










引言
本文我们介绍文本风格转换,虽然是这个名字,但是其实可以是比文本风格更广泛的东西。
风格转换
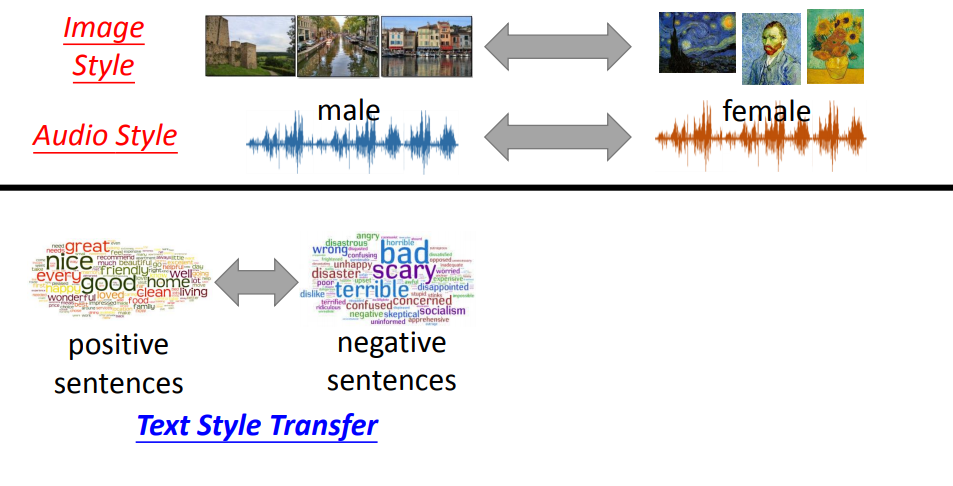
本文主要介绍文本风格转换。
我们有两堆文本数据,这两堆文本数据有不同的书写风格。
所谓书写风格有很多种定义,比如一种是积极(正面)的书写风格,另一种是消极(负面)的书写风格。
我们希望能把一种书写风格转换为另一种。如果我们有这样的不同风格的文本对,那么事情就很简单,用seq2seq模型训练就好了。
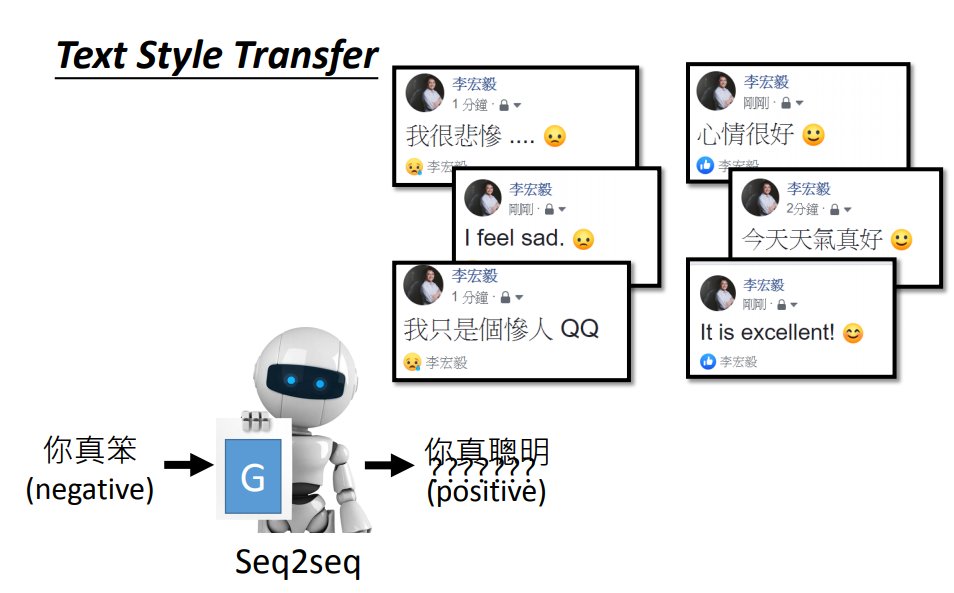
但实际上,我们很难有足够多的成对数据。我们也不知道一个负面的句子要对应那一个正面的句子。
所以我们需要用无监督学习的方法,从两种风格,但是没有成对的文字里面进行学习。
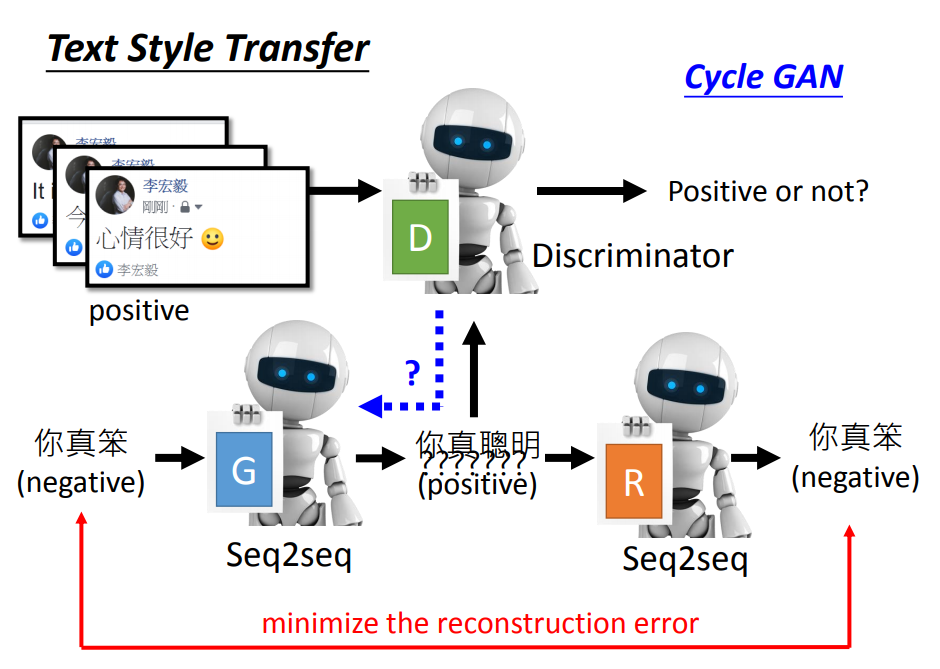
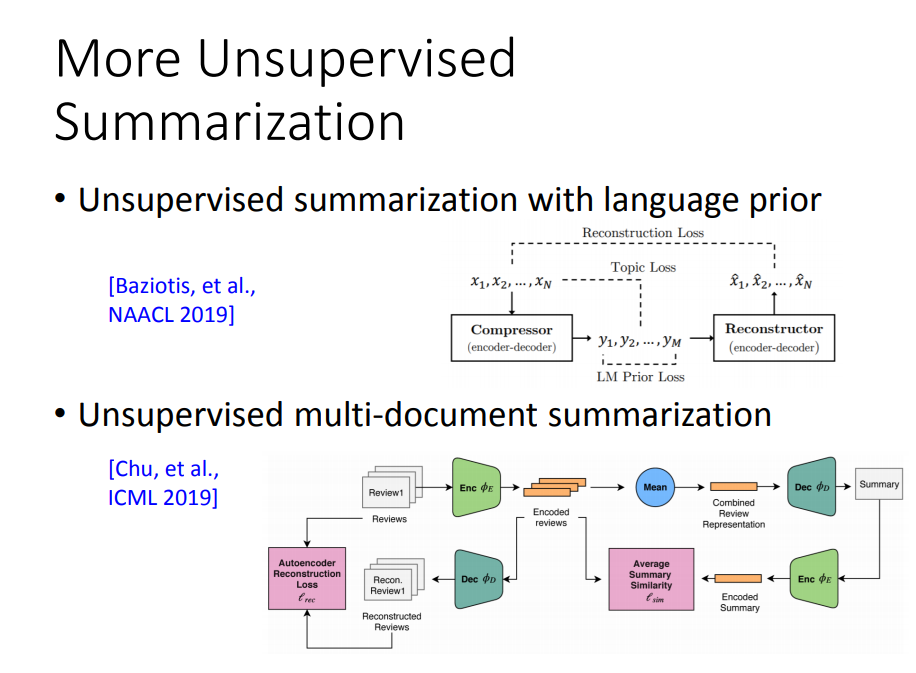
具体来说,我们可能需要训练一个Discriminator1,然后它看过很多正面的句子,它能知道某个句子是否为正面的。 然后你希望这个seq2seq模型把负面句子转成正面的句子后,这个Discriminator能认为这就是正面的句子。
光有一个Discriminator是不够的,我们还需要有另一个seq2seq模型,它要输出的正面句子转回为负面的句子。
对于第一个seq2seq模型(Generator)来说,它有两个目标:1.把负面的句子转成正面的句子,并且转换后的结果能通过Discriminator 2. 同时这个正面的句子,丢给另外的seq2seq模型后,能转回为原来负面的句子,确保文字的内容(句子的架构)不会发生变化。
这个就是Cycle GAN。我们知道要训练GAN的时候,需要把Generator和Discriminator接起来,一起训练,而Generator训练的目标就是要骗过Discriminator,得出来的结果是我们想要的。
