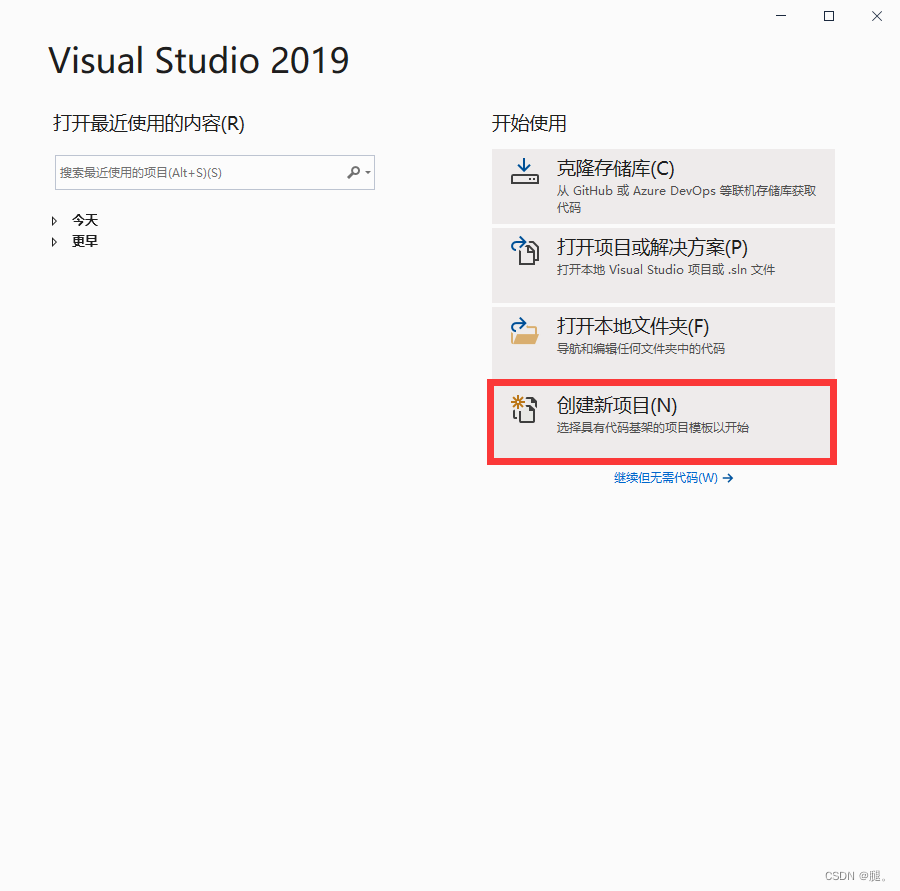
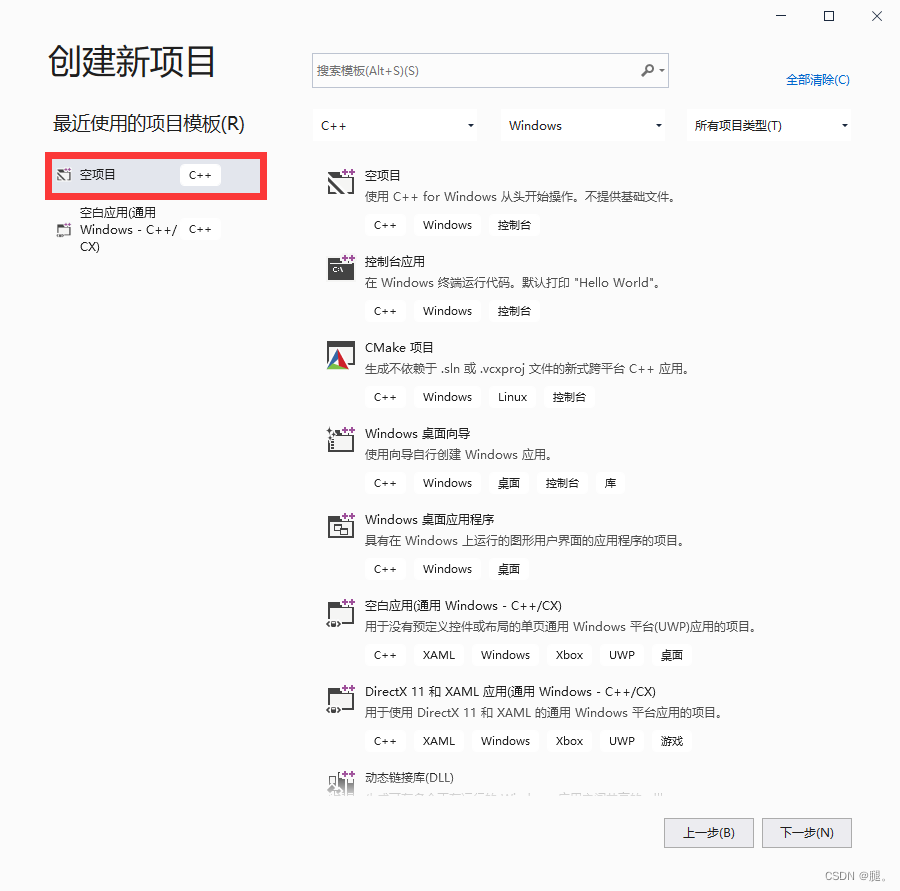
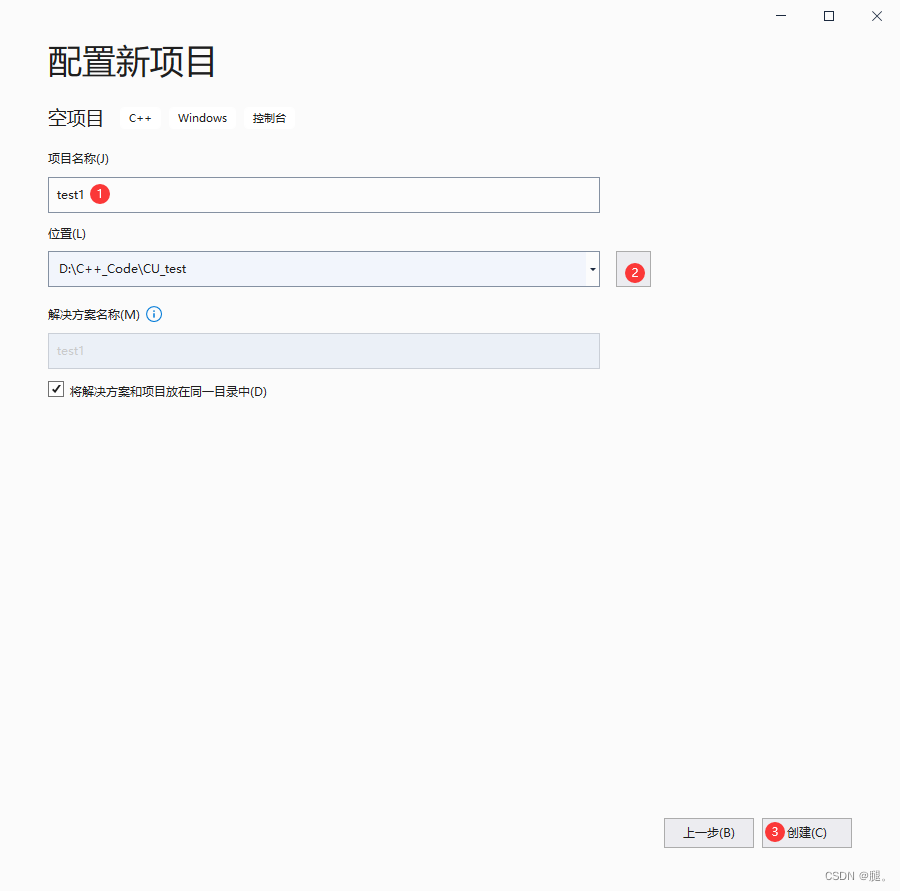
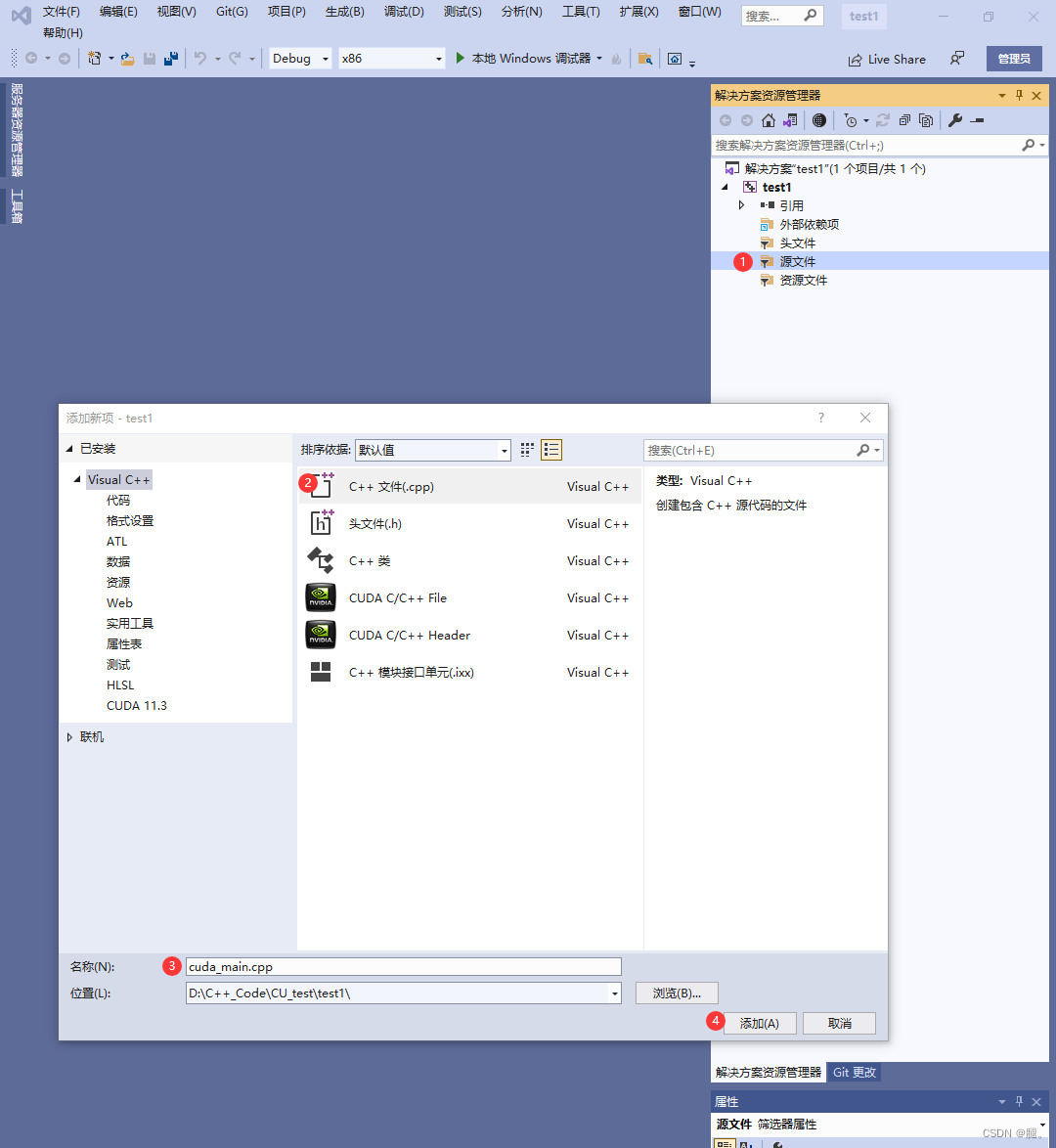
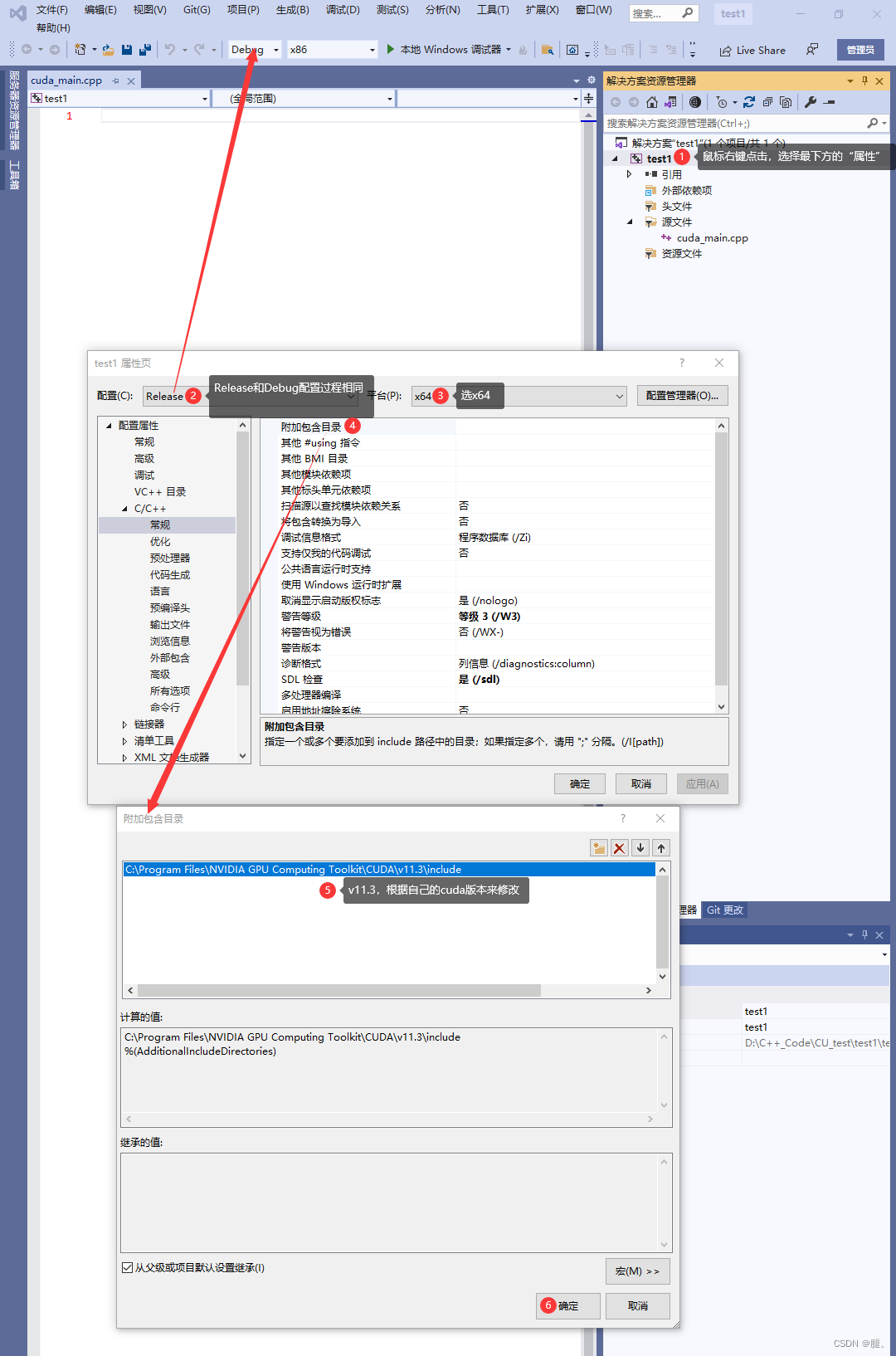
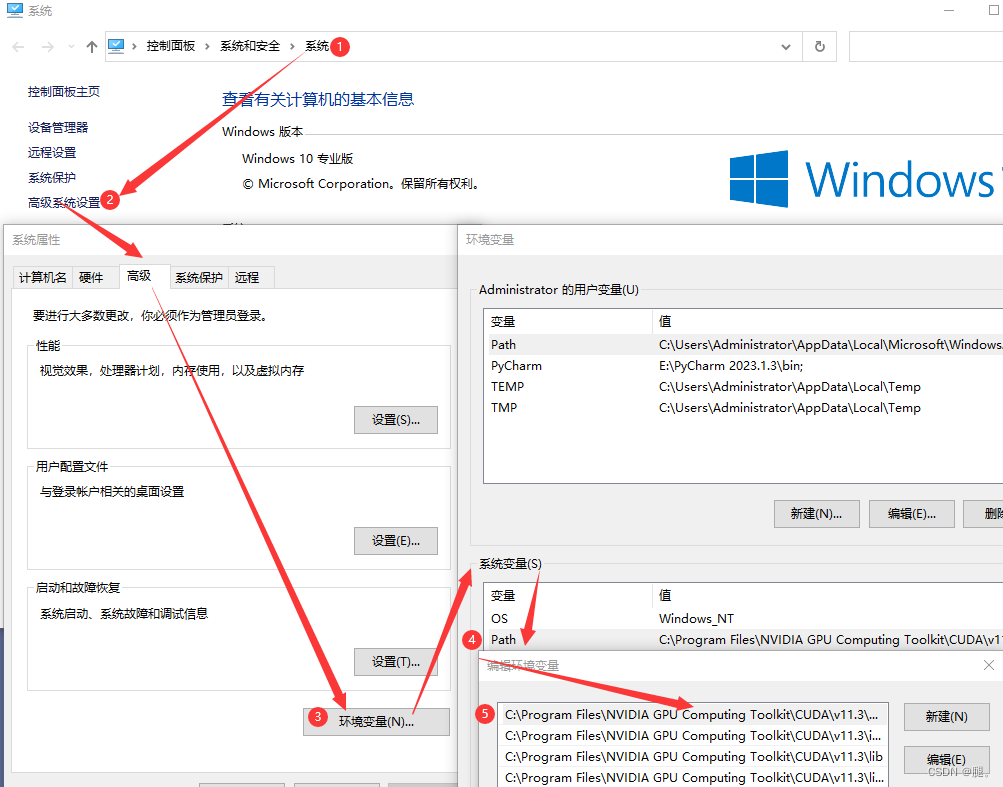
一、VS2019、CUDA以及cuDNN的安装及配置网上相关博客很多,在这不再赘述。 二、打开VS2019 1、创建新项目 2、选择c++空项目 3、项目名称和位置可以自己选择 4、在test1的源文件位置,鼠标右键点击,选择添加->新建项->C++文件(.cpp) 5、在test1的位置鼠标右键点击,选择最下方的“属性”,C/C++ -> 常规 ->附加包含目录 -> 添加include(存放的.h文件)
C: \Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11. 3 \include
