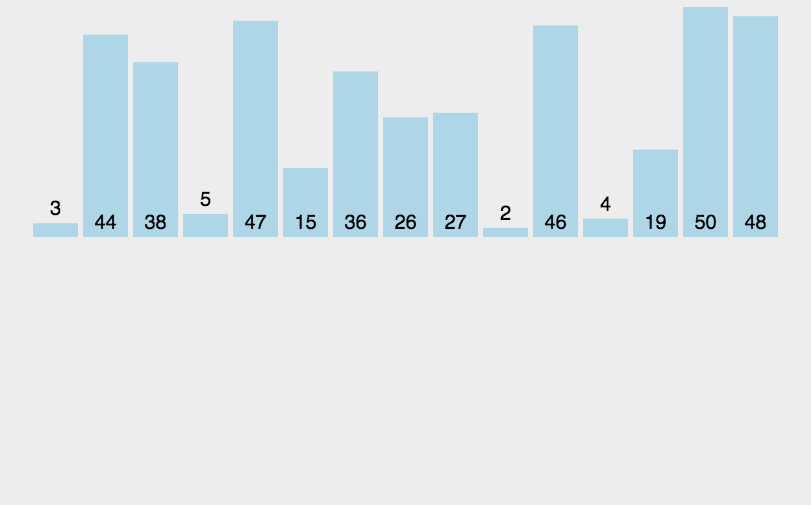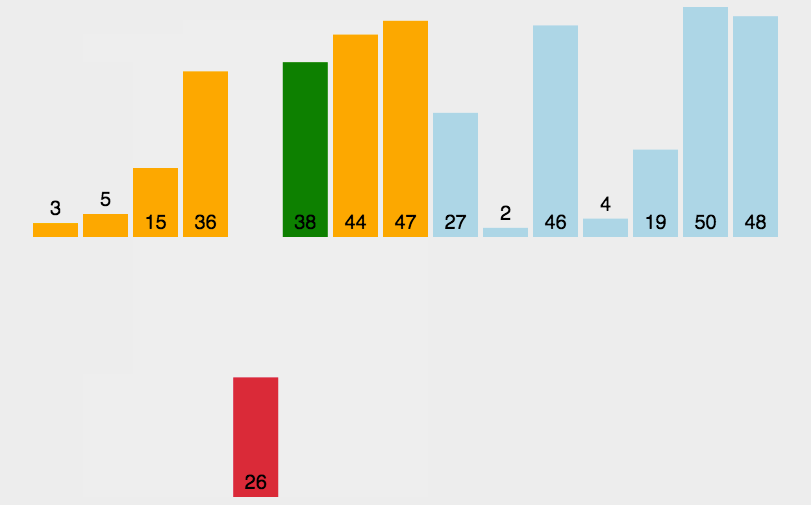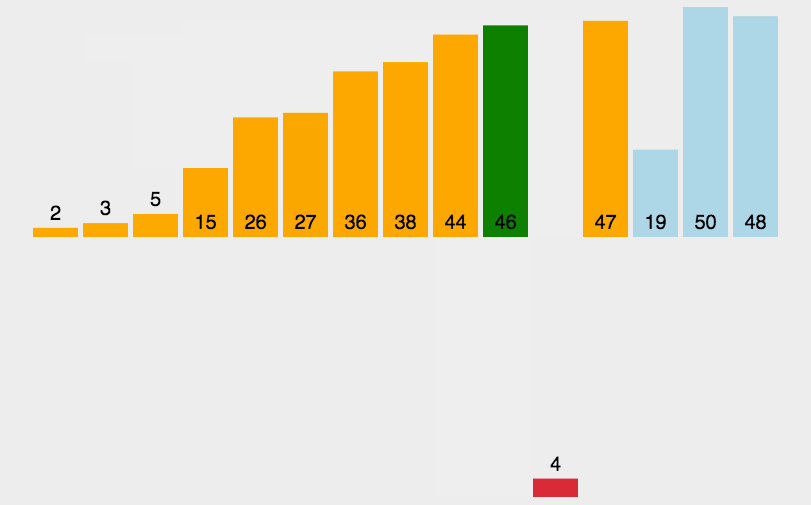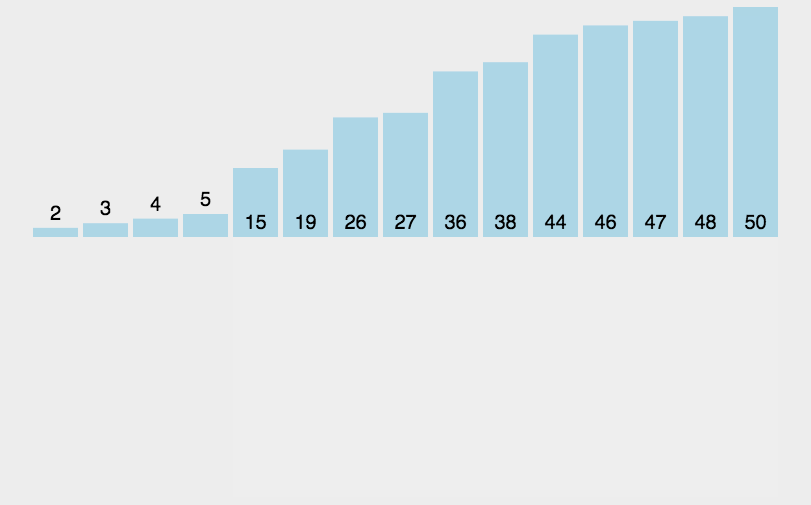
3.3 代码实现:
void insertSort(int num_arr[], int n)
{
for(int i=1;i< n;i++)
{
for(int j=i; j>0; j--)
{
if(num_arr[j]<num_arr[j-1])
{
swap(num_arr[j], num_arr[j-1]);
}
}
}
}
对直接插入排序进行优化:(避免每次都要交换位置)
void insertSortPlus(int num_arr[], int n)
{
for(int i=1;i<n;i++)
{
int e = num_arr[i];
int j;
for(j=i; j>0; j--)
{
if(num_arr[j-1]>e)
{
num_arr[j] = num_arr[j-1];
}
else
{
break;
}
}
num_arr[j] = e;
}
}
3. 4 考点:
直接插入排序是稳定的排序算法,最好情况时间复杂度为O(n),平均情况为O(n^2)
四. 希尔排序(Shell Sort)
4.1 算法描述
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n^2)的第一批算法之一。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。
4.2 演示
首先它把较大的数据集合分割成若干个小组(逻辑上分组),然后对每一个小组分别进行插入排序,此时,插入排序所作用的数据量比较小(每一个小组),插入的效率比较高。

