






Stable Diffusion升级到V1.6版本,长话短说,主要体现三个方面:
**1、界面UI优化;
**
**2、常用功能补充;
**
3、其他。
一、版本升级
1、使用秋叶包的同学直接在启动台界面的版本管理升级即可。
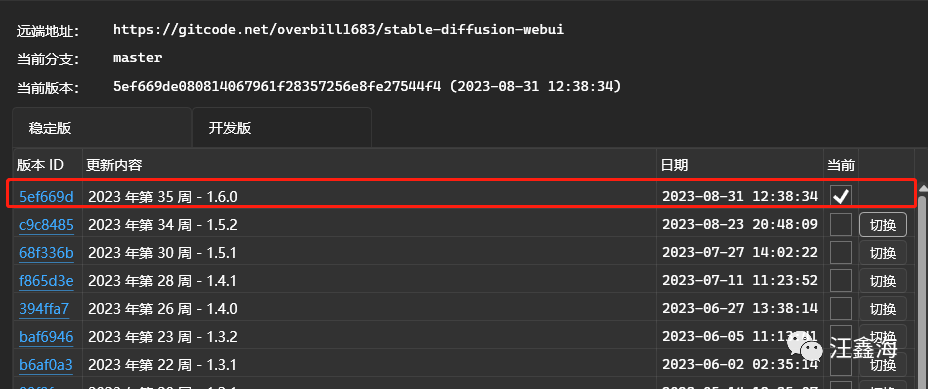
2、官网升级:
官方仓库地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
二、功能优化
1、界面UI优化;
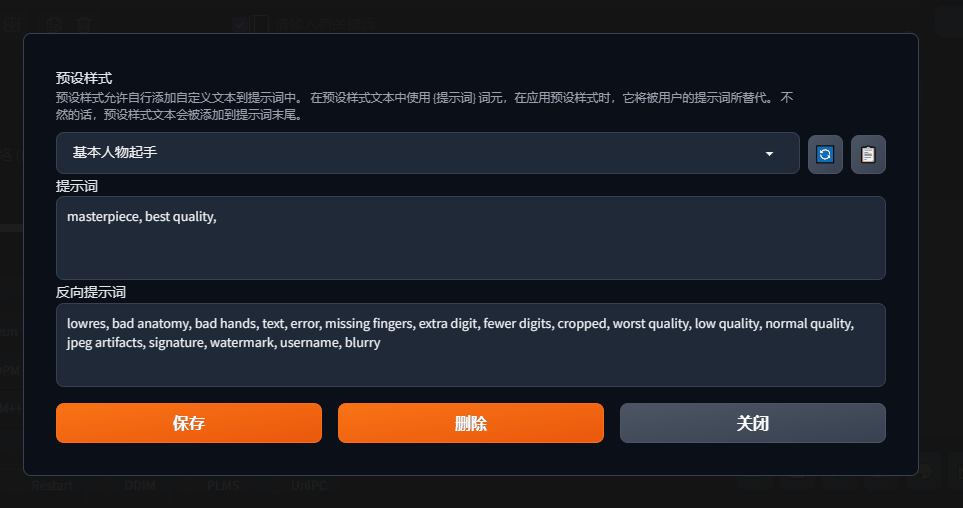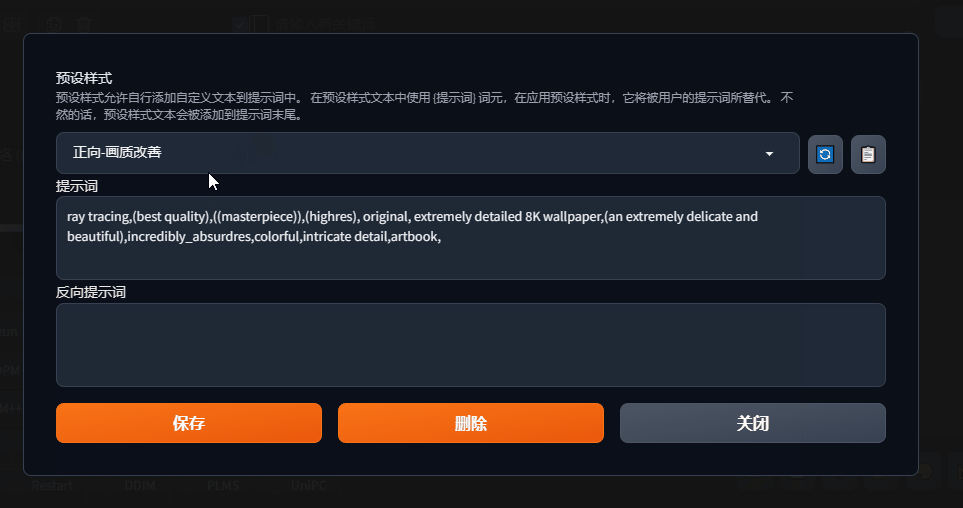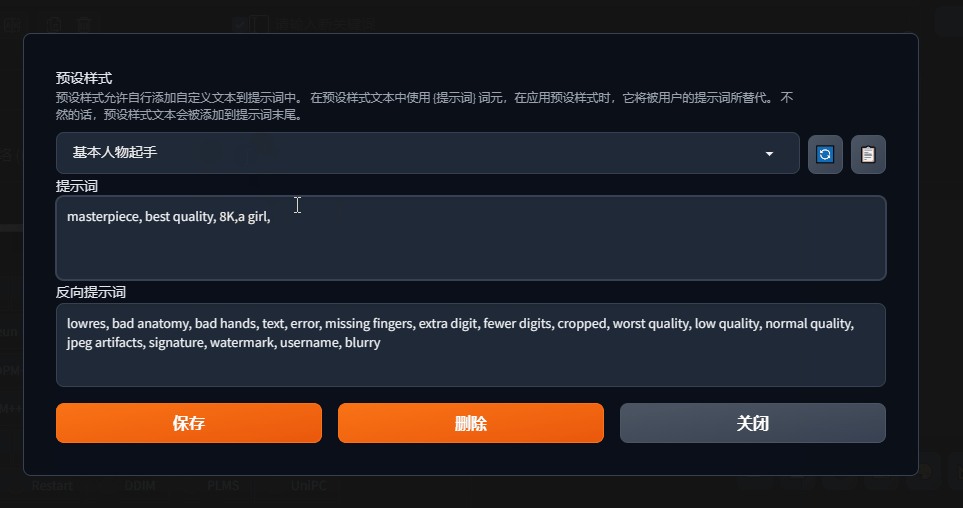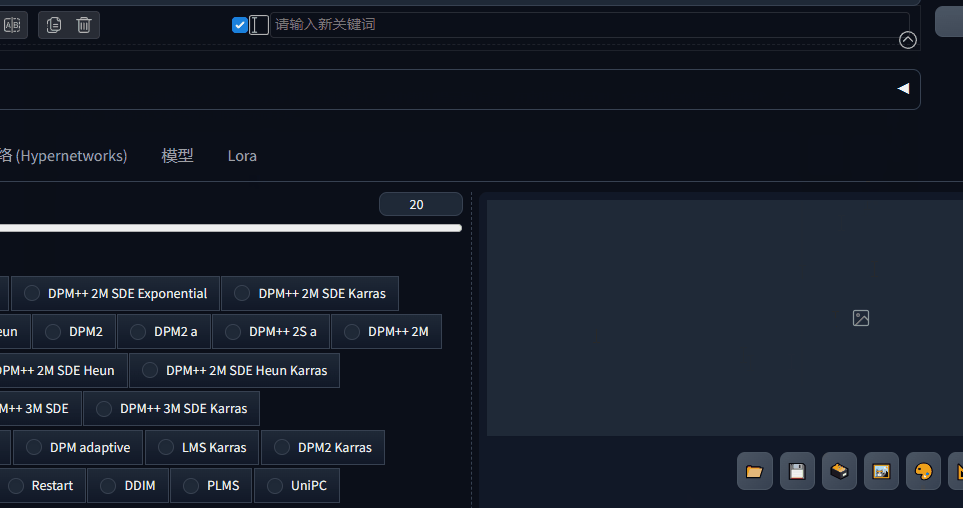
1、小模型(嵌入式 (T.I. Embedding)/超网络 (Hypernetworks)/大模型/Lora)位置调整了。
原来在生成图片按钮下面放了一个红色图标,用来展开和隐藏小模型,现在直接与生成图片参数设置并列的导航栏,用的时候直接点击选择即可。
2、生成图片参数设置和图片生成的窗口之间的分界线,可以用鼠标自由控制拖动。
