









往期,笔者基于LLava的数据对齐训练,搞了一个Reyes多模态大模型,并且看了些多模态大模型,相关开源的多模态大模型如:KimiVL、Internvl、QwenVL等,其视觉编码器的尺寸都比较大,如:MoonViT-SO-400M、InternViT-6B-448px-V2_5 等都非常大,对于特定的垂直场景(或者是端侧落地都不大友好),也许并不需要这么大视觉编码器。如:表格场景(【多模态 & 文档智能】一次多模态大模型表格识别解析探索小实践记录),当时笔者用了一个8B参数的模型及百万表格数据进行训练达到了不错的效果。近期,因此思考一些模型轻量化的方案,寻找一个轻量点的视觉编码器(比如参数量小于100M),下面来看看SAM,供参考。
Segment Anything Model(SAM)是Meta AI发布的一个突破性图像分割模型为计算机视觉领域提供一个通用的、灵活的基座视觉大模型。它受到自然语言处理(NLP)中基础模型(如GPT、BERT)的启发,强调零样本迁移和提示式交互能力。在SA-1B数据集上的训练,该数据集包含超过11百万张图像和11亿个高质量分割掩码,覆盖了从日常场景到专业领域的多样化内容。
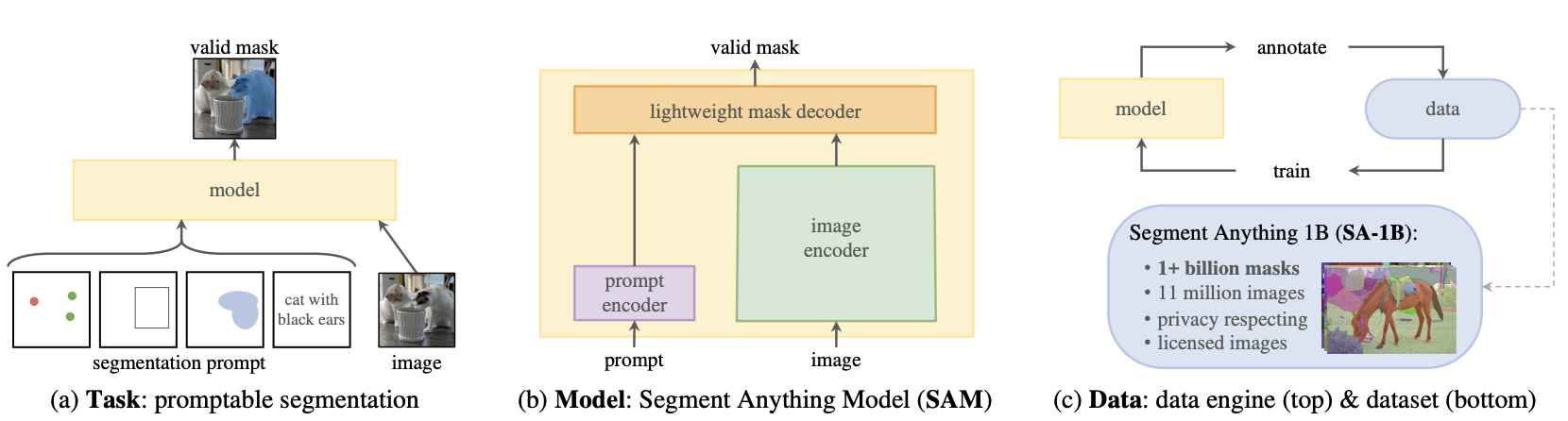
模型结构
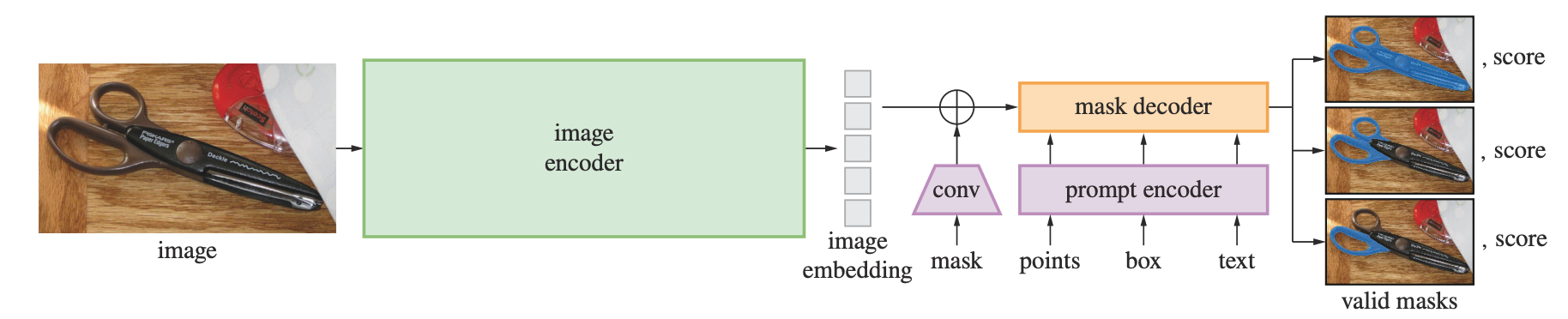
SAM的模型结构由三个核心组件组成,Image Encoder、Prompt Encoder和Mask Decoder。分别负责图像特征提取、提示编码和掩码生成。图像经过Image Encoder编码,Prompt提示经过Prompt Encoder编码,两部分Embedding再经过一个轻量化的Mask Decoder得到融合后的特征。其中,Encoder部分使用的是已有模型,Decoder部分使用Transformer。
下表为三个组件的总结:
| 组件名称 | 功能 | 关键特点 |
|---|---|---|
| Image Encoder | 将输入图像转换为密集特征表示 | 使用MAE预训练的Vision Transformer(ViT-H/16),输入1024x1024x3,输出64x64x256嵌入。 |
| Prompt Encoder | 将用户提示(点、框、文本、掩码)编码为嵌入 | 支持稀疏提示(点、框、文本)和密集提示(掩码),使用CLIP处理文本,灵活适应多种输入。 |
