









1.背景介绍
RNN模型在机器翻译,语言模型,问答系统中取得了非凡的成就,由于RNN的结构,当前的层输入为前一层的输出,所有RNN比较适合时间序列问题,但也正是由于这种串行结构,限制了RNN模型的训练速度,与CNN相比,RNN并不能进行并行化处理。而SRU网络结构的提出就是为了解决这个问题,SRU(simple recurrent units)将大部分运算放到进行并行处理,只是将有具有小量运算的步骤进行串行。
2.SRU介绍
SRU算法主要是将运算操作最多的去除时间上的依赖关系,并进行并行化处理,下图将SRU结构与传统的RNN进行了对比。
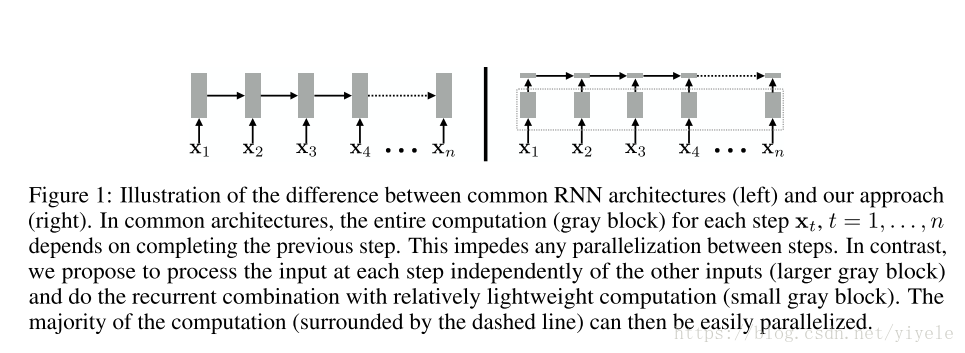
另外,与其它的算法相比:
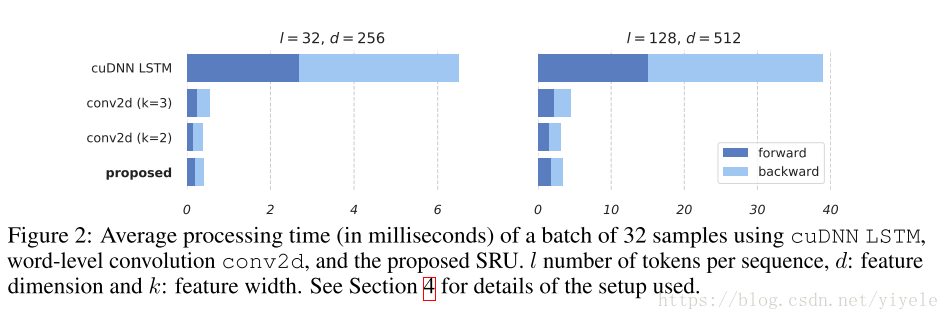
2.1 SRU网络结构
SRU基础结构包含了一个单一的forget gate,假定输入Xt和时间t,需要计算线性的转换˜xt 和forget gate ft,则:
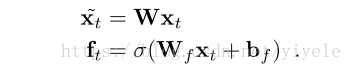
上面的计算仅仅依靠Xt,因此,能够进行并行化处理。
forget gate中包含internal state Ct,则计算output state ht:
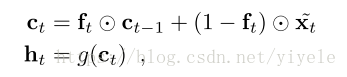
其中g表示激活函数。
因此,整个SRU网络结构的计算结构:
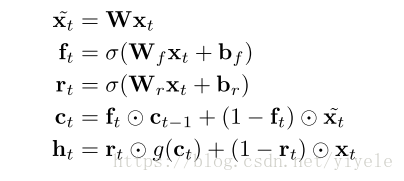
其中,f表示forget gate,r表示 reset gate,h表示output state,c表示internal state。x表示输入。
2.2 CUDA-LEVEL optimization
综合上面的公式:
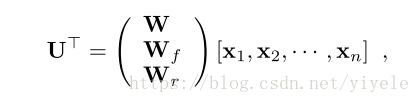
其中,n表示sequence length,U ∈ Rn×3d,d是hidden state size,k表示mibi-batcj的大小,U是一个(n,k,3d)的张量。
因此,Mini-batch版本的算法为:




















 3329
3329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











