









来源: AINLPer微信公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2022-09-30
引言
注意力机制或图神经网络(GNN)生成长文本摘要,存在忽略黄金摘要中传递的关键语义信息以及忽略了单词之间的顺序和句法依赖性。针对这两个问题,本文提出了一个新的框架 GRETEL,用于长文本的提取摘要,为 PLM 提供神经主题推理,以充分结合局部和全局语义。 实验结果表明,模型型优于现有的最先进方法。

关注 AINLPer公众号,最新干货第一时间送达
背景介绍
众所周知,在文本摘要任务中,预训练语言模型 (PLM) 具有无法捕获长期依赖关系的局限性,有人提出尝试将神经主题模型 (NTM) 集成到PLM中。这样PLM不仅可以捕获的本地上下文信息,还可以为在文档内容中捕获的全局语义提供近似表示,即潜在主题及其后端主题表示。全局语义进一步用于指导模型,通过注意力机制或图神经网络(GNN)生成涵盖文档中讨论的最相关主题的连贯摘要。然而,由于现有方法的两大局限性,潜在主题作为近似全局语义和真正全局语义之间存在语义差距。
第一个限制是:涉及这些方法中无监督主题推理的本质,主题和后验主题分布以无监督的方式从文档中学习,而不考虑黄金摘要中传递的关键语义信息。现有的利用文档-词特征的方法,在不访问金摘要语义信息的情况下,可以提取高频词的次优主题。然而,使用高频词汇的次优主题不一定涵盖黄金摘要中浓缩的真正全局语义。这就导致了主题次优的文档分配错误,从而使得模型提取出包含高频主题词的冗余句。
另一个限制是,现有方法依赖于诸如 Bag-ofWords (BOW) 之类的文档单词特征来提取潜在主题,而忽略了单词之间的顺序和句法依赖性。这可能导致顺序和句法相关的词被分配给不同的主题。一种解决方案是为 NTM 提供来自 PLM 的上下文表示,但这对于直接应用于现有的文本摘要方法具有挑战性。