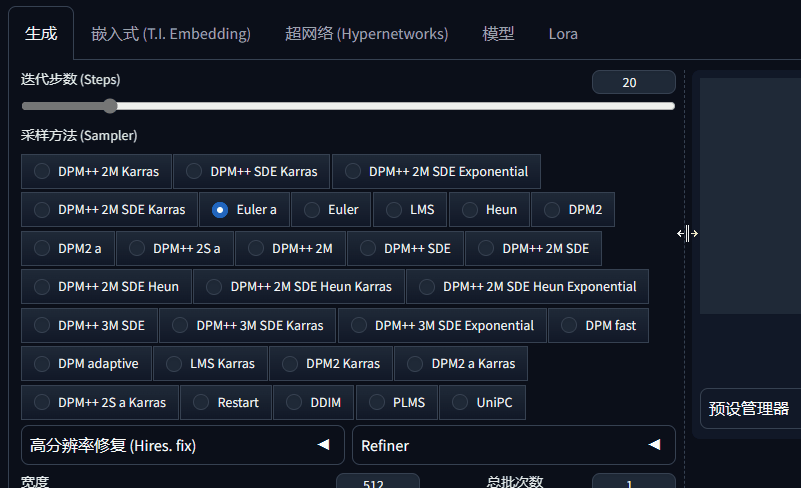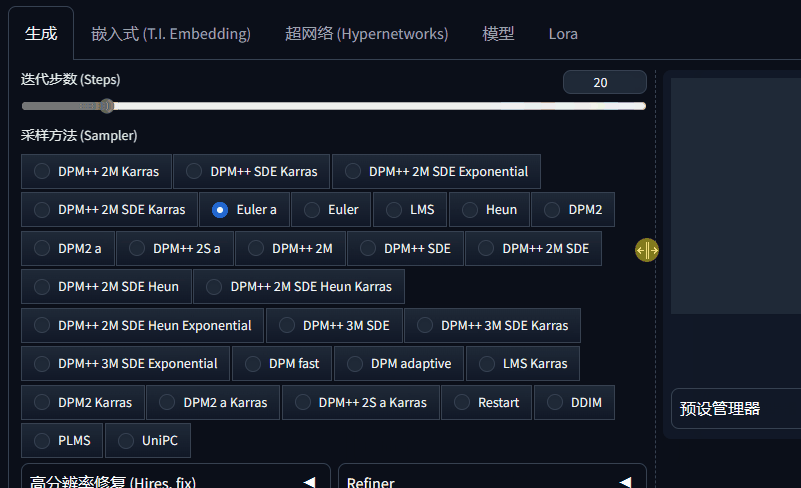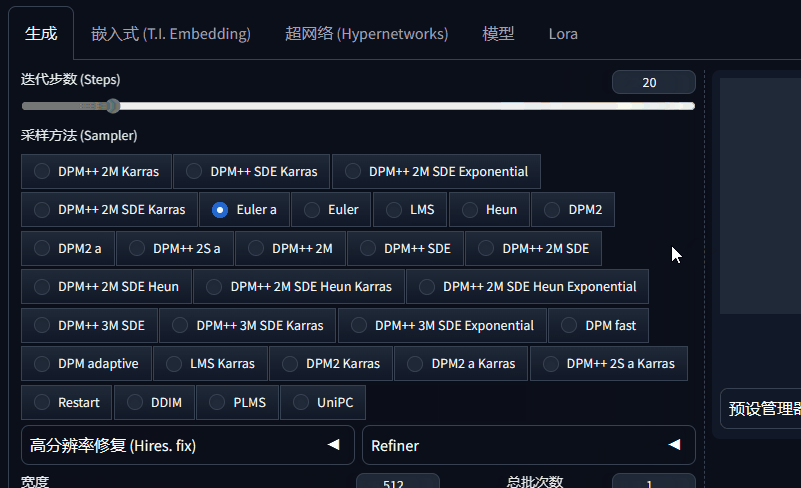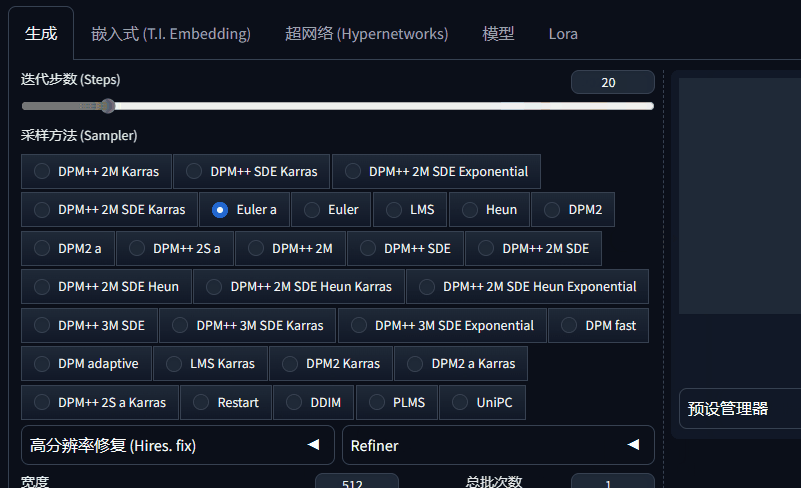
3、图片生成窗口下面的UI图标做了简化更新,这个更新到底好不好各有说法。
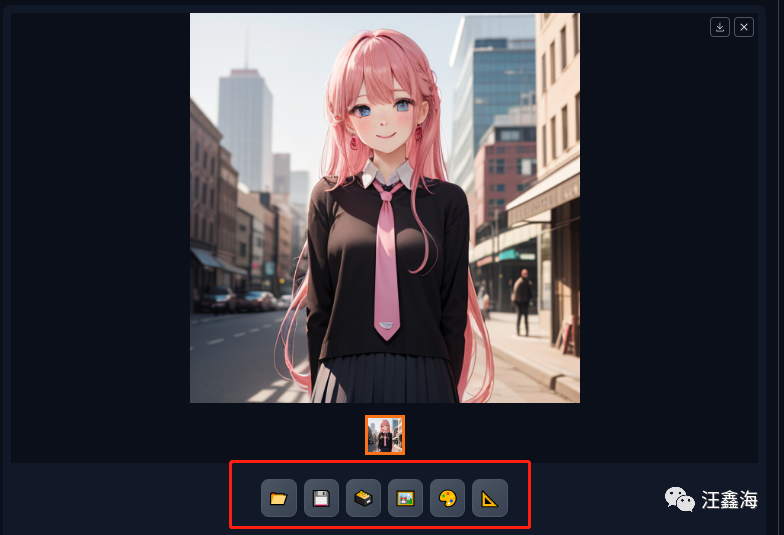
4、预设样式按钮和将预设样式应用到提示词窗口按钮合并一起了,就是这支笔。同时添加功能是,可以直接在界面编辑预设样式提示词,不用到之前的主目录中的styles.csv文件中编辑。
使用预设样式时,先选中自己要用的预设样式,然后点击后面这支笔,可以编辑对应的样式,
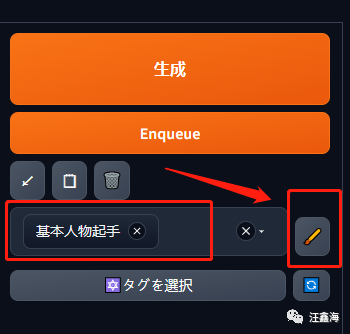
弹出提示词编辑窗口,这里用gif简单演示一下,
2、常用功能补充
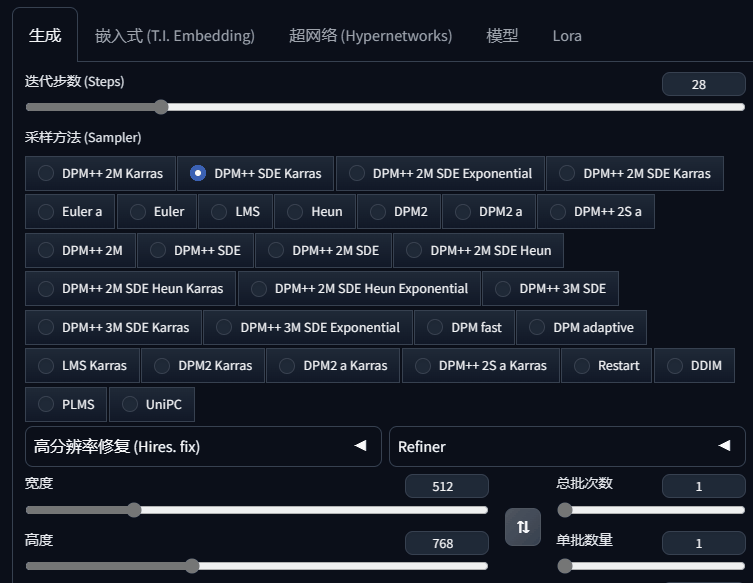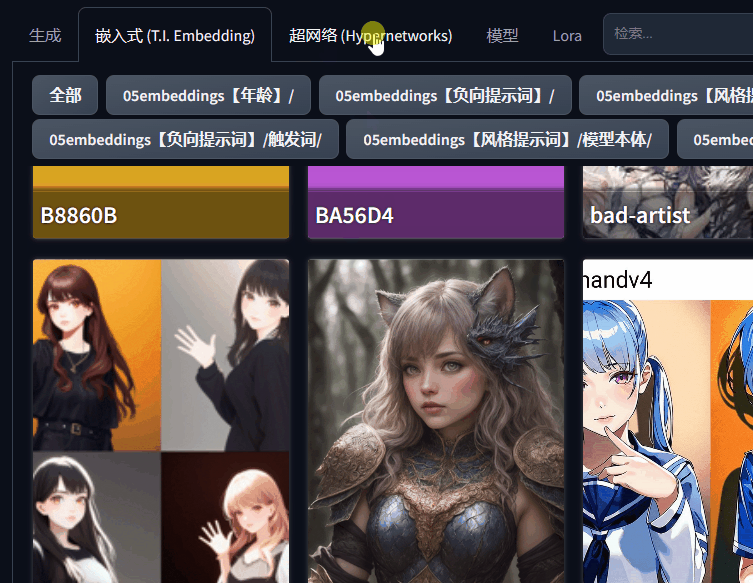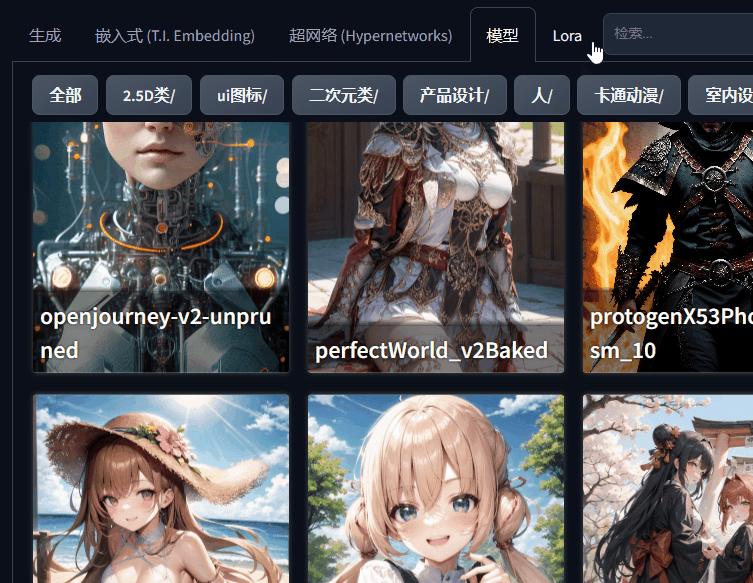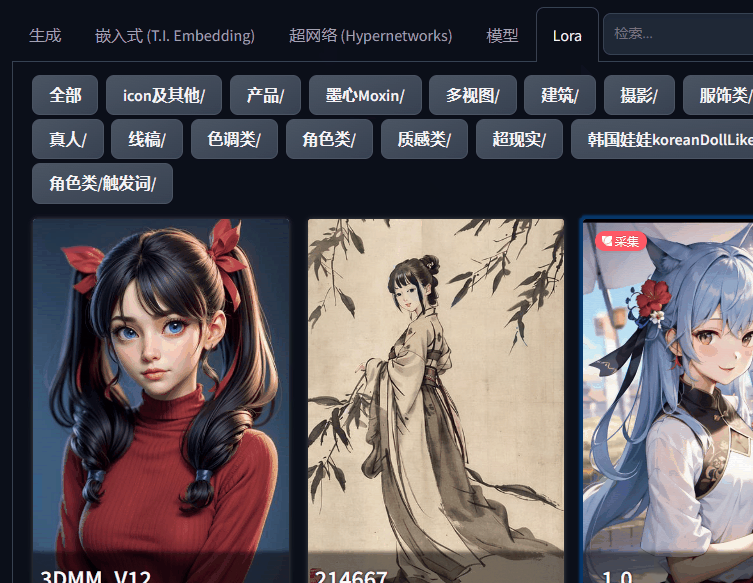