| Mask Decoder | 结合图像和提示嵌入,生成最终分割掩码 | 轻量级Transformer解码器,通过自注意力与交叉注意力机制预测掩码,实时高效。 |
Image Encoder
本文的目的是为了寻找一个轻量化的视觉编码器,因此下面来详细看下视觉编码器部分。Image Encoder的作用是把图像映射到特征空间,整体过程如下图所示。
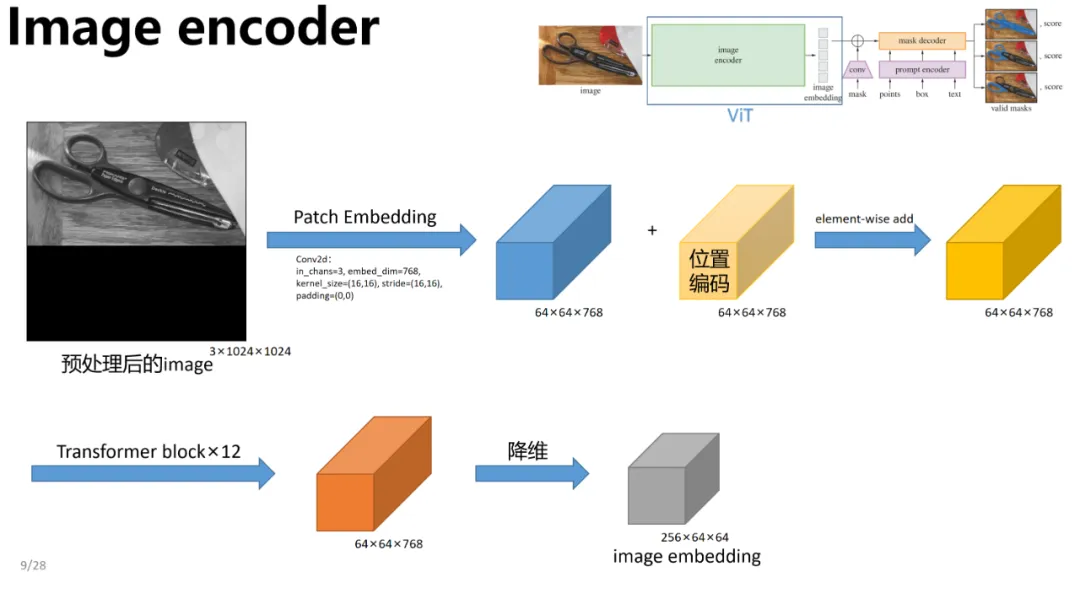
正如论文中所讲,本质上这个Encoder可以是任何网络结构,在这里使用的是微调的Detectron的ViT,当然它也可以被改成传统的卷积结构,非常合理。
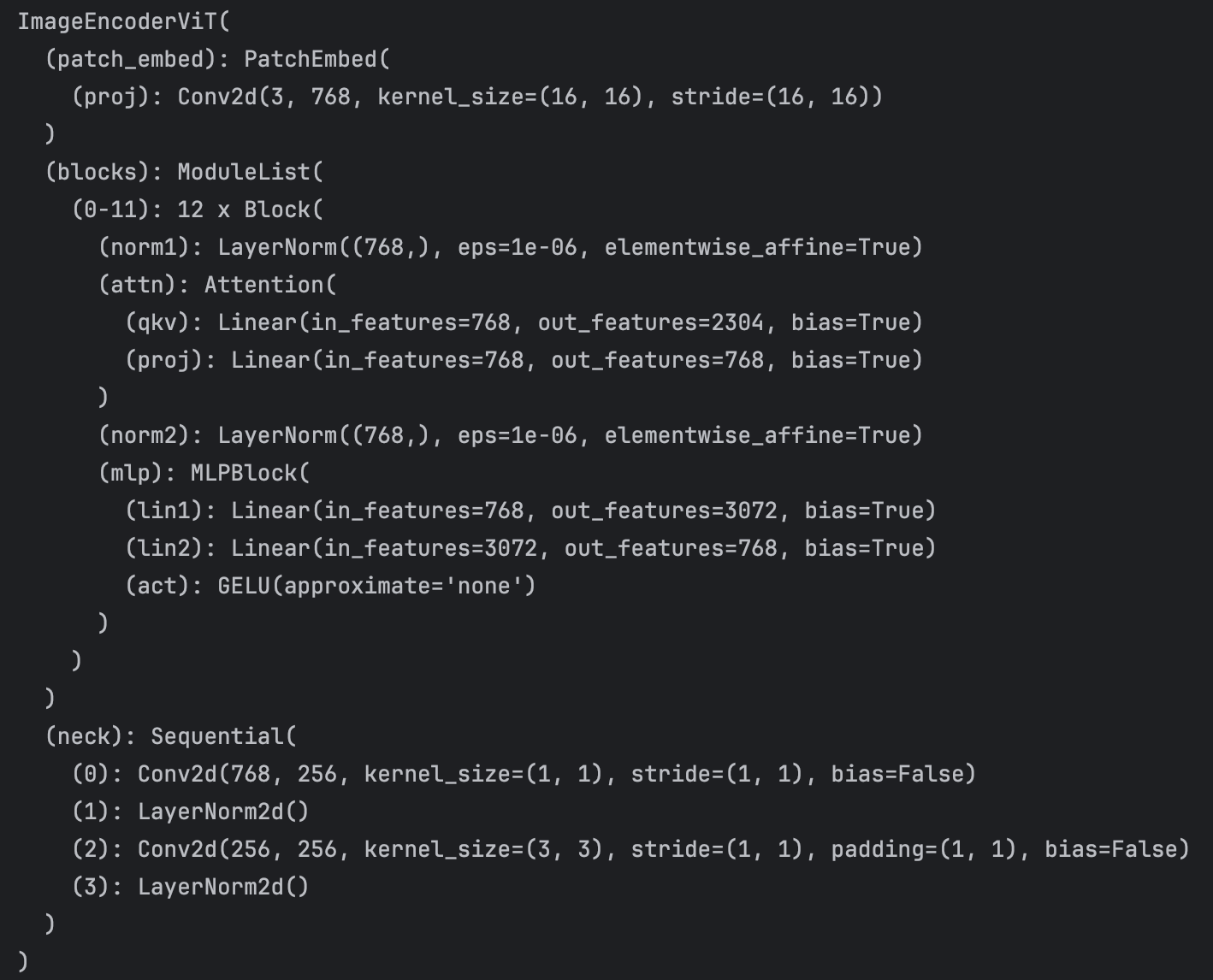
可以看到,Image Encoder就是一个ViT的结构,由PatchEmbed、Transformer Encoder、Neck Convolution组成。
输入图像经过ViT结构的过程如下:
-
Patch Embedding
输入图像通过一个卷积base,将图像划分为16x16的patches,步长也为16,这样feature map的尺寸就缩小了16倍,同时channel从3映射到768。Patch Embedding示意图如下所示。