但是应用在文字就有点不一样。
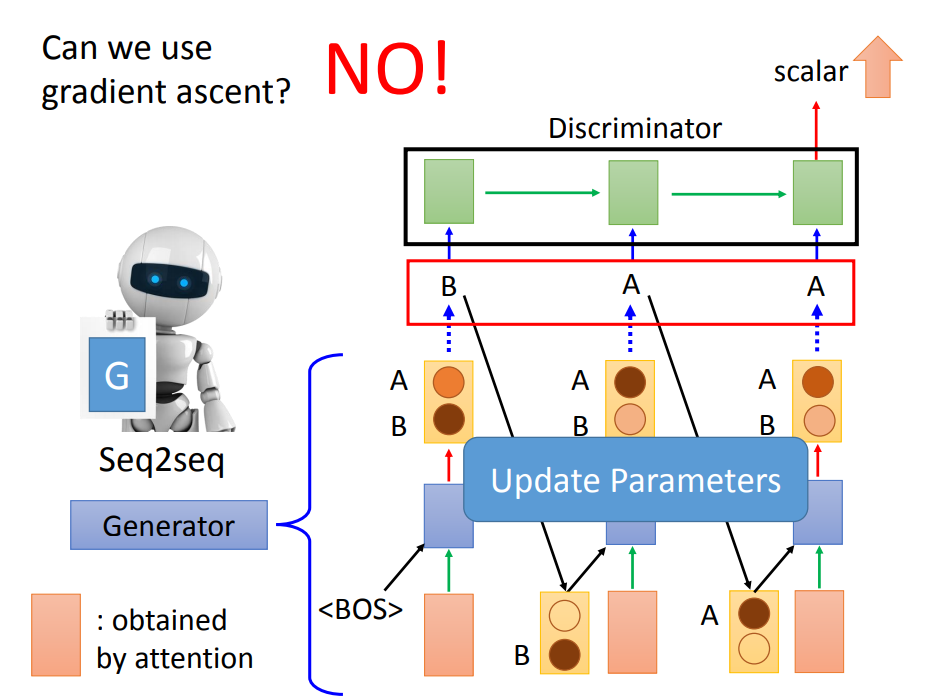
我们知道,文字上一般用seq2seq模型,所以Generator也是一个seq2seq模型,这个seq2seq模型生成出来的结果会丢到Discriminator里面,它会输出一个分数,表示现在这个句子某种风格的分数。这里假设就是正面风格分数。
如果是一般的GAN,接下来我们要做的事就是调整Generator的参数,希望Discriminator输出的分数越大越好。然后我们把Discriminator和Generator合起来,当做是一个模型,然后用梯度下降的方法去训练。
但是在文字上面,我们无法用梯度下降来做,因为在Generator好Discriminator之间,有一个Generator生成的随机采样输出存在。
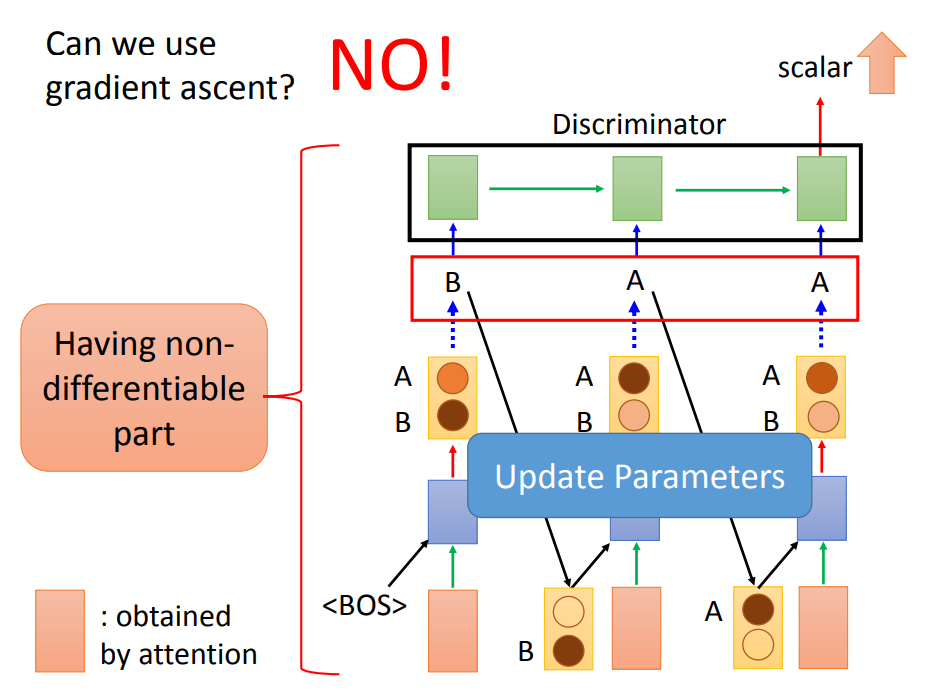
因为里面有随机采样存在,而随机采样是不能微分的,所以不能用梯度下降来做。
所以学者们就研究了各种方法试图解决这个问题。

大致可以分成三类。
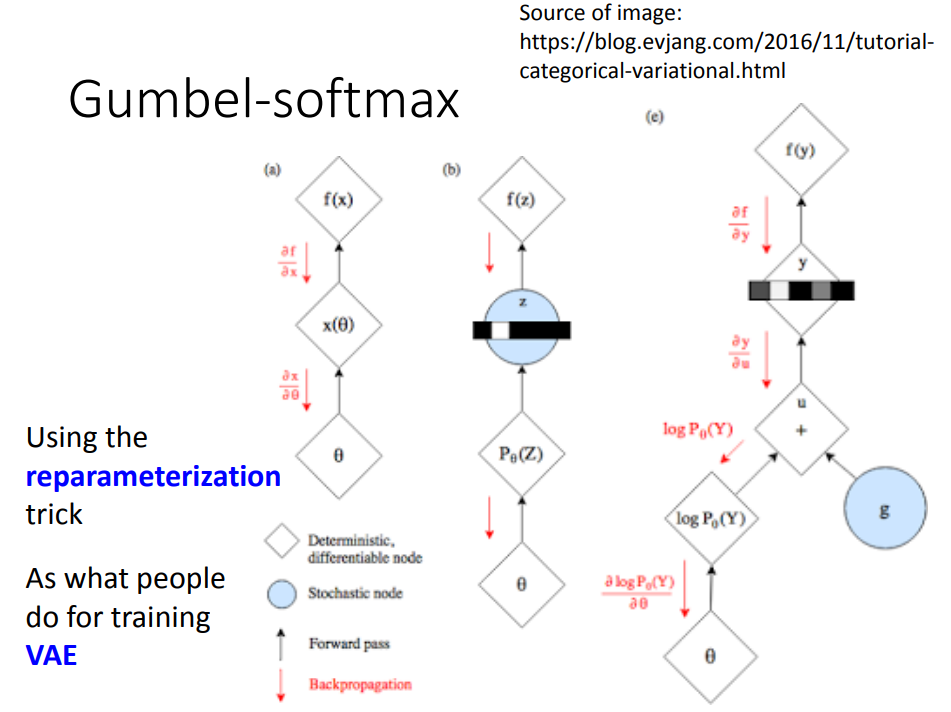
第一种方法主要的想法是用了reparameterization的技巧,类似VAE。
本来采样这件事情是不能微分的,使用了这个技巧,把它变成可微分的。
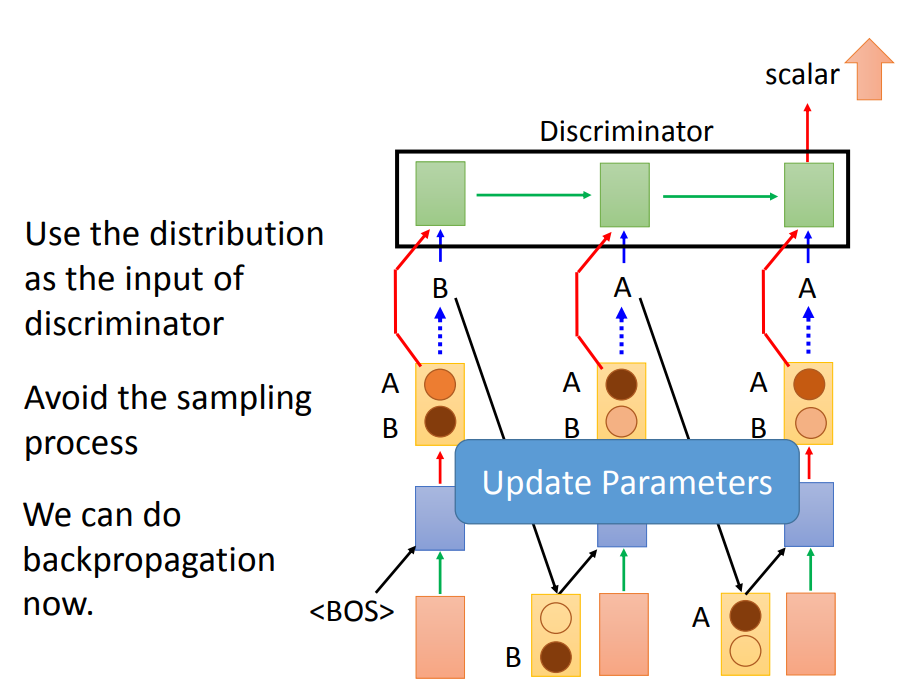
第二种方法就是给Discriminator一个连续的输入,竟然采样无法微分,这种方法就避开采样,直接给Discriminator看连续的输出token向量分布,这样就避免了采样的步骤,然后就能真正的合起来当成是一个模型,就能用梯度下降训练。
但是这个方法存在一个严重的问题。