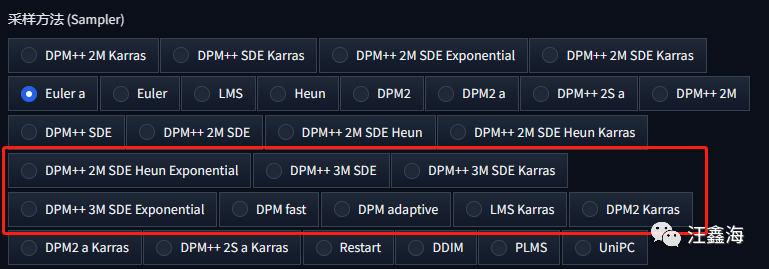
1、采样方法,增加了9种:
- DPM++ 2M SDE Exponential
- DPM++ 2M SDE Heun
- DPM++ 2M SDE Heun Karras
- DPM++ 2M SDE Heun Exponential
- DPM++ 3M SDE
- DPM++ 3M SDE Karras
- DPM++ 3M SDE Exponential
- LMS Karras
- Restart
下面我们来测试一下这9个采样方法在不同步数下的图片效果, 这里就以人脸为例,其他的效果大家可以自行测试。9个采样方法,采样步数:10,20,30,40,50,用XYZ轴脚本。
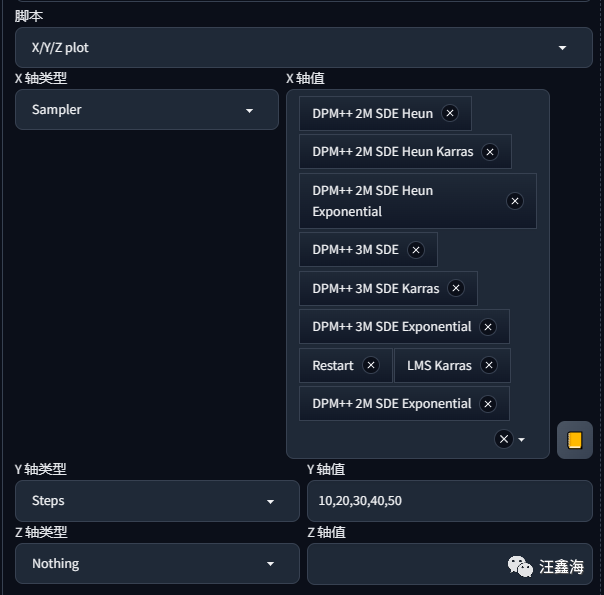
生成图片,下面是测试长图,为了能更好的看到不同采样步数的图片效果,这里就不做缩放了。
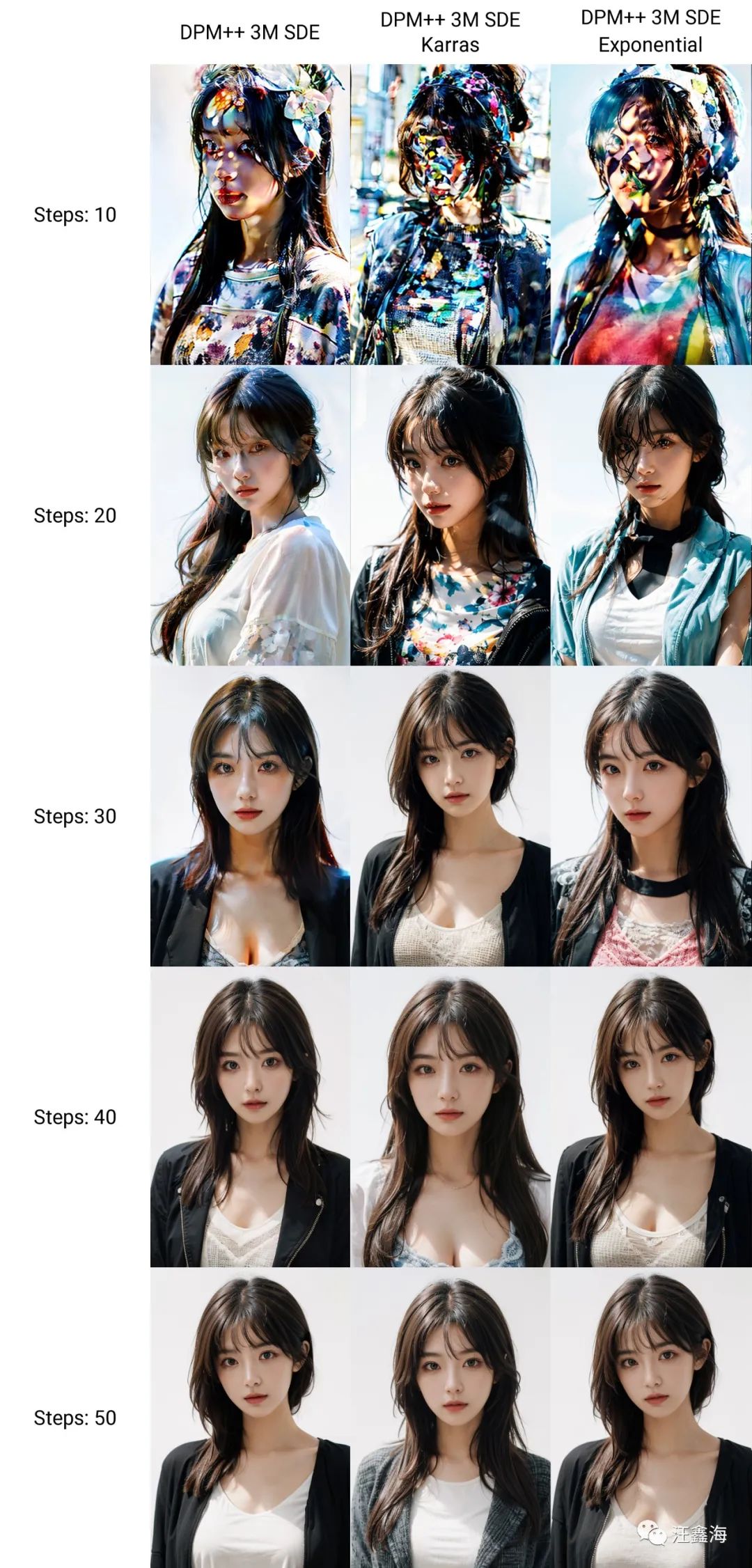
第一组
-
DPM++ 3M SDE
-
DPM++ 3M SDE Karras
-
DPM++ 3M SDE Exponential
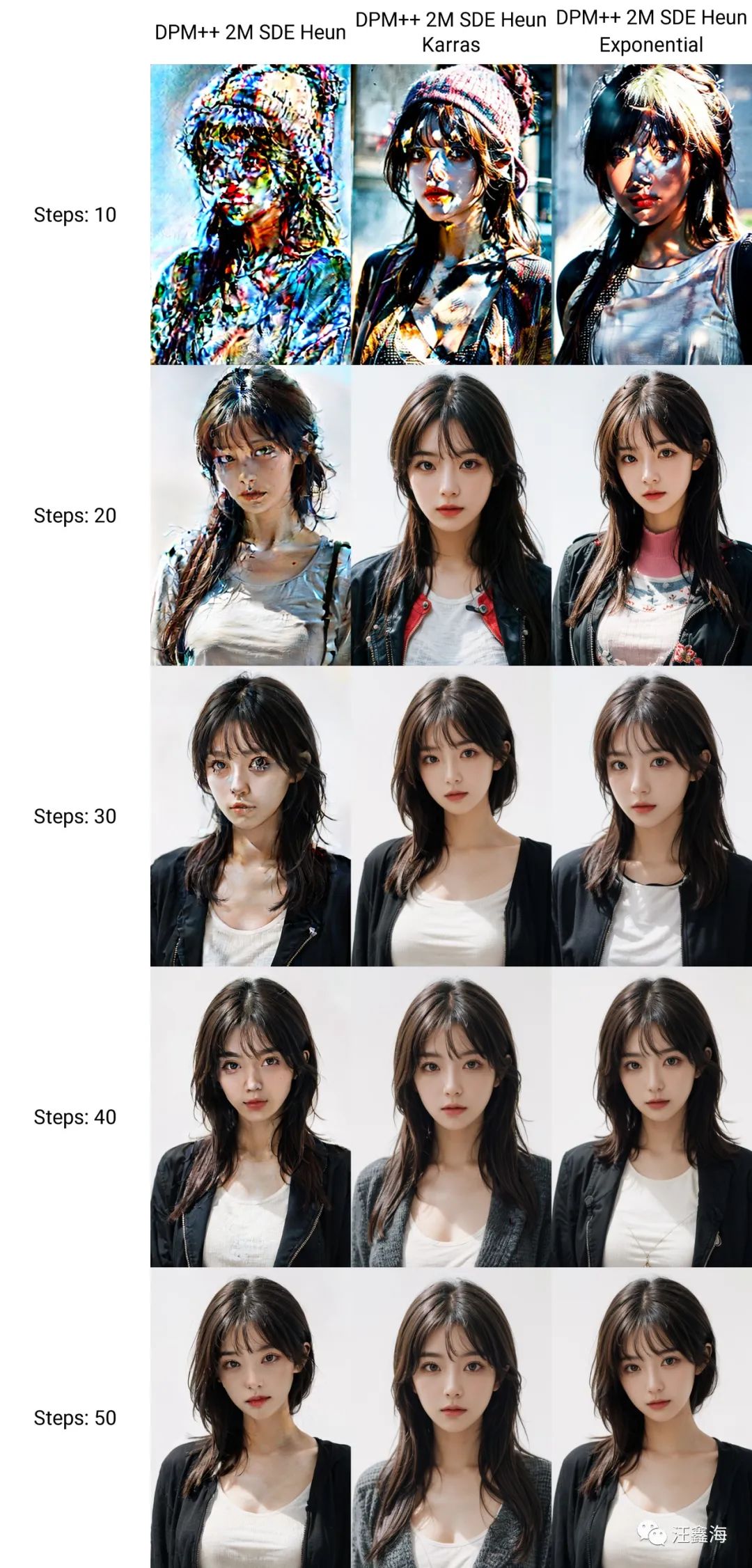
第二组
-
