






 本文介绍了网易有道的HiEcho口语教练,其提供专业对话练习;可栗英语以其流畅对话和准确发音助力备考;一码千言AI平台涵盖多领域语言工具;文心一言免费但AI语音不够自然;BubbleAI则以沉浸式学习吸引孩子。这些AI应用在提升口语能力方面各有特色。
本文介绍了网易有道的HiEcho口语教练,其提供专业对话练习;可栗英语以其流畅对话和准确发音助力备考;一码千言AI平台涵盖多领域语言工具;文心一言免费但AI语音不够自然;BubbleAI则以沉浸式学习吸引孩子。这些AI应用在提升口语能力方面各有特色。
一、Hi Echo口语教练
Hi Echo是网易有道发布的搭载子日教育大模型的全球首个虚拟人口语教练。为你提供随时随地的一对一口语练习,覆盖多个对话场景和话题,比真人口语教练更专业地道;提供对话分数及完整对话评测报告,帮助快速提升口语能力。

Hi Echo是24小时随时随地可以使用,以对话的方式进行口语练习,提供口语对话条件和环境类真人,循循善诱,不断发问引导用户多轮对话,属实是社恐练口语的救星。
而且新用户注册可以免费使用五分钟,连续包月是68元/月,连续包年是498元/月,相当于一节外教课的钱获得了一年的口语教练。

二、可栗英语
"可栗英语"是一款具有高度智能化的英语对话AI应用,既可以在app中使用,也可以在微信小程序中找到它。这款应用的对话流畅性令人惊艳,不仅如此,它的发音准确且自然,仿佛真人在你耳边细语。而对于正在备考雅思口语的学生来说,"可栗英语"更是一位得力的助手,提供了针对性的练习内容。
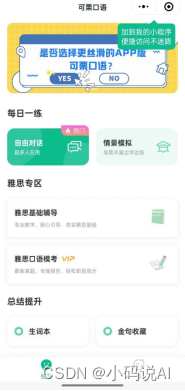
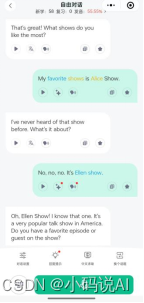
虽然"可栗英语"无法生成分析报告,但它提供了回顾聊天记录的功能,使用户能够随时查看并复习自己的对话内容,从而更好地掌握英语口语。
另外,"可栗英语"的部分功能是完全免费的,即使不开通会员,每天也能免费使用20句对话,这对大多数人来说已经足够。而且,新用户可以领取24小时的试用VIP,且每天用户可以免费使用十几分钟,足以满足日常的学习需求。
三、一码千言AI平台
一码千言AI平台是利用AIGC技术为用户精心打造的工作、学习、生活一体化集成平台。围绕文案、科研、英语、心理、法律、就业等领域设计了近百种种应用工具,总有一款适合您!
、
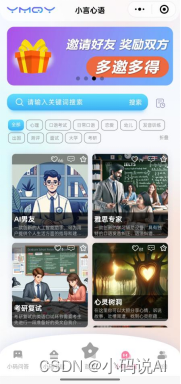
其中,它的小言心语栏目,无论是在网站还是微信小程序中的表现,都是一个极其全面的语言AI平台,所有产品的对话都是通过语音交流进行的。并且通过签到即可免费使用到其中的工具,且语言功能覆盖面还广泛,主打一个效率高且实用。而且,里面的栏目和内容还在不断更新中哦。
四、文心一言
文言一心也是一款极具特色的语言学习应用。用户只需轻松点击“发现”栏目,再选择“英语”选项,就能轻松开启英语对话的学习旅程。

它目前完全免费提供服务,且支持用户回看学习内容,这无疑为英语学习者提供了极大的便利和帮助。但该应用的AI语音对话系统有些许不够自然,机器感较为明显,这可能会影响用户的学习体验。此外,该应用还暂时缺乏纠音润色等附加功能,这对于追求完美发音的用户来说,可能会感到些许遗憾。
然而,无论优点还是缺点,都不能否认的是,文言一心APP为我们的英语学习提供了一个全新的平台和可能。
五、Bubble AI
Bubble AI是一款好玩又有效的英语口语学习软件,备受欢迎。进入软件的第一感受是——这是孩子们会喜欢的沉浸式英语对话语景应用。打开软件就是可以滑动的几个卡通角色(朵拉、小猪佩奇、哈利波特、蛋仔等)口语练习对象,亲切可爱的IP角色陪你一起练习英语,还有专属于IP的话题让熟悉动画片的中小学生练习口语对话更有趣味。

针对不同口语能力的用户,通过AI智能口语陪练,能够打分和纠正口语发音,还可以通过学情报告复习英语常用语料中的单词、词法、情景、语境等知识要点,以快速告别哑巴英语。


















 2037
2037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









