









损失函数源码参考这里yolo_layer.c
本文参考这里和这里
yolo_layer.c中的delta指的是对网络层原始输出y'的负梯度, delta=-gradient
总的来说, loss可分为loss_obj, loss_noobj, loss_cls, loss_coor4个部分, 前3个部分都用到了BCE(binary cross entropy)(网上很多复现的代码中, 损失和原文是有出入的, 比如这个的loss_coor for xy是用BCE)
关于BCE:
BCE是二分类的交叉熵损失, 在BCE中,
y是标签(y=0或者1), p是预测的概率(p=0~1),
y'是网络层的原始输出
损失L对y'求导得
关于坐标映射:
再看看网络预测的坐标t和真实坐标b的映射关系
首先对网络的xy预测和objec score以及C位的类别预测做sigmoid变换(logistic激活函数)
下面分别看这几部分损失
1. loss_obj和loss_noobj
【这里依次遍历特征图上每个像素点,来计算loss_conf_obj和loss_conf_noobj损失(实际上负样本的损失,即loss_conf_noobj都是在这一层循环计算的)】
首先将所有的先验box都看做是noobject, 所以l.delta[obj_index] = -gradient = y - p = 0 - l.output[obj_index] (这里的l.output[obj_index]就是BCE经过sigmoid激活后的值p, 前面已经说过先对这部分施加logistic激活函数, 0是标签y)
其次, 如果预测的box和truth的iou大于l.ignore_thresh, 这些box就不参与loss_conf_obj和loss_conf_noobj的计算(实际上结合下面的依次遍历每个目标的最优, 就是如果box不是最好的,但是iou大于阈值, 就不参与loss_conf_obj和loss_conf_noobj损失的计算), 所以梯度=0
最后如果iou大于truth_thresh(cfg中是1), 参与计算loss_conf_obj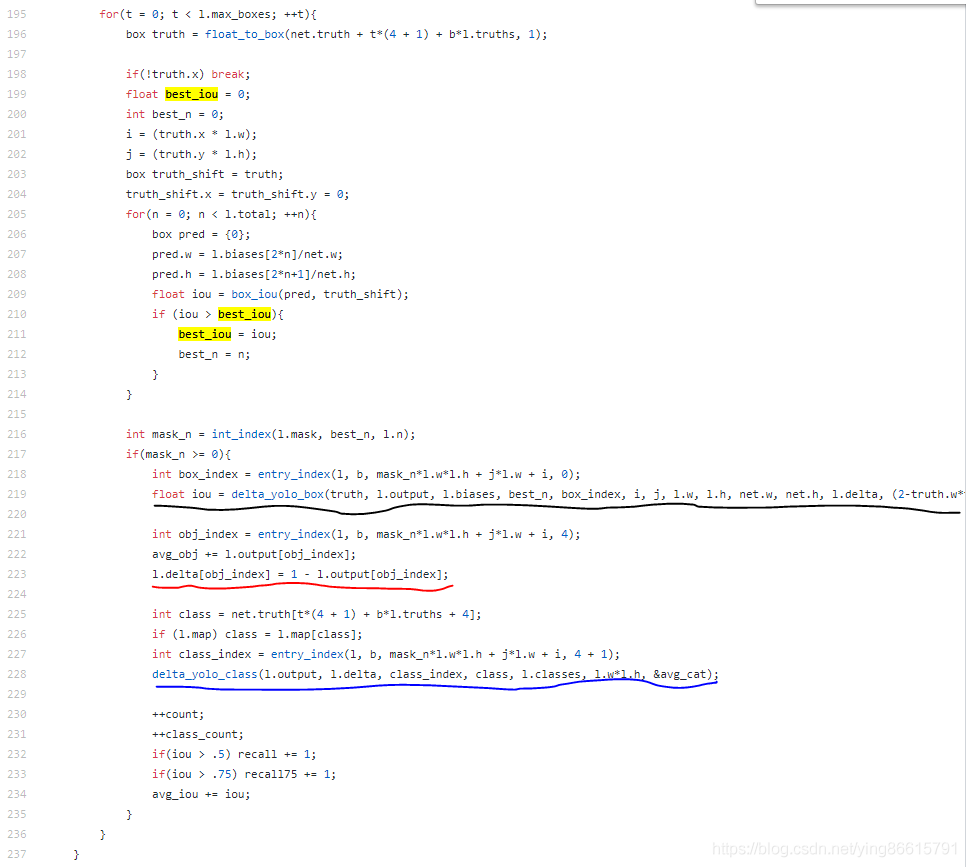
【这里依次遍历每个目标,来计算loss_coord, loss_conf_obj, loss_cls(实际上正样本的损失都是在这一层循环计算的,因为上面best_iou > l.truth_thresh不会为真(如果truth_thresh=1))】
先为每个目标匹配到最好的先验box(就是iou在所有先验box中最大)看坐是object, 所以l.delta[obj_index] = 1 - l.output[obj_index]
这里附上object的标签分配规则
1.如果1个GTbox与某1个先验的bbox的重合度IOU最高(比其他先验的bbox都高), 那么置信度标签为1. 由此可知, 1个GTbox只分配1个先验的bbox, 有多少个objects, 就有多少个标签为1的样本. (并且只有这些样本参与loss_cls和loss_coor的计算)
2.如果1个GTbox与其他先验的bbox的重合度不是最高,但是大于0.5,就忽略它们(表示不计算loss_obj也不计算loss_noobj)
3.其他没有分配到GTbox的先验bboxes,不参与计算坐标和类别损失,只参与计算非目标置信度损失(loss_noobj), 标签为0
2.loss_cls
第一部分看不懂(if (delta[index]))
后面是对每个class的预测算梯度(假设是80类, 就是有80个BCE, )
class表示真实类别的索引, 在该类别上delta = - gradient = 1 - output[](前面说过了, 这里的output是经过logistic激活的),
在其他错误的类别上delta = -gradient = 0 - output[]
3.loss_coor
xy坐标损失是在输出经过sigmoid激活后计算的(上图的x[index + 0*stride]和x[index + 1*stride]分别表示预测的σ(pred_x), σ(pred_y), 前面说过, 这里是经过logistic激活函数的), wh坐标损失是在网络原始输出上计算的
也就是在[tx, ty, tw, th]和[σ(pred_x), σ(pred_y), pred_w, pred_h]之间计算的
所以需要把truth的原始坐标转换一下得到tx, ty, tw, th
坐标损失使用的是MSE
而MSE对预测值x求导为
这里的scale是一个系数=(2-w*h), 对于越小的目标, 系数越大![]()
这里关于xy的损失有个疑问, mse对σ(x或y)的导数如上, 但是不应该进一步对x或y的网络的原始输出再做偏导吗?即(后面是sigmoid的导数)