我们知道Discriminator做的事情是判断现在你给它的输入对不对。我们会给它看真实数据,和Generator的输出,但真实数据一般是一个ont-hot向量,而Generator的输出,它是连串的分布,如果把两者进行比较,Discriminator会发现要分别它们的差异太容易了,直接看输出的向量是不是ont-hot就行。从而导致Generator为了让Discriminator认可,它的输出会越来越接近one-hot向量。结果导致什么都学不到。
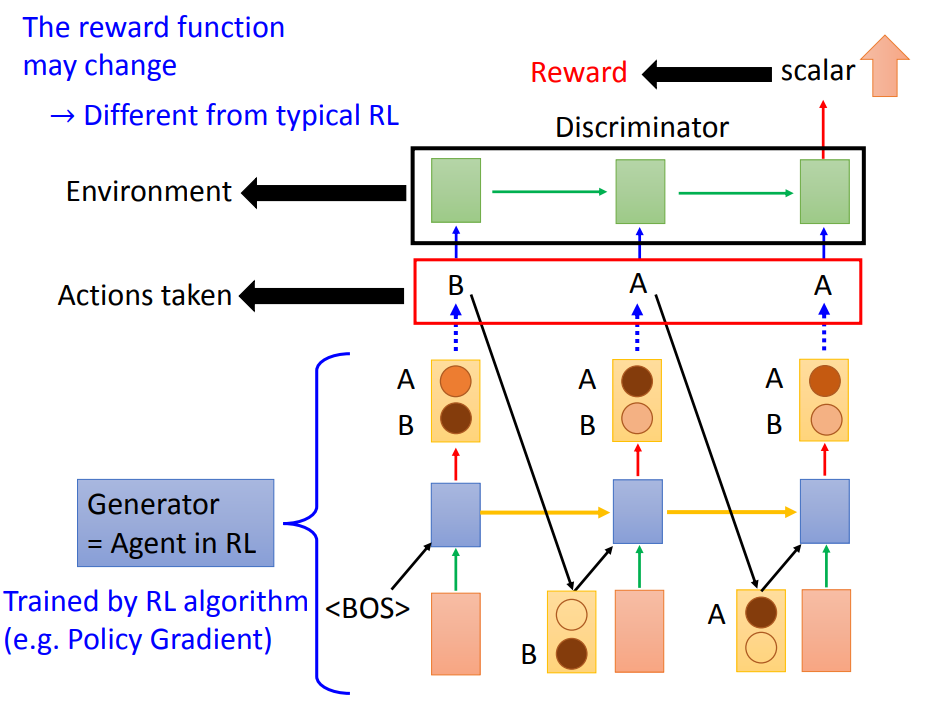
最后一种方法就是强化学习(RL)。它基于碰到不能微分的东西,就用强化学习硬Train一发。
Generator变成了RL中的Agent,现在输出来的东西变成了Actions,然后Discriminator就是Environment,Discriminator输出的分数就是Reward。
然后用RL的算法,比如Policy Gradient去训练Agent,让Reward越高越好。
我们希望Environment是固定的,也就是说,根据Action去计算出Reward这件事情是固定的。
但是现在Discriminator也是会随着训练而改变的,这样会导致在训练的过程中,我们的Environment是不断改变的,我们的Reward函数是不断改变的。这会导致RL的训练变得更加困难。

所以RL+GAN好像是可行的,实际上会很难。RL以很难训练为闻名,GAN也是很难训练的,这两个东西加起来,那岂不是要爆炸。
所以如果你想这么做的话,是需要一些tips(提示)的。
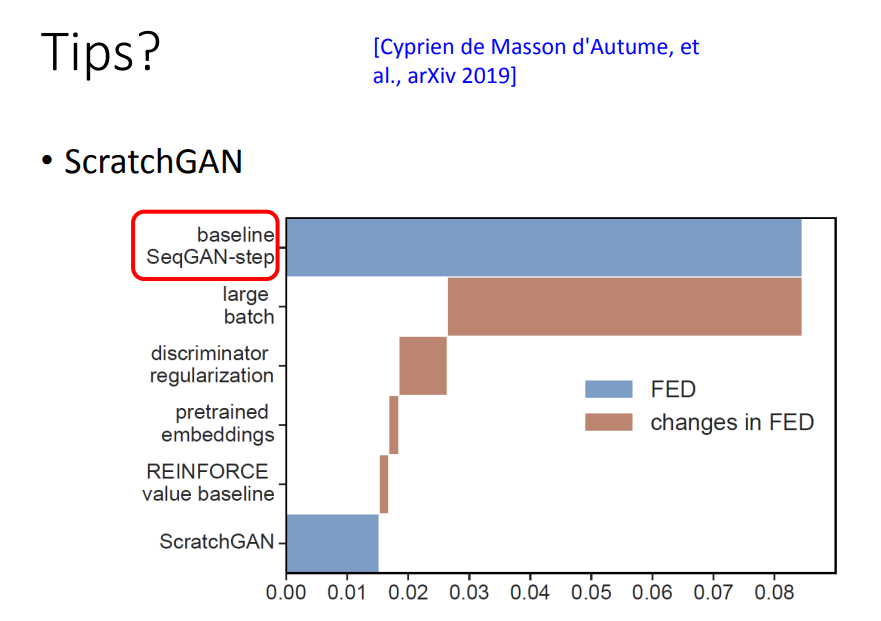
ScratchGAN中把各种各样用RL来训练GAN的方法实验了一轮,这里的FED越小越好。
从结果可以得到启示,有一个一定要用的tips。
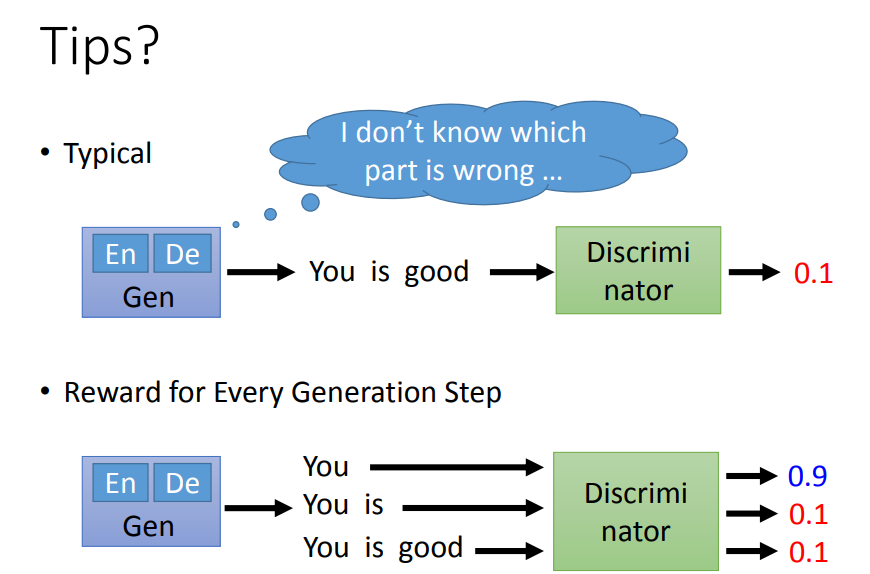
为什么用RL训练GAN会这么困难呢
在GAN里面Disriminator要在Generator(简称Gen)产生完一段完整的文字后,才会给这段完整的文字一个分数。
