






推荐稳定扩散AI自动纹理工具: DreamTexture.js自动纹理化开发包
介绍
大型语言模型 (LLM) 和基础计算机视觉模型的最新突破为编辑图像或视频解锁了新的界面和方法。您可能听说过修复、复绘、生成填充和文本到图像;这篇文章将向您展示如何通过仅使用文本提示和最新的开源模型构建自己的可视化编辑器来执行这些新的生成式 AI 功能。
图像编辑不再是使用托管软件进行手动操作。Segment Anything Model (SAM)、Stable Diffusion 和 Grounding DINO 等模型使得仅使用文本命令执行图像编辑成为可能。它们共同创建了一个强大的工作流程,将图像零样本检测、分割和修复无缝结合在一起。本教程的目标是演示这三个强大模型的潜力,以帮助您入门,以便您可以在此基础上进行构建。
完全更改对象

用于零射物体检测的提示:“消防栓”,用于生成的提示:“照相亭”
更改对象的颜色和纹理

用于零射物体检测的提示:“Car”,用于生成的提示:“Red Car”
具有上下文的创意应用程序

用于零射物体检测的提示:“尤达”,用于生成的提示:“星球大战中的浣熊尤达”
#Step 1:安装依赖
我们的流程从安装必要的库和模型开始。我们从SAM(一种强大的分割模型)、用于图像修复的Stable Diffusion和用于零射物体检测的GroundingDINO开始。
!pip -q install diffusers transformers scipy segment_anything
!git clone https://github.com/IDEA-Research/GroundingDINO.git
%cd GroundingDINO
!pip -q install -e .#Step 2:检测、预测、提取掩码
我们将使用接地 DINO 根据文本输入进行零射物体检测,在本例中为“消火栓”。使用 GroundingDINO 的 predict 函数,我们获取图像的框、对数和短语。然后,我们使用这些结果对图像进行注释。
from groundingdino.util.inference import load_model, load_image, predict, annotate
TEXT_PROMPT = "fire hydrant"
boxes, logits, phrases = predict(
model=groundingdino_model,
image=img,
caption=TEXT_PROMPT,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD
)
img_annnotated = annotate(image_source=src, boxes=boxes, logits=logits, phrases=phrases)[...,::-1]
使用GroundingDINO进行零样本物体检测
使用 SAM 从边界框中提取掩码
然后,我们将使用 SAM 从边界框中提取掩码。
from segment_anything import SamPredictor, sam_model_registry
predictor = SamPredictor(sam_model_registry[model_type](checkpoint="./weights/sam_vit_h_4b8939.pth").to(device=device))
masks, _, _ = predictor.predict_torch(
point_coords = None,
point_labels = None,
boxes = new_boxes,
multimask_output = False,
)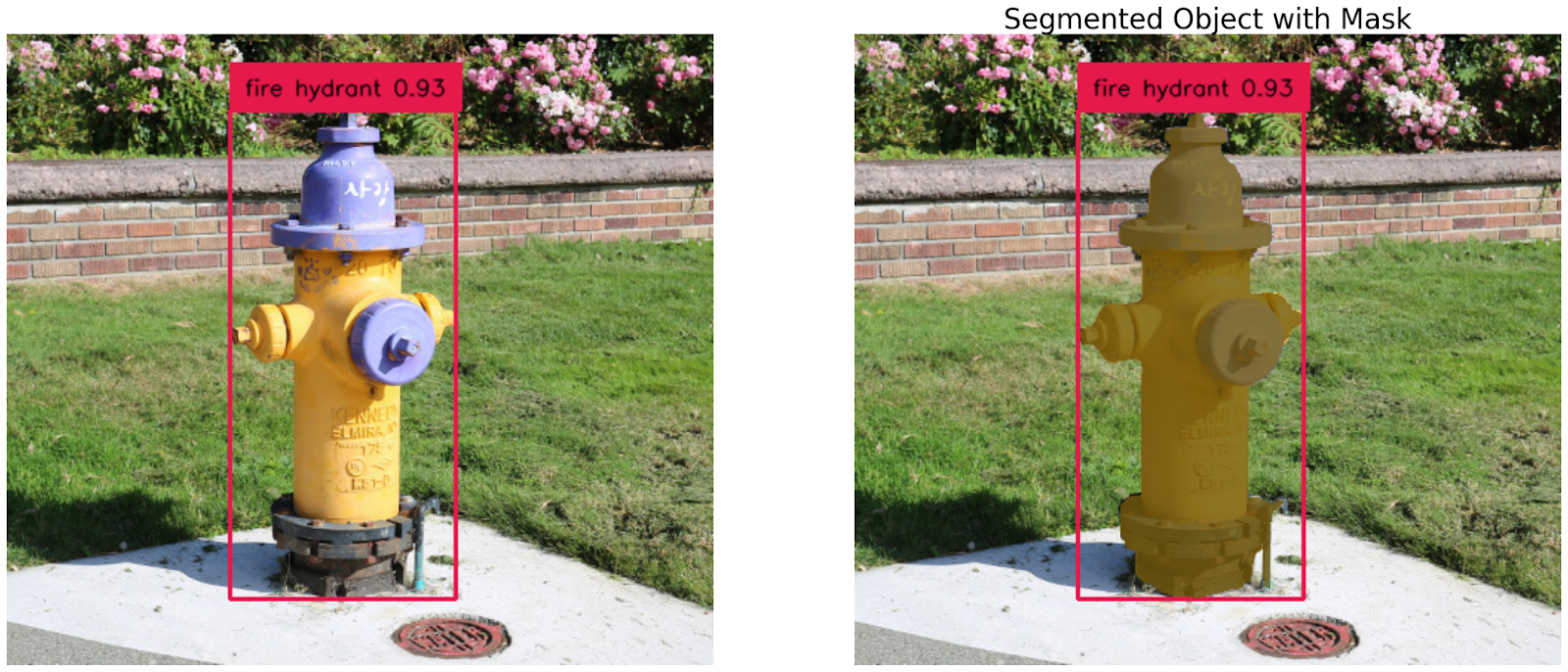
使用 SAM 的带掩码的分段对象

#Step 3:使用稳定扩散修改图像
然后,我们将使用稳定扩散根据文本提示修改图像。Stable Diffusion 的管道功能用于使用文本提示的内容对蒙版标识的区域进行涂色。请记住这一点,对于您的用例,您将希望上色的对象与它们要替换的对象具有相似的形式和形状。
prompt = "Phone Booth"
edited = pipe(prompt=prompt, image=original_img, mask_image=only_mask).images[0]
使用文本提示编辑图像的用例
- 快速原型设计:通过快速可视化加速产品开发和测试,使设计人员和开发人员能够更快地获得反馈和决策。
- 图像翻译和本地化:通过翻译和本地化视觉内容来支持多样性。
- 视频/图像编辑和内容管理:使用文本提示而不是 UI 加快图像和视频的编辑速度,满足个人创作者和企业的大规模编辑任务。
- 物体识别和替换:轻松识别物体并用其他物体替换它们,例如用可乐瓶替换啤酒瓶。
结论
就是这样!利用 SAM、Stable Diffusion 和 Grounding DINO 等强大的模型,使图像转换更轻松、更易于访问。使用基于文本的命令,我们可以指示模型执行精确的任务,例如识别对象、分割对象以及用其他对象替换它们。















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