# 注意版本v11. 3
在Visual Studio 2019的C/C++项目属性页中,常规(General)选项卡下的“附加包含目录”(Additional Include Directories)是用于指定额外的头文件包含目录的设置。头文件包含目录是编译器在编译过程中搜索头文件(.h文件)的路径。通过在“附加包含目录”中添加路径,可以告诉编译器在这些路径中查找头文件。
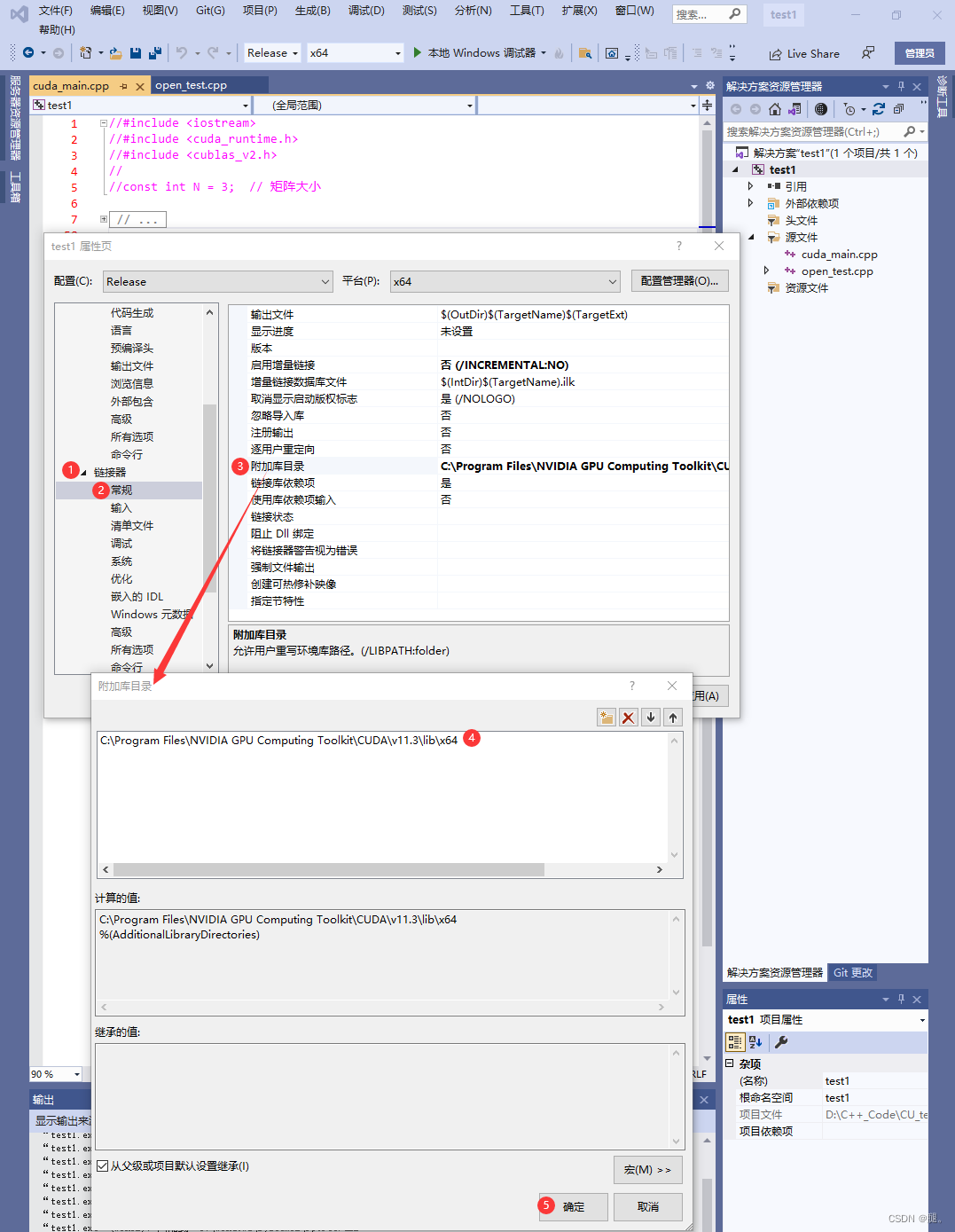
6、链接器-> 常规 -> 附加库目录->添加lib\64x C: \Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11. 3 \lib\x64
在项目属性中,将库文件输出目录(通常是“lib”目录)添加到链接器的附加库目录中,是确保在链接过程中能够正确找到库文件的常见做法。
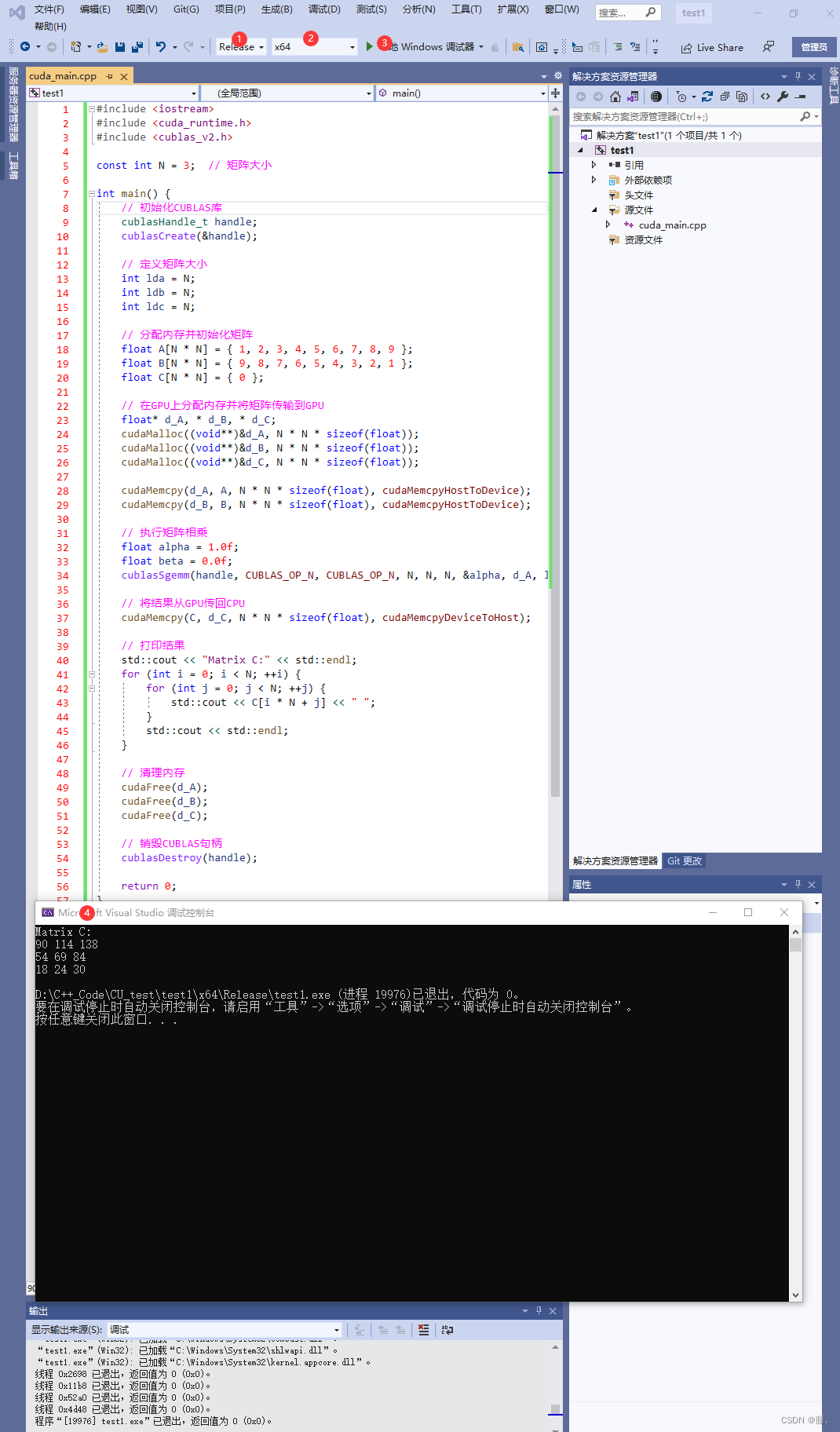
