







Learning from imbalanced data: open challenges and future directions
Tackling imbalanced data
-
Data-level methods that modify the collection of examples to balance distributions and/or remove difficult samples.
修改训练集,使其适合标准学习算法。为了平衡分布,我们可以为少数群体产生新对象的方法(过抽样)和从多数群体中剔除样本的方法(欠抽样)。标准方法使用随机性方法来选择用于预处理的目标样本。然而,这通常会导致删除重要的样本或引入无意义的新对象。因此,提出了更先进的方法,试图维持样本的整体结构和或根据潜在的分布产生新的数据。
-
Algorithm-level methods that directly modify existing learning algorithms to alleviate the bias towards majority objects and adapt them to mining data with skewed distributions.
专注于改进现有的算法,以减轻它们对多数群体的bias。这需要对改进的学习算法有很好的了解,并准确地识别其在挖掘倾斜分布时失败的原因。最流行的分支是成本敏感型方法(重加权)。考虑对每组实例设置不同的惩罚。通过这种方式,通过将更高的成本分配给较少代表的对象集,我们在学习过程中提高了它的重要性。但对于许多现实生活中的问题,很难在成本矩阵中设定实际值。另一种算法级别的解决方案是应用聚焦于目标群体的单类学习,创建数据描述。通过这种方式,消除对任何组的bias,只关注一组对象。
-
Hybrid methods that combine the advantages of two previous groups.
Real-life imbalanced problems
从不平衡数据中学习的发展主要是由大量现实生活应用推动的,在这些应用中,我们面临着数据表示不平衡的问题。在这种情况下,少数类通常是更重要的一类,因此我们需要一些方法来提高其识别率。这与防止恶意攻击、检测危及生命的疾病、管理社交网络中的非典型行为或处理监控系统中的罕见案例等重要问题密切相关。
Binary imbalanced classification
2022/06/21
什么是二分类不平衡
In such a scenario the relationship between classes is well defined: one of them is a majority, while the other is a minority group.
解决思路
- 平衡分布
- 优化损失
存在的问题1
- 不平衡比率并不是学习困难的唯一来源,即使不平衡比例很高,但这两个类别都得到了很好的表示,并且来自非重叠分布,任然可以使用规范分类器来获得良好的分类率。 Degradation of performance may also be caused by the presence of difficult examples, especially within the minority class.
少数样本中的 difficult examples,这里具体指的什么样的样本论文中没有说清楚,还需查阅一哈其他文献。
解决思路
- 重要的是要提出新的分类器,可以直接或间接地将对象的背景知识纳入其训练过程。在设计一个有效的分类器时,not only alleviate the bias towards the majority class, but also pay attention to difficulties of individual minority examples.
- 在分析少数类结构的时候,关注 difficult examples and important examples,避免在过采样或者欠采样的进程中丢失代表样本。
- 关于少数类中离群样本和噪声样本,如果只是简单的丢弃,可能会造成严重的后果。本来少数类样本就少,通过现有的环境分析得出的样本属性可能并不是真实的属性,也就是说丢弃的离群、噪声样本也可能代表样本。
存在的问题2(2022/06/22)
极端不平衡: Most of the contemporary works in class imbalance concentrate on imbalance ratios ranging from 1:4 up to 1:100. 但当不平衡比例达到 1:1000 - 1:5000 了呢?
解决思路
- In cases with such a high imbalance the minority class is often poorly represented and lacks a clear structure. 重构少数类的结构可能是一个好的解决方向。
- 将原始问题分解为一组子问题,每个子问题不平衡比例降低,然后就可以使用规范的方法。然而,这种方法又带来了新的挑战
(i) 有效的分解算法。
(ii) 重构算法。 - 特征提取:在面对高纬度特征的应用时,考虑降维的同时也要考虑对少数类的bias。
存在的问题3
Methods for addressing class imbalance are either concentrating on modifying the learning algorithm or the training set. However, simply changing the data distribution without considering the imbalance effect on the classification output may be misleading.
解决思路
- A drawback of methods based on output adjustment lies in possibility of overdriving the classifier towards the minority class, thus increasing the error on the majority one.
Multi-class imbalanced classification
Here we deal with a more complicated situation, as the relations among the classes are no longer obvious.
A class may be a majority one when it is compared to some other classes, but a minority or well-balanced for the rest of them. When dealing with multi-class imbalanced data we may easily lose performance on one class while trying to gain it on another.
