









前言
前面文章介绍到,文档智能中版式分析(DLA)(《【文档智能 & RAG】RAG增强之路:增强PDF解析并结构化技术路线方案及思路》)、阅读顺序(《【文档智能】符合人类阅读顺序的文档模型-LayoutReader及非官方权重开源》)都是文档的智能结构识别和解析中非常重要的部分。传统的pipline的形式,首先通过版式分析的方法识别出文档中各个信息区块的位置信息及类别信息,然后通过使用阅读顺序的方法,复原出原始文档中各个区块的阅读顺序。本文介绍一种端到端的解决文档版式分析、阅读顺序的方法-DLAFormer,DLAFormer通过将各种DLA子任务视为关系预测问题,并将这些关系预测标签整合到一个统一的标签空间中,允许使用统一的关系预测模块同时处理多个任务。该方法将所有这些子任务集成到一个单一的模型中。
一、概念
1.1 文档图像(版面)组成

文档版面通常包含以下元素信息:
- 文本区域:页眉、页脚、标题、段落、页码、脚注、图片标题、表格标题等
- 表格
- 公式
- 图片
1.2 信息区块间的关系类型
文档中存在多种逻辑关系,最常见的是阅读顺序关系。文章定义了三种不同类型的关系:
-
内部区域关系(Intra-region relationship):在同一个文本区域内,所有相邻文本行之间建立内部区域关系。如果文本区域只包含一行文本,则该文本行的关系被指定为自引用。
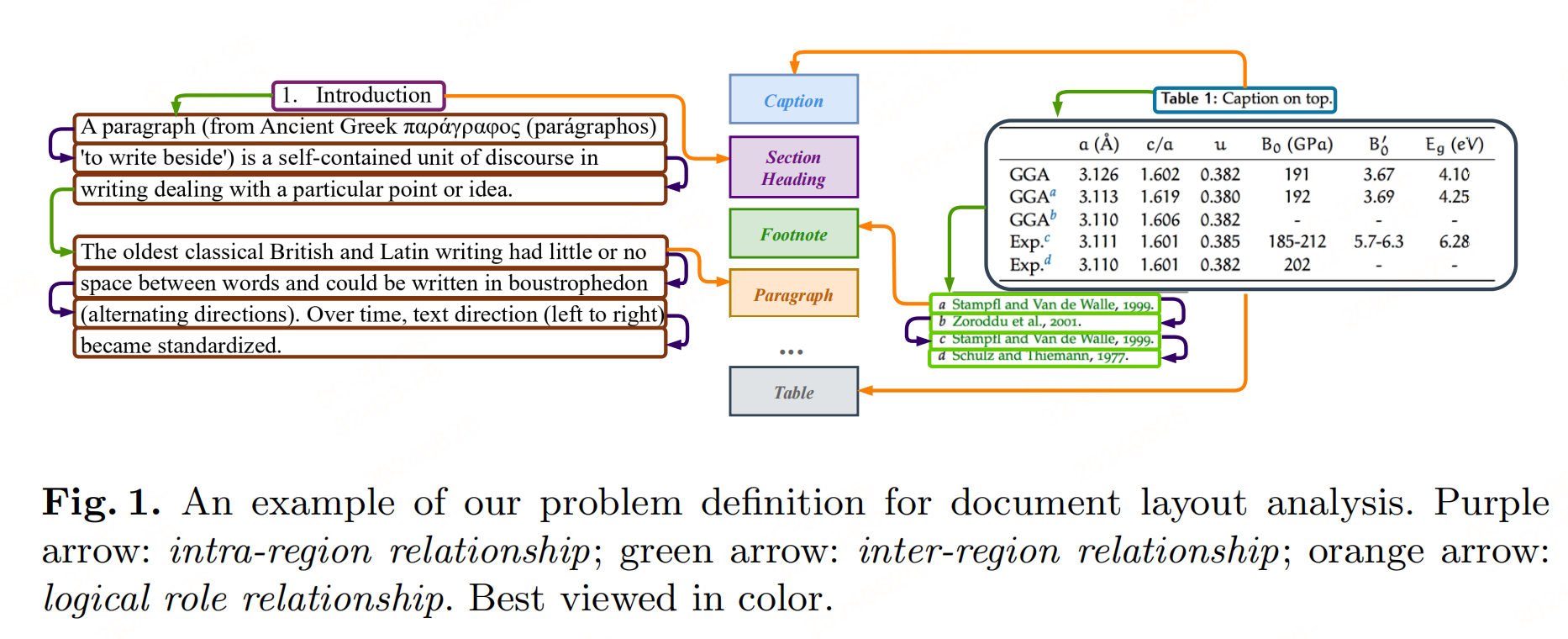
-
区域间关系(Inter-region relationship):构建所有表现出逻辑联系的区域对之间的区域间关系。例如,两个相邻段落之间或一个表格与其相应的标题或脚注之间的关系。
-
逻辑角色关系(Logical role relationship):定义了各种逻辑角色单元,包括标题、小节标题、段落等。由于每个文本区域都被分配了一个逻辑角色,因此在文本区域中的每行文本与其相应的逻辑角色单元之间建立逻辑角色关系。