# include <iostream> # include <cuda_runtime.h> # include <cublas_v2.h> const int N = 3 ;
int main ( ) {
cublasHandle_t handle;
cublasCreate ( & handle) ;
int lda = N;
int ldb = N;
int ldc = N;
float A[ N * N] = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } ;
float B[ N * N] = { 9 , 8 , 7 , 6 , 5 , 4 , 3 , 2 , 1 } ;
float C[ N * N] = { 0 } ;
float * d_A, * d_B, * d_C;
cudaMalloc ( ( void * * ) & d_A, N * N * sizeof ( float ) ) ;
cudaMalloc ( ( void * * ) & d_B, N * N * sizeof ( float ) ) ;
cudaMalloc ( ( void * * ) & d_C, N * N * sizeof ( float ) ) ;
cudaMemcpy ( d_A, A, N * N * sizeof ( float ) , cudaMemcpyHostToDevice) ;
cudaMemcpy ( d_B, B, N * N * sizeof ( float ) , cudaMemcpyHostToDevice) ;
float alpha = 1.0f ;
float beta = 0.0f ;
cublasSgemm ( handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, & alpha, d_A, lda, d_B, ldb, & beta, d_C, ldc) ;
cudaMemcpy ( C, d_C, N * N * sizeof ( float ) , cudaMemcpyDeviceToHost) ;
std:: cout << "Matrix C:" << std:: endl;