最后给一下最终的loss形式吧:
每项分别是loss_coor, loss_obj, loss_noobj, loss_cls. 带*的是ground truth, wi*和hi*是0~1之间的
从官方的模型的cfg文件中可以看出, 没有给任何的损失权重, 那么上面的λ系数都为1?
附上一个很不错的YOLOv3的Pytorch实现版本, 里面的标签生成在utils\utils.py\build_targets, loss计算在models.py\class YOLOLayer的forward里面(YOLOLayer表示网络的的输出层, 源码使用了FPN结构的Darknet, 有3个输出层, 对应3个不同的尺度).
这个版本使用的loss跟上面总结的差不多, 只是没有在坐标损失中引入系数(2-w*h), 下面对build_targets和YOLOLayer的forward中的损失计算做些小改动, 引入该系数:
修改后的build_targets(lambda_scale就是加入的系数):
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres):
# pred_boxes: [nsamples, nanchors, gridsize, gridsize, 4]
# pred_cls: [nsamples, nanchors, gridsize, gridsize, ncls]
# target: [nobjs, 6]
# anchors: [nanchors, 2]
# ignore_thres: scalar
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda else torch.ByteTensor
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
nB = pred_boxes.size(0)
nA = pred_boxes.size(1)
nC = pred_cls.size(-1)
nG = pred_boxes.size(2)
# Output tensors
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0) # 1表示有目标的位置
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1) # 1表示没有目标的位置
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0)
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0)
tx = FloatTensor(nB, nA, nG, nG).fill_(0)
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
th = FloatTensor(nB, nA, nG, nG).fill_(0)
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0)
# Convert to position relative to box
target_boxes = target[:, 2:6] * nG # 坐标从0-1扩大到feature map的尺度上
gxy = target_boxes[:, :2]
gwh = target_boxes[:, 2:]
# Get anchors with best iou
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors]) # [nanchors, nobjs]
best_ious, best_n = ious.max(0)
# Separate target values
b, target_labels = target[:, :2].long().t() # [nobjs, 2] -> [2, nobjs]
# !!!!!! b:[nobjs], 样本序号, 例如 b=[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 2, 3], 表示13个目标, 0123表示第几个图片(batch中第几个样本)
# target_labels:[nobjs], 目标类别
gx, gy = gxy.t()
gw, gh = gwh.t()
gi, gj = gxy.long().t() # 向下取整, 从坐标获得grid cell坐标
# Set masks
obj_mask[b, best_n, gj, gi] = 1 # 对每个obj选取最好的anchor, 设置objectnetss score标签为1. 注意gj, gi的顺序?