1.3 问题转化
通过定义信息区块间的关系类型,将DLA的各个子任务(如:文本区域检测、区块分类和阅读顺序预测)转化为关系预测问题。这些不同的关系预测任务的标签被合并到一个统一的标签空间中,使得可以使用统一的模型同时处理这些任务。
二、模型架构
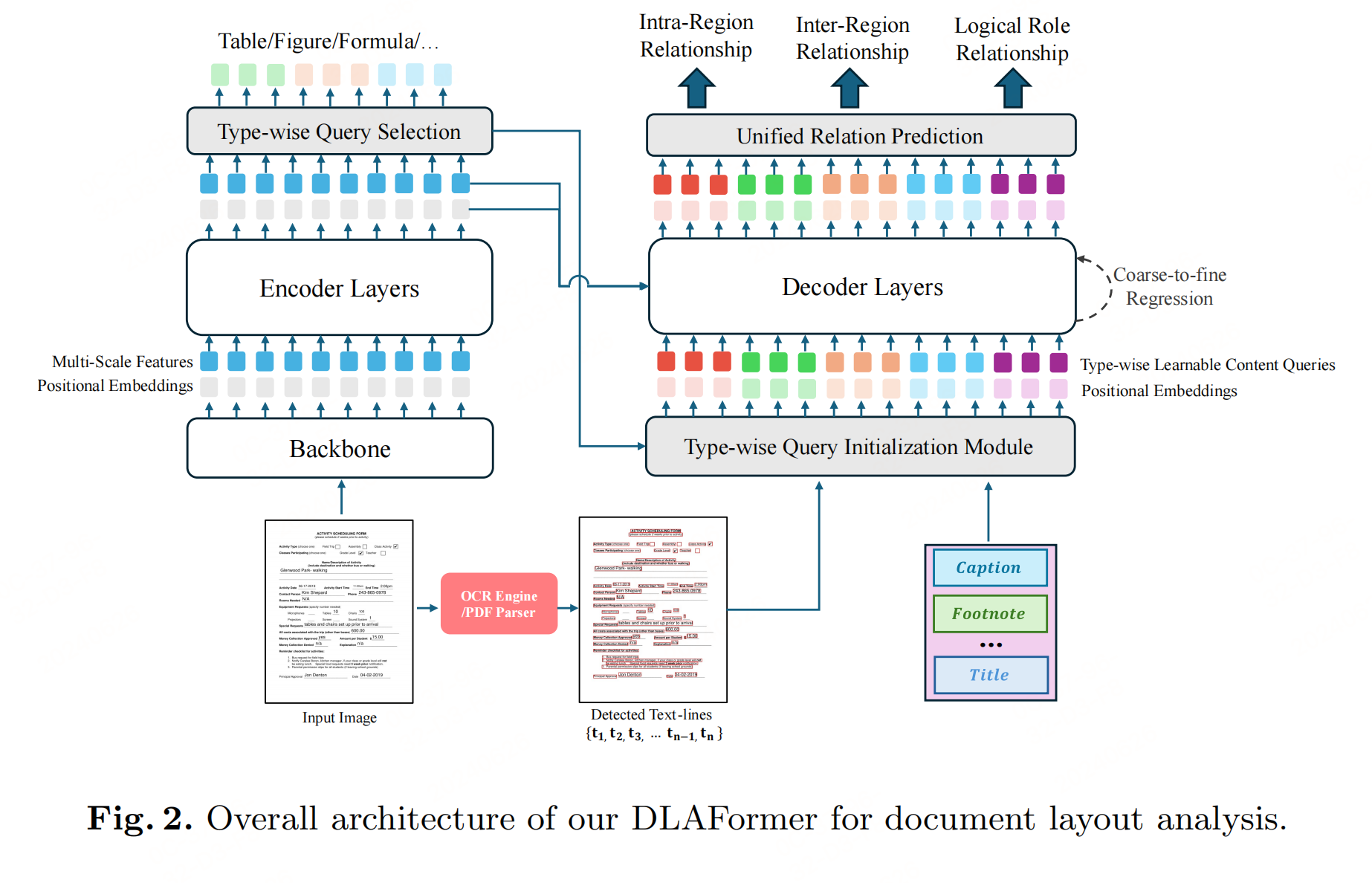
DLAFormer是一个基于Transformer的端到端方法,用于文档布局分析。它遵循DETR模型架构,包含以下几个主要组件:
- Backbone网络:用于从文档图像中提取多尺度特征。
- Transformer Encoder:处理输入特征并生成位置编码。
- Transformer Decoder:使用参考框和类别标签来处理潜在的图形对象提议。
