









Tensorflow简介
深度学习介绍
深度学习,如深度神经网络、卷积神经网络和递归神经网络已被应用,计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域,并获取了极好的效果。
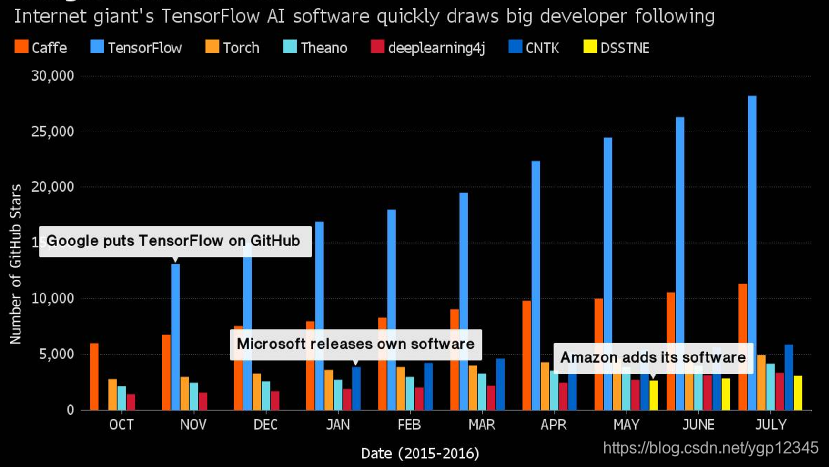
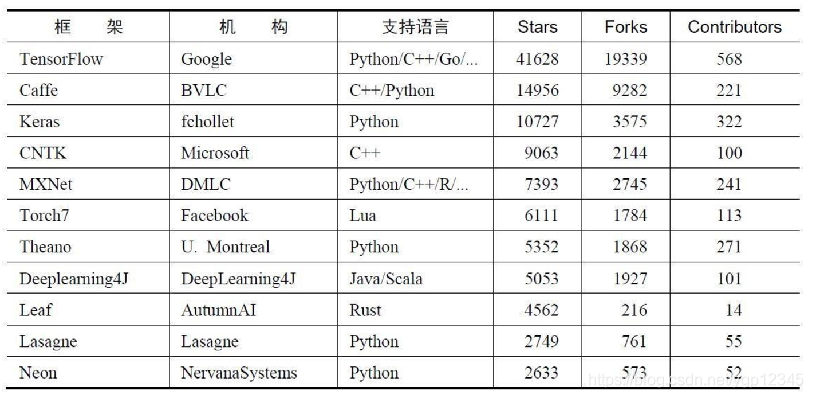
我们可以看到上图所示的现在最流行的深度学习框架。

