










引言
本文我们会学习几种常见的BERT变体,如ALBERT1,RoBERTa2,ELECTRA3和SpanBERT4。
ALBERT
A Lite version of BERT(ALBERT)1想解决的是BERT模型参数量过多的问题,相比BERT它是一个精简版的。它使用下面两种技术来减少参数量:
- 跨层参数共享(Cross-layer parameter sharing)
- 嵌入层参数分解(Factorized embedding layer parameterization )
跨层参数共享
跨层参数共享是一种减少参数量的有趣的方法。我们知道,BERT包含 N N N个编码器层。比如BERT-base包含12个编码器层,在训练时,需要学习所有编码器层的参数。而使用跨层参数共享的方法,我们只需要学习第一个编码器层的参数,然后让其他所有层共用这套参数。
下图显示了有N个编码器层的BERT,为了简便我们只展开第一层:
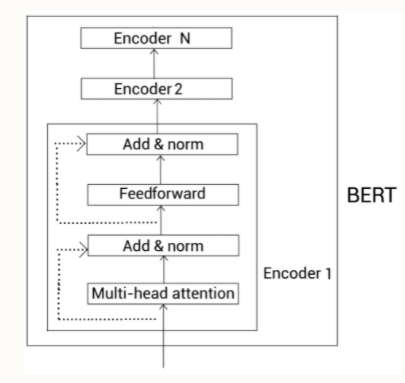
我们知道其中每一层的结构都是相同的,即它们都包含叫做多头注意力和前馈神经网络的子层。在应用跨层参数共享时有几种不同的方式:
- All-shared: 共享第一个编码器层的所有子层参数到其他编码器层
- Shared feedforward network:只共享第一个编码器层的前馈神经网络层参数到其他编码器层(的前馈神经网络)
- Shared attention:只共享第一个编码器层的多头注意力层参数到其他编码器层(的多头注意力层)
ALBERT模型使用All-shared模式。
嵌入层参数分解
在BERT中,使用WordPiece分词器创建WordPiece标记。其WordPiece标记的嵌入大小被设成和隐藏层嵌入大小(向量表示大小)一样。而WordPiece嵌入是上下文无关的表示,它是从词表中的独热编码向量学习的。而隐藏层嵌入是由编码器返回的有上下文信息的表示。
我们记词表大小为 V V V。我们知道BERT的词表大小为30000。我们记隐藏层嵌入大小为 H H H,WordPiece嵌入大小为 E E E。
为了编码更多的信息到隐藏层嵌入中,我们通常需要设置一个很大的隐藏层嵌入大小。比如,在BERT-base中,其隐藏层嵌入大小 H H H为768。那么隐藏层嵌入的维度是 V × H = 30000 × 768 V \times H = 30000 \times 768 V×H=30000×768。因为WordPiece嵌入大小 E E E被设成预隐藏层嵌入大小一样,所有它的大小也为768。这样,WordPiece嵌入层的维度为 V × E = 30000 × 768 V \times E =30000 \times 768 V×E=30000×768。也就是说,增加隐藏层嵌入大小 H H H也会同时增加WordPiece嵌入大小 E E E。
那么我们如何避免这个问题?我们可以使用嵌入层参数分解方法将嵌入矩阵分解为更小的矩阵。
我们将WordPiece嵌入大小设为隐藏层嵌入大小,因为我们可以直接投影独热向量到隐藏层空间。基于分解(将 E E E和 H H H分离,即让它们相互独立),我们首先将独热向量投影到低维嵌入空间 V × E V \times E V×E,然后再将该低维嵌入投影到隐藏空间 E × H E \times H E×H,而不是直接投影独热向量到隐藏空间( V × H V \times H V×H)。即,我们不是直接投影 V × H V \times H V×H,而是将这步分解为 V × E V \times E V×E和 E × H E \times H E×H。
举个例子,假设我们词表大小 V = 30000 V=30000 V=30000,我们将 E E E和 H H H分离。假设我们将WordPiece嵌入大小设置为较小的维度,假设 E = 128 E=128 E=128。同时隐藏层大小保持不变,还是 H = 768 H=768 H=768。现在我们通过以下步骤来投影 V × H V \times H V×H:
- 我们将one-hot向量投影到低维WordPiece嵌入向量空间 V × E = 30000 × 128 V \times E = 30000 \times 128 V×E=30000×128
- 我们接着投影WordPiece嵌入空间到隐藏空间 E × H = 128 × 768 E \times H = 128 \times 768 E×H=128×768
这样,我们将 V × H = 30000 × 768 V \times H=30000 \times 768 V×H=30000×768分解为 V × E = 30000 × 128 V \times E=30000 \times 128 V×E=30000×128和 E × H = 128 × 768 E \times H=128 \times 768 E×H=128×768。如此一来,我们可以随意调整隐藏层维度,而无需担心导致模型参数量增加过多。