针对这种情况可以选择重要的标签,该标签对分类有着重要影响。
数据清洗
- New data cleaning methods must be developed to handle presence of overlapping and noisy samples that may additionally contribute to deteriorating classifier’s performance. One may think of projections to new spaces in which overlapping will be alleviated or simple removal of examples.错误标记的样本可能会增加不平衡(当实际比例较低时)或掩盖实际的不平衡。
- 新的抽样策略。简单地重新平衡最大或最小的类并不是一个合适的方法。我们需要开发专门的方法,根据类的个别属性和它们的相互关系调整抽样过程。
分解策略
An intuitive approach for handling multi-class imbalanced datasets is to apply a decomposition strategy and reduce it to a set of binary problems that can be solved by one of existing techniques. However, one must be aware of possible drawbacks such as loss of balanced performance on all of classes or rejecting the global outlook on the multi-class problem.
- 到目前为止使用的分解方法对每对类应用相同的方法。因为两两关系可能会有很大的不同,为每对单独计算成本惩罚或过采样比是一个很好的开始方向。
划分平衡的验证集、测试机(2022/06/23)
以不平衡回归为例
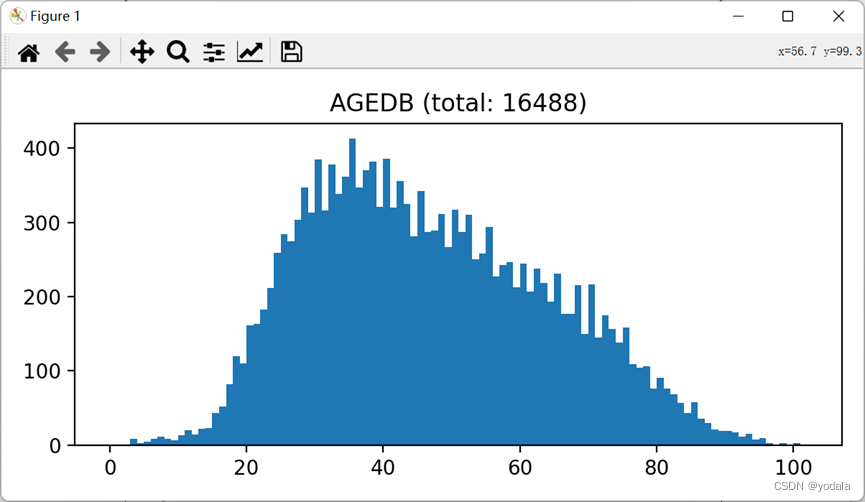
上图为数据集AGEDB的整体分布,从图中可以得出结论30-50左右的样本占比很大,其它区间占比较小,这就是我们常说的不平衡分布。
为了能够使验证集和测试集的拥有平衡的分布,我们可以在每一个bin区间随机抽样, p=max[n//3,threshold],其中threshold是人为设置的常量,n为该区间的样本数,验证集和测试集分别取[:p], [p:2p]。
def make_balanced_testset(db="agedb", max_size=30, seed=666, verbose=True, vis=True, save=False):
file_path = join(BASE_PATH, "meta", f"{db}.csv")
df = pd.read_csv(file_path)
df['age'] = df.age.astype(int)
val_set, test_set = [], []
import random
random.seed(seed)
for value in range(121):
curr_df = df[df['age'] == value]
curr_data = curr_df['path'].values
random.shuffle(curr_data)
curr_size = min(len(curr_data) // 3, max_size)
val_set += list(curr_data[:curr_size])
test_set += list(curr_data[curr_size:curr_size * 2])
if verbose:
print(f"Val: {len(val_set)}\nTest: {len(test_set)}")
assert len(set(val_set).intersection(set(test_set))) == 0
combined_set = dict(zip(val_set, ['val' for _ in range(len(val_set))]))