认识Tensorflow

Tensorflow特点

Tensorflow的安装

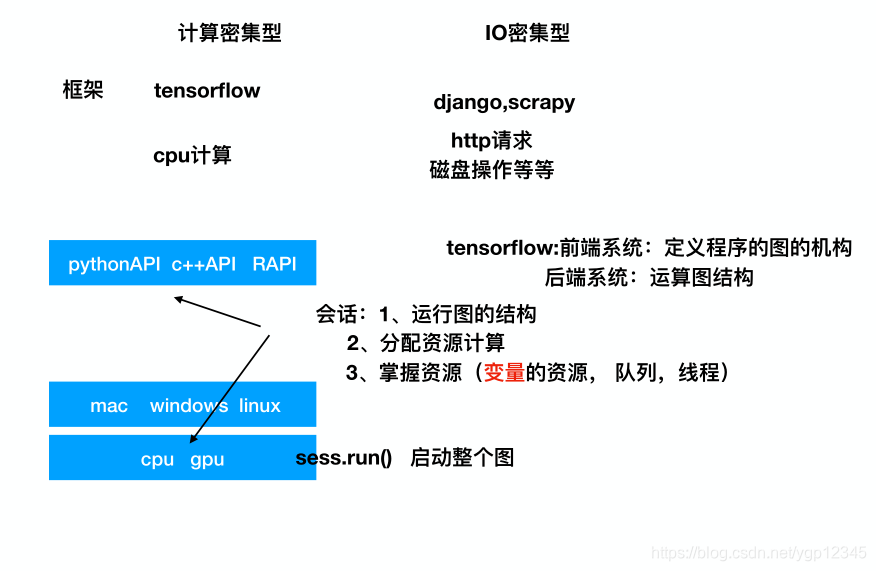
在说安装之前,先看看上图,cpu对于计算的处理没有gpu好,在公司里面肯定是用gpu版本的tensorflow,我安装的是windows版的cpu版的tensorflow,安装过程百度上有,值得注意的是要一般选择1.x版本比较稳定,而且如果百度上面教程中地镜像变了,可以手动下载相关地压缩包,解压到自己地python目录下,要想import有效,则必须复制到lib下的site-package目录下。具体看一下这个博客:安装tensorflow(注意看该博客下面的评论)
Tensorflow初体验
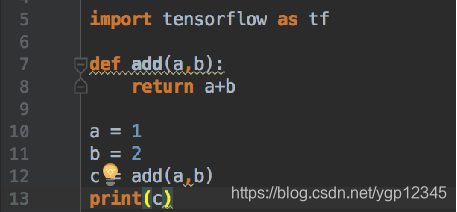
普通的python加法
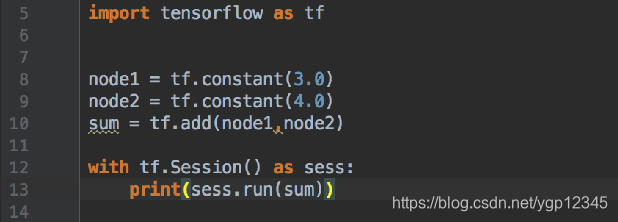
tensorflow的加法
tensorflow里的元素:
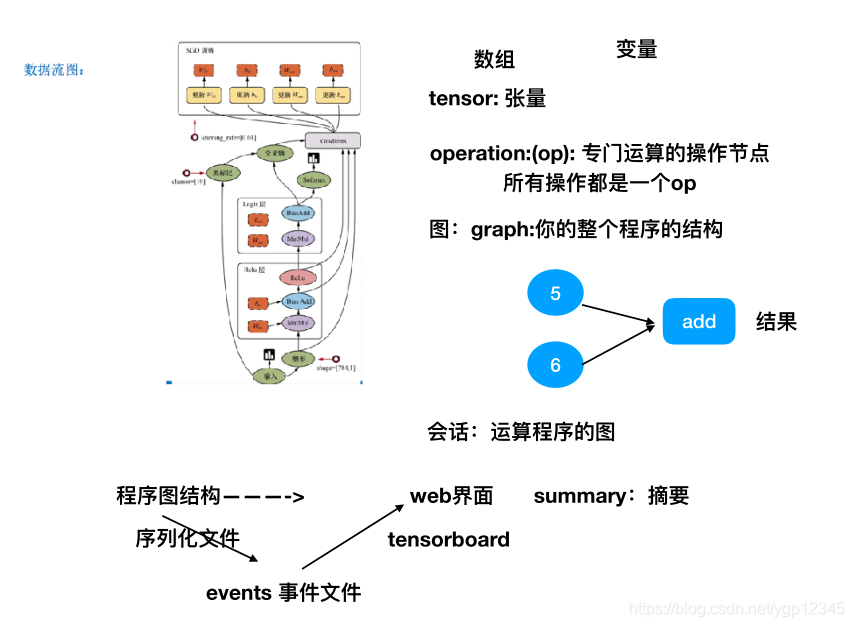
两种不同种类的框架
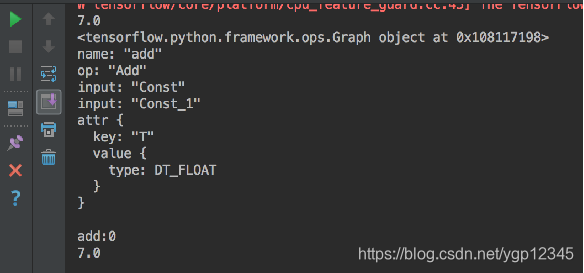
tensorflow中的图