我们已经知道了ALBERT是如何减少参数量的,我们下面来学习如何训练ALBERT模型。
训练ALBERT模型
与BERT类似,ALBERT模型也使用英文维基百科和Toronto BookCorpus数据集训练。我们知道BERT基于掩码语言建模(masked language modeling,MLM)和下一句预测(next sentence prediction,NSP)任务来预训练的。类似地,ALBERT也使用MLM任务,但没有使用NSP任务,而是使用一个新任务,叫句子顺序预测(sentence order prediction,SOP)。
ALBERT的作者指出基于NSP任务进行预训练并不是真的有效,它与MLM任务相比并不是一个很难的任务。同时,NSP结合了主题预测和连贯性预测到一个任务中。为了解决这个问题,他们引入了SOP任务,SOP基于句子间的连贯性而不是主题预测。我们来看下SOP任务的细节。
句子顺序预测
类似NSP,SOP也是一个二分类任务。在NSP中,我们训练模型去预测某个句子对是属于isNext还是notNext类别,而在SOP任务中,我们训练模型去预测给定句子对中的句子顺序是否被交换过。还是以一个例子来理解,考虑下面的句子对:
Sentence 1: She cooked pasta
Sentence 2: It was delicious
我们可以看出句子2和句子1是有连续关系的,因此我们把它们分为正例。现在我们创建一个负例,只要简单地交换这两个句子的顺序即可:
Sentence 1: It was delicious
Sentence 2: She cooked pasta
上面句子对中的句子顺序是交换过了的,我们把它们分为负例。
这样,我们可以使用任意语言的语料库创建SOP任务的数据集。假设我们有一些文本,我们简单地从某个文本中抽取连续的两个句子标记为正例。然后,交换它们的顺序就变成了一个负例。
对比ALBERT和BERT
类似BERT,ALBERT也基于不同的配置进行预训练。在所有的配置中,ALBERT相比BERT具更好的参数。下表显示了BERT和ALBERT模型不同配置的比较。我们看到在同样的配置下,ALBERT相比BERT少了很多参数。比如,BERT-large有334M参数,而ALBERT-large只有18M参数:
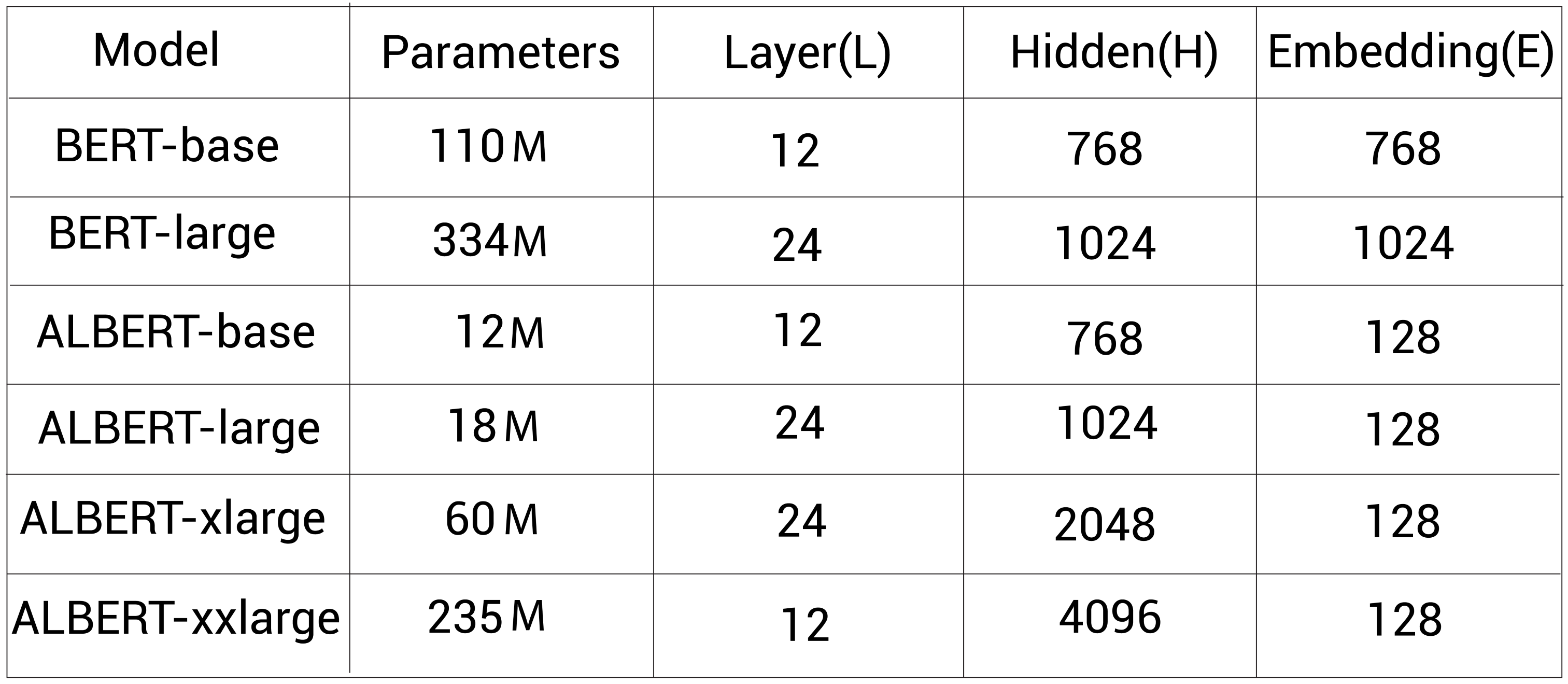
在训练之后,我们也能在任何下游任务上微调预训练的ALBERT模型。ALBERT-xxlarge模型比BERT-base和BERT-large在一些语言基准数据集上效果有不少的提升,其中包括SQuAD1.1、SQuAD2.0、MNLI SST-2和RACE数据集。
抽取ALBERT的嵌入
使用🤗的transformers,我们可以像我们使用BERT一样使用ALBERT。来看一个实例,假设我们需要抽取句子Paris is a beautiful city中每个单词的词嵌入向量。
首先导入需要的模块:
!pip install transformers sentencepiece
from transformers import AlbertTokenizer, AlbertModel
下载并加载预训练的ALBERT模型和分词器:
model = AlbertModel.from_pretrained('albert-base-v2')
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
然后将句子喂给分词器得到处理后的输入:
sentence = "Paris is a beautiful city"
inputs = tokenizer(sentence, return_tensors="pt")
print(inputs)
{'input_ids': tensor([[ 2, 1162, 25, 21, 1632, 136, 3]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
然后,我们直接把输入喂给模型就可以得到结果了。模型返回的hidden_rep包含最后一个编码器层的所有标记的隐藏状态表示;cls_head包含最后一个编码器层[CLS]标记的隐藏状态表示:
hidden_rep, cls_head = model(**inputs)
我们可以获得句子中每个标记的上下文单词嵌入:
-
hidden_rep[0][0]包含[CLS]标记的上下文嵌入 -
hidden_rep[0][1]包含Paris标记的上下文嵌入 -
