









Synthetic Sample Generation for Label Distribution Learning (SSG)
研究背景
已有的 LDL 算法都将重心放在模型设计上,忽略了对数据的预处理。
通过研究现有的数据集,与其输入特征和输出标签的高维度相比,它们包含的样本数量非常少。 一旦应用于学习算法,具有稀疏数据的数据集将导致性能不佳。
本文从数据预处理阶段开始,提出了一种过采样方法,通过从现有实例创建新实例来生成原始数据集的超集。
主要难点
- 不同于smote算法,选择少数类样本作为种子样本,SSG 通过选择空间是最远节点作为种子样本,如何筛选这些样本是第一个挑战。
- 人造样本不仅要处理特征维度,还要处理标签维度。
算法步骤
下图描述了 SSG 的算法流程。
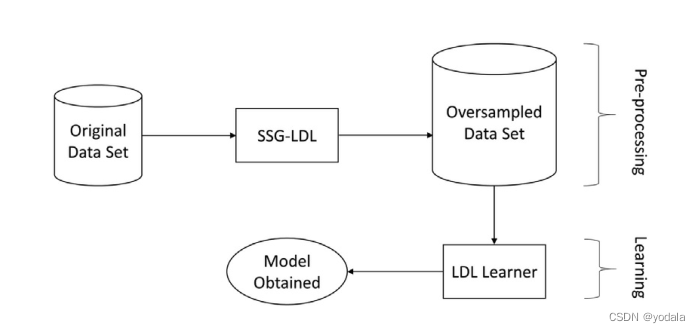

距离
D
I
S
T
‾
[
x
i
]
=
f
x
∑
l
=
1
m
euclidean
(
x
i
,
x
l
)
m
+
f
y
∑
l
=
1
m
euclidean
(
D
i
,
D
l
)
m
.
\overline{D I S T}\left[x_i\right]=f_x \frac{\sum_{l=1}^m \text { euclidean }\left(x_i, x_l\right)}{m}+f_y \frac{\sum_{l=1}^m \text { euclidean }\left(D_i, D_l\right)}{m} \text {. }
DIST[xi]=fxm∑l=1m euclidean (xi,xl)+fym∑l=1m euclidean (Di,Dl).
将两个维度的欧式距离的加权和作为目标样本与其他样本的最终距离;
取目标样本与所有样本的距离的均值作为筛选种子样本的度量。
种子样本选择算法

每个样本被选中的概率为:
P
x
i
=
DIST
‾
[
x
i
]
∑
j
=
1
m
D
I
S
T
‾
[
x
j
]
P_{x_i}=\frac{\overline{\operatorname{DIST}}\left[x_i\right]}{\sum_{j=1}^m \overline{D I S T}\left[x_j\right]}
Pxi=∑j=1mDIST[xj]DIST[xi]
样本合成算法

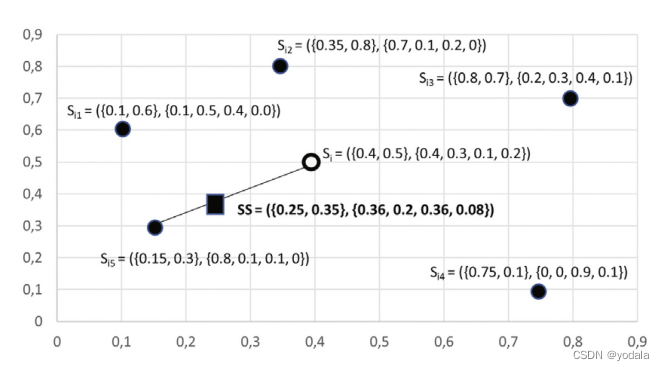
- 在特征维度上,只利用种子样本和它随机的一个 k k k近邻样本来合成特征向量,上图gap=0.6。
- 标签维度上同时考虑种子样本和所有 k k k近邻样本,计算其均值作为最终的标签向量。
实验
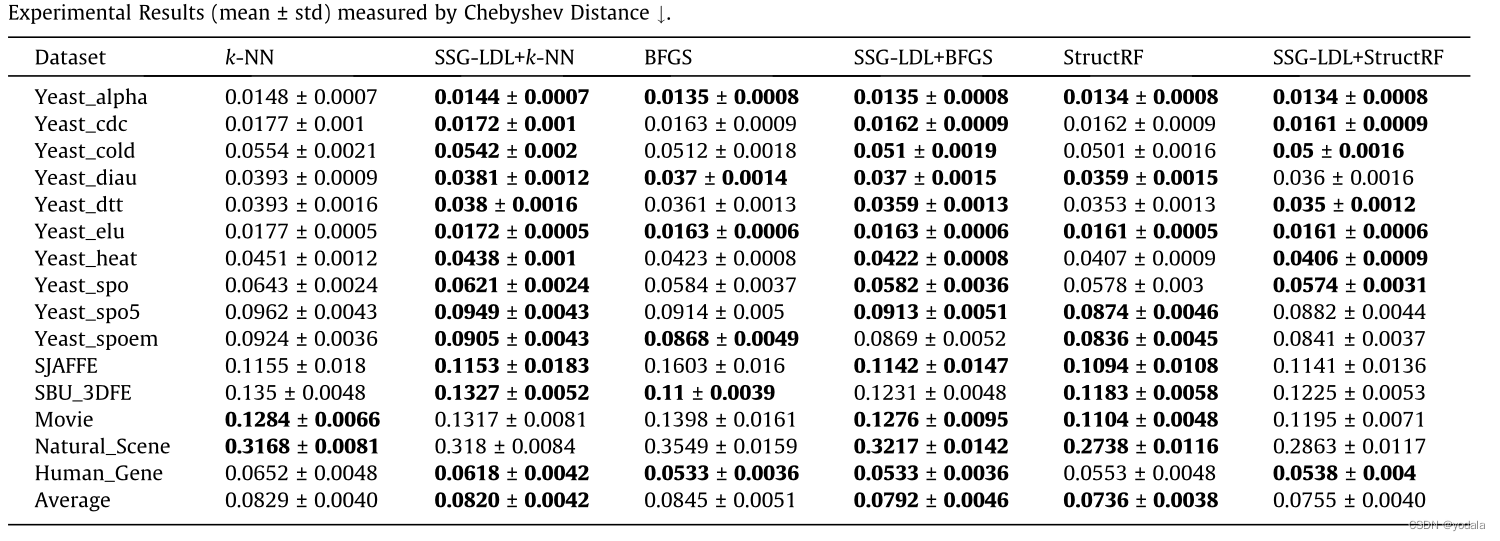
启发
- 种子样本并不一定要从标签入手,LDL 由于其标签特性,通过标签来定义少数类是比较困难的。本文通过空间信息来选择种子样本是一个较好的着陆点。通过聚类来选择种子节点可能也是不错的出发点。样本数量少的簇可能会被学习器所忽略。
- 特征向量和标记向量使用不同的方法来生成,标记向量的生成应该用到更多的信息。在生成特征向量之后结合原始样本利用矩阵分解得到标签向量也许能够取得更好的结果。
















 2861
2861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