- 统一关系预测头:用于同时处理多种关系预测任务。
- 粗到细检测头:用于精确识别文档图像中的图形页面对象。
2.1 Type-wise Query Selection
在传统的DETR及其变体中,解码器的查询通常是静态的嵌入向量,它们在训练过程中学习,但不包含来自编码器的多尺度特征。这可能导致解码器在处理特定图像时缺乏对特征的适应性。为了解决这个问题,DLAFormer提出了类型感知查询选择策略。该策略利用潜在的类别信息来初始化内容查询,从而使查询能够适应不同类型图形对象的视觉特征。
- 使用多类别分类器替代辅助检测头中的二分类器,以识别每个选定特征的类别。
- 初始化查询
- 位置查询:使用预测的参考框来初始化位置查询。这通常通过将参考框应用于正弦位置编码来实现。
- 内容查询:根据预测的类别,为每个查询选择相应的特征,这些特征是可学习的,并且与类别相关联。这样,每个查询的内容向量就会根据其类别进行初始化,增强了查询对特定类别特征的捕捉能力。
在DLAFormer中,类型感知查询选择策略通过一个辅助的检测头来实现,该检测头在训练过程中与主模型一起优化。通过这种方式,模型能够学习如何根据编码器特征的类别信息来初始化解码器查询,进而提高模型对文档布局的理解和分析能力。
2.2 Type-wise Query Initialization Module
该模块的目的是标准化不同查询之间的逻辑关系建模,确保解码器输入的统一性。通过为每种类型的查询分配特定的可学习特征来增强模型对不同区域特征的适应性。接收以下三个组件作为输入:
- 图像目标检测的候选框和类别。
- 提取的文本行的边界框。
- 预定义的逻辑角色类型。
该模块为每种类型的查询分配了可学习的特征,并根据类别选择相应的特征来初始化内容查询。
2.3 Unified Relation Prediction Head