hidden_rep[0][2]包含is标记的上下文嵌入
然后,我们也可以基于下游任务来微调ALBERT模型,下面我们来学习RoBERTa。
RoBERTa
RoBERTa是另一个流行的BERT变体,其作者们发现BERT是严重训练不足的并提出了一些预训练BERT模型的方法。RoBERTa通过以下改变来改善BERT的预训练:
- 在MLM任务中使用动态掩码而不是静态掩码
- 移除NSP任务,仅使用MLM任务
- 通过更大的批数据进行训练
- 使用BBPE作为分词器
使用动态掩码而不是静态掩码
我们知道在BERT的MLM任务中,我们随机对15%的标记进行掩码,然后让模型预测掩码的标记。
比如,假设我们有一个句子:We arrived at the airport in time。现在,在预处理后我们有:
tokens = [ [CLS], we, arrived, at, the, airport, in, time, [SEP] ]
接着,我们随机对15%的标记进行掩码:
tokens = [ [CLS], we, [MASK], at, the airport, in, [MASK], [SEP] ]
现在,我们将这些掩码后的标记列表喂给BERT模型并训练它去预测被掩码的标记。注意掩码操作只在预处理阶段进行一次,然后我们训练模型在不同的epoch中去预测这些已经掩码的标记。这被称为静态掩码。
RoBERTa使用动态掩码。我们举个例子来理解动态掩码。
首先,我们将句子复制10份,假设我们将给定的句子:We arrived at the airport in time复制了10份。接着,我们对所有的这10个同样的句子随机地对15%的标记进行掩码。所以,现在我们有10个被掩码的句子,其中每个句子被掩码的标记不同:

我们训练模型40个epoch。对于每个epoch,我们用不同标记被掩码的句子喂给模型。
比如epoch1,我们将句子1喂给模型;epoch2,我们将句子2喂给模型,如此循环重复:
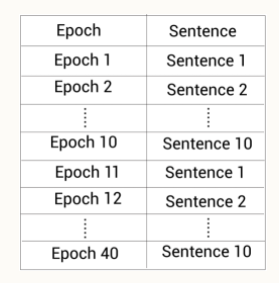
这样我们的模型只会在4个epoch中看到具有同样掩码标记的句子。比如,句子1会被epoch1,epoch11,epoch21和epoch31看到。这样,我们使用动态掩码而不是静态掩码去训练RoBERTa模型。
移除NSP任务
作者们发现NSP任务并不是对预训练BERT模型真的有用,因此他们在预训练RoBERTa时只使用MLM任务。为了证明可以移除NSP任务,他们进行了下面的实验:
- SEGMENT-PAIR+NSP: 和原始论文方法。每个输入是片段对,每个片段可以由多个自然句子组成,但是总的组合长度必须少于512;
- SENTENCE-PAIR+NSP:每个输入是一个一对自然句子,每个自然句子可是一个文本的连续部分,也可以是不同文本。因为这些输入显然少于512,因此增加了批大小,让一个批次总的单词数和SEGMENT-PAIR+NSP差不多。同时保留NSP loss;
- FULL-SENTENCES: 每个输入都包含从一个或多个文档中连续采样的完整句子,因此总长度差不多512个单词。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加文档边界标记。移除NSP loss;
- DOC-SENTENCES: 输入格式和FULL-SENTENCES类似,除了它们不会跨域文档边界。在文档末尾附近采样的输入可能短于 512 个单词,所以动态增加了批大小让单词总数和FULL-SENTENCES类似。移除NSP loss;
作者在上面四种设定中预训练BERT模型,并在几个不同的数据集中进行评估。下表显示了在SQuAD数据集中的F1得分,以及MNLI-m、SST-2和RACE数据集中的准确率得分:
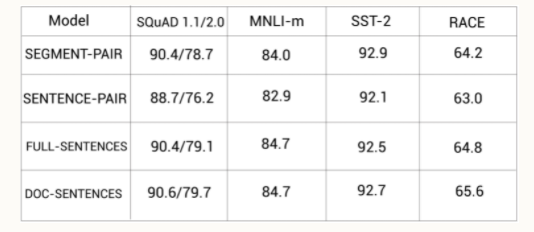
我们可以看到,BERT在FULL-SENTENCES和DOC-SENTENCES设定中表现的更好,这两者都没有NSP任务。
对比FULL-SENTENCES和DOC-SENTENCES,DOC-SENTENCES我们只从一篇文档中采样,此种设定的表现比FULL-SENTENCES在多篇文档中采样要好。但在RoBERTa中,作者使用了FULL-SENTENCES,因为DOC-SENTENCES导致批大小变化很大。
通过更多的数据训练
RoBERT除了在Toronto BookCorpus和英文维基百科上进行训练,还在CC-News(Common Crawl-News)数据集、Open WebText和Stories(Common Crawl的子集)上进行训练。
这样,RoBERT模型在5个数据集上进行预训练,这5个数据集总大小为160G。
通过更大的批大小训练
