






AlexNet:
1, 第一部分:摘要
第一段:要做object recognition就是物体的识别或者就图片分类
为了提升性能,收集更大数据及训练.更厉害的模型使用更好的
技术来避免过拟合.
第二部分: 讲数据,有Caltech-101 一样最后过渡到imageNet这个数据集.
为了去识别上千种不一样的类别,在百万的图片里面,我们需要一个很大的
模型,就是一个Large learing capacity,主要用CNN来做网络,然后怎么样
把CNN做的特别大. 大家应该用CNN做神经网络,因为CNN这个是一个很好的模型.
第三部分: CNN虽然很好,但是很难训练.,但是好处是说现在有了GPU,
GPU能够算力能跟上,使得能够训练很大的东西.而且图片数据集够大
确实能够训练比较大的CNN,
AlexNet图结构:
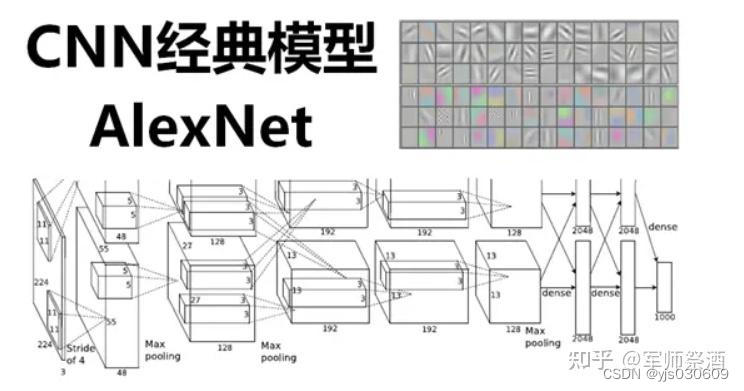
1,框框是表示每一层的输入和输出这个数据的一个大小进来的时候是一张图片,是一个2高宽分别是24*24的图片,它的宽度rgb的那个通道数是3,它有3个图片,
就RGB,它的高宽是24,这个东西进来,然后第一层卷积,卷积他的一个窗口是11*11,
他是11*11然后进来第一层卷积有48个输出的通道,这里有一点不一,
但是有stride等于4,但卷积的stride的就是每次往前后往往左后往下跳4下,
这里比较有意思是说他有两个GPU就Alex小哥有两个GPU所以,他为了把这个东西塞进去,
他把整个网络给你切开,横的切了一刀,这个东西是放在就是说这个地方我画一下,
这个地方有个卷积的一个层在这个地方,这个地方也有个卷积层,这个东西放在gpu0上的,这个东西呢,
是放在GPU1上的,所以GPU1和GPU0都有自己的卷积的那个核的参数他们拿到同一张图片,各做各
的东西,GPU做出来的东西,写来这个地方,GPU1做东西写在这个地方,所以这个这一块是在GPU1上,
这一块是在GPU0上,这是他输出的结果,那GPU1的东西,然后继续往下,第二个卷积层就是说这个是
第一个卷积层,我们来这是第一个卷积层,第二个,第三个,第四个,第五个,这个是表示12345的卷积层
的输出,卷积层是在前面中间那个绿色的蓝色的框框里面,可以看到的说第一个卷积层在GPU,
两个GPU上各有一个,然后第二个卷积层,他是在每个GPU把当前的那个卷积层结果拿出来,就是说gpu0的卷积层,第二个卷积层读的是GPU0的第一个卷积上输出,直接进来OK,中间是没有任何通讯的,然后这有个奇怪的设定,到第三个的时候,GPU还是每个GPU上有自己的卷积核,但是呢,他每个人会去看别人,他会把第二个卷积层的输出在GPU0上GPU1的都拿到(在输出通道维度合并)然后再
看一眼,对这个也是一样,他会都拿的都看一看,所以在这个地方,他两个GPU之间会通讯一次,然后继续往下做,到第四也是各把各的就中间是没有任何通讯的.第五个也是各搞各的,只是说每个都不一样,就是你能看到是通道数的有增加,通道数从48变道128变到192变道192,高宽是有在变化的,就是说你看到它的这个地方本来是224*224现在你的变成了高宽变成了55*55然后变成27*27 13*13,就基本上你看就是说你的输入来是一个很瘪很宽的一个图片,然后把它高宽慢慢的变小,但是深度的慢慢的增加,你随着你的网络增加,我慢慢的把空间信息压缩,24*24高宽,我慢慢的压缩我的空间信息,压到最后是13*13,就是你认为这个里面的每一个像素能够代表前面一大块的像素,然后呢,我再把我的通道数慢慢的增加,就是说,你可认为每个通道数是去看一种特定的一些模式,就192个你可以简单认为是说,我能够识别图片中间的192种不同的模式.就每一个通道去识别一个是猫腿呀,还是一个边,
还是一个什么东西,所以就是说他在慢慢的压缩你的信息把空间信息压缩,但是这个是语义的一个空间慢慢的增加,到最后卷积完之后,进入全连接层,全连接层你看到这个地方又来了一个,在机器之间的就两个卡之间的通讯,全连接层的输入是每个GPU第五个卷积的输出合并起来,合并成一个大的做成全连接,全连接虽然还是各搞各的,就每个人做一个2048的全连接,但是最后的结果是要拼回成一个4096的,就是说,实际上来说一个24*24*3的图片,最后再进入你最后的分类层在这个地方的时候它是表示成了一个4096长的一个向量,包括了说每一块是来自两块卡,一片是2048,一片是2048最后拼起来,所以说说一张图片会表示成一个4096的这个维度,然后最后用一个线性分类去做链接,这是他整个架构的事情,所以是个奠基的事情,这个长为4096的向量其实是很好的,能够抓住你的语义信息,如果你两个图片
