







为什么深度学习会兴起?
本节视频主要讲了推动深度学习变得如此热门的主要因素。
深度学习和神经网络之前的基础技术理念已经存在大概几十年了,为什么它们现在才突然流行起来呢?本节课程主要讲述一些使得深度学习变得如此热门的主要驱动因素,这将会帮助你在你的组织机构内发现最好的时机来应用这些东西。
在最近的几年里,很多人都问我为什么深度学习突然好使了?当我回答这个问题时,我通常给他们画个图,横坐标表示:在某个任务上我们拥有的数据量;纵坐标表示:学习算法的性能,比如说体现在垃圾邮件过滤或者广告点击预测的准确率,或者是神经网络在自动驾驶汽车时判断位置的准确性。
根据图像可以发现,如果你把一个传统机器学习算法的性能画出来,你可能得到下图的函数图像。就像图中这样,它的性能一开始在增加,但是随着数据量的增加,过段时间性能将趋于平坦。他们不知道如何处理规模巨大的数据,而过去十年的社会里,我们遇到的很多问题只有相对较少的数据量。

数字化社会的来临,现在的数据量都非常巨大,我们花了很多时间活动在这些数字信息领域,比如在电脑网站上、在手机软件上以及其它数字化的服务,这些行为都能创建数据。我们已经收集到越来越多的数据。所以对于过去几十年里,我们已经积累了很多数据,超出了传统的学习算法所能利用的。如果能使用神经网络,它的性能会得到提升(如函数图像,从Small NN -> Lorge NN)。
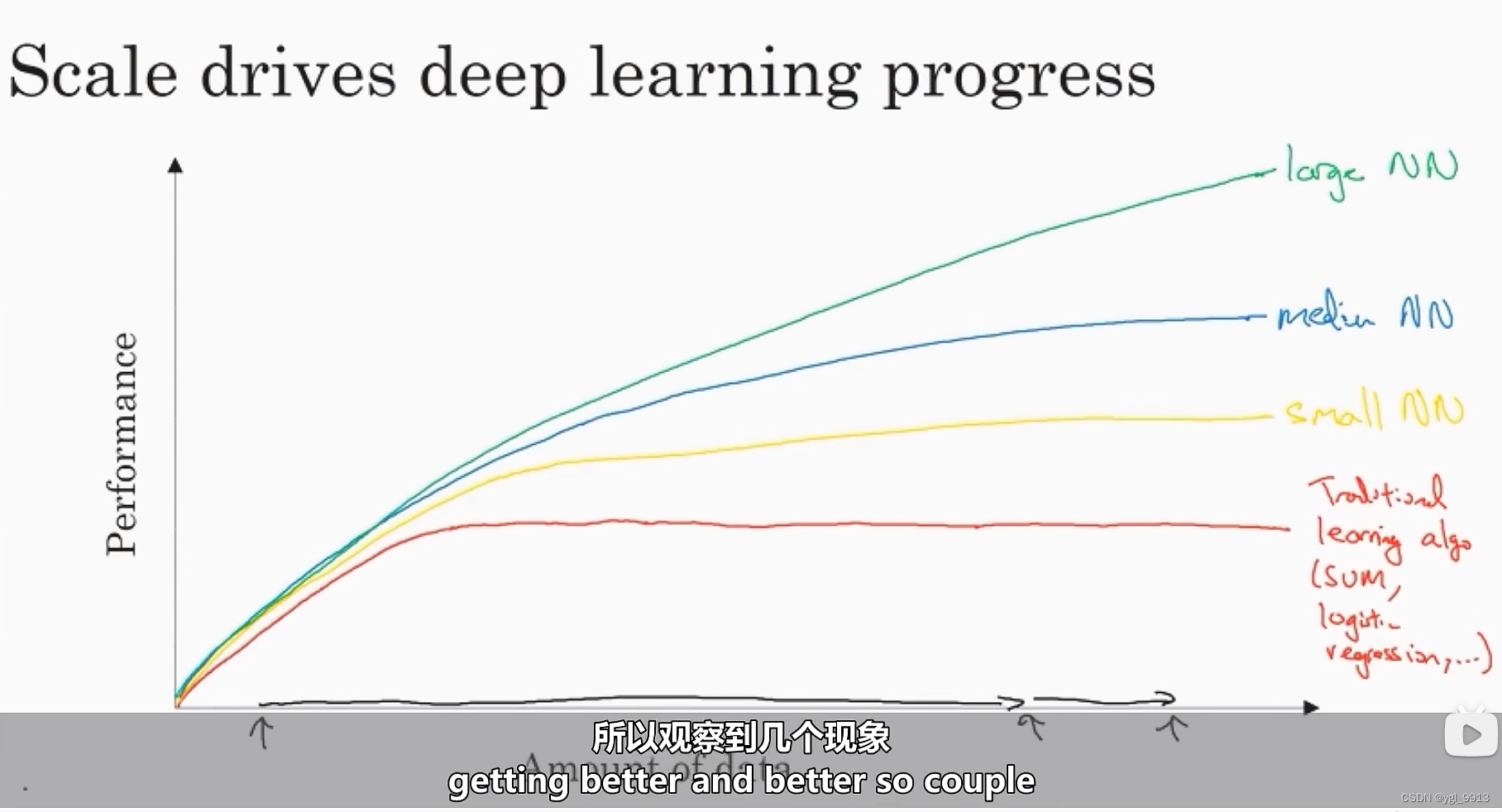
如图中展现出那样,如果你训练一个小型的神经网络,那么这个性能可能会像下图黄色曲线表示那样;如果你训练一个稍微大一点的神经网络,比如说一个中等规模的神经网络(下图蓝色曲线),它在某些数据上面的性能也会更好一些;如果你训练一个非常大的神经网络,它就会变成下图绿色曲线那样,并且保持变得越来越好。
因此可以注意到两点:如果你想要获得较高的性能体现,那么你有两个条件要完成,第一个是你需要训练一个规模足够大的神经网络,来利用大量的数据;其次你需要能画到 轴 这里,你需要很多数据。因此我们经常说规模一直在推动深度学习的进步,这里的规模指的是神经网络的规模和数据的规模。事实上如今最可靠的方法来在神经网络上获得更好的性能,往往就是要么训练一个更大的神经网络,要么投入更多的数据。然后最终你也会到达瓶颈,因为最终你耗尽了数据,或者最终你的网络规模实在太大了,训练需要花费很长时间。但是仅仅提升规模的确可以让我们在深度学习的世界中前进一大步。
为了使这个图更加从技术上讲更精确一点,我在轴上经写明的数据量,这儿加上一个被标记(labeled)标签,通过这些被标记的数据量(被标记意思是:对于训练集,我们同时有输入
和标记
)。使用小写的字母
表示训练集大小,或者说训练样本的数量。