DPM++ 2M SDE Heun
-
DPM++ 2M SDE Heun Karras
-
DPM++ 2M SDE Heun Exponential
第三组
- DPM++ 2M SDE Exponential
- LMS Karras
- Restart

令人惊艳的是Restart,步数从10到50都是保持高质量的效果。
而DPM++ 2M SDE Heun Karras,在步数为40-50的时候,表现出来的效果也可以。
这里是以真实模型以及人像为例,大家可以自行测试其他风格。
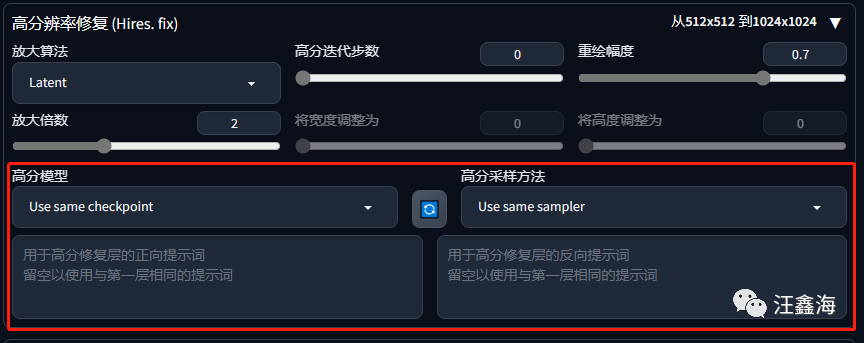
2、高分辨率修复 (Hires. fix)窗口,
这个窗口增加了一个高分模型和高分采样方法。
就是在放大图片的同时,进行重绘图片。可以理解为图生图的操作,比如先用大模型生成一个图片,然后在高分辨率里面设置其他的模型和风格,进行二次生成,得到最终的图片效果。
模型和采样方法下面可以填写想要重绘的内容提示词,也可以不填,不填就是保持底模提示词不变。这里我们可以填入LoRA,效果就会比原来直接放在底模提示词里面效果会好一些。
我们来演示一下,现在的需求是,我们想要一个模型的构图和样式,另一个模型的画风和氛围,以前我们现在文生图中先生成构图,然后再到图生图中进行油画风格,而现在我们可以使用高分模型进行一步到位。
