







实现2个矩阵(Width=2048, Height=1024)的相加,输入的矩阵A,B按照以下要求初始化,矩阵A的初始值全为本人学号的最后1位数字,矩阵B的初始值全为本人学号的倒数第2位数字。同时用CPU代码实现,比较两个代码的运行时间。
- 用二维线程结构来计算矩阵加法,每一个线程对应一个矩阵元素
线程配置
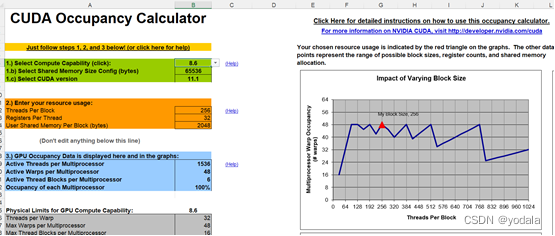
从上图得出我的计算机在每个Block有128,256,512个线程时,资源利用率最大。
int nx = 2048;
int ny = 1024;
dim3 threadsPerBlock(16, 16);
dim3 blocksPerGrid((nx - 1) / 16+1, (ny - 1) /16+1); //dim3 blocksPerGrid(128,64)
实验设备
设备名称与型号,显存大小,含有的SM数量,CUDA CORE数量,计算能力。
可以使用以下代码查看需要的信息。
void GetDeviceInfo()
{
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, 0);
printf("Device 0 information:\n");
printf("设备名称与型号: %s\n", deviceProp.name);
printf("显存大小: %d MB\n", (int)(deviceProp.totalGlobalMem / 1024 / 1024));
printf("含有的SM数量: %d\n", deviceProp.multiProcessorCount);
printf("CUDA CORE数量: %d\n", deviceProp.multiProcessorCount * 128);
printf("计算能力: %d.%d\n", deviceProp.major, deviceProp.minor);
}
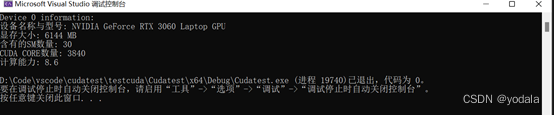
也可用调用deviceQuery.exe查看详情。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <chrono>
#include <cuda_runtime.h>
#include <stdio.h>
#include <iostream>
using namespace std;
//检查返回是否正确
void CHECK(cudaError error)
{
if(error!=cudaSuccess)
{
printf("ERROR: %s:%d,",__FILE__,__LINE__);
printf("code:%d,reason:%s\n",error,cudaGetErrorString(error));
exit(1);
}
}
void initDevice(int devNum)
{
int dev = devNum;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
}
//按照学号初始化矩阵
void initialMatrix(float* ip, int s, const int t)
{
if (t == 0)
{
for (int i = 0; i < s; i++)
{
ip[i] = 0.0;
}
}
else if (t == 1)
{
for (int i = 0; i < s; i++)
{
ip[i] = 6.0;
}
}
else
{
for (int i = 0; i < s; i++)
{
ip[i] = 0.0;
}
}
}
void checkResult(float* host, float* device, const int N)
{
double epsilon = 1.0E-8;
for (int i = 0; i < N; i++)
{
if (abs(host[i] - device[i]) > epsilon)
{
printf("Not match!\n");
printf("%f(host[%d])!= %f(device[%d])\n", host[i], i, device[i], i);
return;
}
}
printf("Match\n");
}
//CPU运行同样的矩阵加法,对比host和device的运行速度
void sumMatrix2DonCPU(float* MatA, float* MatB, float* MatC, int nx, int ny)
{
float* a = MatA;
float* b = MatB;
float* c = MatC;
for (int j = 0; j < ny; j++)
{
for (int i = 0; i < nx; i++)
{
c[i] = a[i] + b[i];
}
c += nx;
b += nx;
a += nx;
}
}
__global__ void sumMatrix(float* MatA, float* MatB, float* MatC, int nx, int ny)
{
int ix = threadIdx.x + blockDim.x * blockIdx.x;
int iy = threadIdx.y + blockDim.y * blockIdx.y;
int idx = ix + iy * nx;