哪些是op?
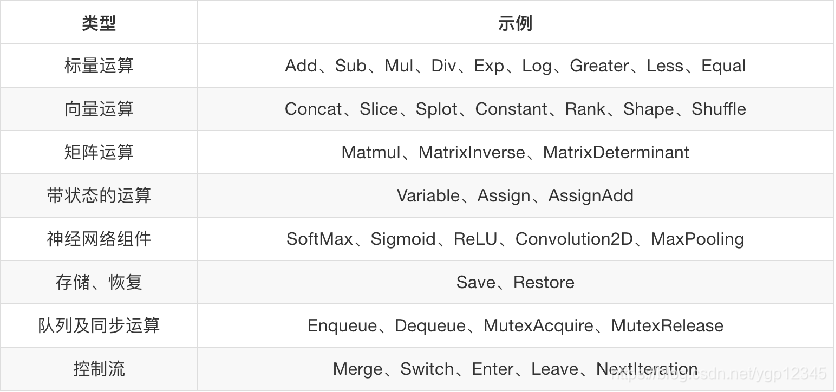
从上图我们可以看到。constant(6.0)这种写法的并不是变量,得variable这种的才表示变量。
图的创建

示例代码:
# 创建一张图包含了一组op和tensor,上下文环境
# op:只要使用tensorflow的API定义的函数都是OP
# tensor:就指代的是数据
g = tf.Graph()
print(g)
with g.as_default():
c = tf.constant(11.0)
print(c.graph)
#
# # 实现一个加法运算
a = tf.constant(5.0)
b = tf.constant(6.0)
#
sum1 = tf.add(a, b)
#
# # 默认的这张图,相当于是给程序分配一段内存
graph = tf.get_default_graph()
#
print(graph)
可以看到,constant类型的c属于图g,然后我们还可以打印tf默认使用的图是什么。
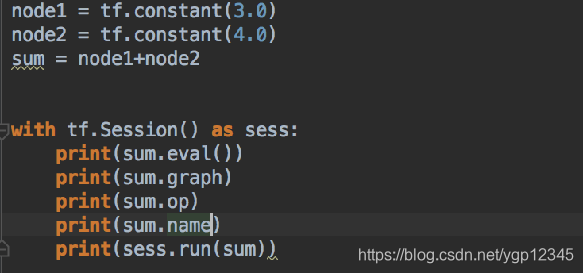
会话

使用上下文我就不用手动去close了!!
会话的run()方法

示例代码:
# # 不是op不能运行,也就是不能run
var1 = 2.0
var2 = 3
sum2 = var1 + var2
print(sum2)
#
# # 有重载的机制,默认会给运算符重载成op类型
sum2 = a + var1
#
print(sum2)
我们可以从结果看出来,当a是tensor类时,会自动将普通变量重载为tensor类,只有tensor类的元素才能放到run里。
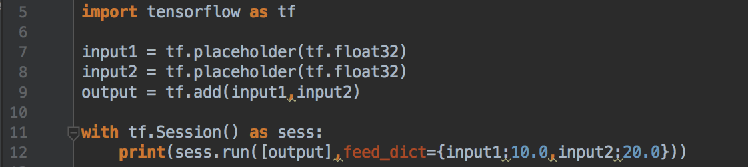
Tensorflow Feed操作

张量(tensor)
张量的阶

张量的数据类型

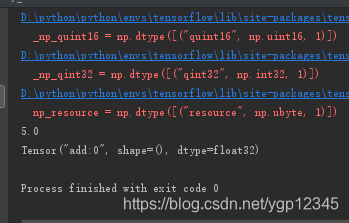
张量属性

张量的动态形状与静态形状

代码如下:
# 形状的概念
# 静态形状和动态性状
# 对于静态形状来说,一旦张量形状固定了,不能再次设置静态形状, 不能夸维度修改 1D->1D 2D->2D
# 动态形状可以去创建一个新的张量,改变时候一定要注意元素数量要匹配 1D->2D 1->3D
#
plt = tf.placeholder(tf.float32, [None, 2])
#
print(plt)
#
plt.set_shape([3, 2, 1])
#
print(plt)
#
plt.set_shape([2, 3])# 不能再次修改
#
plt_reshape = tf.reshape(plt, [3, 3])
#
print(plt_reshape)
上面代码里的None是个占位符,也就是若干行,然后我通过静态设置成[3,2,1]的矩阵是不行的,因为不能跨维度。倘若我设置为[2,2]则满足要求,当满足要求后,就不能再次用静态设置去设定该形状了,动态设置可以,但要注意元素总数。
张量操作-生成张量