这里选择墨幽人造人生成人像构图,然后用高分模型动漫化。
第一步,底模我们选择一个构图和泛化性比较好的模型:墨幽人造人.safetensors,

第二步,为了示例对比明显,这里高分模型选择风格化明显的迪士尼卡通模型:disneyPixarCartoon_v10-迪士尼&皮克斯。
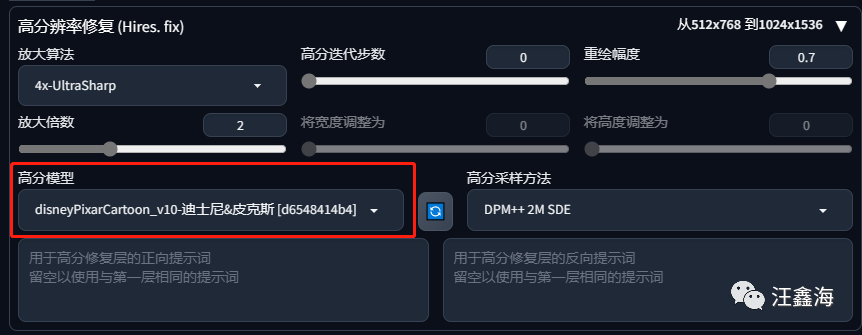
点击生成图片,
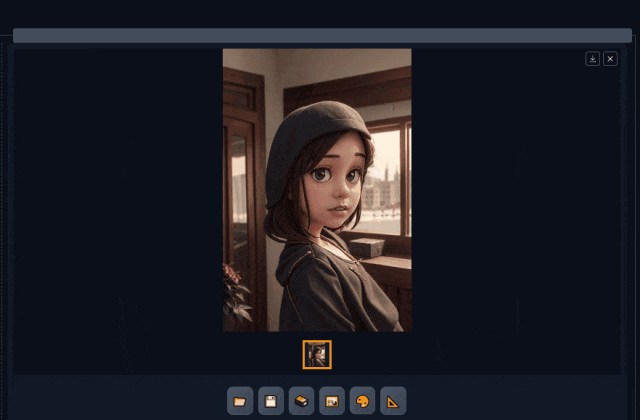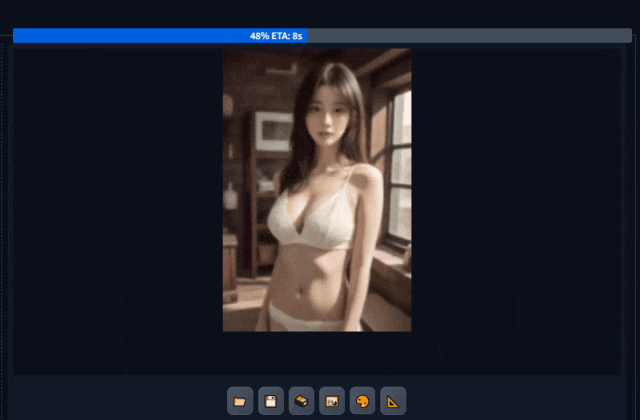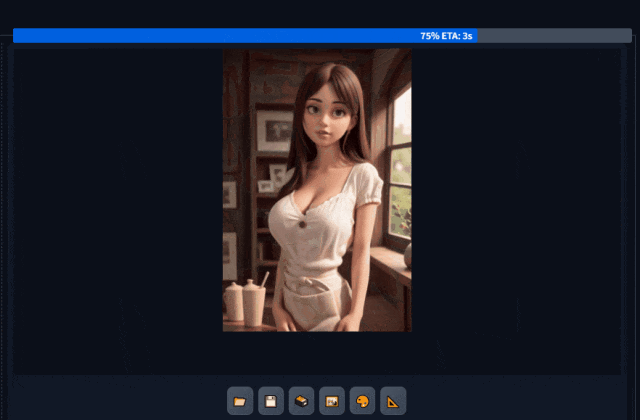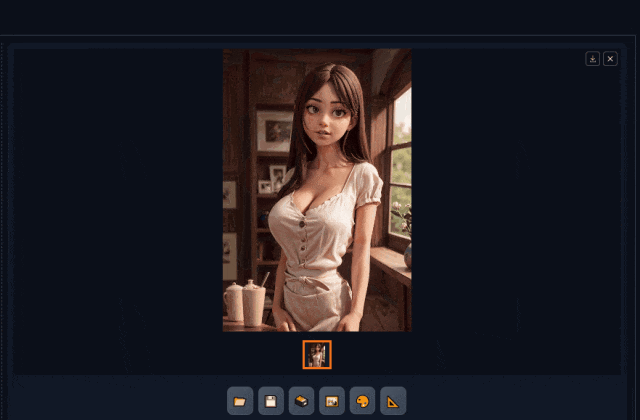
可以看到前部分模型风格写实化形成了构图场景,后面部分在放大图片的同时按照新的模型,重绘图片风格化。
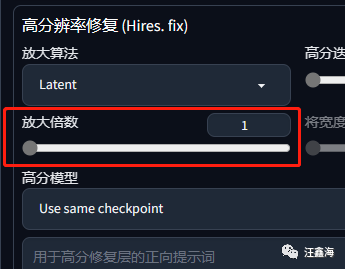
不想使用高分辨率修复,可以把放大倍数值调为1。
另外要说明一点,
这个窗口默认更新是没有的,需要重新设置一下:设置-用户界面-最下面的高分辨率修复两个选项打勾,
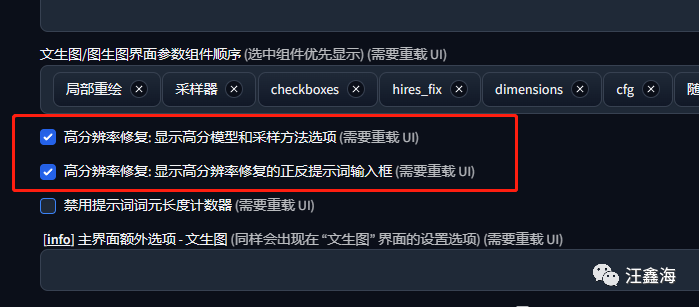
保存设置,重启SD,就会出现这个界面。