比如Gen产生了一个语法错误的话“You is good”,Disriminator可能会产生一个较低的分数,但是它不知道哪里有问题。
刚才我们说的那个tip就是为每个生成步骤进行打分。
即Disriminator要去衡量“You”,”You is”和“You is good”每个步骤的输出好不好。
这样Generator才能知道哪一步出问题了。
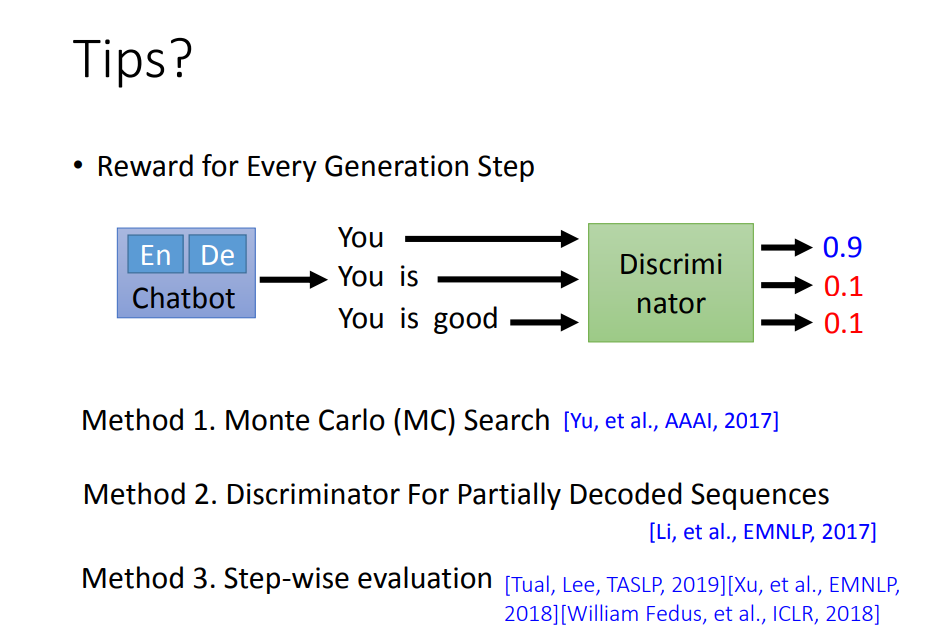
听起来不错,那要如何做到每一步输出都给一个分数呢
这里就有各种不同的方法。上面给出了一些文献,感兴趣的可以了解一下。建议尝试第3个方法。

现在我们看训练的Cycle GAN得到的结果怎样。上面是不同的负面句子,看生成的正面句子会怎样。

除了对句子做正负面的转换意外,还可以做更广泛的转换。

比如有人试着把放松转成烦躁;把男性的句子转换为女性的句子;还把年轻风格转换为老年风格。
我们上面介绍的技术是Cycle GAN。一般是用于两种风格互相转换。如果你有多种风格,建议使用StartGAN的方法。
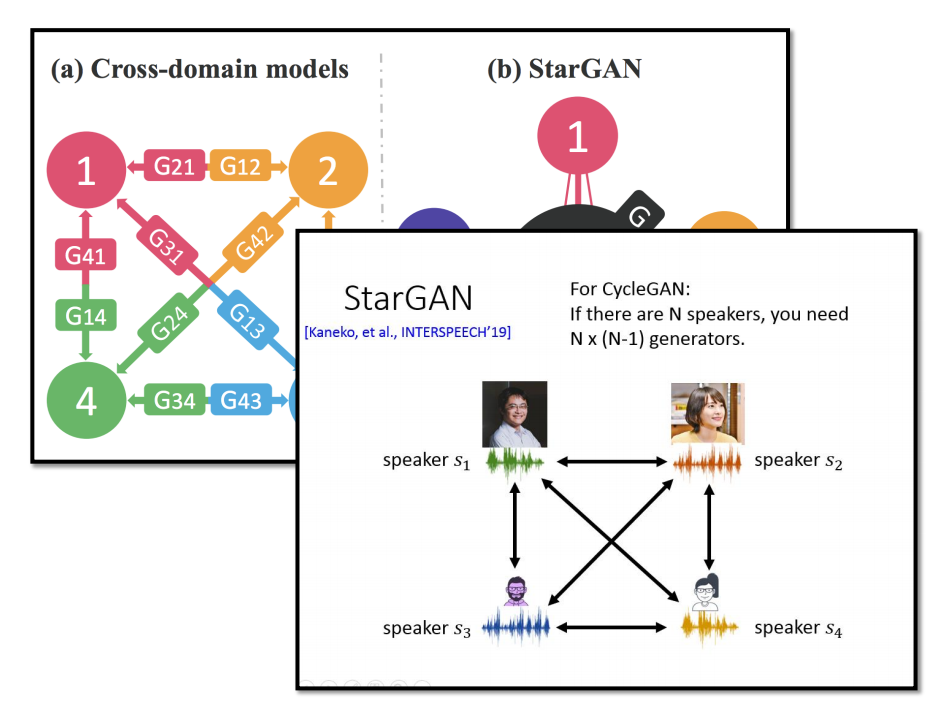
比如StarGan可以用于多人声音互换。
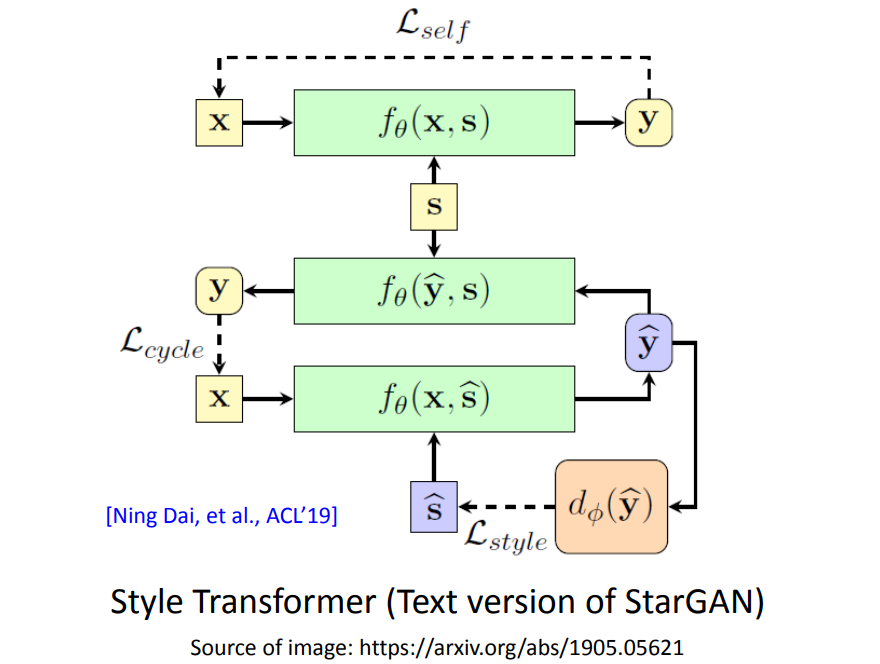
在文字上也有StarGAN——Style Transformer。
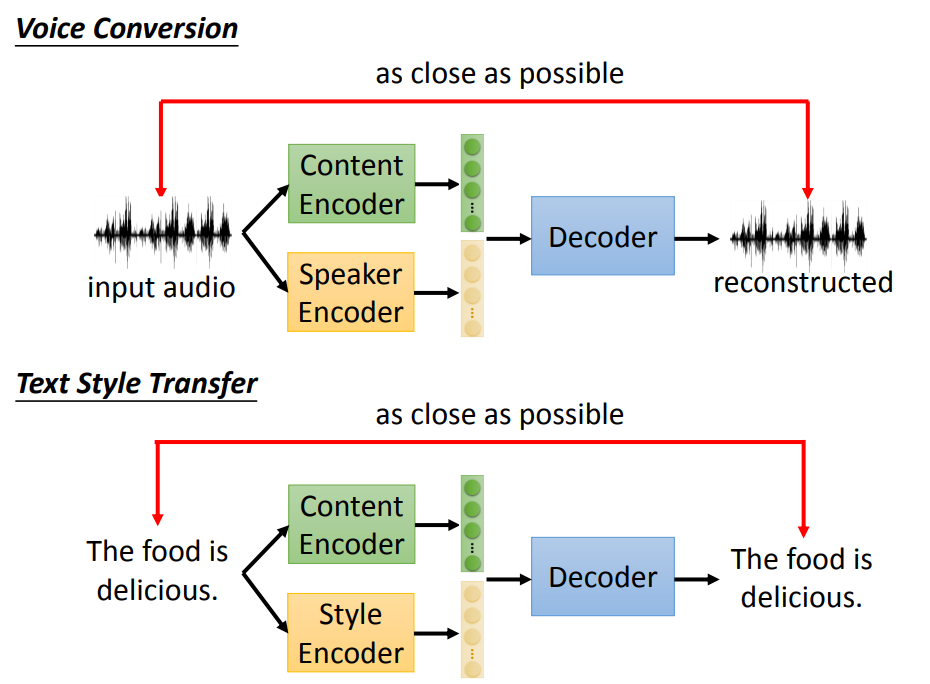
语音风格转换有两大类做法,那文字风格转换是不是也类似呢。
在语音风格转换中,我们可以有两个编码器,一个抽出内容信息,另一个抽去讲话人的信息。
在文字风格转换里面,我们也可以做一样的事情。
我们可以训练两个编码器,一个抽取文字的内容信息,另一个抽取文字的风格信息。接下来用一个解码器,读入内容信息和风格信息,还原原来的句子。