noobj_mask[b, best_n, gj, gi] = 0 # 表示有目标
# Set noobj mask to zero where iou exceeds ignore threshold
for i, anchor_ious in enumerate(ious.t()): # ious.t(): [nobjs, nanchors]
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0 # !!!!!! 对于不是最好的但是大于某个阈值的anchors, 不计算noobj objectness loss
# Coordinates
tx[b, best_n, gj, gi] = gx - gx.floor()
ty[b, best_n, gj, gi] = gy - gy.floor()
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
# 坐标损失的系数 scale = 2-w*h
lambda_scale = FloatTensor(nB, nA, nG, nG).fill_(1)
lambda_scale[b, best_n, gj, gi] = 2 - gw/nG * gh/nG
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1
# Compute label correctness and iou at best anchor
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float() # 所有预测中类别预测正确则class_mask对应位置为1
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False) # 计算
tconf = obj_mask.float() # 表示 objectness score, 1的表示GT, 1的个数=nobjs
return iou_scores, class_mask, obj_mask.bool(), noobj_mask.bool(), tx, ty, tw, th, tcls, tconf, lambda_scaleYOLOLayer中修改的forward部分(loss_x, loss_y, loss_w, loss_h分别乘上lambda_scale):
......
#首先要在def __init__中把mse_loss的reduction去掉, 返回每个元素的loss
self.mse_loss = nn.MSELoss(reduction='none')
......
if targets is None:
return output, 0
else:
iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf, lambda_scale = build_targets(
pred_boxes=pred_boxes,
pred_cls=pred_cls,
target=targets,
anchors=self.scaled_anchors,
ignore_thres=self.ignore_thres,
)
# Loss : Mask outputs to ignore non-existing objects (except with conf. loss)
loss_x = (self.mse_loss(x[obj_mask], tx[obj_mask]) * lambda_scale[obj_mask]).mean() # 从上面可以知道, 这里x和y是经过sigmoid激活后的值: x=σ(x), y=σ(y)
loss_y = (self.mse_loss(y[obj_mask], ty[obj_mask]) * lambda_scale[obj_mask]).mean()
loss_w = (self.mse_loss(w[obj_mask], tw[obj_mask]) * lambda_scale[obj_mask]).mean()
loss_h = (self.mse_loss(h[obj_mask], th[obj_mask]) * lambda_scale[obj_mask]).mean()
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask])
loss_coord = loss_x + loss_y + loss_w + loss_h
total_loss = loss_coord + loss_conf + loss_cls
# Metrics
cls_acc = 100 * class_mask[obj_mask].mean()
conf_obj = pred_conf[obj_mask].mean()
conf_noobj = pred_conf[noobj_mask].mean()
conf50 = (pred_conf > 0.5).float()
iou50 = (iou_scores > 0.5).float()
iou75 = (iou_scores > 0.75).float()
detected_mask = conf50 * class_mask * tconf
precision = torch.sum(iou50 * detected_mask) / (conf50.sum() + 1e-16)
recall50 = torch.sum(iou50 * detected_mask) / (obj_mask.sum() + 1e-16)
recall75 = torch.sum(iou75 * detected_mask) / (obj_mask.sum() + 1e-16)
self.metrics = {
"loss": to_cpu(total_loss).item(),
"x": to_cpu(loss_x).item(),
"y": to_cpu(loss_y).item(),
"w": to_cpu(loss_w).item(),
"h": to_cpu(loss_h).item(),
"coord": to_cpu(loss_coord).item(),
"conf": to_cpu(loss_conf).item(),
"cls": to_cpu(loss_cls).item(),
"cls_acc": to_cpu(cls_acc).item(),
"recall50": to_cpu(recall50).item(),
"recall75": to_cpu(recall75).item(),
"precision": to_cpu(precision).item(),
"conf_obj": to_cpu(conf_obj).item(),
"conf_noobj": to_cpu(conf_noobj).item(),
"grid_size": grid_size,
}
return output, total_loss附上大牛对上面函数的逐行说明















 2000
2000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