for ( int i = 0 ; i < N; ++ i) {
for ( int j = 0 ; j < N; ++ j) {
std:: cout << C[ i * N + j] << " " ;
}
std:: cout << std:: endl;
}
cudaFree ( d_A) ;
cudaFree ( d_B) ;
cudaFree ( d_C) ;
cublasDestroy ( handle) ;
return 0 ;
}
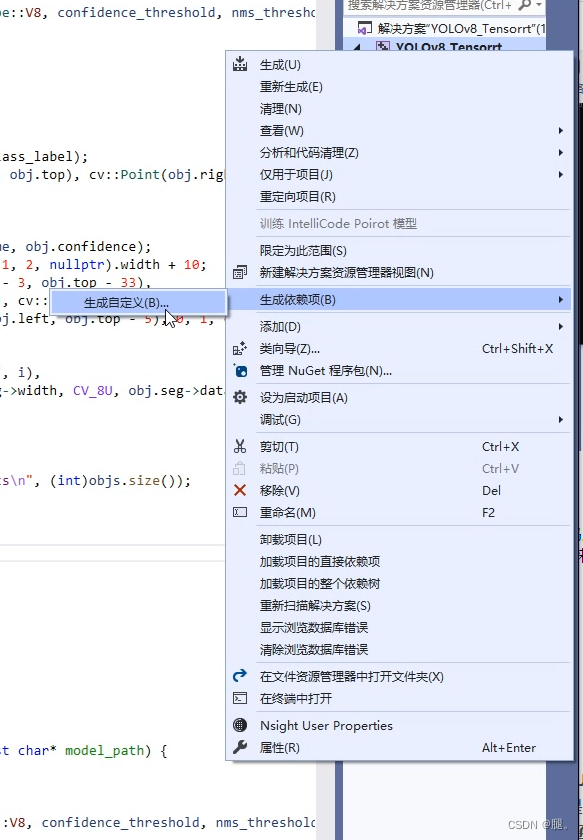
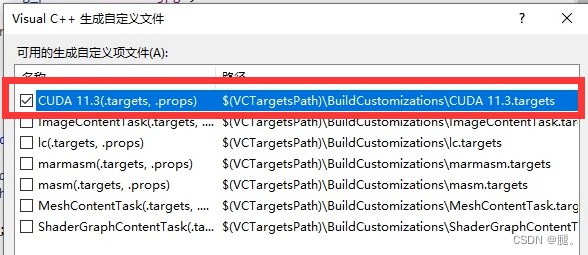
三、编译.CU文件(如有需要) .cu 文件: 这些文件包含了 GPU 上运行的 CUDA C/C++ 代码。在 .cu 文件中,可以使用 CUDA 扩展来定义 GPU 函数(称为 kernel),使用线程和块来描述并行执行,以及调用 GPU 函数等。1、鼠标右击项目 -> 生成依赖项 ->生成自定义->点击cuda
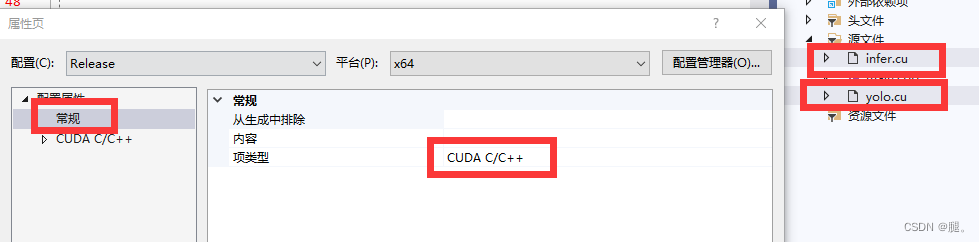