如果要做文字风格转换,我们只要换掉抽取风格信息编码器的输出,期待它就能产生不同风格的文字。
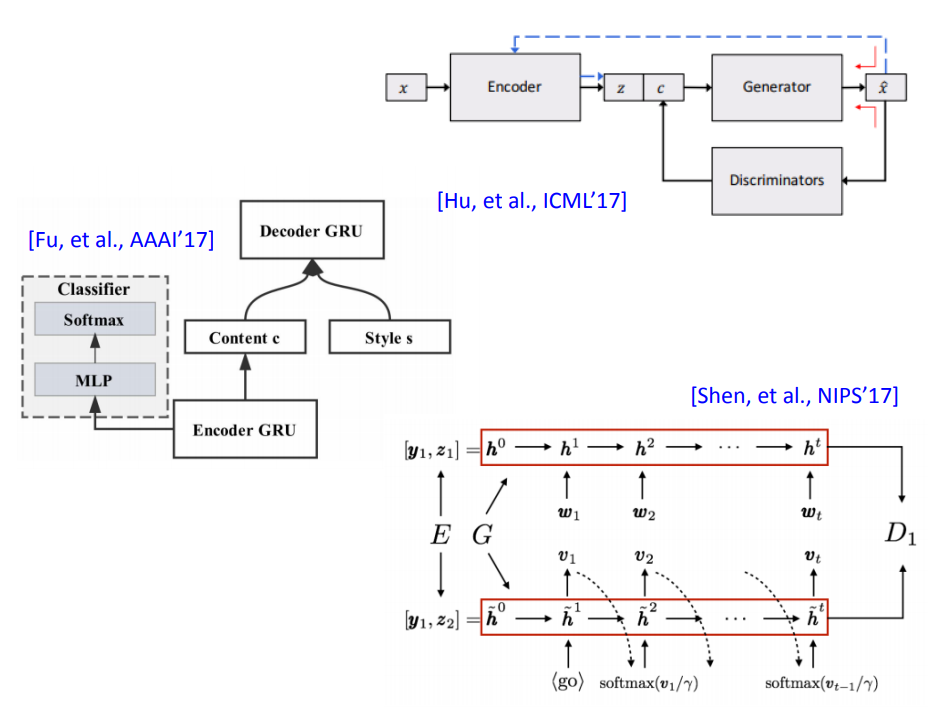
在文献上确实就有这样的方法。但是你可以发现相关的论文都比较早,都是17年发表的。
为什么今年来这种方法就没那么火了呢,可能因为文字本身是离散的,把这些文字压缩到一个连续空间后,然后这个连续空间里面可能就有很多空洞,是无法产生句子的。
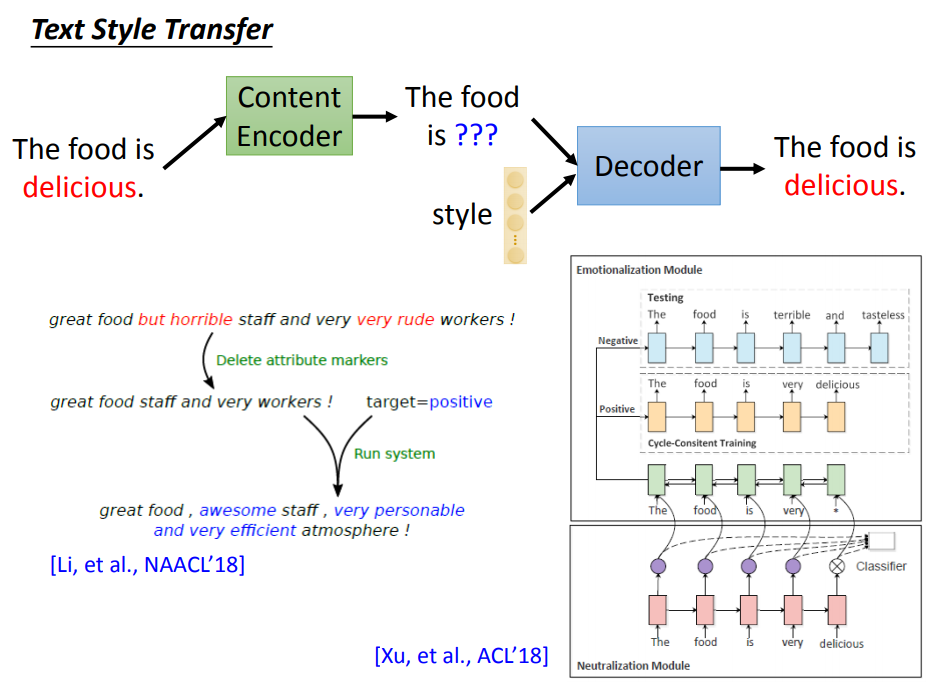
我们知道把一个句子,用一个向量来表示,有点困难。那我们能不能把这些离散的文字内容抽取来,也用离散的东西来表达呢。比如用另外一段文字来表达。
比如,内容编码器读入一个句子“The food is delicious”,然后它知道“delicious”跟(正面)风格比较有关。
然后内容编码器就抹掉“delicious”这个形容词,然后输出“The food is ???”这个句子,此时它输出的不是一个向量,而直接是一个句子。
然后把这个句子加上一种风格,然后要求解码器还原原来的句子。上面列出了两个文献,就是做这件事情的。
刚才我们说过,文字风格的应用比我们想象的更广泛。其实我们也可以把长文章当做一种书写风格,把简短的摘要当成另一个种书写风格。这样我们就能做无监督的自动摘要了。
过去我们可以通过监督学习的方法,通过一个seq2seq模型来做,但是收集这种有标签的数据是很困难的。
如果能做到无监督摘要的话,我们就可以给机器看一大堆文章,然后准备一大堆摘要,这些文章和摘要不需要对应起来。我们只是告诉机器人类写的文章是什么风格,人类写的摘要是什么风格。
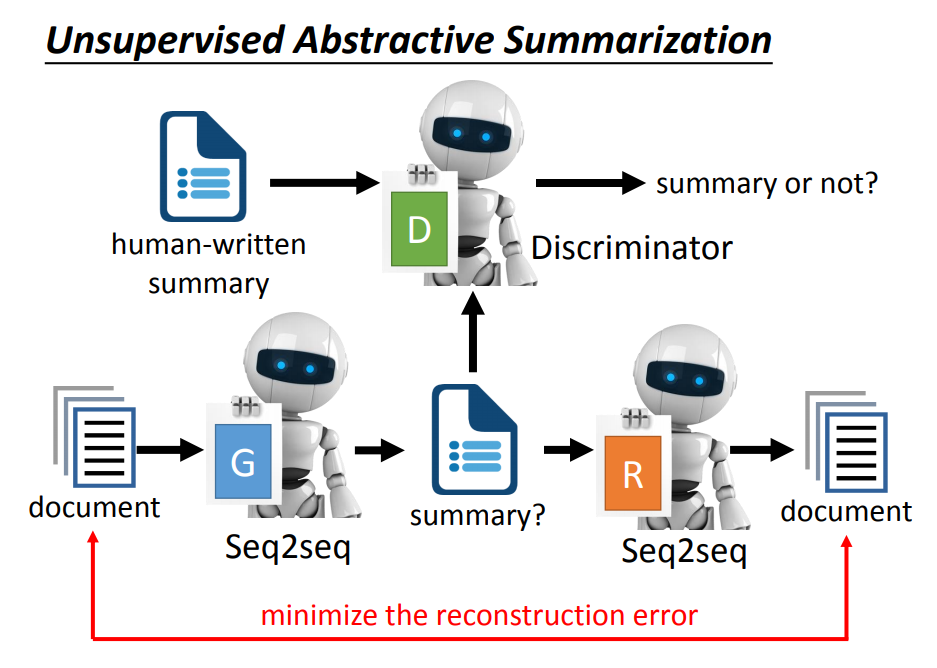
类似Cycle GAN,把相应的思想套进去就可以了。有一个seq2seq的Generator,用于输入文章,输出文章的摘要,Discriminator先看过很多人类些的摘要,然后交给它去判断Gen生成的是否为摘要。