if (ix < nx && iy < ny)
{
MatC[idx] = MatA[idx] + MatB[idx];
}
}
int main(int argc, char** argv)
{
//设备初始化
printf("strating...\n");
initDevice(0);
//输入二维矩阵,2048*1024,单精度浮点型。
int nx = 2048;
int ny = 1024;
int size = nx * ny * sizeof(float);
//Malloc,分配host内存
float* A_host = (float*)malloc(size);
float* B_host = (float*)malloc(size);
float* C_host = (float*)malloc(size);
float* C_from_gpu = (float*)malloc(size);
initialMatrix(A_host, nx * ny, 0);
initialMatrix(B_host, nx * ny, 1);
//cudaMalloc,分配device内存
float* A_dev = NULL;
float* B_dev = NULL;
float* C_dev = NULL;
CHECK(cudaMalloc((void**)&A_dev, size));
CHECK(cudaMalloc((void**)&B_dev, size));
CHECK(cudaMalloc((void**)&C_dev, size));
//输入数据从host拷贝到device
CHECK(cudaMemcpy(A_dev, A_host, size, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(B_dev, B_host, size, cudaMemcpyHostToDevice));
dim3 threadsPerBlock(16, 16);
cout << "threadsPerBlock.x = " << threadsPerBlock.x << endl;
cout << "threadsPerBlock.y = " << threadsPerBlock.y << endl;
dim3 blocksPerGrid((nx - 1) / 16 + 1, (ny - 1) / 16 + 1);
cout << "blocksPerGrid.x = " << blocksPerGrid.x << " blocksPerGrid.y=" << blocksPerGrid.y << endl;
//测试GPU执行时间
//double gpuStart = cpuSecond();
//将核函数放在线程网格中执行
auto beforeTime = std::chrono::steady_clock::now();
sumMatrix << <blocksPerGrid, threadsPerBlock >> > (A_dev, B_dev, C_dev, nx, ny);
auto afterTime = std::chrono::steady_clock::now();
double duration_millsecond = std::chrono::duration<double, std::milli>(afterTime - beforeTime).count();
CHECK(cudaDeviceSynchronize());
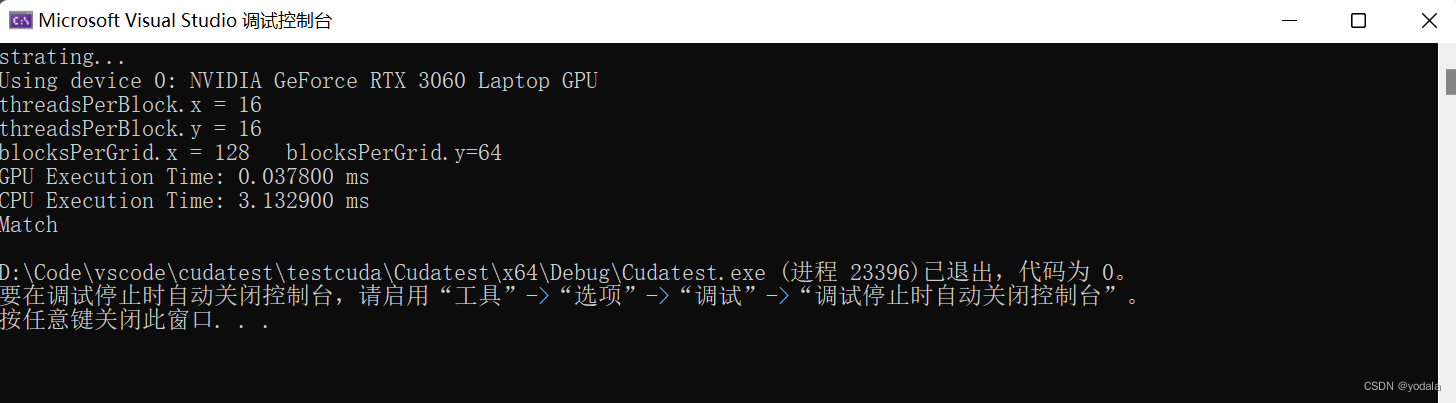
printf("GPU Execution Time: %f ms\n", duration_millsecond);
//在CPU上完成相同的任务
cudaMemcpy(C_from_gpu, C_dev, size, cudaMemcpyDeviceToHost);
beforeTime = std::chrono::steady_clock::now();
sumMatrix2DonCPU(A_host, B_host, C_host, nx, ny);
afterTime = std::chrono::steady_clock::now();
duration_millsecond = std::chrono::duration<double, std::milli>(afterTime - beforeTime).count();
printf("CPU Execution Time: %f ms\n", duration_millsecond);
//检查GPU与CPU计算结果是否相同
CHECK(cudaMemcpy(C_from_gpu, C_dev, size, cudaMemcpyDeviceToHost));
checkResult(C_host, C_from_gpu, nx * ny);
//释放内存
cudaFree(A_dev);
cudaFree(B_dev);
cudaFree(C_dev);
free(A_host);
free(B_host);
free(C_host);
free(C_from_gpu);
cudaDeviceReset();
return 0;
}















 3146
3146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