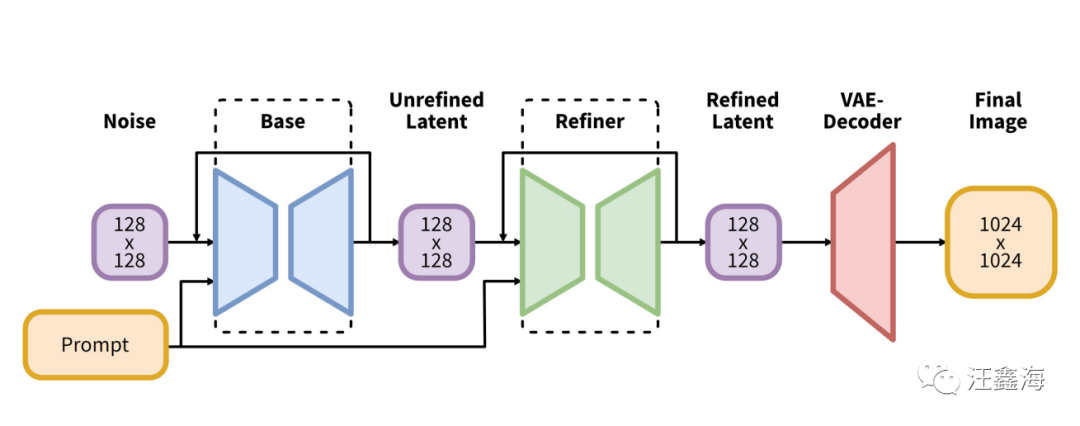
3、支持refiner:
SDXL 采用了一种两步走的生图方式,
- Base模型
这个Base模型就是用来生成词语生成图片的
- Refiner模型
这个refiner就是一个图片生成图片的,相当于是对生成图片进行一个优化
在高分辨率修复 (Hires. fix)后面加了一个Refiner窗口,
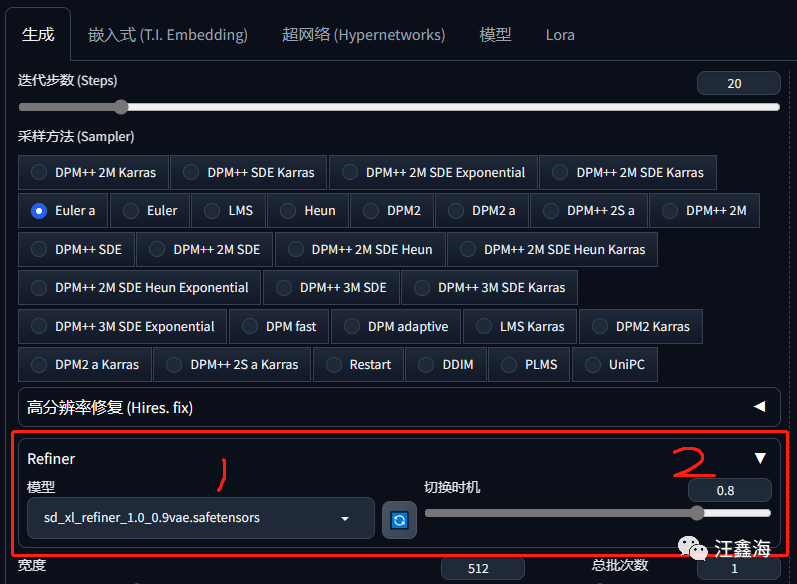
展开窗口可以看到两个选项,模型和切换时机,
模型可以选想要二次优化的风格方向的模型,
切换时机就是二次风格化图形时的切入时间,范围0-1,切换步数等于切换时机值:0.8x迭代步数(Steps)值:20等于16,即当第一个基础模型采样到第16步时,Refiner模型可以介入,到20步完成为止。
3、其他。
官网更新日志:https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.6.0
1、内存占用优化,SDXL 模型使用的内存大幅下降。

2、可以为每个模型选择VAE。

3、支持多种显卡。
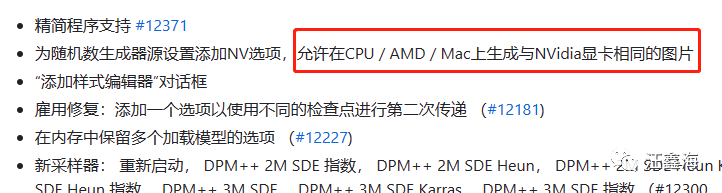
下面是官网的主要升级部分翻译部分,有兴趣的可以自行了解下。