同时用另一个seq2seq模型尝试还原Gen生成的摘要为原来的文章。
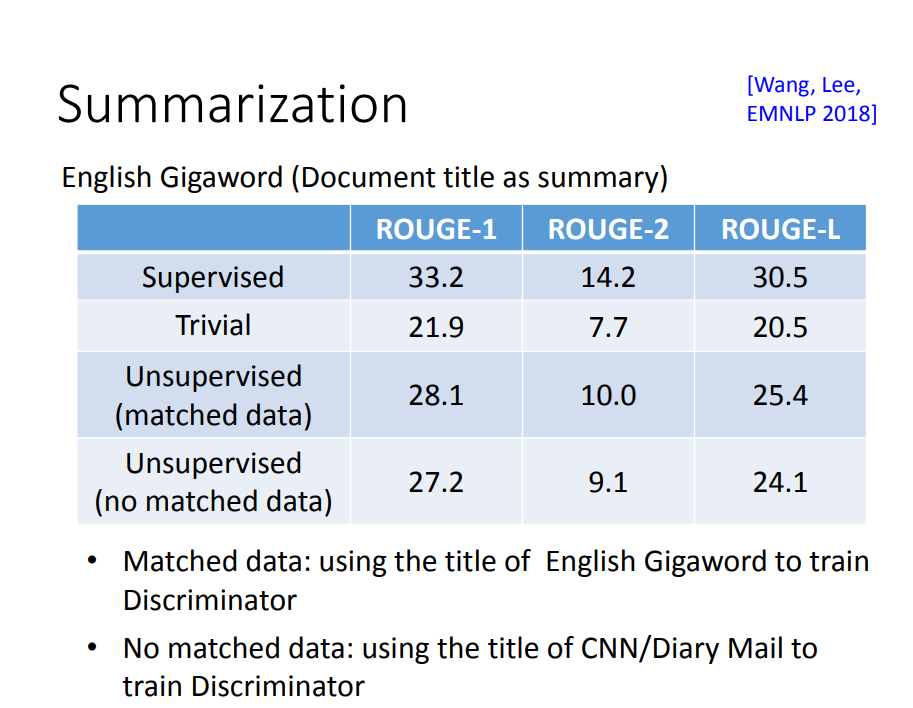
一般我们评估摘要的好坏用的是ROUGE这个分数,用监督学习的方法,能得到33.2分(ROUGE-1),而用Cycle GAN的方式,能得到28.1分。超过了基准模型Trivial。
其中ROUGLE-L中的L代表n-gram里面的n。
其中Matched data使用英文Gigaword语料库中的标题去训练Discriminator,而No matched data的摘要和文章是无关的。可以发现这种方法的得分也不是很差。
上面还有更多的无监督学习摘要生成方法。列出了相关文献。
 到目前为止,我们看到的两种风格的文字,只是书写方式不同,还是同样的语言。
到目前为止,我们看到的两种风格的文字,只是书写方式不同,还是同样的语言。
如果我们说,两种风格的句子,一边是英文,一边是中文。机器能否在两种语言之间进行转换呢,即做机器翻译任务。这样就能做无监督机器翻译任务。
最早这一系列的研究是从词嵌入的映射开始的。
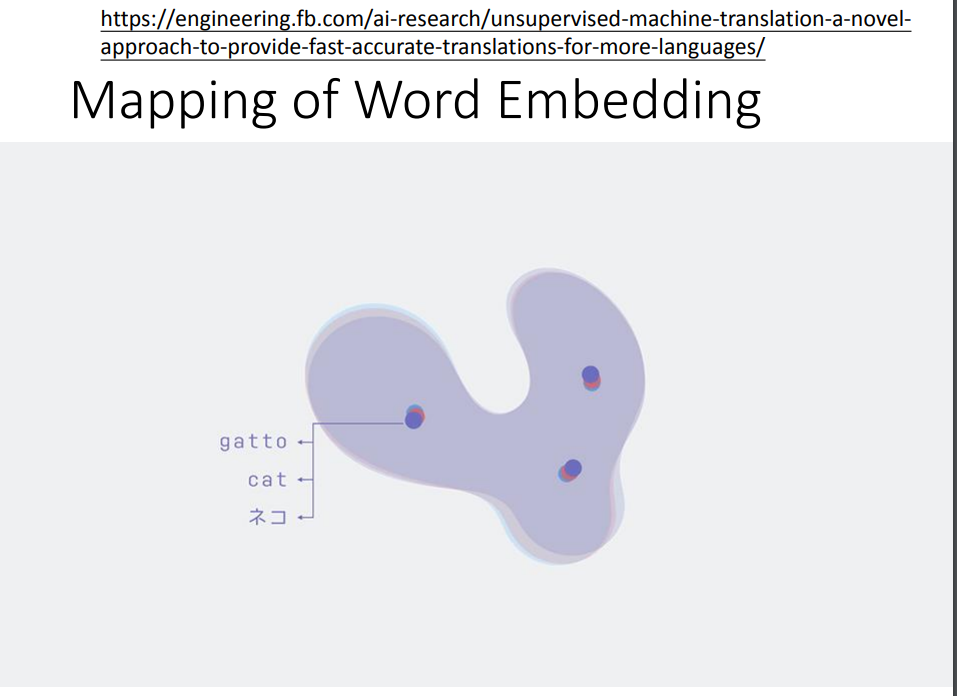
可能让机器直接学会不同语言之间句子的转换太难了,我们先让机器学会词嵌入之间的转换。想办法让不同语言的词嵌入堆在一起,那同样意思的词汇,它们的嵌入向量就是一样的。
比如dog对应到狗。

我们可以训练英文的嵌入和中文的嵌入,可能这两种不同语言的嵌入之间只差了某种转换而已。
这个转换有可能就是线性的转换,即乘以某个矩阵,就能完成。也许英文里面rabbit和fish的关系与中文里面兔和跳的关系是一样的。
如果词嵌入真的能捕获到词汇之间的关系,那么不同语言之中同样词汇对应的关系就是一样的,只要我们找到这种线性的转换,就能做到不同语言词嵌入之间的转换。
那我们如何找到这个线性转换呢
比较简单的想法是监督学习的方法,我们已经知道了英文里面的某些词汇对应中文里面的哪些词汇。