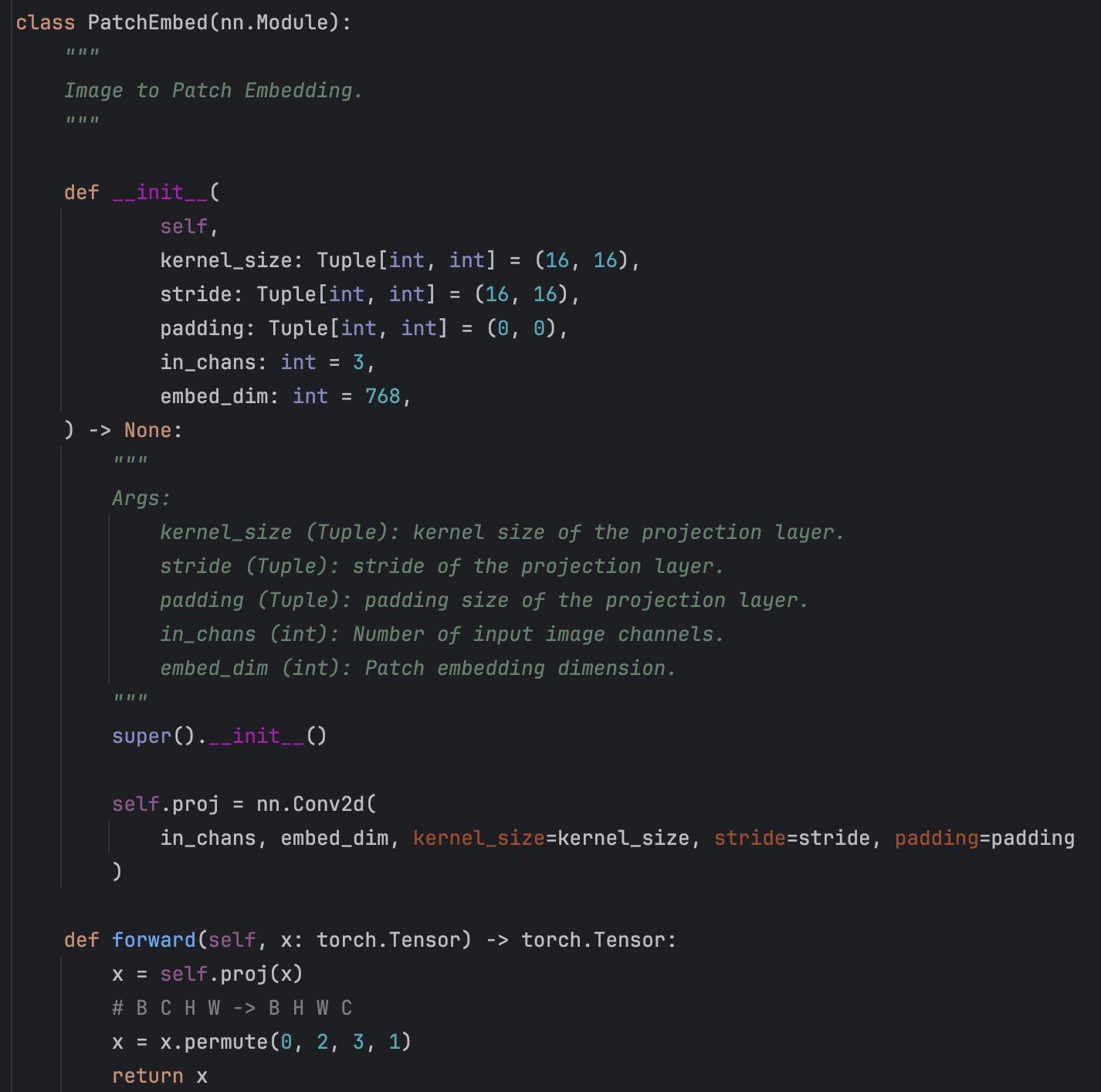
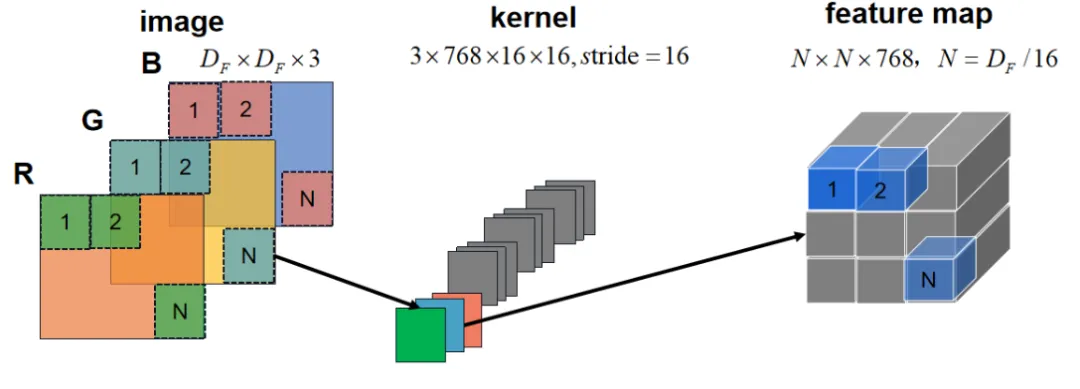
Patch Embedding过程在Vision Transformer结构图中对应下图所示。
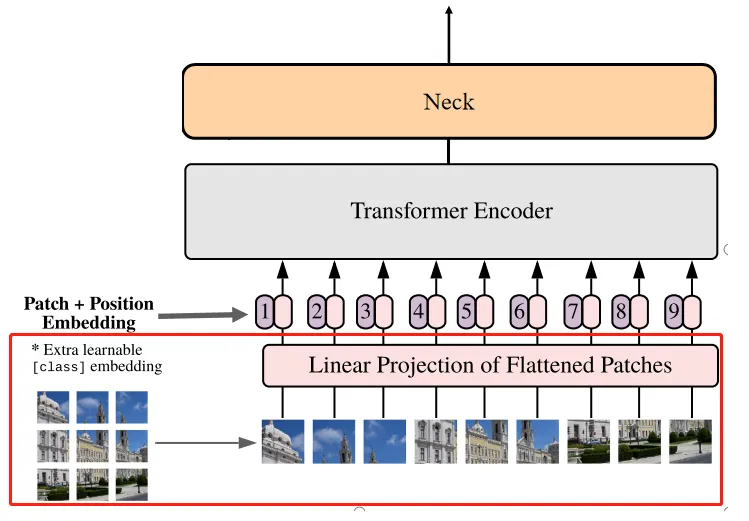
-
Transformer Encode
feature map通过16个Transformer Block,其中12个Block使用了基于Window Partition(就是把特征图分成14*14的windows做局部的Attention)的注意力机制,以处理局部信息。另外4个Block是全局注意力模块(多头注意力),它们穿插在Window Partition模块之间,以捕捉图像的全局上下文。
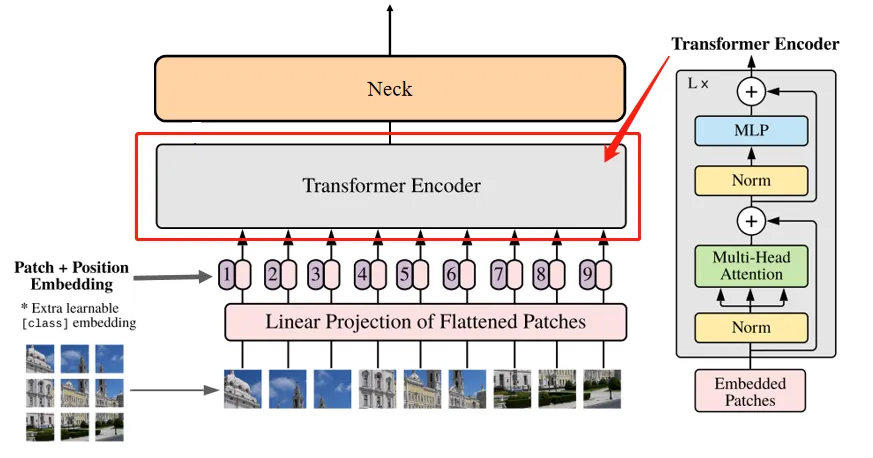
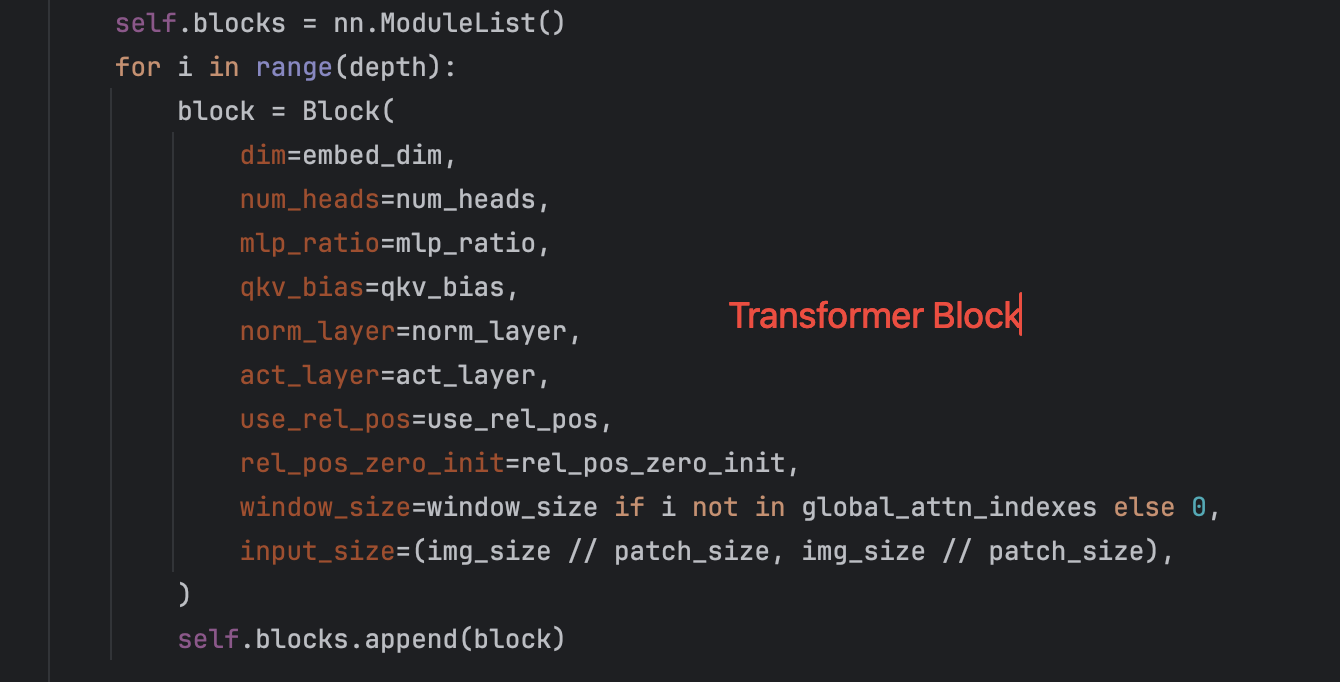
-
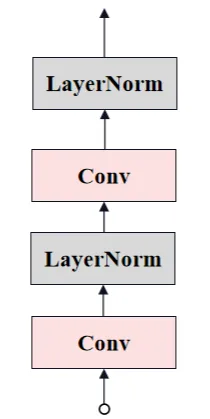