我们知道BERT训练时的批大小是256,训练了1M步。训练RoBERTa时采样了更大的批大小,达到了8000,训练了300000步。在同样的批大小上,也训练了一个更长训练步的版本,有500000步。
训练一个更大的批大小可以增加训练速度同时也可以优化模型的表现。
使用BBPE作为分词器
我们知道BERT使用WordPiece分词器。WordPicce分词器类似于BPE分词器,它基于符号对的概率还不是频率来合并符号对。
而RoBERTa使用BBPE作为分词器。我们已经在文章是时候彻底弄懂BERT模型了中学习了BBPE的原理。BBPE基于字节级序列,我们知道BERT使用大于30000大小的词表,但RoBERTa使用大约50000大小的词表。
深入RoBERTa分词器
我们本节中通过实际代码来理解这个分词器。
首先导入需要的模块:
from transformers import RobertaConfig, RobertaModel, RobertaTokenizer
下载并加载预训的RoBERTa模型:
model = RobertaModel.from_pretrained('roberta-base')
我们来看一下这个RoBERTa模型的配置:
print(model.config)
RobertaConfig {
"_name_or_path": "roberta-base",
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"classifier_dropout": null,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.10.3",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 50265
}
我们可以看到这个RoBERTa模型有12个编码器层,12个注意力头和768大小的隐藏层。
现在我们加载RoBERTa分词器:
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
然后我们对句子: It was a great day进行分词:
tokenizer.tokenize('It was a great day')
['It', 'Ġwas', 'Ġa', 'Ġgreat', 'Ġday']
这个符号Ġ是什么?它用于显示一个空格。RoBERTa分词器使用该符号替换所有的空格。我们还可以发现这个符号在句子中所有的标记前出现,除了第一个标记。因为只有第一个标记前面没有空格,而所有其他标记前都有空格。我们可以在句子第一个标记前面增加额外的空格来看看效果:
tokenizer.tokenize(' It was a great day')
['ĠIt', 'Ġwas', 'Ġa', 'Ġgreat', 'Ġday']
我们再来看一个不同的例子:
tokenizer.tokenize('I had a sudden epiphany')
['I', 'Ġhad', 'Ġa', 'Ġsudden', 'Ġep', 'iphany']
从中我们可以看到单词epiphany被拆分为子词ep和iphany,我们也可以发现只有ep前面才有符号Ġ。
ELECTRA
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)是另一个BERT的有趣的变体。ELECTRA没有使用MLM任务,而是使用一个叫做替换标记检测(replaced token detection)任务。
做替换标记检测任务与MLM任务非常像,但是它不是使用[MASK]去对某个标记进行掩码,而是使用不同的标记去替换原来的标记,并训练模型去判断该标记是否被替换过(分类任务)。
为什么要这么做呢?一个可能的原因是由于MLM任务在预训练期间引入了[MASK]标记,而在微调下游任务时没有[MASK]标记。这导致了预训练和微调的一种不匹配。在替换标记检测任务中,没有使用任何[MASK]标记来做掩码,仅仅是通过不同的标记进行替换,这解决了这种不匹配问题。
和BERT不同的是,BERT在预训练时同时使用了MLM和NSP任务,而ELECTRA仅使用替换标记检测任务。那么这个任务是怎么做的呢,我们要替换哪个标记呢?
理解替换标记检测任务
还是通过实例来理解。考虑句子:The chef cooked the meal。在分词后,我们有:
tokens = [ The, chef, cooked, the, meal]
我们先用a替换第一个标记the,以及用ate替换第三个标记cooked。这样,我们得到了:
tokens = [ a, chef, ate, the, meal]
这里我们替换了两个标记。现在,我们训练BERT模型去判断句子中的标记是否被替换。我们可以成这个BERT模型为判别器(discriminator)模型,因为它知识判断标记是否被替换了。