也许不同的语言都有阿拉伯数字,同一个阿拉伯数字在不同的语言中的意思就是一样的,我们就有一些天然的标记数据。我们知道英文里面的 1 1 1完全对应于中文里面的 1 1 1。
通过这种成对的数据,我们就能训练出这个线性转换 W W W,然后就能应用到其他词汇上。
这就是监督学习的想法,处理监督学习的方法外,我们希望能做到更自动的形式。就是使用无标签的数据。
上面这篇19年的文献就总结了不同的方法。那无监督的方法是怎么做的呢。
比如可以把 W W W当成Generator,然后把 W W W乘上英文嵌入,然后训练一个Discriminator,希望Generator生成的输出和中文的嵌入越接近越好。
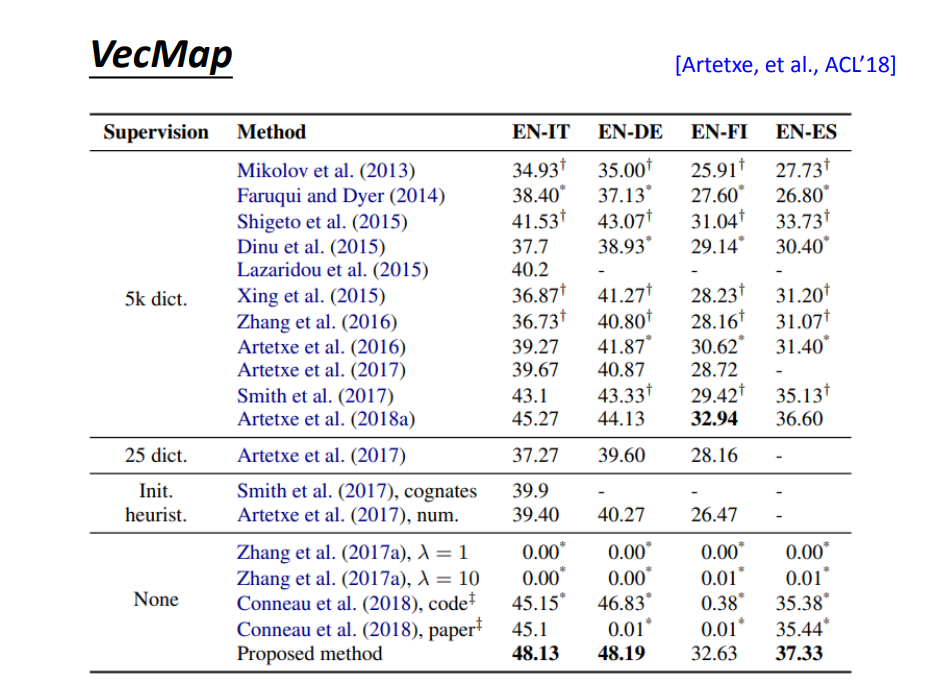
这一系列的方法得到了较大的突破,现在这些无监督的方法(48.13),经过不断的研究后,它们的结果居然比监督学习的方法(45.27)还要好一些。
下面我们探讨下如何做真正的无监督翻译,也就是句子对句子的翻译。
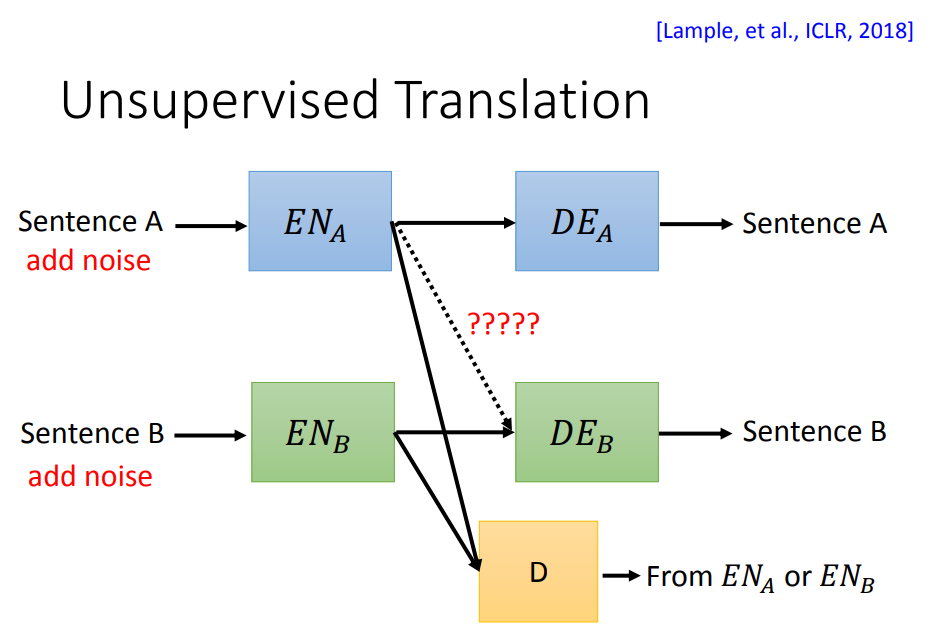
假设现在有语言A和语言B,我们想互相翻译这两种语言。但是我们只有一堆A的数据和一堆B的数据,我们没有A和B对应关系。
我们先训练语言A的编码器和解码器,然后语言B的编码器和解码器。在训练的时候需要把输入加一些噪音(替换词汇,或更改词汇的顺序等)。
然后把语言A的编码器和语言B的解码器拿出来,希望输入句子A,得到A编码器编码后的结果,再喂给B语言的解码器,希望能它能输出句子B。这样就能把A语言的句子翻译成B语言的句子。
实际上并没有这么容易,因为不同语言的编码器是分开训练的,没有理由说它们就能简单的互换。接下来就有各种各样的技巧来解决这问题。
比如可以加一个Discriminator,用它来判断编码器A的输出和编码器B的输出有什么不同。希望除了能让它们的解码器成功解码外,它们还要想办法让它们的编码器输出越接近越好。