随机创建张量

正态分布
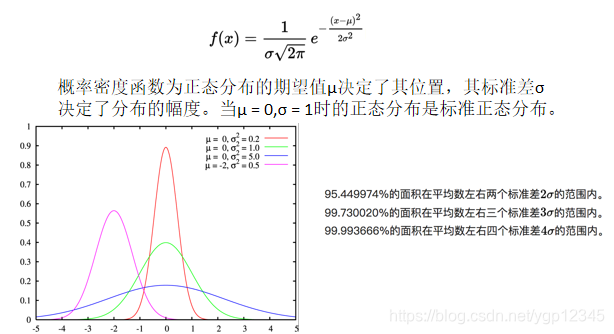
张量操作-张量变换


合并
axis指定按行还是按列合并
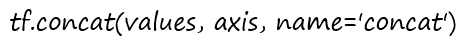
提供给Tensor运算的数学函数
参考这个链接,大体张量运算跟numpy矩阵运算类似
变量
变量是张量的一种具体形式。

变量的创建

变量的初始化

这就跟普通变量道理一样,定义了之后要初始化!!!
可视化学习Tensorboard
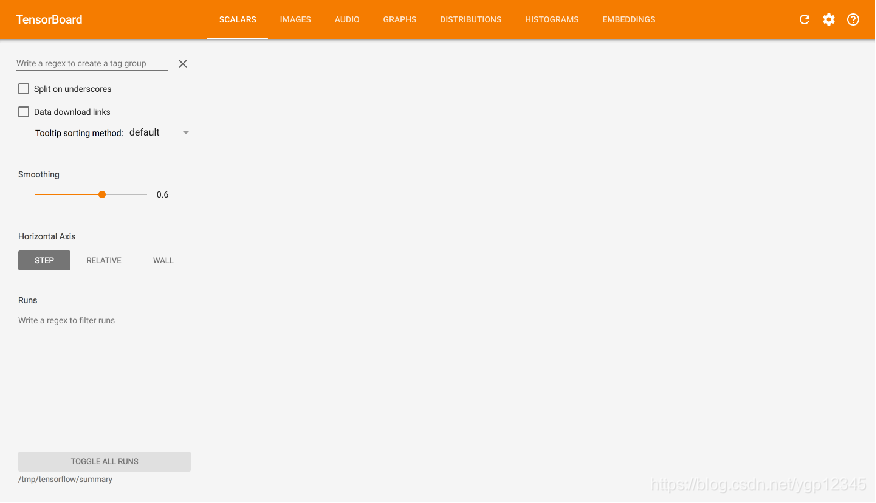

就是一个web项目,然后去监视你的tensorflow项目各个op与tensor之间的关系,以图像直观展示给我们。
图中的符号意义

示例代码:
# 变量op
# 1、变量op能够持久化保存,普通张量op是不行的
# 2、当定义一个变量op的时候,一定要在会话当中去运行初始化
# 3、name参数:在tensorboard使用的时候显示名字,可以让相同op名字的进行区分
a = tf.constant(3.0, name="a")
#
b = tf.constant(4.0, name="b")
#
c = tf.add(a, b, name="add")
#
var = tf.Variable(tf.random_normal([2, 3], mean=0.0, stddev=1.0), name="variable")
#
print(a, var)
#
# # 必须做一步显示的初始化op
init_op = tf.global_variables_initializer()
#
with tf.Session() as sess:
## 必须运行初始化op
sess.run(init_op)
#
# # 把程序的图结构写入事件文件, graph:把指定的图写进事件文件当中
# filewriter = tf.summary.FileWriter("./tmp/summary/test/", graph=sess.graph)
#
print(sess.run([c, var]))