如下图所示,我们将上面的标记喂给这个判别器,然后它返回标记是否被替换了,如果被替换则返回replaced,否则orignial:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VxEBcy6a-1632669150936)(https://learning.oreilly.com/api/v2/epubs/urn:orm📖9781838821593/files/assets/e7e1b49d-6ab5-4bea-bf48-d0e44592d038.png)]
现在问题是,在将这些标记输入给判别器之前,我们要如何替换这些标记呢?为了做到这一点,我们使用MLM任务。考虑原始的句子:The chef cooked the meal。在分词后,我们有:
tokens = [ The, chef, cooked, the, meal]
现在我们随机地对15%的标记进行掩码,得到:
tokens = [ [MASK] , chef, [MASK] ,the, meal]
接下来,我们把上面的标记喂给另一个BERT模型,让这个模型来预测被掩码的标记。我们称这个BERT模型为生成器(generator),因为它返回所有标记的概率分布。我们可以从下图中看到,我们将掩码后的标记喂给生成器,然后它选择概率最大的标记来预测被掩码的标记:
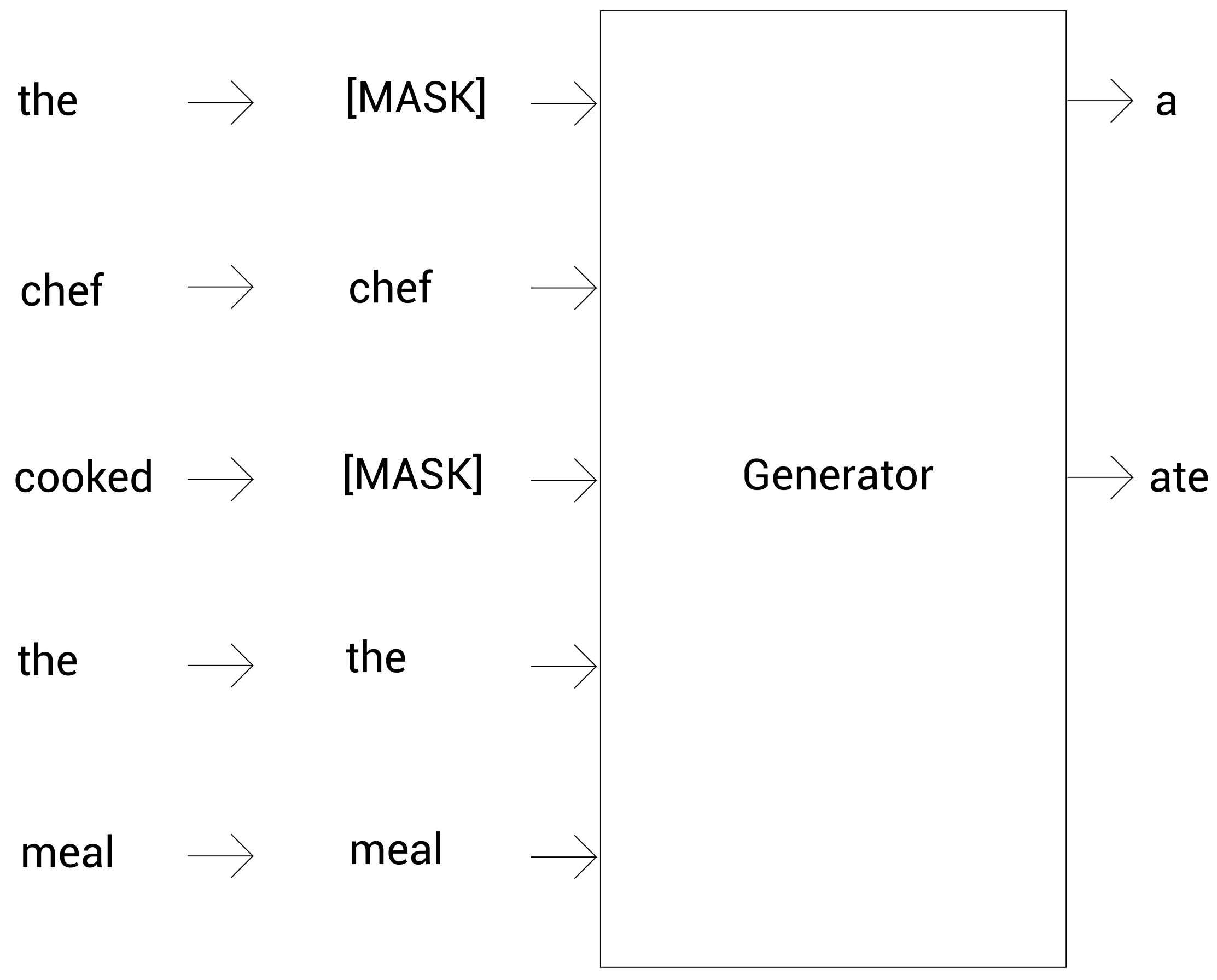
从上图可以看到,我们知道生成器把掩码后的the和cooked预测为a和ate。现在,我们把生成器预测后的标记和原来的标记放到一起(用预测的替换[MASK]标记),得到:
tokens = [ a, chef, ate, the, meal]
现在,我们将上面的标记喂给判别器,训练它来判断标记是否被替换过。
总结以下,整个流程如下图,首先我们随机地对标记进行掩码,然后把掩码后的结果喂给生成器。让生成器对[MASK]进行预测,并用它预测的标记替换[MASK],作为判别器的输入,然后判别器来判断每个输入的标记是否被替换过。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zQyA7wvt-1632669150938)(https://learning.oreilly.com/api/v2/epubs/urn:orm📖9781838821593/files/assets/d7dac08e-d836-48ab-98cf-01b81cdd4949.png)]
这里的判别器基本上就是ELECTRA模型,在训练完成之后,我们可以移除生成器只用判别器作为ELECTRA模型。
深入ELECTRA的生成器和判别器
首先,我们来看生成器。我们知道生成器利用MLM任务。我们随机地以15%的概率对标记进行掩码,然后训练生成器来预测掩码的标记。假设输入标记记为 X = [ x 1 , x 2 , ⋯ , x n ] X=[x_1,x_2,\cdots,x_n] X=[x1,x2,⋯,xn]。我们随机地掩码一些标记并喂给生成器,生成器返回每个标记的表示向量。记 h G ( X ) = [ h 1 , h 2 , ⋯ , h n ] h_G(X)=[h_1,h_2,\cdots,h_n] hG(X)=[h1,h2,⋯,hn]代表生成器返回的每个标记的表示。
现在,我们将掩码的标记表示喂给一个分类器,它基本上是有Softmax函数的前馈神经网络,它会返回所有标记被预为掩码标记的概率分布。
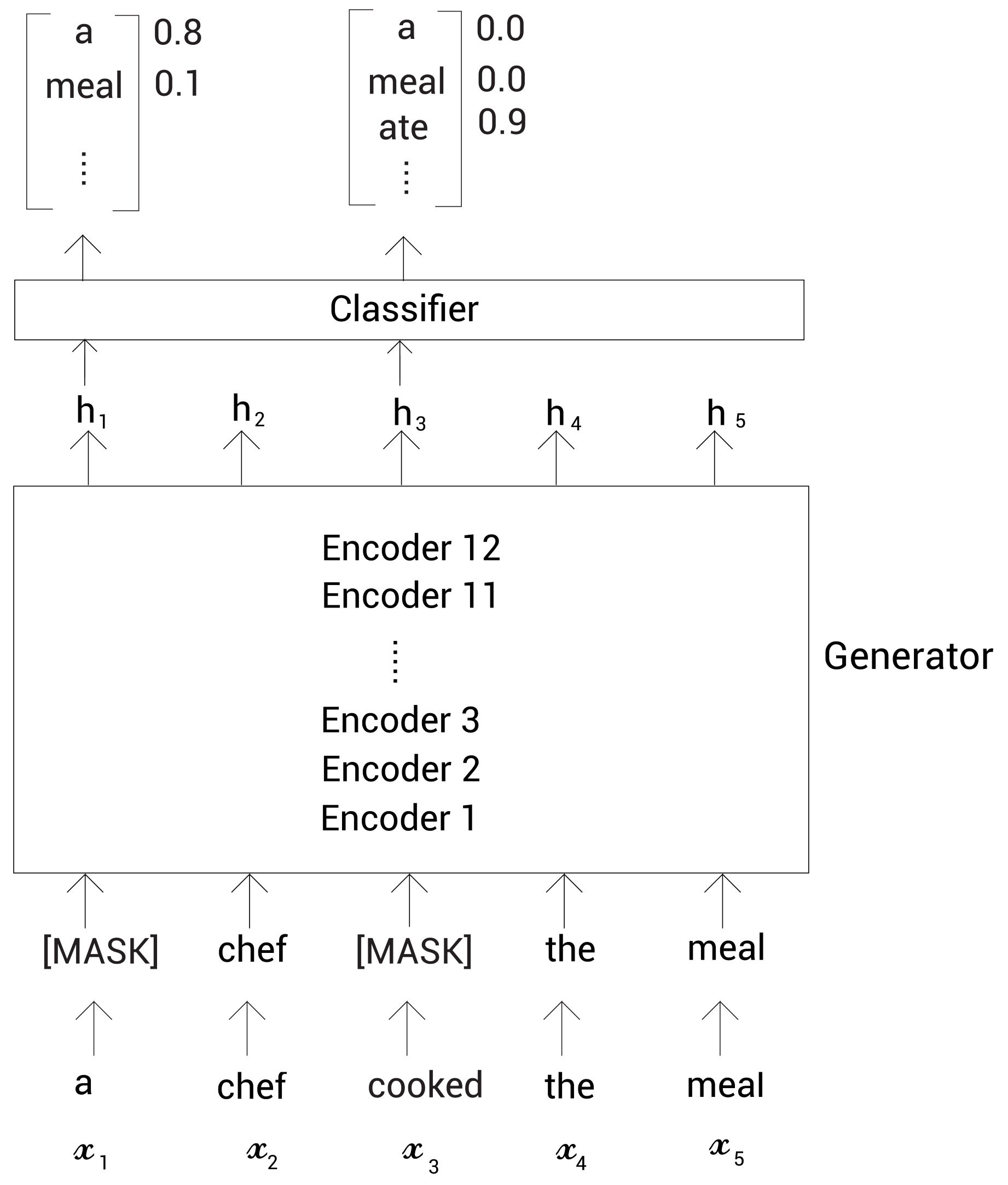
令
x
t
x_t
xt为位置
t
t
t上的被掩码的单词;然后生成器返回词表中每个单词作为被掩码单词的概率:
P
G
(
x
t
∣
X
)
=
exp
(
e
(
x
t
)
T
h
G
(
X
)
t
)
∑
x
′
exp
(
e
(
x
′
)
T
h
G
(
X
)
t
)
P_G(x_t|X) = \frac{\exp(e(x_t)^T h_G(X)_t)}{\sum_{x^\prime} \exp(e(x^\prime)^Th_G(X)_t)}
PG(xt∣X)=∑x′exp(e(x′)ThG(X)t)exp(e(xt)ThG(X)t)
在上面的式子中,
e
(
⋅
)
e(\cdot)
e(⋅)代表标记嵌入。从生成器中得到了单词的概率分布后,我们从中选择概率最大的单词预测为掩码标记。以上图为例,基于概率分布,掩码标记
x
1
x_1
x1被预测为a,掩码标记
x
3
x_3
x3被预测为ate。然后,我们用被预测的单词去替换掩码标记,然后喂给判别器。
现在,我们来看下判别器。