combined_set.update(dict(zip(test_set, ['test' for _ in range(len(test_set))])))
df['split'] = df['path'].map(combined_set)
df['split'].fillna('train', inplace=True)
if verbose:
print(df)
if save:
df.to_csv(str(join(BASE_PATH, f"{db}.csv")), index=False)
if vis:
_, ax = plt.subplots(3, figsize=(6, 9), sharex='all')
df_train = df[df['split'] == 'train']
ax[0].hist(df_train['age'], range(max(df['age'])))
ax[0].set_title(f"[{db.upper()}] train: {df_train.shape[0]}")
ax[1].hist(df[df['split'] == 'val']['age'], range(max(df['age'])))
ax[1].set_title(f"[{db.upper()}] val: {df[df['split'] == 'val'].shape[0]}")
ax[2].hist(df[df['split'] == 'test']['age'], range(max(df['age'])))
ax[2].set_title(f"[{db.upper()}] test: {df[df['split'] == 'test'].shape[0]}")
ax[0].set_xlim([0, 120])
plt.tight_layout()
plt.show()
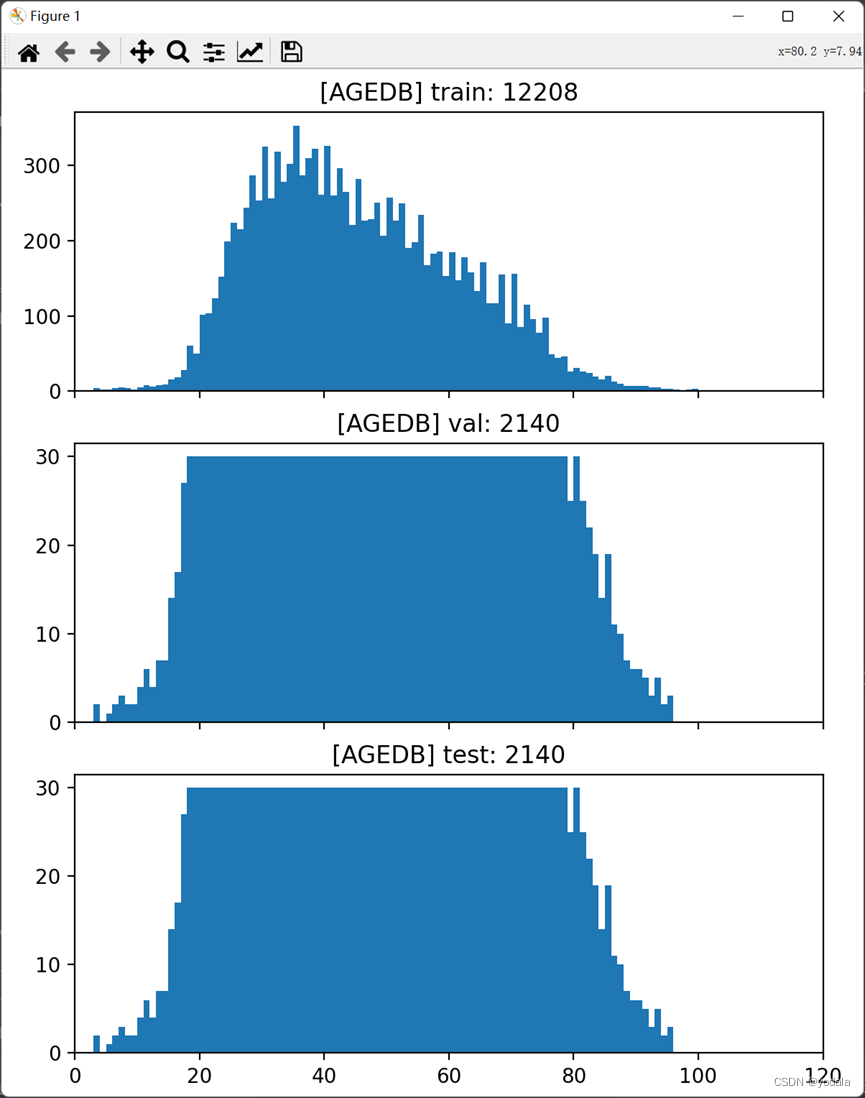
上图显示了抽样之后的训练集、验证集、测试集,其中训练集拥有和原始数据集相似的分布,而验证集和测试集则拥有相对平衡的分布。
2022/06/24
每一种标签都利用LDS得到一个平滑的分布
假设原始的loss被定义为MAE,即
M
A
E
i
=
1
n
∑
j
=
1
n
∣
p
i
j
−
d
i
j
∣
MAE_i=\frac{1}{n}\sum_{j=1}^{n}{|p_i^j-d_i^j|}
MAEi=n1j=1∑n∣pij−dij∣
当
c
=
2
c=2
c=2时
M
A
E
i
=
1
2
(
∣
p
i
1
−
d
i
1
∣
+
∣
p
i
2
−
d
i
2
∣
)
MAE_i=\frac{1}{2}(|p_i^1 - d_i^1|+ |p_i^2 - d_i^2|)
MAEi=21(∣pi1−di1∣+∣pi2−di2∣)
受LDF启发,可以将上式优化为
M
A
E
i
=
1
2
(
α
∣
p
i
1
−
d
i
1
∣
+
β
∣
p
i
2
−
d
i
2
∣
)
MAE_i=\frac{1}{2}(\alpha|p_i^1 - d_i^1|+ \beta|p_i^2 - d_i^2|)
MAEi=21(α∣pi1−di1∣+β∣pi2−di2∣)
其中
α
\alpha
α和
β
\beta
β分别由
p
i
1
p_i^1
pi1和
p
i
2
p_i^2
pi2决定。
* 对每种标签的分布通过加权得到一个总体分布,累加取平均?
通过smote等方法进行人造数据?
* 能够直接通过FDS修改特征特征空间,从而得到适用于LDL的平滑特征分布?
* 数据集
从多标签学习的不平衡数据集找可用的数据集?
但这又面临着一个新的问题,多标签数据集缺少真实标签分布数据集?使用标签增强获得标签分布数据?怎么证明使用的标记增强算法不受不平衡影响?
* 组会
重新确定方向,先从单标签、多标签的不平衡开始-----进行该方面的文献调研。















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