由于语言模型的复杂性,现有方法中的 PLM 被迫将输入截断为有限长度。因此,来自文档部分内容的表示不一定能帮助 NTM 挖掘涵盖文档全部内容的信息主题,尤其是对于长文档。总体而言,尽管现有方法鼓励使用与文档主题分布在主题上相似的句子进行摘要,但摘要更侧重于高频词的句子,并且与黄金摘要的语义相似度较低。为了帮助理解这些限制,我们根据第 3 节中的基准数据集进行了详细分析。
模型介绍
针对上述问题,我们提出了一种新的图对比主题增强语言模型(GRETEL),该模型将基于黄金摘要和全局文档上下文语义信息的图对比主题模型(GCTM)与用于长文档提取摘要的PLM相结合。GRETEL的第一个显著特征是使用了分层Transformer编码器(HTE)来完全嵌入长文档的全局上下文,以通知文档和句子的主题表示。在HTE中捕获但BOW特性中缺失的全局上下文信息,使模型能够学习更具辨别性的文档和句子主题表示以及连贯的主题。
其次,利用黄金摘要的监督信息进行图对比学习;它拉近了与黄金摘要具有高度语义相似性的文档和句子的主题表示。这能够让模型捕捉更好的全局语义信息:描述原始文档内容中最关键信息的潜在主题。因此,它允许模型选择与黄金摘要主题相似的关键句。实验结果表明,该方法能够有效地从具有全局和局部语义的文档中区分显著句,具有较好的识别性能。
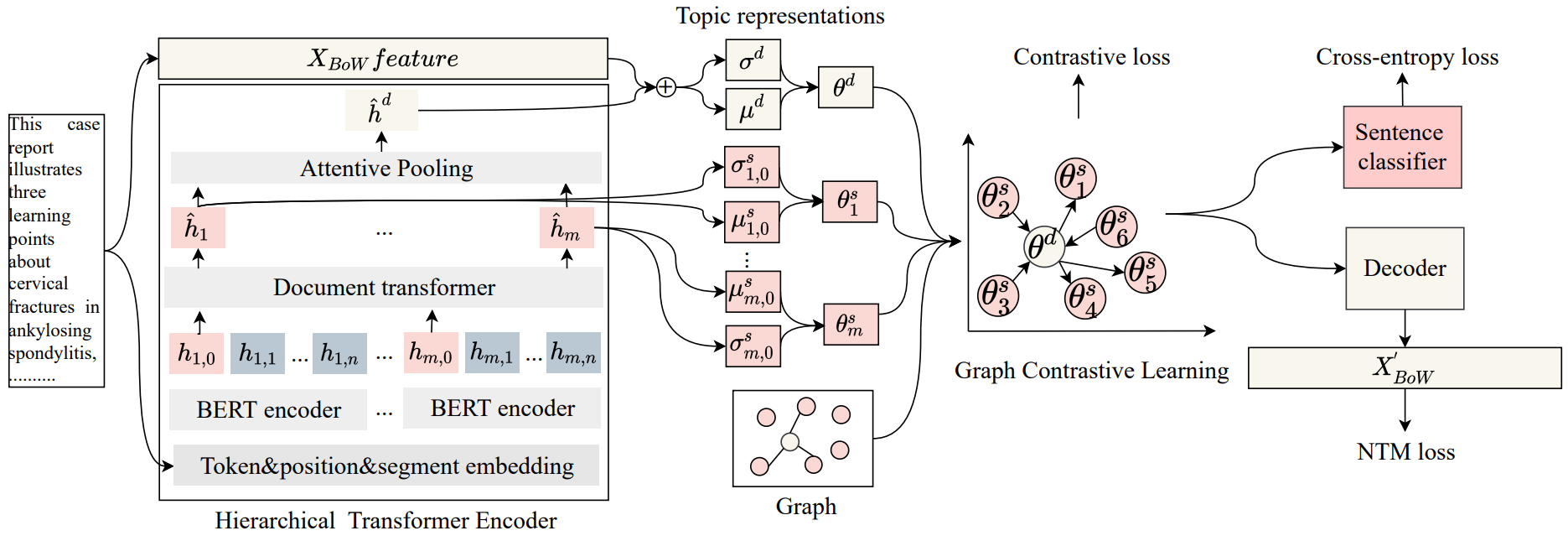
GRETEL 模型结构图如上所示,其中:
分层Transformer编码器:为了完全编码文档内容,特别是对于长文档,使用基于块的分层Transformer编码器(HTE),它有两个模块:块转换器编码器和文档转换器。
图对比主题模型:引入了图对比主题模型,以获取来自HTE和黄金摘要的语义信息的全局语义。它由一个带有HTE和监督图对比学习的概率主题编码器和一个概率解码器组成。
概率编码器:基于样本语句和文档表示,我们使用概率解码器生成观察词,并预测每个文档中句子的标签。