我们知道判别器的目标是判断给定的标记是否被替换过了。首先,我们将标记列表喂给判别器,它会返回每个标记的表示。令 h D ( X ) = [ h 1 , h 2 , ⋯ , h n ) ] h_D(X)=[h_1,h_2,\cdots,h_n)] hD(X)=[h1,h2,⋯,hn)]代表由生成器返回的每个标记表示。接下来,我们把这些标记表示喂给一个分类器,它就是一个有Sigmoid函数的前馈神经网络,由它来判断每个标记是否被替换过。
生成器如下图所示。
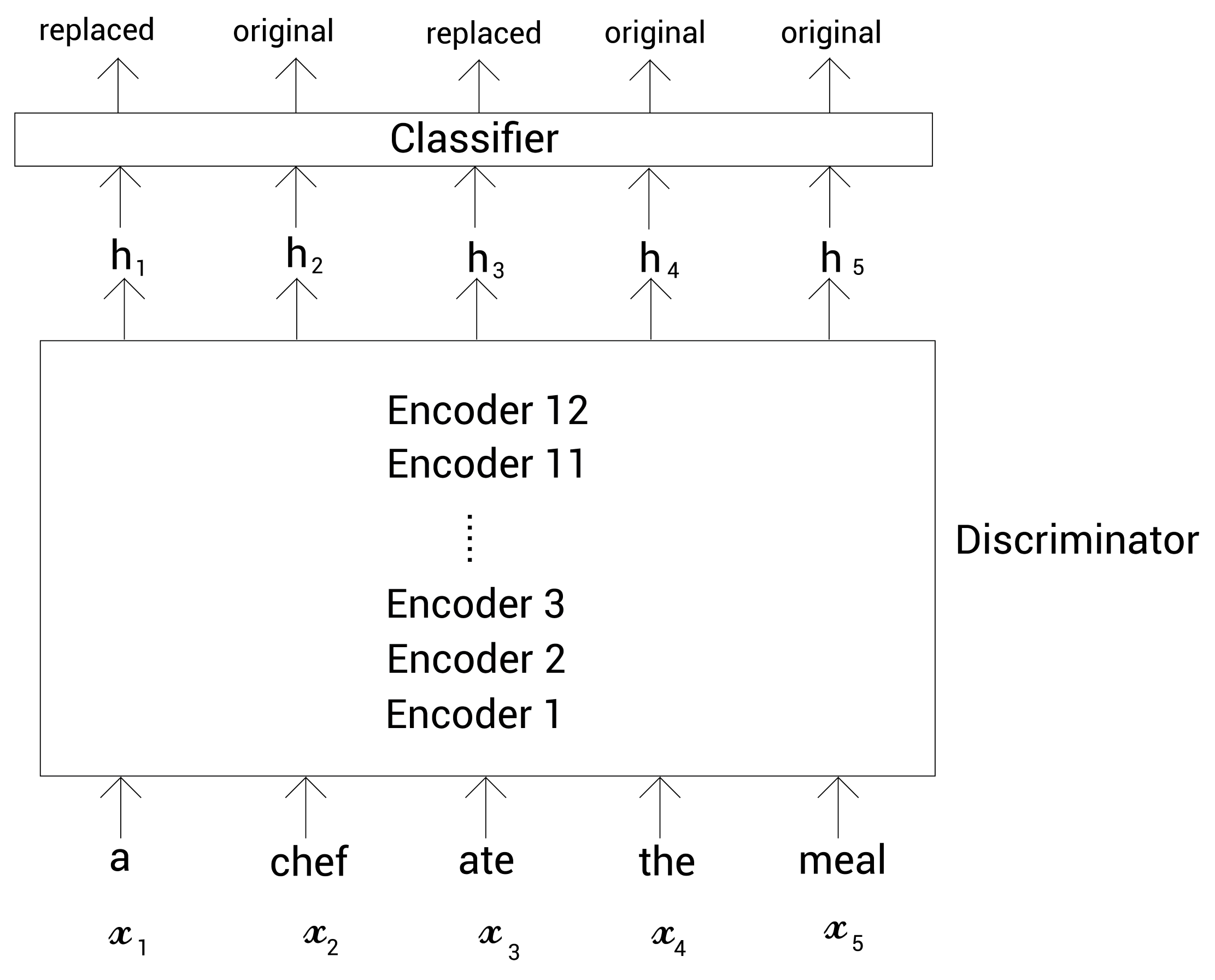
令
x
t
x_t
xt为位置
t
t
t上的标记;然后判别器返回该标记是原始标记还是被替换的标记:
D
(
X
,
t
)
=
Sigmoid
(
w
T
h
D
(
X
)
t
)
D(X,t) = \text{Sigmoid}(w^Th_D(X)_t)
D(X,t)=Sigmoid(wThD(X)t)
总结来说,我们将掩码标记喂给生成器,然后由生成器来预测这些掩码标记。接着,我们用生成器预测的单词替换它输入中的掩码,然后喂给判别器。由判别器来判断输入的每个标记是否被替换过:
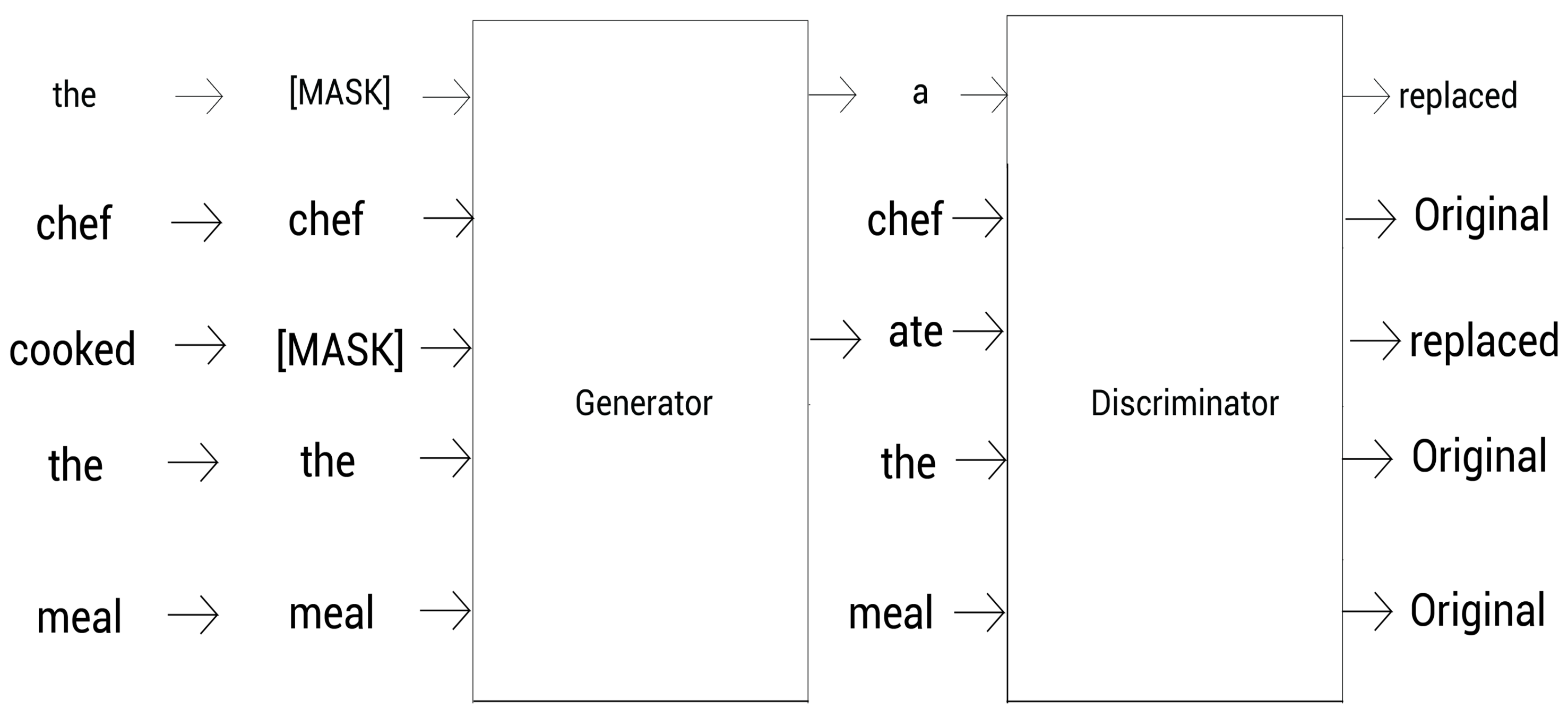
判别器BERT就是ELECTRA模型。这里了,我们训练这个判别器BERT去判断给定的标记有没有被替换过。因此它的全名是:高效地学习一个能准确分类替换标记的编码器(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)。
ELECTRA相比于BERT的一个优点是,在BERT中,我们使用MLM作为训练目标,其中我们随机对15%的标记进行掩码,所以对于模型的训练信号只是这些15%被掩码的标记。但在ELECTRA中,训练信号是所有的标记,因为该模型需要判断所有给定的标记是否被替换。
训练ELECTRA模型
生成器还是通过MLM任务训练。所以,给定一个输入,
X
=
[
x
1
,
x
2
,
⋯
,
x
n
]
X=[x_1,x_2,\cdots,x_n]
X=[x1,x2,⋯,xn],我们随机地选择一些位置用于掩码。令
M
=
[
m
1
,
m
2
,
⋯
,
m
n
]
M=[m_1,m_2,\cdots,m_n]
M=[m1,m2,⋯,mn]代表选择用来掩码的位置。这样,我们通过[MASK]标记来替换这些选择的位置,可以表示如下:
X
masked
=
Replace
(
X
,
M
,
[MASK]
)
X^{\text{masked}} = \text{Replace}(X, M,\text{[MASK]})
Xmasked=Replace(X,M,[MASK])
在掩码之后,我们将
X
masked
X^{\text{masked}}
Xmasked标记喂给生成器,由其来预测被掩码的标记。
现在,我们用生成器生成的标记替换输入 X X X中的一些标记。我们记为 X corrupted X^{\text{corrupted}} Xcorrupted,因为它包含由生成器替换的标记。
那么生成器的损失函数可以表示为:
L
G
(
X
,
θ
G
)
=
E
(
∑
i
∈
m
−
log
P
G
(
x
i
∣
X
masked
)
)
L_G(X,\theta_G) = E\left(\sum_{i \in m} -\log P_G(x_i|X^{\text{masked}})\right)
LG(X,θG)=E(i∈m∑−logPG(xi∣Xmasked))
我们将替换的标记
X
corrupted
X^{\text{corrupted}}
Xcorrupted喂给判别器。判别器的损失函数表示如下:
L
D
(
X
,
θ
D
)
=
E
(
∑
t
=
1
n
−
1
(
x
t
corrput
=
x
t
)
log
D
(
X
corrput
,
t
)
−
1
(
x
t
corrput
≠
x
t
)
log
(
1
−
D
(
X
corrput
,
t
)
)
)
L_D(X,\theta_D) = E\left( \sum_{t=1}^n -1(x_t^{\text{corrput}}=x_t)\log D(X^{\text{corrput}},t) -1(x_t^{\text{corrput}} \neq x_t)\log \left(1-D(X^{\text{corrput}},t)\right) \right)
LD(X,θD)=E(t=1∑n−1(xtcorrput=xt)logD(Xcorrput,t)−1(xtcorrput=xt)log(1−D(Xcorrput,t)))
我们通过最小化生成器和判别器的组合损失来训练ELECTRA模型:
min
θ
D
,
θ
G
∑
X
∈
X
L
G
(
X
,
θ
G
)
+
λ
L
D
(
X
,
θ
D
)