Tensorboard观察图结构,变量显示

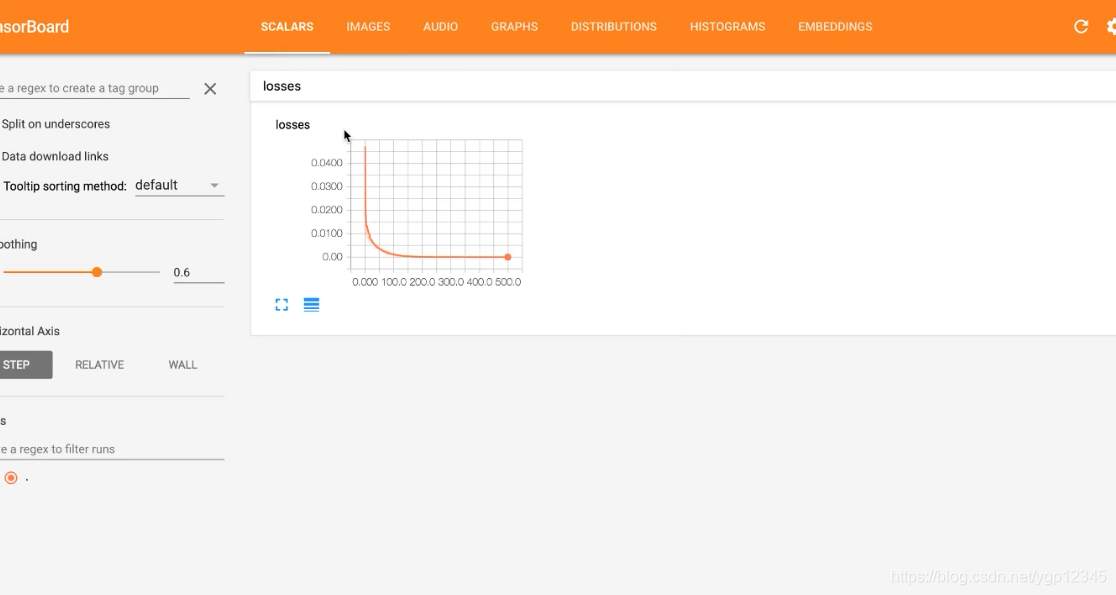
上图的意思是训练了6万次的损失值
Tensorflow运算API

梯度下降API

作用域
tensorflow变量作用域
相当于给某一段功能代码取了一个名字,有点像方法。

如果在之前,给变量取相同的name会出现什么样的情况?
如下如,c_1,c_2去区分。
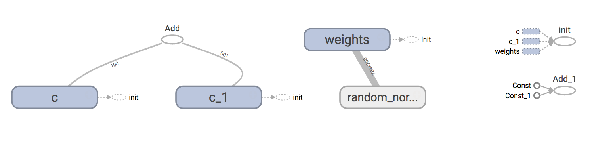
tensorflow变量作用域的作用
让模型代码更加清晰,作用分明
模型保存和加载
有这么一个场景,比如说有一大堆数据,要训练很多天才能出结果,我已经训练了两天了,结果服务器宕机了,那我之前训练的岂不白弄了???如果重新开始的话又得从随机值开始训练,又得花很多时间。模型保存就是我可以设定每训练多少次我就保存一次,对我来说最重要的就是当即之前的几次训练的数据,当系统恢复后,我有从保存的数据开始训练即可!!


自定义命令行参数
这个有点像c语言里的宏,就是定义一个全局的东东,然后到处都可以用!!



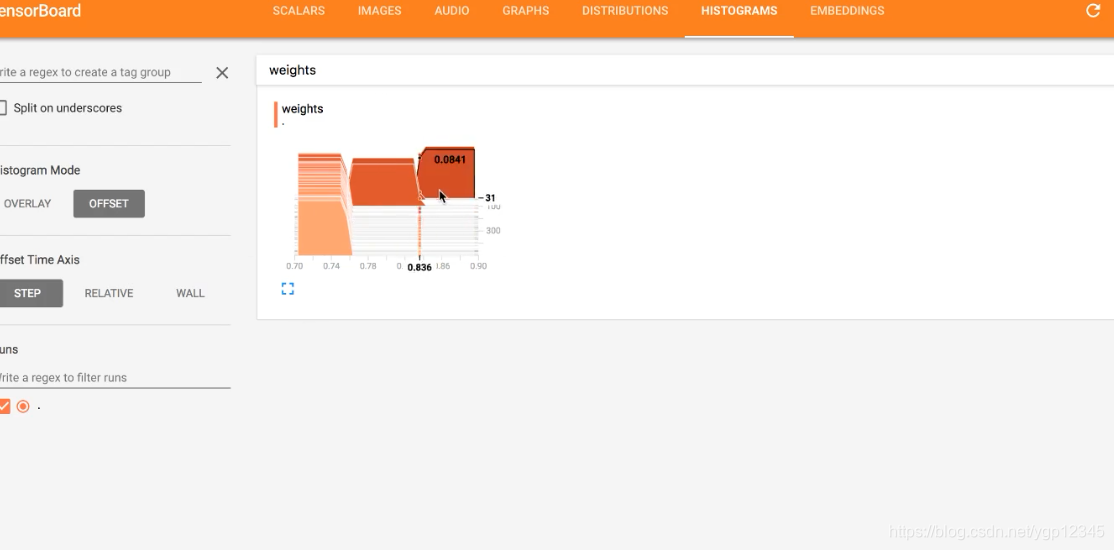
增加变量显示
引入了tensorboard后,可以看到张量和op之间的关系,当然我们也可以增加要显示的变量,比如说每次训练的损失之类的。