下面颜色相同的是逻辑上的分组,并没有实际的进行分组操作,在数组中的位置还是原来的样子,只是将他们看着这么几个分组(逻辑上分组)。
可以看出,他是按下标相隔距离为4分的组,也就是说把下标相差4的分到一组,比如这个例子中a[0]与a[4]是一组、a[1]与a[5]是一组…,这里的差值(距离)被称为增量。

每个分组进行插入排序后,各个分组就变成了有序的了(整体不一定有序)

此时,整个数组变的部分有序了(有序程度可能不是很高)

然后缩小增量为上个增量的一半:2,继续划分分组,此时,每个分组元素个数多了,但是,数组变的部分有序了,插入排序效率同样比高

同理对每个分组进行排序(插入排序),使其每个分组各自有序。

最后设置增量为上一个增量的一半:1,则整个数组被分为一组,此时,整个数组已经接近有序了,插入排序效率高。

同理,对这仅有的一组数据进行排序,排序完成。
4.4 代码实现:
void shellsort3(int a[], int n)
{
int i, j, gap;
for (gap = n / 2; gap > 0; gap /= 2)//控制分组步长
for (i = gap; i < n; i++)//控制组数
for (j = i - gap; j >= 0 && a[j] > a[j + gap]; j -= gap)
Swap(a[j], a[j + gap]);
}
五. 归并排序(Merge Sort)
5.1 算法描述
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(n log n)的时间复杂度。代价是需要额外的内存空间。
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
六. 快速排序(Quick Sort)
参考我的另一篇文章:https://blog.csdn.net/yexudengzhidao/article/details/87103155
七. 堆排序(Heap Sort)
参考我的另一篇文章:https://blog.csdn.net/yexudengzhidao/article/details/93053144
参考链接:https://www.bilibili.com/video/av54147410/?p=2
参考链接:https://blog.csdn.net/hellozhxy/article/details/79911867
希尔排序参考链接:https://blog.csdn.net/qq_39207948/article/details/80006224
















 2716
2716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