\min_{\theta_D,\theta_G} \sum_{X \in \Bbb{X}} L_G(X,\theta_G) + \lambda L_D(X,\theta_D)
θD,θGminX∈X∑LG(X,θG)+λLD(X,θD)
在上面的公式中,
θ
G
\theta_G
θG和
θ
D
\theta_D
θD表示生成器和判别器的参数,
X
\Bbb{X}
X表示大文本预料库。
探索有效的训练方法
为了能高效地训练ELECTRA模型,我们可以共享生成器和判别器之间的权重。即,如果生成器和判别器都有同样的维度,那么我们就可以共享它们的编码器。
但是问题是,如果生成器和判别器是同样的维度,那么会增加训练时间,为了避免这个问题,我们可以使用一个小一点的生成器。当生成器是一个相对小的模型时,我们可以仅共享生成器和判别器之间的嵌入层(标记和位置嵌入)。这种生成器和判别器之间的嵌入层绑定能最小化训练时间。
预训练的ELECTRA可以从 https://github.com/google-research/electra 下载,它有三种大小的配置:
- ELECTRA-small: 12个编码器层和256隐藏层大小
- ELECTRA-base: 12个编码器层和768隐藏层大小
- ELECTRA-large: 24个编码器层和1024隐藏层大小
我们也可以通过transformers包来加载ELECTRA模型,就是我们加载BERT模型一样:
from transformers import ElectraTokenizer, ElectraModel
假设我们使用ELECTRA-small的判别器模型,那么我们可以这样加载预训练的ELECTRA-small判别器:
model = ElectraModel.from_pretrained('google/electra-small-discriminator')
假设我们想使用ELECTRA-small的生成器模型,我们可以这样加载:
model = ElectraModel.from_pretrained('google/electra-small-generator')
使用SpanBERT预测片段
SpanBERT是另一种BERT的变体。
这里的Span翻译为“片段”,表示一片连续的单词。
SpanBERT最常用于需要预测文本片段的任务,像问答。
理解SpanBERT的结构
举个例子。考虑下面的句子:
You are expected to know the laws of your country
在分词后,我们有:
tokens = [ you, are, expected, to, know, the, laws, of, your, country]
在SpanBERT中,不是对标记进行随机掩码,而是对连续片段进行掩码,如下:
tokens = [ you, are, expected, to, know, [MASK], [MASK], [MASK], [MASK], country]
现在我们将上面的标记喂给SpanBERT并得到得到标记的表示。如下图所示:
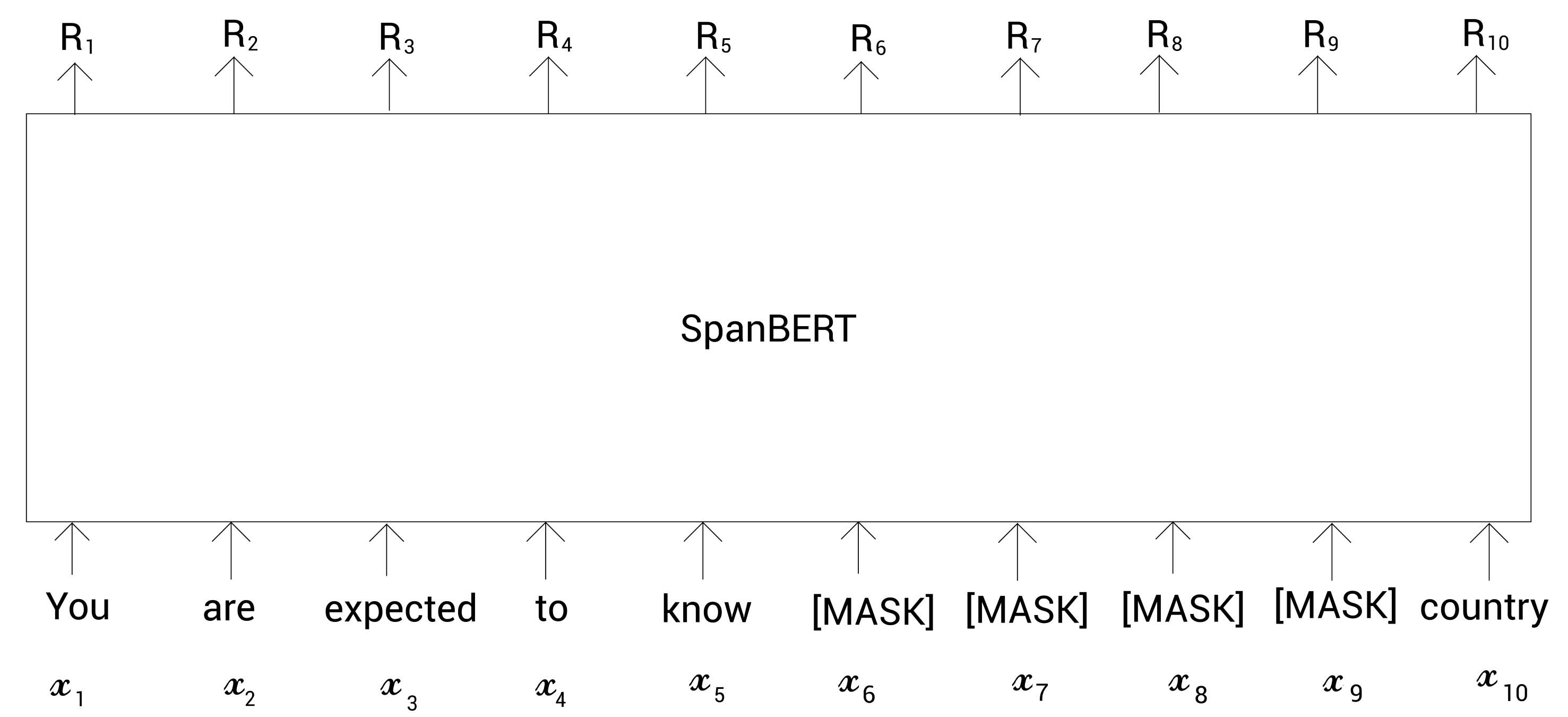
为了预测掩码标记,我们用MLM目标函数以及一个新的叫片段边界目标(span boundary objective,SBO)的目标函数训练SpanBERT。
我们知道在MLM中,为了预测掩码标记,我们的模型利用的相应掩码标记的表示。假设我们需要预测掩码标记 x 7 x_7 x7,所以,利用对应的表示 R 7 R_7 R7,我们能预测被掩码的标记。只需要将表示 R 7 R_7 R7喂给一个分类器,它会返回词表中每个单词属于这个掩码标记的概率。
现在,我们来看SBO。在SBO中,为了预测任何掩码标记,不是使用掩码标记对应的表示,而是仅仅使用片段边界上的标记表示。片段边界就是片段的前一个标记和后一个标记。
比如,如下图所示,我们可以看到标记 x 5 x_5 x5和 x 10 x_{10} x10代表在片段边界上的标记,而 R 5 R_5 R5和 R 10 R_{10} R10是片段边界上每个标记的表示。现在,为了预测任何掩码的标记,我们的模型仅使用这两个标记。这里,为了预测掩码的标记 x 7 x_7 x7,我们的模型仅使用片段边界标记表示 R 5 R_5 R5和 R 10 R_{10} R10。
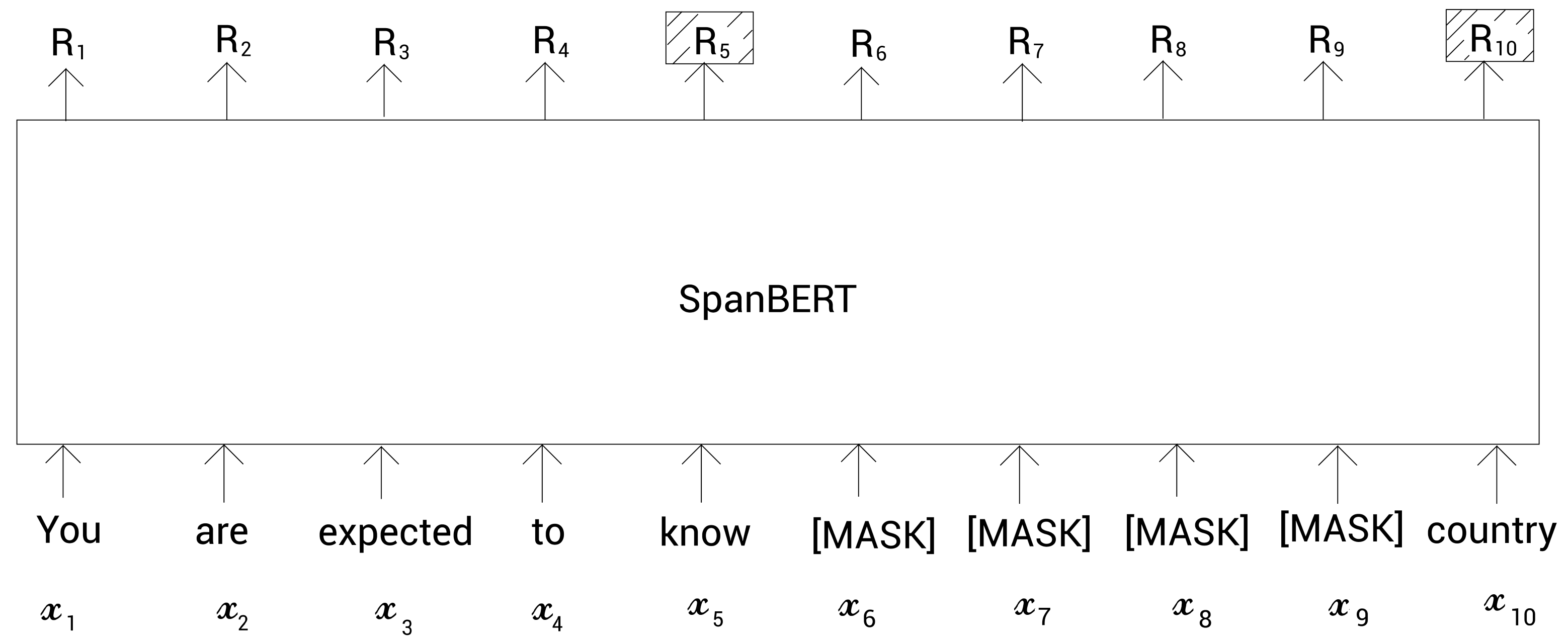
问题是如果模型只使用片段边界标记表示来预测任何掩码的标记,那它是如何区分不同的被掩码的标记呢?比如,为了预测掩码的标记 x 6 x_6 x6,我们的模型只使用片段边界标记表示 R 5 R_5 R5和 R 10 R_{10} R10,然后为了预测掩码的标记 x 7 x_7 x7,我们的模型还是使用 R 5 R_5 R5和 R 10 R_{10} R10。那这样的话,模型如何区别不同的掩码标记呢?