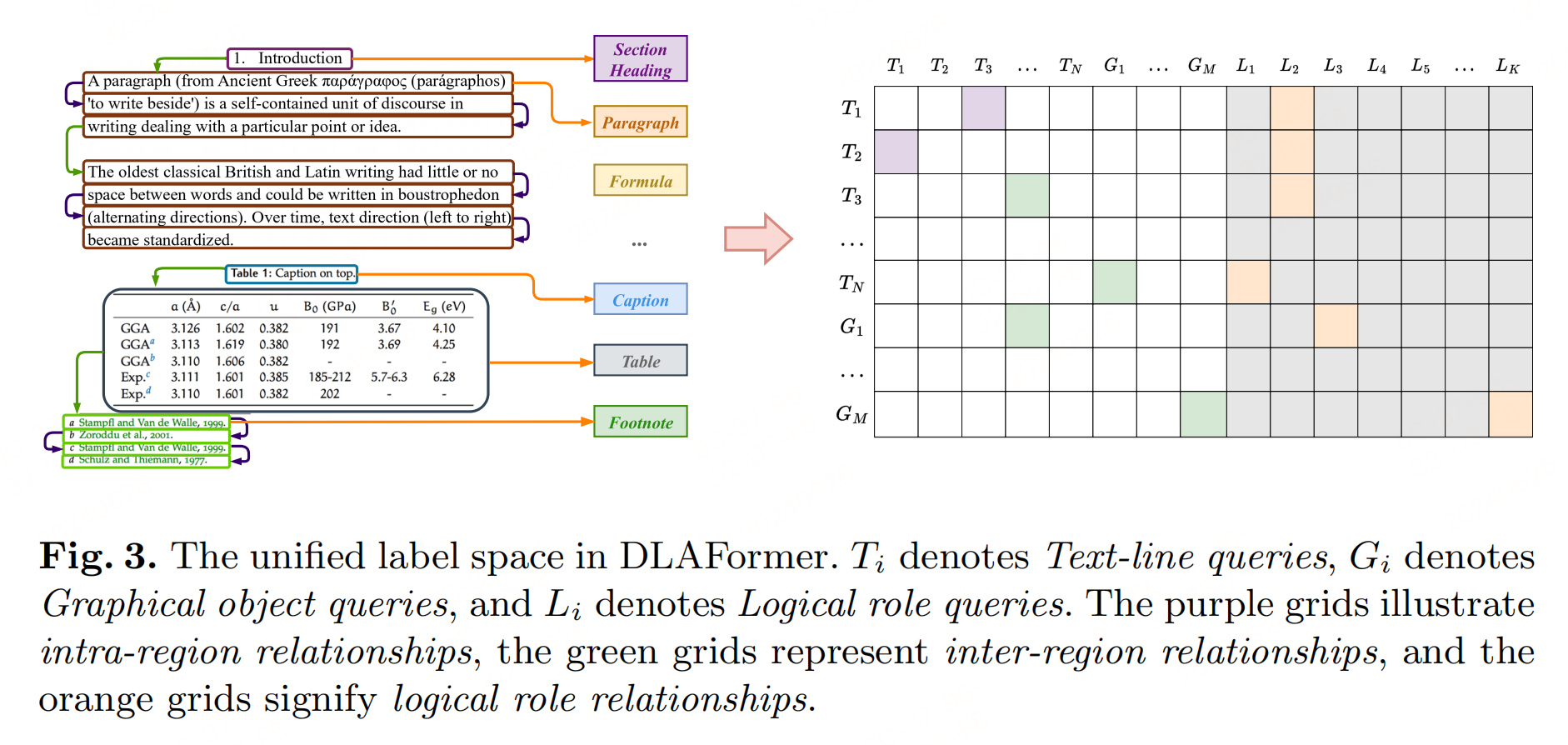
统一关系预测头的主要目标是同时处理多种类型的关系预测任务,包括内部区域关系、区域间关系和逻辑角色关系。这种统一处理方式有助于提高模型的效率和效果。关系预测头包含两个模块:
-
关系预测模块:
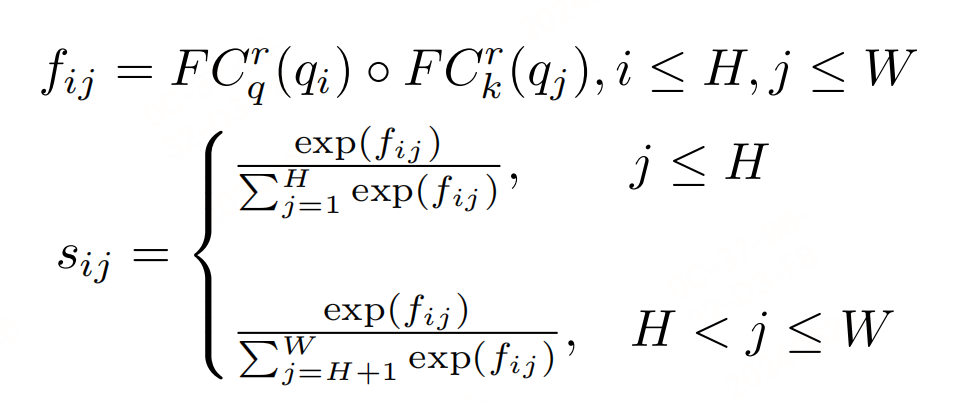
- 文本行查询:文档中的文本行。
- 区块查询:文档中的图形对象,如表格、图表等。
- 逻辑角色查询:文档中的逻辑结构单元,如标题、段落、小节等。
该模块计算文本行/区块查询与逻辑角色查询之间的逻辑关系得分。使用两个全连接层( F C q r FC^{r}_q FCqr 和 F C k r FC^{r}_k FCkr)来映射查询的特征,并通过点积操作计算关系得分。
-
关系分类模块:
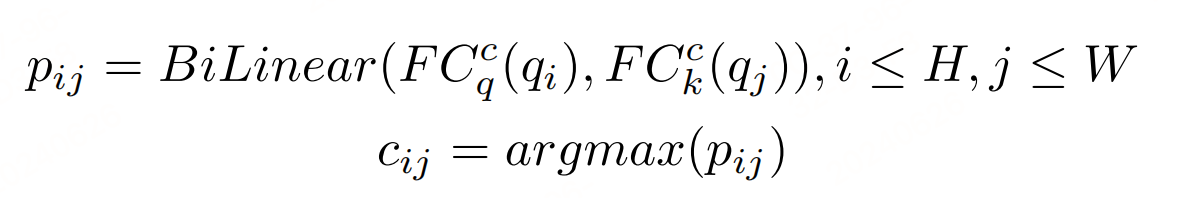