2、选择.cu文件右击 -> 常规 -> 项内容 ->CUDA C/C++
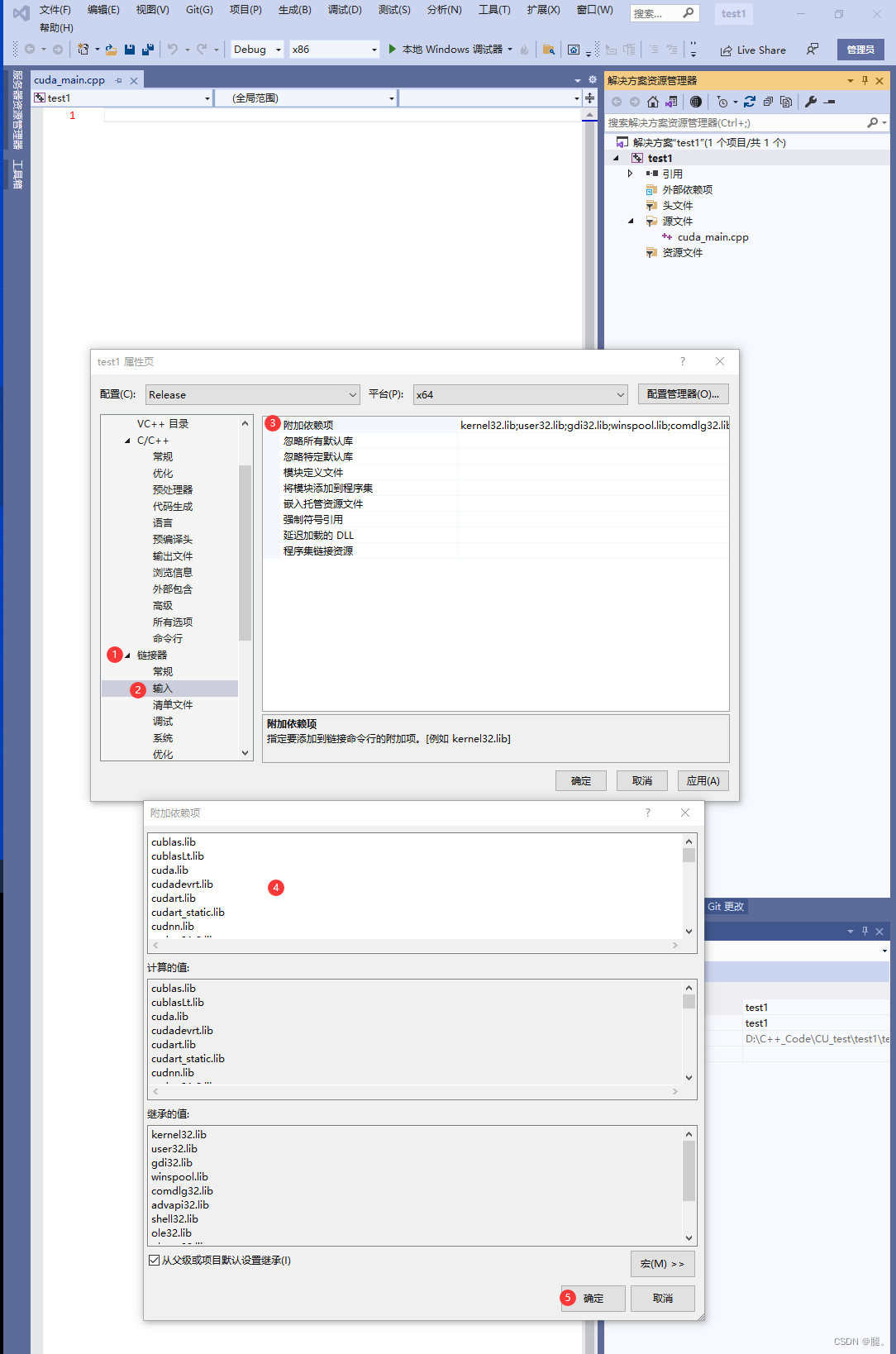
三、CUBLAS库 CUBLAS库是一种在CUDA环境下使用的库,它提供了一些CUDA的封装,使得使用CUBLAS函数在CPU上运行是可行的,而不需要额外的GPU代码。这是由于CUBLAS库在其实现中对CUDA的API和数据结构进行了封装,允许在CPU上调用这些函数,而库内部会根据环境选择是否将计算移至GPU上。 需要注意的是,尽管代码看起来直接在C++编译器下运行,但实际上它在内部仍然使用了CUDA库和CUBLAS库的功能。这些库确保了在GPU上进行高性能的计算,但由于封装,可以在C++环境中运行这些代码而无需直接涉及GPU编程。 四、.dll和.lib的区别 .dll 和 .lib 是在 Windows 系统上用于共享库的两种不同类型的文件。它们在库的使用、链接和部署方面有不同的角色和功能。 .dll(Dynamic Link Library): 动态链接库是一种共享库,包含编译好的可执行代码和数据。