因此,除了片段边界标记表示,模型还使用掩码标记的位置嵌入信息。这里的位置嵌入代表了掩码标记的相对位置。即,假设我们要预测掩码标记 x 7 x_7 x7。现在,在所有的掩码标记中,我们检查掩码标记 x 7 x_7 x7的位置。如下图所示,掩码标记 x 7 x_7 x7是所有掩码标记的第二个位置。所以现在,除了使用片段边界标记表示,我们也使用该掩码标记的位置嵌入,即 P 2 P_2 P2:
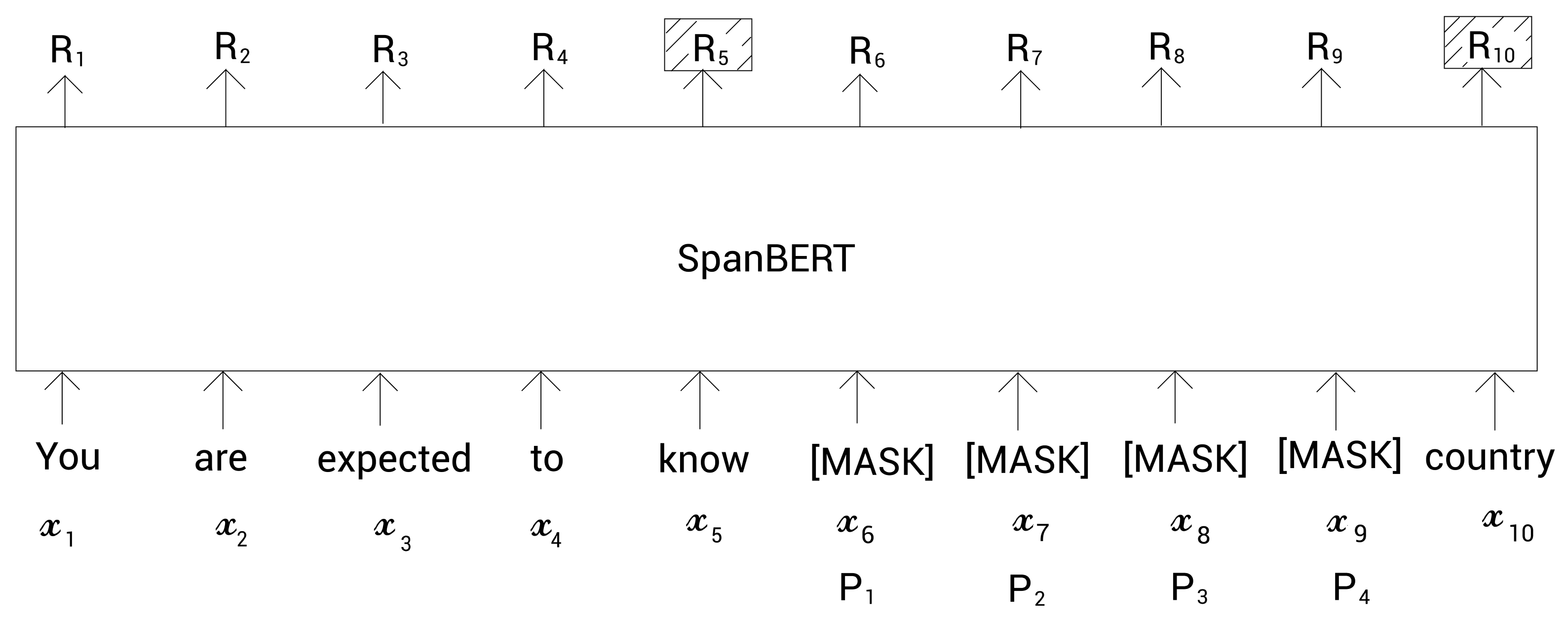
这样,SpanBERT使用了两个目标函数:MLM和SBO。
深入SpanBERT
我们知道在SpanBERT中,我们对句子中一个连续的标记片段进行掩码。另 x s x_s xs和 x e x_e xe分别表示掩码片段的开始和结束标记。我们将这些标记喂给SpanBERT,它也是返回每个标记的向量表示。标记 i i i的向量表示是 R i R_i Ri。在片段边界中的标记表示记为 R s − 1 R_{s-1} Rs−1和 R e + 1 R_{e+1} Re+1。
我们先看SBO目标。为了预测掩码标记 x i x_i xi,我们使用三个值,即片段边界中的标记表示 R s − 1 R_{s-1} Rs−1和 R e + 1 R_{e+1} Re+1,以及掩码标记 P i − s + 1 P_{i-s+1} Pi−s+1的位置嵌入。那如何利用这三个值来预测掩码标记呢?
首先,我们使用一个函数
f
(
⋅
)
f(\cdot)
f(⋅)创建一个新的表示叫做
z
i
z_i
zi,该函数的输入就是这三个值:
z
i
=
f
(
R
s
−
1
,
R
e
+
1
,
P
i
−
s
+
1
)
z_i = f(R_{s-1},R_{e+1},P_{i-s+1})
zi=f(Rs−1,Re+1,Pi−s+1)
那
f
(
⋅
)
f(\cdot)
f(⋅)函数是什么?它基本上是一个有GeLU激活函数的两层前馈神经网络:
h
o
=
[
R
s
−
1
;
R
e
+
1
;
p
i
−
s
+
1
]
h
1
=
LayerNorm
(
GeLU
(
W
1
h
0
)
)
z
i
=
LayerNorm
(
GeLU
)
(
W
2
h
1
)
h_o = [R_{s-1};R_{e+1};p_{i-s+1}]\\ h_1 =\text{LayerNorm}(\text{GeLU}(W_1h_0))\\ z_i = \text{LayerNorm}(\text{GeLU})(W_2h_1)
ho=[Rs−1;Re+1;pi−s+1]h1=LayerNorm(GeLU(W1h0))zi=LayerNorm(GeLU)(W2h1)
现在,为了预测掩码标记
x
i
x_i
xi,我们只要使用表示
z
i
z_i
zi即可。我们将
z
i
z_i
zi喂给一个分类器,它返回预测的词表中所有单词的概率分布。
在MLM目标中,为了预测掩码标记 x i x_i xi,我们只要使用标记标记 R i R_i Ri即可。将 R i R_i Ri喂给一个分类器,它返回预测的词表中所有单词的概率分布。
SpanBERT的损失函数是MLM损失和SBO损失的总和。我们通过最小化这个损失函数来训练SpanBERT。在预训练之后,我们可以把预训练的SpanBERT用于任何下游任务。
基于预训练的SpanBERT完成问答任务
我们本节学习如何使用预训练的SpanBERT在问答任务上进行微调5。
我们使用🤗transformers 的pipelineAPI。pipeline是由transformers提供的简单的能无缝处理从文本分类到问答这样的复杂任务。
在本节中,我们会学到如何使用pipeline来完成问答任务。
首先,还是要引入pipeline:
from transformers import pipeline
现在,我们定义问答pipeline,我们传入我们想要完成的任务名称,这里是问答question-answering,和使用的预训练模型,mrm8488/spanbert-large-finetuned-squadv2以及对应的分词器:
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/spanbert-large-finetuned-squadv2",
tokenizer="SpanBERT/spanbert-large-cased"
)
现在,我们只需要输入问题和上下文到pipeline中,它就会返回问题的答案:
results = qa_pipeline({
'question': "What is machine learning?",
'context': "Machine learning is a subset of artificial intelligence. It is widely for creating a variety of applications such as email filtering and computer vision"
})
我们输出答案看看:
print(results['answer'])
a subset of artificial intelligence
其实用起来就像端到端模型一样。通过这种方式,SpanBERT在需要预测文本片段的任务中非常受欢迎。



















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











