






ResNet的基本构建模块是残差块,每个残差块通常由多个卷积层、批归一化(batch normalization)和激活函数(如ReLU)组成。在残差块中,输入信号会通过“跳跃连接”(skip connection)与卷积层的输出相加,形成一个残差。这种设计允许信息更流畅地在深层网络中传递,从而可以训练出数百甚至上千层的模型。
1.残差块结构
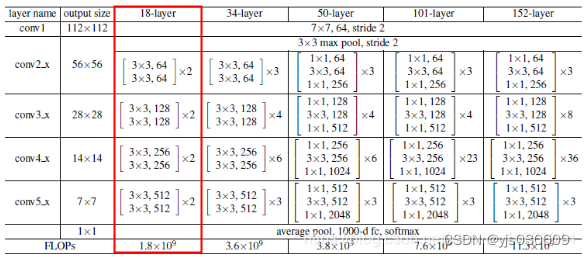
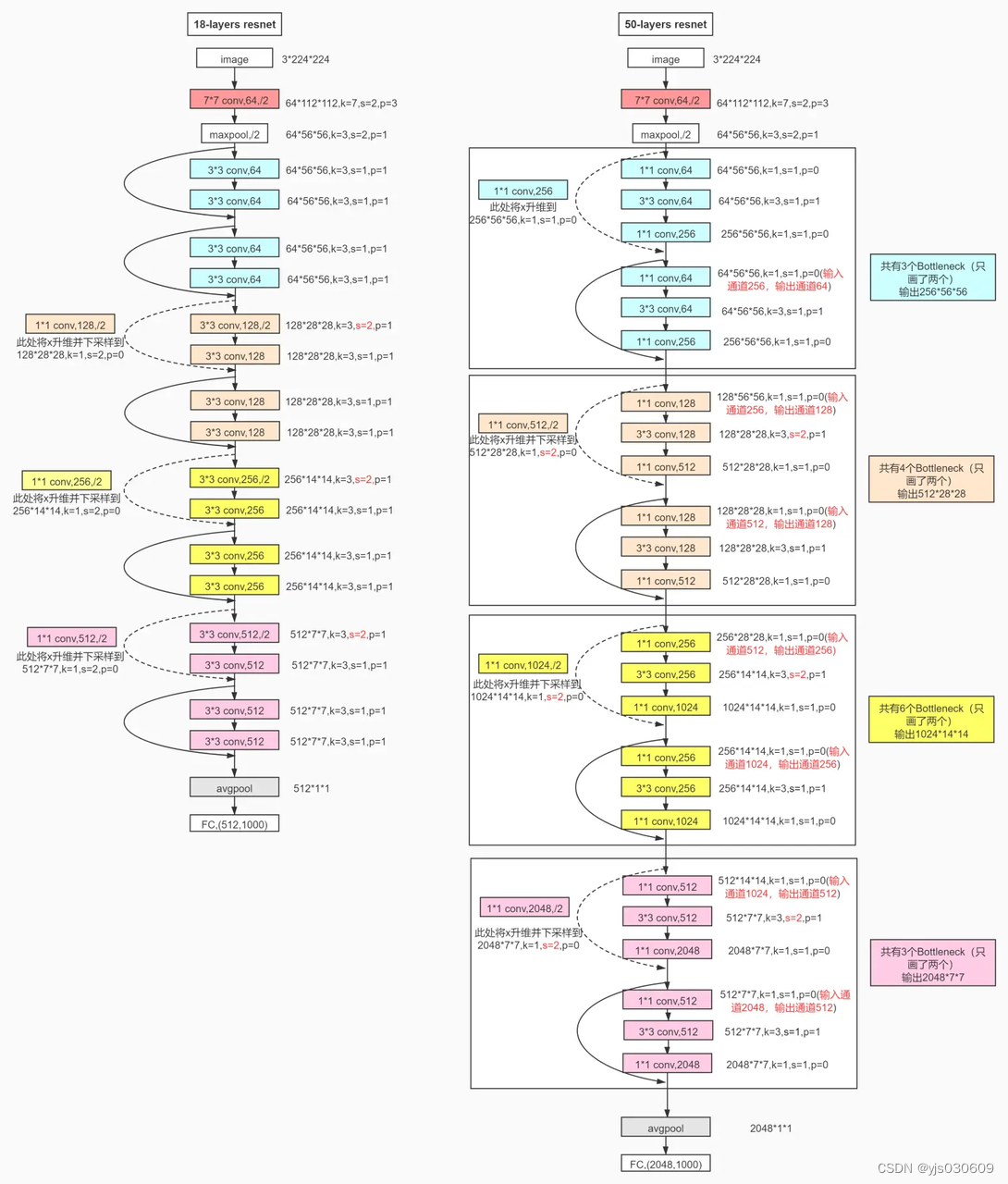
ResNet中存在两种主要的残差块结构:BasicBlock和BottleneckBlock。BasicBlock主要用于较浅的ResNet网络(如ResNet18和ResNet34),而BottleneckBlock则用于更深的ResNet网络(如ResNet50、ResNet101等)。
2.平均池化、最大池化、自适应平均池化的区别
平均池化、最大池化和自适应平均池化在卷积神经网络中扮演着不同的角色,各自具有独特的特点和用途。以下是这三种池化方法的详细区别:
-
平均池化(Average Pooling):
-
操作:平均池化是将输入的图像或特征图划分为若干个矩形区域(或称为池化窗口),然后对每个子区域计算所有值的平均值,作为该区域的输出。
-
作用:平均池化有助于保留图像的背景信息,突出背景特征。通过减小邻域大小受限造成的估计值方差增大,能够更多地保留图像的背景细节。
-
特点:平均池化可以抑制噪声,降低信息冗余,并提升模型的尺度不变性和旋转不变性。在回传梯度时,由于每个块(如2x2)的平均值作为下一层的一个元素值,因此在回传时,下一层的每一元素的loss(或者说梯度)要除以块的大小(如2x2 = 4),再分配到块的每个元素上。
-
-
最大池化(Max Pooling):
-
操作:最大池化是将输入的图像或特征图划分为若干个矩形区域,然后对每个子区域输出最大值,即取局部接受域中值最大的点。
-
作用:最大池化有助于保留主要特征,突出前景,并提取特征的纹理信息。通过减小卷积层参数误差造成估计均值的偏移,能够更多地保留图像的纹理细节。
-
特点:最大池化同样可以降低模型的计算量,并防止过拟合。在回传梯度时,由于最大池化是取每个块的最大值作为下一层的一个元素值,因此下一个元素的Loss只来源于这个最大值,因此梯度更新也只更新这个最大值,其他值梯度为0。
-
-
自适应平均池化(Adaptive Average Pooling):
-
操作:自适应平均池化是一种特殊类型的平均池化,它可以根据指定的输出大小自适应地调整池化窗口的大小。通过空间中的一元函数,将卷积核和空间中的特征映射到一个特定的坐标系中,然后计算该坐标系中的特征向量的平均值。
-
作用:自适应平均池化能够在高维空间中生成平均池,有效地降低特征图的维度,同时保留重要信息。
-
特点:自适应平均池化具有更高的灵活性和适应性,可以根据网络的需求动态调整池化窗口的大小。它主要应用于需要固定输出大小或需要降低特征图维度的场景。
-
总结:
-
平均池化和最大池化都是卷积神经网络中常见的池化方法,它们通过不同的方式处理输入图像或特征图,以减小特征图的尺寸,降低模型的计算量,并防止过拟合。平均池化更注重保留背景信息,而最大池化更注重保留前景和纹理信息。
-
自适应平均池化是一种特殊的平均池化方法,它可以根据指定的输出大小自适应地调整池化窗口的大小,具有更高的灵活性和适应性。它通常用于需要固定输出大小或降低特征图维度的场景。
3.self卷积与forward传播
