









GraphRAG经过一些场景验证KG+LLM的范式能够有效的增强RAG系统性能,对于如何联合文档建立多模态的GraphRAG,笔者之前也有过相关分享,如:《多模态GraphRAG初探:文档智能+知识图谱+大模型结合范式,https://mp.weixin.qq.com/s/coMc5jNPJldPk9X74tDAbA》。
下面我们来看一个用RAG的思路构建文档级别知识图谱构建框架思路,这个思路要解决的问题是如何自动构建文档级别的知识图谱。传统的知识图谱构建方法面临长文本处理中的长距离遗忘问题、复杂实体消歧、跨文档知识整合不足的问题。整体思路可以参考下。
方法
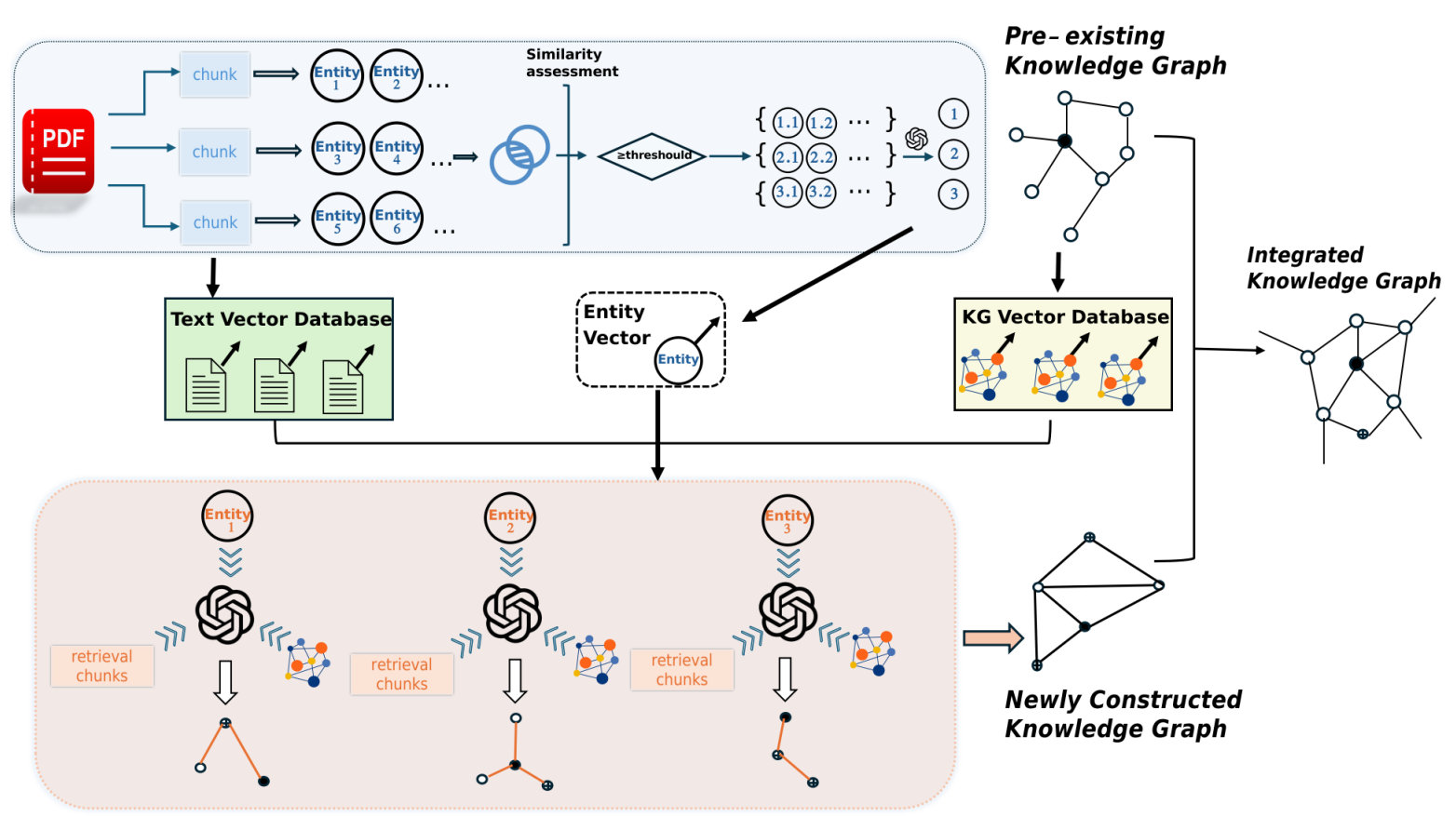
上图的流程:RAKG框架通过句子分割和向量化处理文档,提取初步实体,并执行实体消歧和向量化。处理后的实体经过语料库回顾检索以获取相关文本和图结构检索以获取相关知识图谱。随后,使用LLM整合检索到的信息以构建关系网络,这些网络针对每个实体进行合并。最后,新构建的知识图谱与原始知识图谱相结合。
A. 理想知识图谱的假设
RAKG假设存在一个理论上完美的知识图谱构建过程,该过程可以将文档转换为一个理想的完备知识图谱。这个理想知识图谱可以表示为:
K G ∗ = Construct ( D ) KG^* = \operatorname{Construct}(D) KG∗=Construct(D)
其中, K G ∗ KG^* KG∗ 是从文档 D D D 构建出来的理想知识图谱,包含所有的语义关系。