优化:我们从图对比主题建模和提取摘要两个方面优化损失函数,以支持联合推理。GRETEL的最终损失是证据下限(ELBO)和图的对比损失之和
实验快照
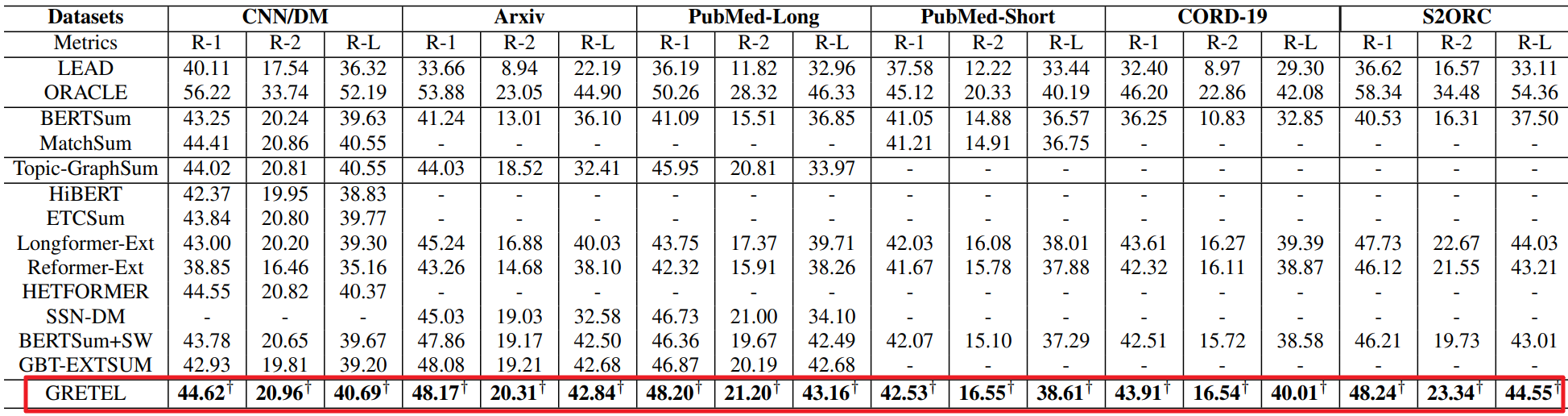
1、下表展示了不同模型在所有数据集上的 ROUGE F1 结果,可以发现本文方法 GRETEL 在所有数据集中优于所有现有的基线方法。
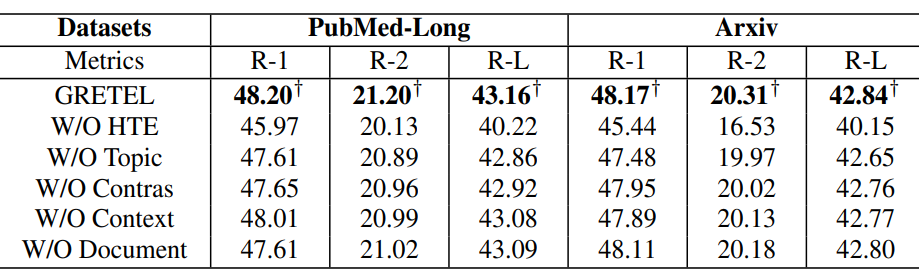
2、验证了每个组件对GRETEL性能改进的贡献,
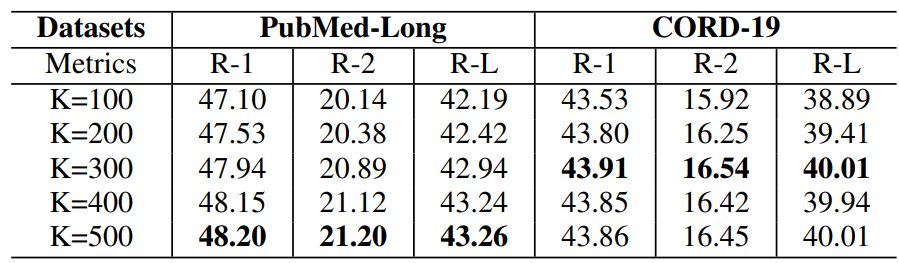
3、在长文档数据集PubMed-Long数据集和短文档数据集CORD-19上展示了不同主题号对GRETEL性能的影响。
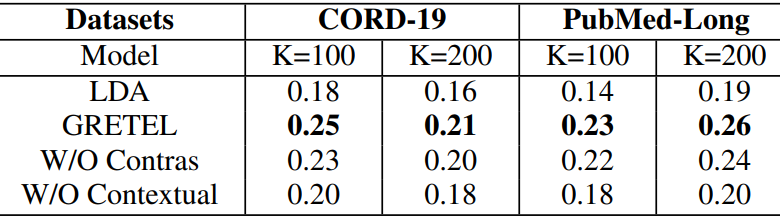
4、本文方法和经典主题模型LDA对比,验证生成的主题的质量。
推荐阅读
[1] 一文了解EMNLP国际顶会 && 历年EMNLP论文下载 && 含EMNLP2022
[2]【历年NeurIPS论文下载】一文带你看懂NeurIPS国际顶会(内含NeurIPS2022)
[3]【微软研究院 && 含源码】相比黑盒模型,可解释模型同样可以获得理想的性能
[4]【IJCAI2022&&知识图谱】联邦环境下,基于元学习的图谱知识外推(阿里&浙大&含源码)
[5]【NLP论文分享&&语言表示】有望颠覆Transformer的图循环神经网络(GNN)
[6]【NeurIPS && 图谱问答】知识图谱(KG) Mutil-Hop推理的锥形嵌入方法(中科院–含源码)
[7]【NLP论文分享 && QA问答】动态关联GNN建立直接关联,优化multi-hop推理(含源码)















 1192
1192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