这些库在运行时由程序动态加载,以便在内存中共享其功能。 .dll 文件中包含函数和数据,可以由多个程序共享。这减少了内存使用和代码冗余。 当程序需要使用库中的功能时,它会在运行时从 .dll 文件中加载所需的函数和资源。这种方式实现了代码的共享,但需要确保 .dll 文件在运行时可以访问。 .lib(Library): 静态库是一组已经编译好的对象代码的集合,可以在编译时被链接到程序中。 .lib 文件包含了库中的函数和数据的实现,将这些实现编译进最终生成的可执行文件中。 在链接时,编译器会从 .lib 文件中提取所需的函数和资源,将其合并到最终的可执行文件中。这使得可执行文件在运行时不需要外部 .dll 文件。 .dll 文件是动态链接库,程序在运行时加载其中的代码和数据,使得代码共享和更新变得更容易,但需要确保 .dll 文件的可用性。 总结区别: .dll 文件是动态链接库,程序在运行时加载其中的代码和数据,使得代码共享和更新变得更容易,但需要确保 .dll 文件的可用性。 .lib 文件是静态库,编译器在链接时将库的代码和数据嵌入到可执行文件中,使得程序不依赖外部 .dll 文件,但可能导致更大的可执行文件大小。 通常,如果希望库的更新可以应用于多个程序,或者希望减少程序的体积,可以选择使用 .dll。如果希望将库的代码完全嵌入到程序中,或者不希望程序依赖外部文件,可以选择使用 .lib。选择哪种类型的库取决于项目需求和设计考虑。








 本文详细介绍了如何在VisualStudio2019中安装和配置CUDA、cuDNN,以及在C++项目中设置附加包含目录、附加库目录和链接依赖项。重点讲解了CUBLAS库的使用和.CU文件的编译,同时对比了.dll和.lib文件在Windows系统上的区别。
本文详细介绍了如何在VisualStudio2019中安装和配置CUDA、cuDNN,以及在C++项目中设置附加包含目录、附加库目录和链接依赖项。重点讲解了CUBLAS库的使用和.CU文件的编译,同时对比了.dll和.lib文件在Windows系统上的区别。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