B. 知识库向量化
RAKG将文档和知识图谱进行向量化处理,便于后续的检索和生成操作。
-
文档分块和向量化: 文档被分割成多个文本块(chunks),通常以句子为单位进行分割。每个文本块被向量化,以便于后续的处理和分析。类似RAG,这种方法能够减少LLM每次处理的信息量,同时确保每个片段的语义完整性,从而提高了命名实体识别的准确性。
-
知识图谱向量化: 初始知识图谱中的每个节点(如实体)通过提取其名称和类型来进行向量化。使用 BGE-M3 模型进行向量化,便于在检索过程中使用。
C. 预实体构建
RAKG通过命名实体识别(NER)来识别文本中的实体,并将这些实体作为预实体进行处理。
-
实体识别和向量化: NER的整个过程由LLM(Qwen2.5-72B)完成。先对每个文本块进行命名实体识别,识别出其中的实体。接着为每个预实体分配类型和属性描述,区分具有相似名称的不同实体。最后将实体的名称和类型组合后进行向量化。
-
实体消歧: 在完成整个文档的实体识别和向量化后,进行相似性检查。对于相似度超过阈值的实体,进行进一步的消歧处理,以确保每个实体只有一个唯一表示。
D. 关系网络构建
RAKG通过RAG的方法来构建关系网络。
-
文档文本块检索: 对于指定的实体,通过文本块的标识符(chunk-id)检索相关的文本块。使用向量检索获取与选定实体相似的文本块。
-
图结构检索: 在初始知识图谱中进行向量检索,获取与选定实体相似的其他实体及其关系网络。
-