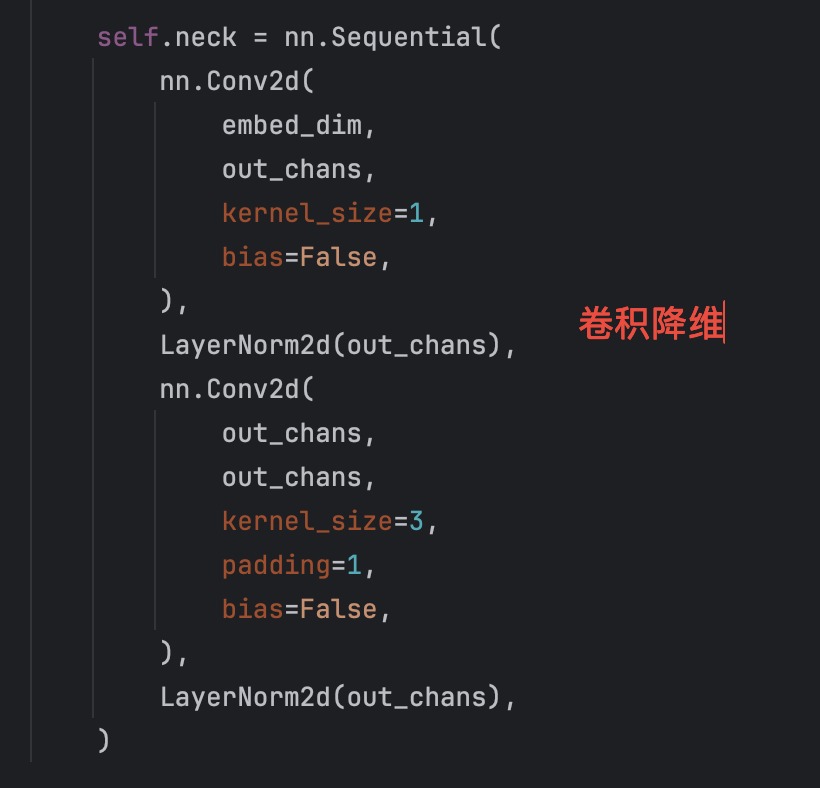
Neck Convolution
最后,通过两层卷积(Neck)将通道数降低至256,生成最终的Image Embedding。其结构图如下所示。
SAM构建与轻量化编码器提取
通过下面代码提取一个参数量大小仅为80几M的视觉编码器。
import torch
from functools import partial
from modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
def build_sam_vit_b(checkpoint=None):
return _build_sam(
encoder_embed_dim=768,
encoder_depth=12,
encoder_num_heads=12,
encoder_global_attn_indexes=[2, 5, 8, 11],
checkpoint=checkpoint,
)
sam_model_registry = {
"vit_b": build_sam_vit_b,
}
def _build_sam(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
checkpoint=None,
):
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
sam = Sam(
image_encoder=ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
),
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoder(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
sam.eval()
if checkpoint is not None:
with open(checkpoint, "rb") as f:
state_dict = torch.load(f)
sam.load_state_dict(state_dict)
return sam
if __name__ == '__main__':
x = torch.zeros(2, 3, 1024, 1024)
net = build_sam_vit_b(checkpoint='sam_vit_b_01ec64.pth')
image_encoder = net.image_encoder
print(image_encoder)
print(image_encoder(x).shape) # 输出:torch.Size([2, 256, 64, 64])
total_params = sum(p.numel() for p in image_encoder.parameters())
print(f"模型的参数量为: {(total_params/ 1e6):.2f}M") # 模型的参数量为: 89.67M
torch.save(image_encoder, 'sam.pth')
参考文献:
Segment Anything,https://arxiv.org/pdf/2304.02643
code:https://github.com/facebookresearch/segment-anything

















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