我们期待说,当这两种编码器的输出很接近时,我们就能实现上面的替换。不过光是这样是不够的,还要有其他的技巧。
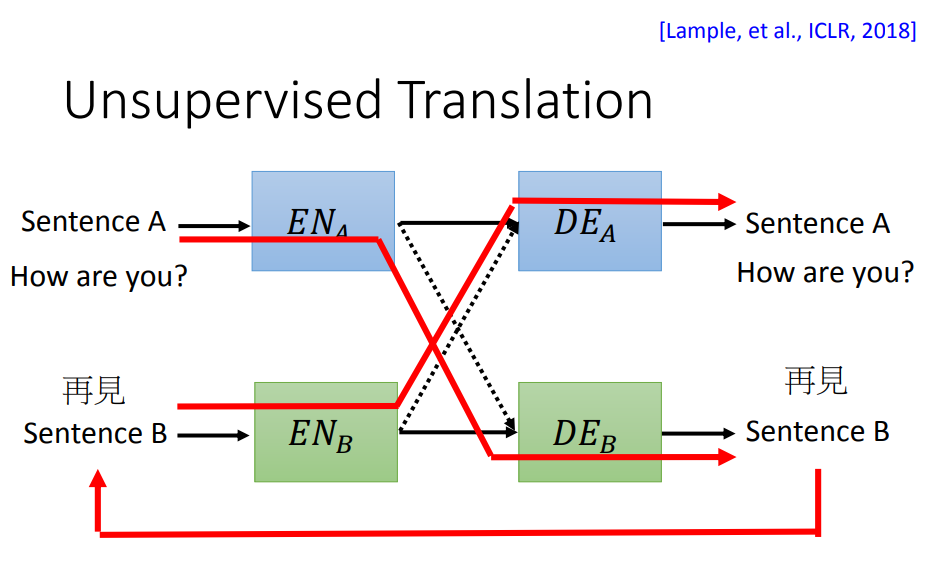
举例来说,你把语言A的句子经过A编码器编码后,丢给语言B的解码器,产生的语言B的句子。再把这个B语言的句子,当成B编码器的输入,编码后,再丢给解码器A,得到语言A的句子。 然后希望经过这么一大堆转换后,原来的A语言的输入和最终得到的输出越接近越好。
但是还不够。还需要借助另外一个无监督学习模型。
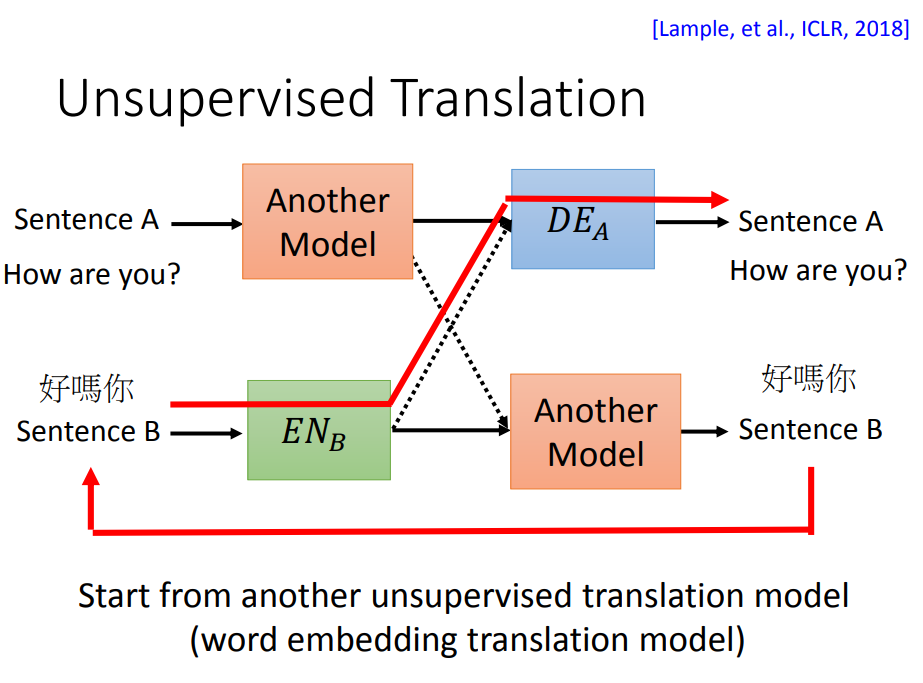
这个新的无监督学习模型我们要选一个不是很好的模型,也许输入“How are you”,它会翻译成“好吗你”。它不能正确翻译,但是有点接近。
这样编码器A和解码器B就不会乱学了,至少要学会把“好吗你”换回“How are you”。类似给B编码器加入一些噪音。
那这个新的不是很好的无监督学习模型是哪里来的呢?可以就用我们刚才只用词嵌入技术找到的词词映射的模型。这样整个过程就能反复进行。
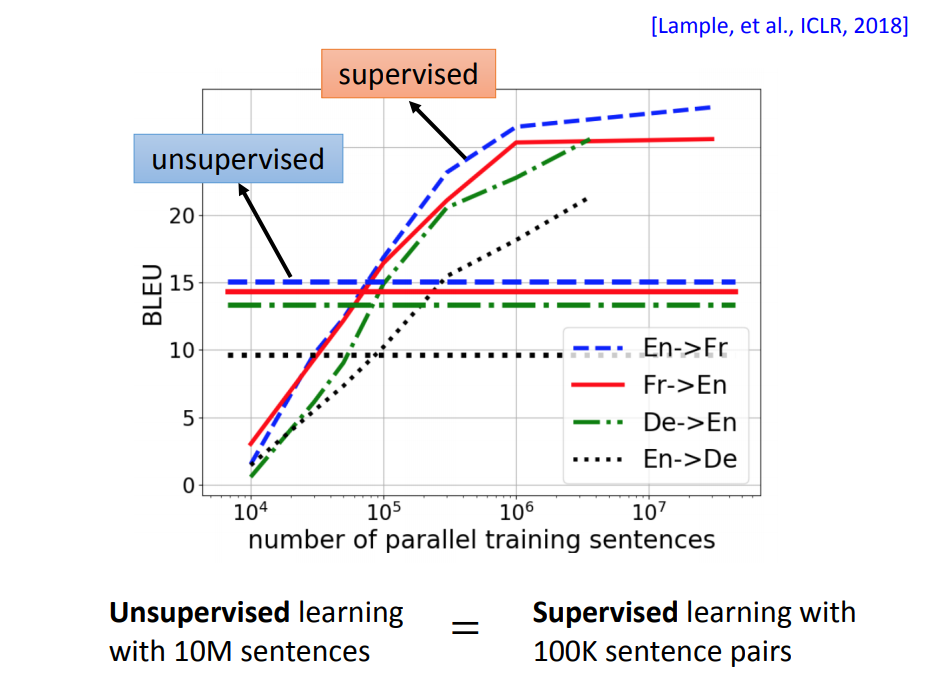
上图是实验结果,横轴是监督学习用到的成对数据量,发现如果用10Million个句子(无标签)用无监督学习的方法训练,预用100K数据量(有标签)的监督学习方法得到的结果差不多。
也就是说,如果你标签的数据量少于100K,你可以直接做无监督学习。
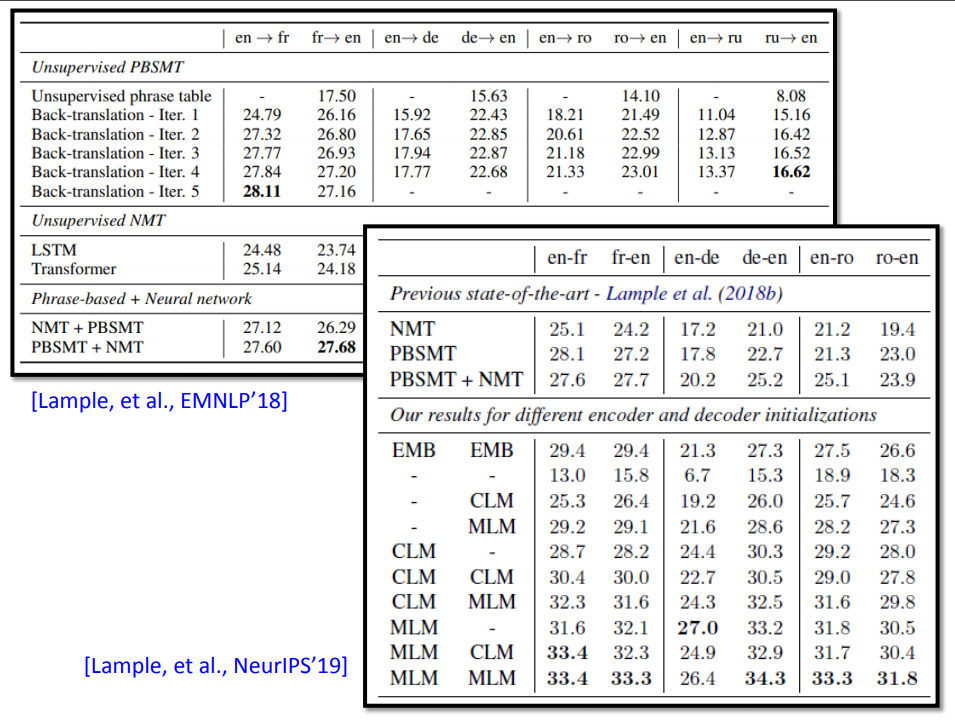
后来同样的团队(上面18年的文献)不断地研究,然后让无监督学习的表现进步了一些。
近年来由于有了BERT之后,产生了比较大的进步。用BERT预训练后,编码器和解码器的表现就起飞了。


















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