关系网络生成和评估: 将检索到的文本和关系网络信息整合,并输入到LLM中,以生成中心实体的属性和关系。使用LLM作为评判者来评估生成的三元组,确保其真实性和准确性。
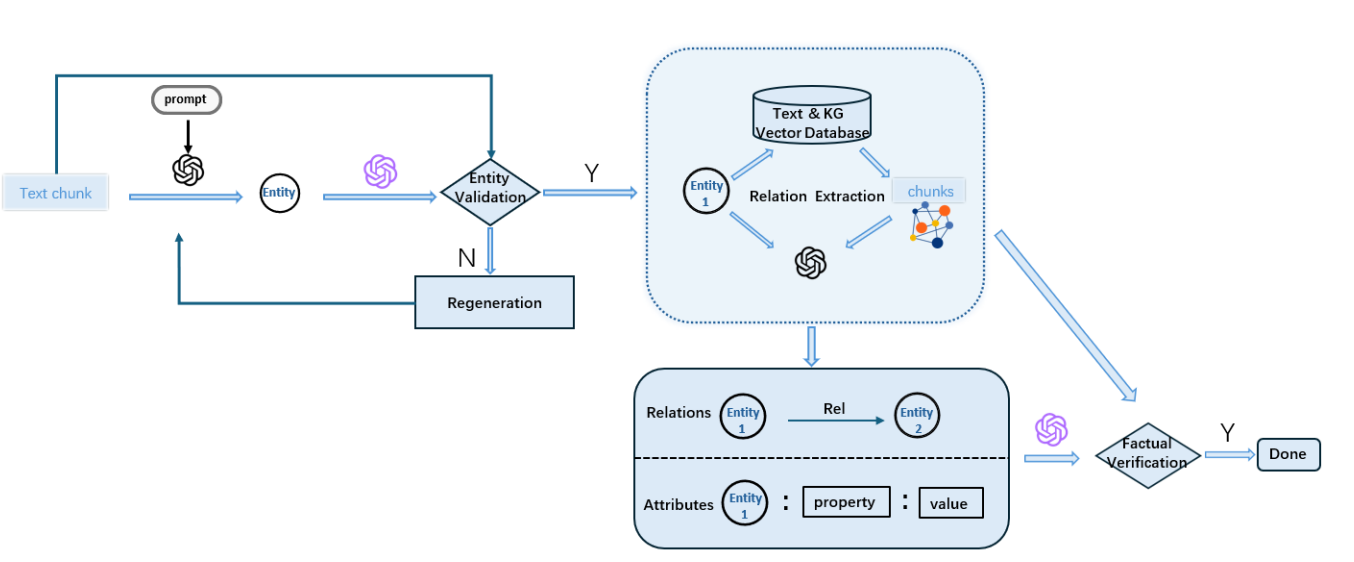
E. 知识图谱融合
RAKG将新构建的知识图谱与初始知识图谱进行融合。自然而然,KG融合有两点核心内容。
-
实体合并: 将新知识图谱中的实体与初始知识图谱中的实体进行消歧和合并,确保实体的一致性。
-
关系整合: 将新知识图谱中的关系与初始知识图谱中的关系进行整合,以获得更全面的知识图谱。
评估指标
评估指标主要是评估KG的,正好复习下KG的常见评估指标。
1. 实体密度(Entity Density, ED)
实体密度是指知识图谱中实体的数量。公式如下:
E D = N e ED = N_e ED=Ne
其中, N e N_e Ne 表示知识图谱中提取的实体数量。实体密度越高,通常意味着从文本中提取的信息越多,知识图谱的覆盖范围越广。
2. 关系丰富度(Relationship Richness, RR)
关系丰富度是指知识图谱中关系的数量相对于实体数量的比率。公式如下:
R R = N r N e RR = \frac{N_r}{N_e} RR=NeNr
其中, N r N_r Nr 表示知识图谱中提取的关系数量。关系丰富度越高,说明知识图谱中实体之间的关系越复杂,能够更好地捕捉实体之间的交互。
3. 实体保真度(Entity Fidelity, EF)
实体保真度用于评估提取的实体的可信度。公式如下:
E F = 1 N e ∑ i = 1 N e LLMJudge entity ( e i , retriever V T ( e i ) ) EF = \frac{1}{N_e} \sum_{i=1}^{N_e} \operatorname{LLMJudge}_{\text{entity}}(e_i, \operatorname{retriever}_{V_T}(e_i)) EF=Ne1i=1∑NeLLMJudgeentity(ei,retrieverVT(ei))
其中, LLMJudge entity \operatorname{LLMJudge}_{\text{entity}} LLMJudgeentity 是一个函数,用于评估每个提取的实体 e i e_i ei 的可信度。它基于LLM对实体的判断,并返回一个介于0和1之间的值,表示实体的可信度。
4. 关系保真度(Relationship Fidelity, RF)
关系保真度用于评估提取的关系的可信度。公式如下:
R F = 1 N r ∑ i = 1 N r LLMJudge rel ( e i , retriever V T ( e i ) , retriever V k g ( e i ) ) RF = \frac{1}{N_r} \sum_{i=1}^{N_r} \operatorname{LLMJudge}_{\text{rel}}(e_i, \operatorname{retriever}_{V_T}(e_i), \operatorname{retriever}_{V_{kg}}(e_i)) RF=Nr1i=1∑NrLLMJudgerel(ei,retrieverVT(ei),retrieverVkg(ei))