在这个小的训练集中,各种算法的优先级事实上定义的也不是很明确,所以如果你没有大量的训练集,那么自己提取出来的特征很大程度上决定了算法的性能和结果。所以就有可能发生:假设有些人训练出了一个SVM(支持向量机);而有的人在这个很小的训练集上,训练一个很大的网络,SVM 可能得到更好的结果。所以在训练集中,算法性能的排名是不固定的。最终的性能更多的是取决于你提取特征方面的能力以及算法处理方面的一些细节,只是在某些大数据规模非常庞大的训练集,也就是在右边这个 很大的数据集区域里,我们才会看到神经网络的方法超过了其他方法。
所以可以这么说,在深度学习萌芽的初期,数据的规模以及计算能力,局限了我们训练一个特别大的神经网络的能力,现在无论是在CPU还是GPU上面,我们都取得了巨大的进步。而且渐渐地,尤其是在最近这几年,我们也见证了算法方面的极大创新。许多算法方面的创新,一直是在尝试着使得神经网络运行的更快。

一个具体的例子,神经网络的算法层面的一个巨大突破是从sigmoid函数转换到一个ReLU函数,这个函数我们在之前的课程里提到过。
如果你无法理解刚才我说的某个细节,也不需要担心,可以知道的一个使用sigmoid函数在机器学习里有一个问题,那就是在箭头区域,梯度几乎是0,那么学习的速度会变得非常缓慢。因为当你实现梯度下降时,梯度接近零的时候,参数会更新的很慢。
当我们把激活函数换成ReLU的函数(修正线性单元)时,对于所有的正输入,梯度都是1。那么梯度就不会变成0。仅仅通过将Sigmod函数转换成ReLU函数,便能够使得一个叫做梯度下降(gradient descent)的算法运行的更快。这就是一个或许相对比较简单的算法创新的例子。所以有很多像这样的例子,我们通过改变算法,使得代码运行的更快,这也使得我们能够训练规模更大的神经网络。
快速计算显得更加重要的另一个原因是,训练你的神经网络的过程,很多时候是凭借直觉的,往往你对神经网络架构有了一个想法,于是你尝试写代码实现你的想法,然后让你运行一个试验环境来告诉你,你的神经网络效果有多好,通过参考这个结果再返回去修改你的神经网络里面的一些细节,然后你不断的重复上面的操作。比如,当你能够有一个想法。用10分钟,或者用一整天尝试一下,又或者你需要用一个月的时间训练你的神经网络。你应该尝试更多的想法,那极有可能使得你的神经网络在你的应用方面工作的更好、进行更快的计算。

这也同时帮助了神经网络的实验人员和有关项目的研究人员在深度学习的工作中迭代的更快,也能够更快的改进你的想法,所有这些都使得整个深度学习的研究社群变的如此繁荣,包括令人难以置信地发明新的算法和取得不间断的进步,这些都是开拓者在做的事情,这些力量使得深度学习不断壮大。
好消息是这些力量目前也正常不断的奏效,使得深度学习越来越好。比如说GPU,以及更快的网络连接各种硬件等 。我非常有信心,我们可以做一个超级大规模的神经网络,而计算的能力也会进一步的得到改善,还有算法相对的学习研究社区连续不断的在算法前沿产生非凡的创新。根据这些我们可以乐观地回答,同时对深度学习保持乐观态度,在接下来的这些年它都会变的越来越好。















 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