它的4096的向量特别相近的话,这两个图片很有可能是同一个物体的图片,所以在深度学习
一个主要是用途是说一张图片来通过前面这些东西最后把它压缩成一个长为4096的一个向量,这个向量能够把中间的语义信息都能表示起来,就说他变成一个机器能够懂的东西,这是一个人能看懂的像素,通过这一块做特征提取之后变成了一个长为一个4096的机器能看到的东西,这个东西第一可以用它来做各种搜索也好,做分类也好,做很多事情都可以所以整个机器学习,你都可以认为是一个压缩,一个知
识的压缩的过程,你前面的原始的数据,不管是图片,文字还是语音,还是视频,它通过中间一个模型,最后压缩成一个向量,这个向量机器能够去识别,然后机器的识别之后,他就能够在上面做各种各样的事情,这才是整个深度神经网络的一个精髓之所在,
lenet5: (具有一个输入层,两个卷积层,两个池化层,
3个全连接层(其中最后一个全连接层为输出层)) 共有7层
卷积-池化,--卷积--池化,--全连接
输入32*32图像想对他进行分类,输入10个类别,输出的10个神经元的概率
如果输入5个类别最大的,也可以是最大的,
层数1,层名称 conv 输入大小32*32 输出28*28
手写数学识别用到的,
输入32*32图像放到一个5*5卷积层,输出通道是6个通道数,28*28,
feturemape输出, pooling层是2*2层28*28变成14*14 后面又是一个卷积层
5*5层 又是一个卷积层,10*10 变成16*16 又一个polling层,5*5
拉成一个向量,一个全连接,120层,84层10层的输出,做softmax的概率
两个卷积层,两个池化层,两个polling层得到我们的lenet5
先用卷积层来学习图像空间信息,,通过池化层降低图片敏感度,全连接类别空间变成
转换类别的空间得到实类.
120个神经元,84层的神经元,10层神经元,每个类别对应的概率,
MaxPool 最大池化, 不重叠的池化,所以步长是2
需要16组卷积核组,
relu激活,将上一步卷积, 进行激活
最大池化,得到5*5特征图,16个5*5 ,全连接,16*5*5 ,120到84的全连接,
84到10的全连接,
LeNet5 一共由7 层组成,分别是C1、C3、C5 卷积层,S2、S4 降采样层(降采样层又称池化层),F6 为一个全连接层,输出是一个高斯连接层,该层使用softmax 函数对输出图像进行分类。为了对应模型输入结构,将MNIST 中的28* 28 的图像扩展为32* 32 像素大小。
下面对每一层进行详细介绍。
C1 卷积层由6 个大小为5* 5 的不同类型的卷积核组成,卷积核的步长为1,没有零填充,卷积后得到6 个28* 28像素大小的特征图;
S2 为最大池化层,池化区域大小为2* 2,步长为2,经过S2 池化后得到6 个14* 14 像素大小的特征图;
C3 卷积层由16 个大小为5* 5 的不同卷积核组成,卷积核的步长为1,没有零填充,卷积后得到16 个10* 10 像素大小的特征图;S4 最大池化层,
池化区域大小为2* 2,步长为2,经过S2 池化后得到16 个5* 5 像素大
小的特征图;C5 卷积层由120 个大小为5* 5 的不同卷积核组成,卷积核
的步长为1,没有零填充,卷积后得到120 个1* 1 像素大小
的特征图;将120 个1* 1 像素大小的特征图拼接起来作为F6 的输入,F6 为一个由84 个神经元组成的全连接隐藏层,激活函数使用sigmoid 函数;最后一层输出层是一个由10 个神经元组成的softmax 高斯连接层,可以用来做分类任务
LeNet-5是LeNet系列的最终稳定版,
它被美国银行用于手写数字识别,该网络有以下特点:所有卷积核大小均为5*5,步长为1;
所有池化方法为平均池化;所有激活函数采用Sigmoid
1.输入层:输入图像的尺寸统一归一化为32*32.