resnet模型中只用一次用self卷积但是在forward中多次调用有什么问题
在ResNet模型中,虽然每个残差块(Residual Block)内部可能包含一个或多个自卷积层(通常称为卷积层),但如果我们在forward方法中多次调用同一个自卷积层(即同一个卷积层的实例),而不是多次使用不同的卷积层或残差块,那么可能会遇到以下问题:
-
功能重复:如果多次调用同一个自卷积层,并且每次调用时输入数据保持不变,那么输出也将是相同的。这会导致网络的功能重复,并且没有增加新的特征表示能力。
-
参数更新问题:在训练过程中,反向传播算法会根据损失函数的梯度来更新网络的参数。如果多次调用同一个卷积层,并且该层的参数在每次调用后都进行更新,那么这种更新可能会相互干扰,导致训练不稳定或性能下降。
-
计算效率:虽然从表面上看,多次调用同一个卷积层可能节省了参数数量,但实际上这并不会提高计算效率。因为每次调用都需要执行相同的计算操作,并且由于参数更新的原因,可能还需要额外的内存来存储中间结果。
-
设计不合理:在ResNet中,残差块的设计是为了增加网络的深度,同时避免梯度消失和模型退化问题。如果只在
forward方法中多次调用同一个卷积层,而不是使用多个残差块,那么就无法充分利用残差连接的优势,也无法有效地增加网络的深度。 -
不符合ResNet的设计原则:ResNet的设计原则是通过多个残差块来堆叠网络,每个残差块都包含多个卷积层。这种设计能够确保网络在增加深度的同时,仍然能够保持较好的性能。如果只使用一个自卷积层并在
forward方法中多次调用,那么就无法实现这种设计原则。
因此,在ResNet模型中,我们应该在forward方法中多次使用不同的残差块,而不是多次调用同一个自卷积层。每个残差块内部可以包含一个或多个卷积层,并且可以通过残差连接来确保梯度能够有效地传播到前面的层。这样可以充分利用ResNet的设计优势,并提高网络的性能。
-
步长决定了卷积核在输入特征图上滑动的步幅,从而影响输出特征图的大小和感受野。步长为1时通常用于保持特征图的空间尺寸,而步长为2时则常用于下采样。
-
Padding决定了在输入特征图边界进行的填充操作,可以影响输出特征图的大小和边缘信息的保留。Padding为0时不会进行填充,可能会导致边缘信息丢失;而Padding为1时则可以在一定程度上保留边缘信息。
您提供的forward方法中,Y确实被多次赋值,但每次赋值都是基于之前计算的结果,并且这种赋值在神经网络的前向传播中是常见的。每次Y被新的计算结果覆盖时,它都表示当前网络层或块的输出,这不会引发错误或bug。
关于反向传播(Backpropagation),它是基于链式法则来计算损失函数对模型参数的梯度的。在PyTorch等深度学习框架中,反向传播是自动进行的,框架会跟踪所有计算操作并构建计算图(Computational Graph)。这个计算图会记录每个操作和其输入/输出,以便在反向传播时计算梯度。
当您调用.backward()方法来开始反向传播时,框架会遍历计算图,从损失函数开始,对每个操作应用链式法则,计算梯度,并将这些梯度累积到相应的参数上。即使在前向传播过程中Y被多次覆盖,计算图仍然会保留每个操作对最终损失的贡献,并且每个操作都会根据其输入和输出来计算梯度。
因此,尽管Y在前向传播中被多次覆盖,但反向传播仍然可以正确进行,因为框架维护了完整的计算图,并且能够计算每个参数相对于最终损失的梯度。

















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