- 精简程序支持 #12371
- 为随机数生成器源设置添加NV选项,允许在CPU / AMD / Mac上生成与NVidia显卡相同的图片
- “添加样式编辑器”对话框
- 雇用修复:添加一个选项以使用不同的检查点进行第二次传递 (#12181)
- 在内存中保留多个加载模型的选项 (#12227)
- 新采样器:重新启动, DPM++ 2M SDE 指数, DPM++ 2M SDE Heun, DPM++ 2M SDE Heun Karras, DPM++ 2M SDE Heun 指数, DPM++ 3M SDE, DPM++ 3M SDE Karras, DPM++ 3M SDE 指数 (#12300, #12519, #12542)
- 返工DDIM,PLMS,UniPC以使用与k扩散采样器相同的CFG降噪器:
- 使它们都与img2img一起工作
- 使快速组合成为可能(AND)
- 使它们可用于 SDXL
- 始终在 UI 中显示额外的网络选项卡 (#11808)
- 创建模型时使用较少的 RAM(#11958、#12599)
- SDXL 的文本反转推理支持
- 额外网络 UI:显示 SD 检查点的元数据
- 检查点合并:添加元数据支持
- 提示编辑和注意:在数字后添加对空格的支持 ([ 红色 :绿色 :0.5 ]) (种子中断更改) (#12177)
- VAE:允许为每个检查点选择自己的VAE(在用户元数据编辑器中)
- VAE:将选定的VAE添加到信息文本
- 主UI中的选项:为txt2img和img2img添加自己的单独设置,从粘贴的信息文本中正确读取值,为列计数添加设置(#12551)
- 将调整大小手柄添加到 TXT2IMG 和 IMG2IMG 选项卡,允许更改为生成参数和生成的图像库提供的地平线表空间量(#12687、#12723)
- 更改批处理 cond/uncond 的默认行为 - 现在它默认处于打开状态,并且被 UI 设置禁用(Optimizatios -> 批处理 cond/uncond) - 如果您在 lowvram/medvram 上并且收到 OOM 异常,则需要启用它
- 显示队列中的当前位置,并使其按到达顺序处理请求 (#12707)
- 添加仅适用于 SDXL 模型的标志–medvram-sdxl–medvram
- 提示编辑时间线对首次通过和雇用修复传递(种子突破性更改)具有单独的范围 (#12457)
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 2183
2183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