使用BiLinear分类器来计算不同关系类型上的概率分布。
三、实验
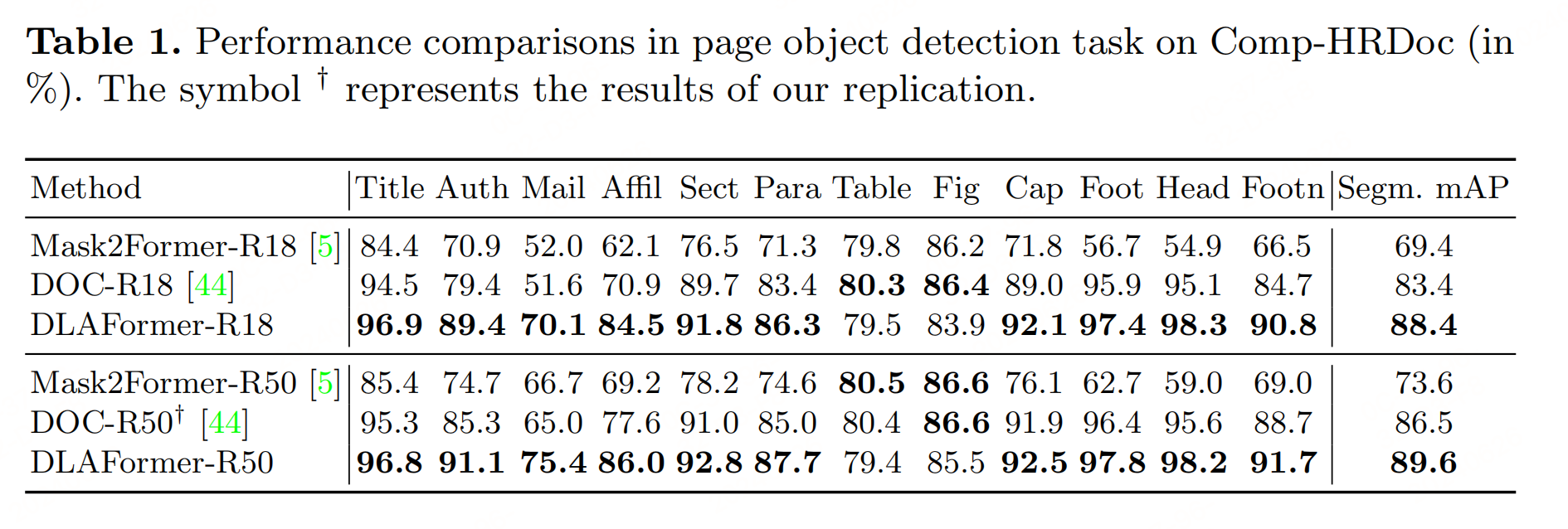
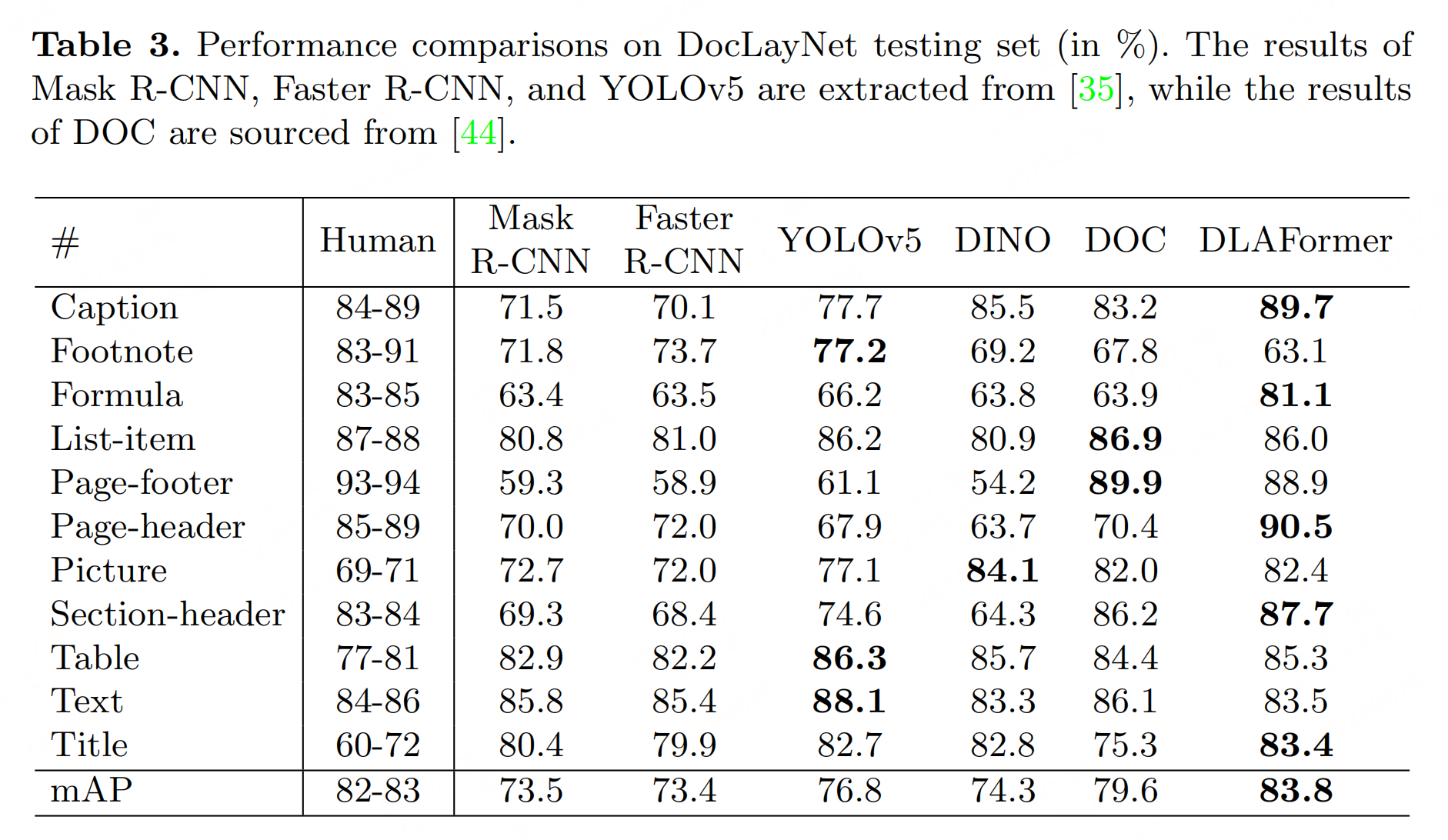
3.1 版式分析
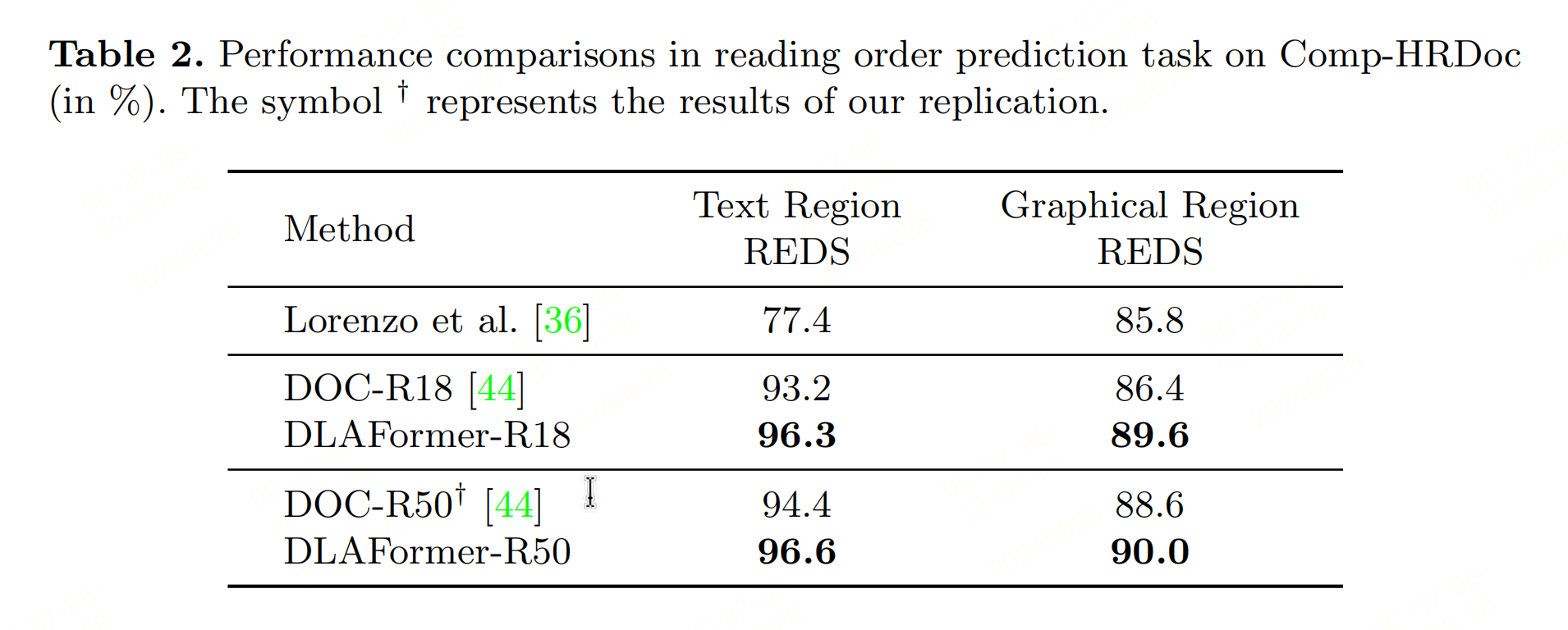
3.2 阅读顺序
总结
DLAFormer的方法挺有趣的,将多个子任务集成到单一模型中,通过统一的关系预测框架来解决文档版式分析和阅读顺序的问题。
参考文献
DLAFormer: An End-to-End Transformer For Document Layout Analysis,https://arxiv.org/abs/2405.11757


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