tensorflow实现一个简单的线性回归案例
代码示例:
# 第一个参数:名字,默认值,说明
tf.app.flags.DEFINE_integer("max_step", 100, "模型训练的步数")
tf.app.flags.DEFINE_string("model_dir", " ", "模型文件的加载的路径")
# 定义获取命令行参数名字
FLAGS = tf.app.flags.FLAGS
def myregression():
"""
自实现一个线性回归预测
:return: None
"""
with tf.variable_scope("data"):
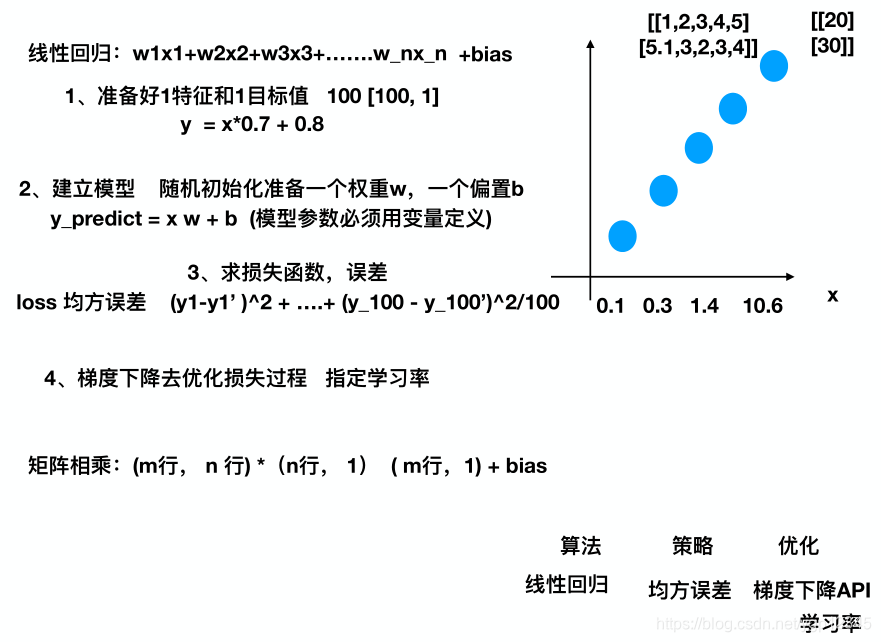
# 1、准备数据,x 特征值 [100, 1] y 目标值[100]
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5, name="x_data")
# 矩阵相乘必须是二维的
y_true = tf.matmul(x, [[0.7]]) + 0.8
with tf.variable_scope("model"):
# 2、建立线性回归模型 1个特征,1个权重, 一个偏置 y = x w + b
# 随机给一个权重和偏置的值,让他去计算损失,然后再当前状态下优化
# 用变量定义才能优化
# trainable参数:指定这个变量能跟着梯度下降一起优化
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="w")
bias = tf.Variable(0.0, name="b")
y_predict = tf.matmul(x, weight) + bias
with tf.variable_scope("loss"):
# 3、建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true - y_predict))
with tf.variable_scope("optimizer"):
# 4、梯度下降优化损失 leaning_rate: 0 ~ 1, 2, 3,5, 7, 10
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 1、收集tensor
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 定义合并tensor的op
merged = tf.summary.merge_all()
# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()
# 定义一个保存模型的实例
saver = tf.train.Saver()
# 通过会话运行程序
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 打印随机最先初始化的权重和偏置
print("随机初始化的参数权重为:%f, 偏置为:%f" % (weight.eval(), bias.eval()))
# 建立事件文件
filewriter = tf.summary.FileWriter("./tmp/summary/test/", graph=sess.graph)
# 加载模型,覆盖模型当中随机定义的参数,从上次训练的参数结果开始
if os.path.exists("./tmp/ckpt/checkpoint"):
saver.restore(sess, FLAGS.model_dir)
# 循环训练 运行优化
for i in range(FLAGS.max_step):
sess.run(train_op)
# 运行合并的tensor
summary = sess.run(merged)
filewriter.add_summary(summary, i)
print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i, weight.eval(), bias.eval()))
saver.save(sess, FLAGS.model_dir)
return None














 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