2.C1层:第一个卷积层输入图片大小:32*32卷积核大小:5*5,步长1,无填充
卷积核种类:6
输出特征图大小:28*28 ; 32-5+1=28神经元数量:28*28*6=4704
可训练参数:(5*5+1)*6=156 其中,1为偏置参数连接数(和输入层的连接数):
(5*5+1)*6*28*28=122304
3.S2层-池化层(下采样层)
输入特征图大小:28*28采样区域:2*2采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数。采样种类:6输出特征图大小:14*14
神经元数量:14*14*6连接数(和C1层连接):(2*2+1)*6*14*14
S2中每个特征图的大小是C1中特征图大小的1/4.
4.C3层-第二个卷积层
输入:S2中所有6个或者几个特征图组合卷积核大小:5*5卷积核种类:16
输出特征图大小:10*10 14-5+1=10
C3中的每个特征图是连接到S2中的所有6个或者几个特征图的,表示本层的特征图是上一层提取到的特征图的不同组合。存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集作为输入。接下来6个特征图以S2中4个相邻特征图自己为输入。然后的3个以不相邻的4个特征图子集作为输入。最后一个将S2中所有特征图作为输入。输出的16个通道并没有与输入的每个通道相连。这样设计的初衷有两个:
1.减小计算量;2.打破对称性。
现在的网络设计中,很少会遵循这样的设计原则。
可训练参数:6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516连接数:10*10*1516=151600
5.S4层-池化层(下采样层)
输入:10*10采样区域:2*2采样方式:4个输入相加,乘以一个可训练参数,
再加上一个可训练偏置。结果通过sigmoid函数。采样种类:16输出特征图大小:5*5
神经元数量:5*5*16=400连接数:(2*2+1)*400=2000S4中每个特征图的大小是C3特征图大小的1/4
6.C5层-第三个卷积层
输入:5*5,即S4层的全部16个单元特征图(与S4全相连)
卷积核大小:5*5卷积核种类:120输出特征图大小:1*1 (5-5+1)
可训练参数:120*(16*5*5+1)=48120连接数:1*1*48120=48120
C5层是一个卷积层。
由于S4层的16个图的大小为5*5,与卷积核的大小相同,所以卷积后形成的图的大小为1*1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5*5*16+1)*120=48120个连接。
7.F6层-全连接层
输入:120维向量 输出:84维向量 计算方式:计算输入向量和权重向量之间的点积,
再加上一个偏置,结果通过sigmoid函数输出。可训练参数:84*(120+1)=10164
8.输出层-全连接层
输入:84维向量
输出:10维向量
可训练参数:84*10,其中10就是分类的类别数。
一共有10个节点,分别代表数字0到9,
且如果节点i的值为0,
则网络识别的结果是数字i。采用的是径向基函数
(RBF)的网络连接方式。假设x是上一层的输入,
y是RBF的输出
VGG16
VGG的输入为224×224×3224×224×3的图像
对图像做均值预处理,每个像素中减去在训练集上计算的RGB均值。网络使用连续的小卷积核(3×33×3)做连续卷积,卷积的固定步长为1,并在图像的边缘填充1个像素,这样卷积后保持图像的分辨率不变。连续的卷积层会接着一个池化层,降低图像的分辨率。空间池化由五个最大池化层进行,这些层在一些卷积层之后(不是所有的卷积层之后都是最大池化)。在2×2像素窗口上进行最大池化,步长为2。卷积层后,接着的是3个全连接层,前两个每个都有4096个通道,第三是输出层输出1000个分类。所有的隐藏层的激活函数都使用的是ReLU使用1×11×1的卷积核,为了添加非线性激活函数的个数,
而且不影响卷积层的感受野。没有使用局部归一化,作者发现局部归一化并不能提高网络的性能。
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替
AlexNet中的较大卷积核(11x11,7x7,5x5)
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,
使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证
具有相同感知野的条件下,提升网络的深度,在一定程度上提升神经网
络的效果。
VGG最后三个全连接层在形式上完全平移了AlexNet的最后三层,
VGGNet后面三层(三个全连接层)为:
FC4096-ReLU6-Drop0.5,FC为高斯分布初始化(std=0.005),
bias常数初始化(0.1)
FC4096-ReLU7-Drop0.5,FC为高斯分布初始化(std=0.005),
bias常数初始化(0.1)
FC1000-SoftMax1000分类,FC为高斯分布初始化(std=0.005),
bias常数初始化(0.1)
超参数上只有最后一层fc有变化:bias的初始值,由AlexNet的0变为0.1,
该层初始化高斯分布的标准差,由AlexNet的0.01变为0.005。















 2926
2926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