其中, LLMJudge rel \operatorname{LLMJudge}_{\text{rel}} LLMJudgerel 是一个函数,用于评估每个提取的关系 r i r_i ri 的可信度。它基于LLM对关系的判断,并返回一个介于0和1之间的值,表示关系的可信度。
5. 准确性(Accuracy)
准确性是指知识图谱在问答任务中的表现。通过构建的知识图谱来回答问题的准确率。较高的准确性意味着知识图谱能够更好地保留文本的语义信息。
6. 实体覆盖率(Entity Coverage, EC)
实体覆盖率衡量的是评估知识图谱中的实体与标准知识图谱中的实体之间的匹配程度。公式如下:
E C = ∣ E ∩ E ∗ ∣ ∣ E ∗ ∣ EC = \frac{|E \cap E^*|}{|E^*|} EC=∣E∗∣∣E∩E∗∣
其中, E E E 是评估知识图谱中的实体集合, E ∗ E^* E∗ 是标准知识图谱中的实体集合。实体覆盖率越高,说明知识图谱在实体层面的完整性越好。
7. 关系网络相似度(Relation Network Similarity, RNS)
关系网络相似度衡量的是评估知识图谱与标准知识图谱在关系层面上的相似度。公式如下:
R N S = ∑ e i ∈ E ∩ E ∗ ( RelSim i × EntityWeight i ) RNS = \sum_{e_i \in E \cap E^*} (\operatorname{RelSim}_i \times \operatorname{EntityWeight}_i) RNS=ei∈E∩E∗∑(RelSimi×EntityWeighti)
其中, RelSim i \operatorname{RelSim}_i RelSimi 表示评估知识图谱和标准知识图谱中相同实体的关系网络的相似度, EntityWeight i \operatorname{EntityWeight}_i EntityWeighti 是对应实体的权重。关系网络相似度越高,说明知识图谱在关系层面的准确性越好。
这些指标用于全面评估知识图谱的质量,确保其在实体提取、关系构建和整体准确性方面的表现。
实验效果
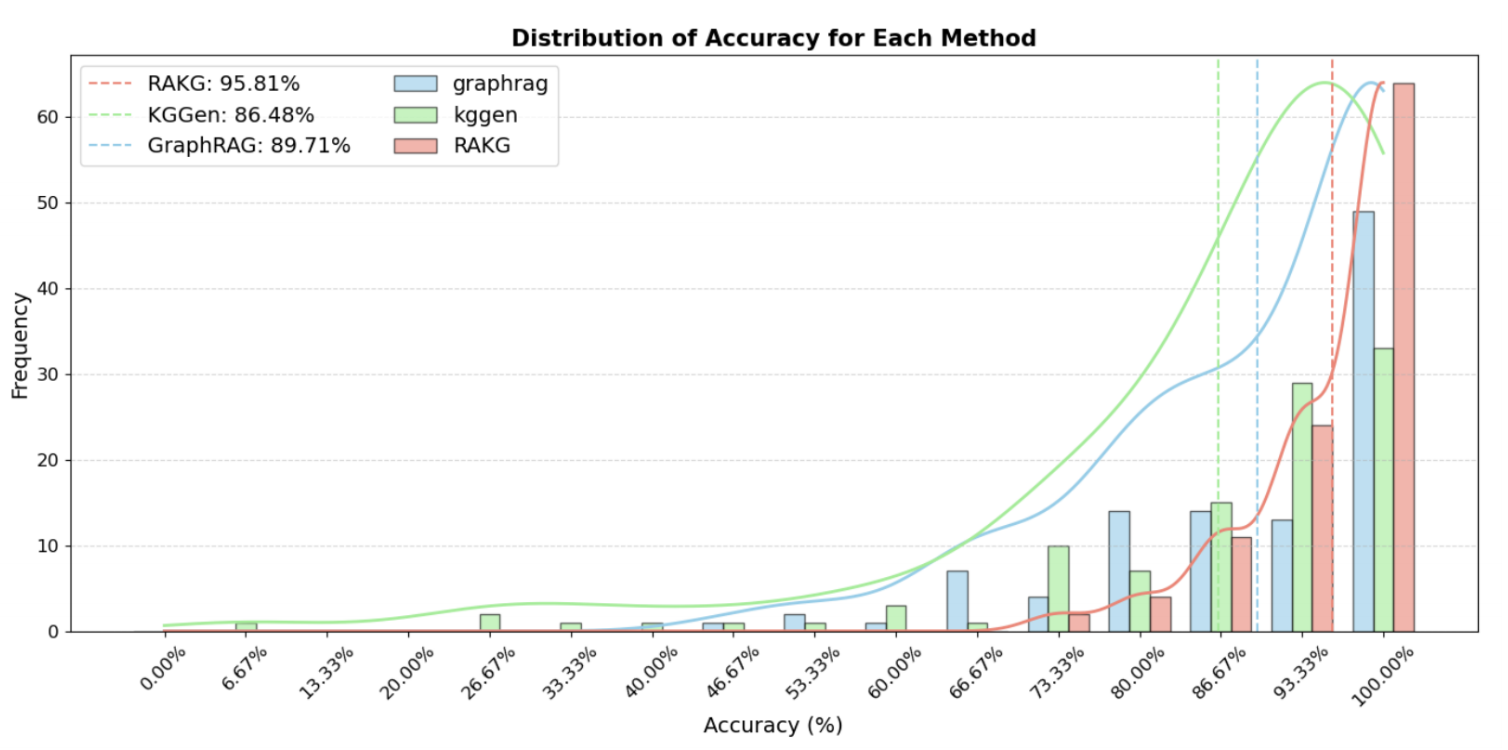
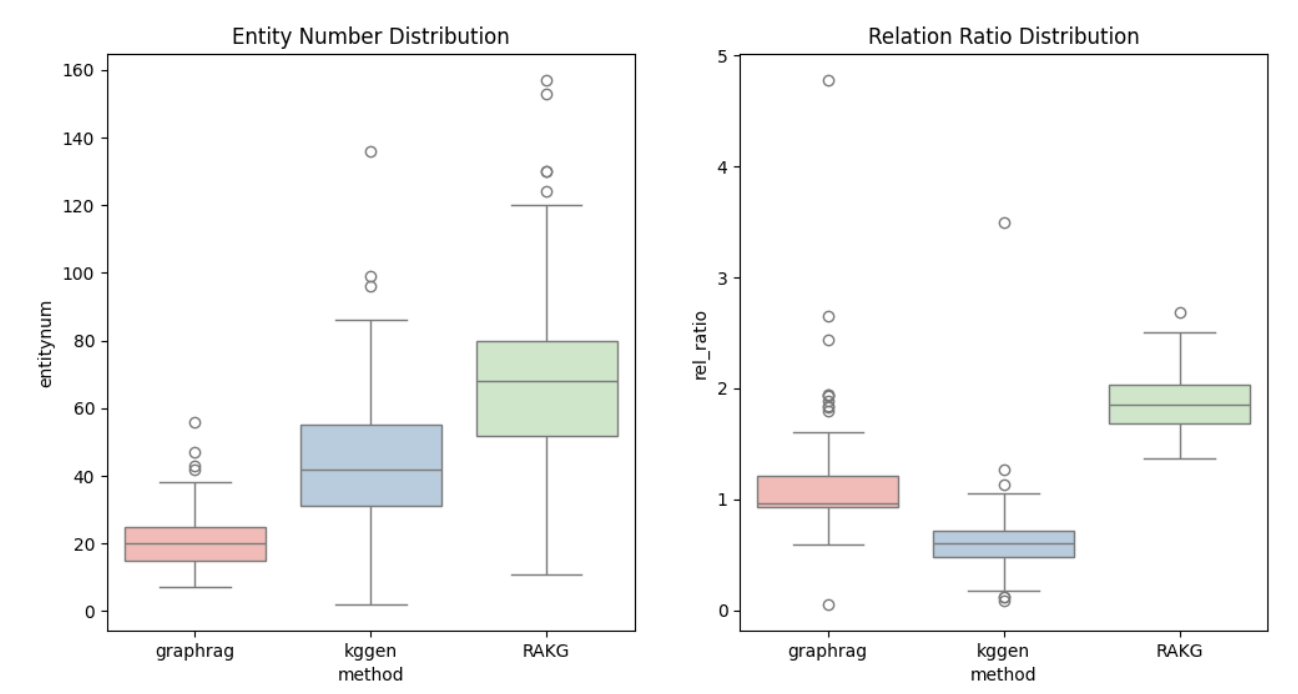
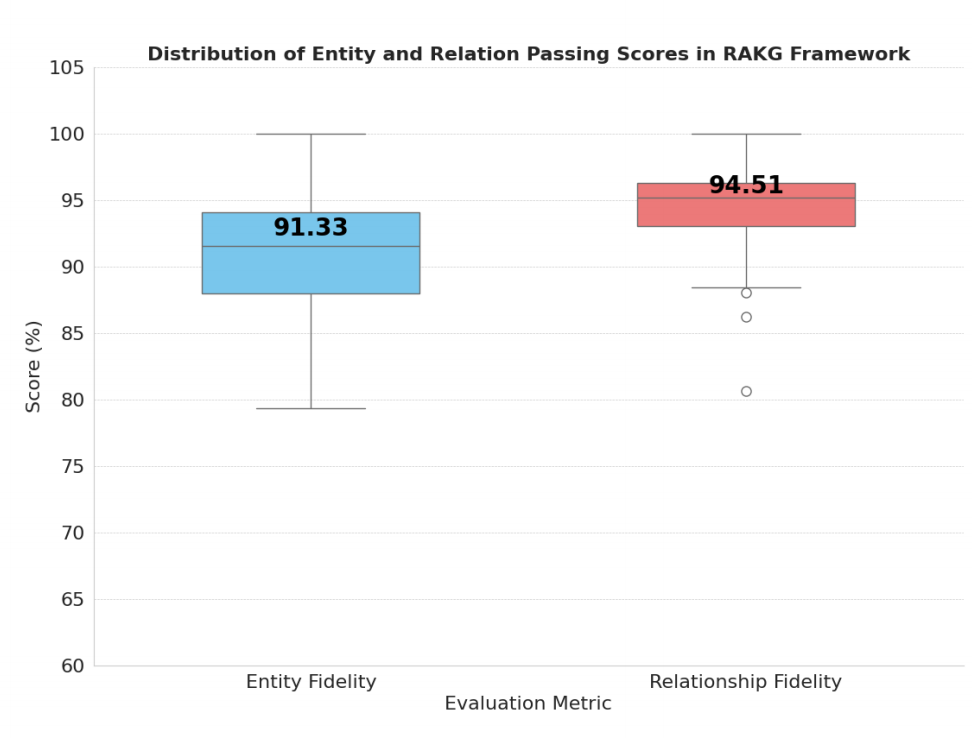
参考文献:RAKG:Document-level Retrieval Augmented Knowledge Graph
Construction,https://arxiv.org/pdf/2504.09823

















 3426
3426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









