






文章目录
前言
作者从2023年开始接触YOLO,24年写了一篇关于YOLO的论文,当时用的是v5版本,阅读了很多博主的文章,现在也算是有了自己的一些理解,因此写下这篇文章,希望能帮到初学者。文中如果有侵犯了别的作者的权益请联系我删。另外,若此文有不妥之处敬请批评。
首先说一下YOLO(You Only Look Once)的发展历史,其历程可以分为以下几个阶段:
YOLOv1:YOLO的第一个版本是由Joseph Redmon为首的大佬们于2015年提出的一种新的目标检测算法,它采用了一个全卷积神经网络,将输入图像分为S×S个网格,每个网格预测B个边界框和各自边界框的类别概率。然后,通过阈值筛选和非极大值抑制(NMS)来获得最终的检测结果。
YOLOv5是由Ultralytics团队在2020年开发的。相比于之前的版本在精度和速度上都有显著提升,与以往的版本相比,YOLOv5引入了新的网络架构,以及一种新的训练方法,使用更大的数据集和更长的训练时间,从而提高了算法的性能。
YOLOv8 是由 Ultralytics 公司在2023年1月发布的最新一代实时目标检测模型。YOLOv8 采用了新的骨干网络和颈部架构,实现了改进的特征提取和目标检测性能。此外,YOLOv8 提供了一系列预训练模型,以满足不同任务和性能要求,使得用户可以根据自己的具体用例找到合适的模型。
YOLOv9 由中国台湾 Academia Sinica、台北科技大学等机构在2024年2月联合开发。YOLOv9引入了程序化梯度信息(Programmable Gradient Information, PGI),旨在解决深层网络中信息丢失的问题。此外,YOLOv9采用了全新的网络架构——泛化高效层聚合网络(Generalized Efficient Layer Aggregation Network, GELAN)。GELAN通过梯度路径规划,优化了网络结构,利用传统的卷积操作符实现了超越当前最先进方法(包括基于深度卷积的方法)的参数利用效率,使YOLOv9能够在保持轻量级的同时,达到前所未有的准确度和速度。(论文,YOLOv9源码)
YOLOv10是2024年5月清华大学的研究人员在Ultralytics的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足,在显著降低计算开销的同时实现了最先进的性能,在多个模型尺度上实现了卓越的精度-延迟权衡。(论文,YOLOv10源码 )
YOLOv11是 Ultralytics在2024年9月发布的,是Ultralytics实时物体检测器系列中的最新产品,以最先进的精度、速度和效率重新定义了可能实现的目标。在之前YOLO 版本令人印象深刻的进步基础上,YOLO11 在架构和训练方法上进行了重大改进,使其成为广泛的计算机视觉任务的多功能选择。(YOLOv11源码)
YOLOv11优点看这里:

一、环境安装
要使用YOLOv11训练自己的模型需要安装(拥有)以下环境:
1.CUDA+cuDNN(或者CPU)
2.Anaconda+pytorch
3.YOLOv11源码下载及相关库安装
4.PyCharm
5.* Visual Studio Code(可选)
CUDA是调用GPU的一个框架,能使CPU与GPU协同处理,比单纯地使用CPU训练模型快得多,因此强烈推荐安装。这点体现在安装pytorch框架时选择CPU版本还是GPU版本。
pytorch库是运行深度神经网络所必须的框架,而Anaconda是安装pytorch库所需要的软件。
PyCharm是编写YOLO源文件的工具。
CUDA与Anaconda与PyCharm的安装没有严格的前后顺序。而Visual Studio Code软件则是安装CUDA时所提到的软件,当然,不安装VS也没关系,只需在安装CUDA时取消相对应的组件即可。
(一)CUDA+cuDNN(或者CPU)
CUDA需要从官网下载软件,但是要注意版本。调出命令行窗口,运行nvcc -V,显示

说明此电脑没有安装CUDA,运行nvidia-smi,显示:
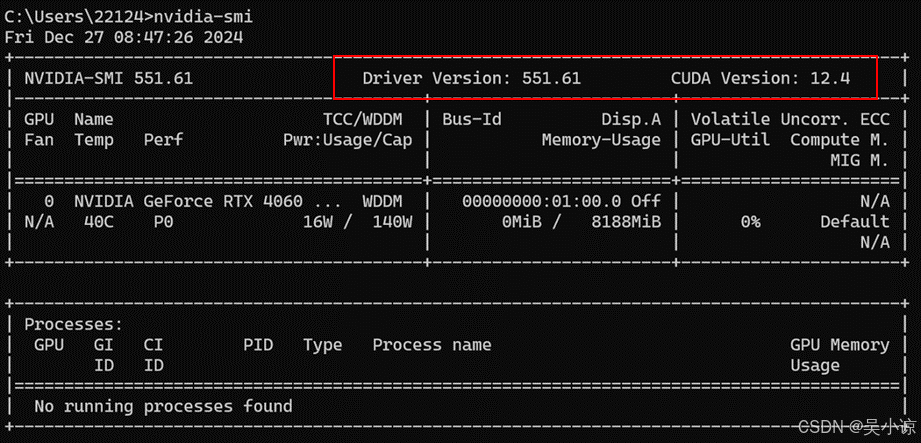
可以看到,我的显卡驱动版本是551.61,可支持最高CUDA版本是12.4,当然,作者建议不安装可支持最高版本的CUDA,因为那样容易安装不成功,显卡驱动对应支持的CUDA版本在这里,登录后即可看到(作者一般用QQ邮箱登录,如果此前没注册过NVIDIA账号,注册一个即可),根据自己的显卡类型选择最新的驱动程序,如图:
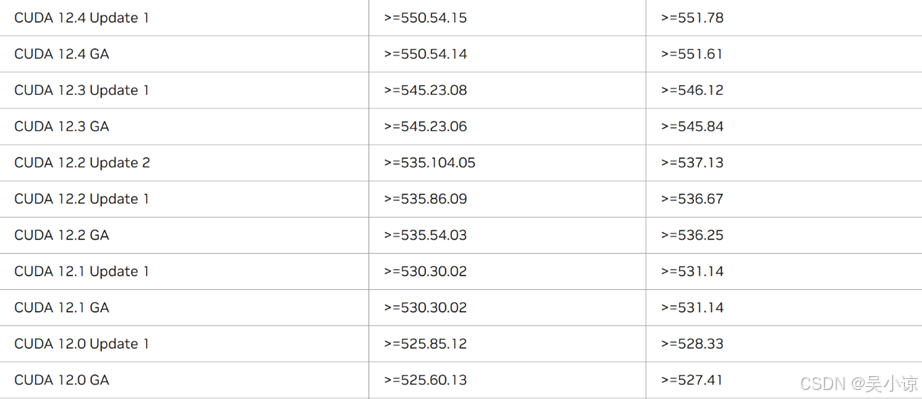
GA表示正式版本,Update表示更新版本。选择好CUDA版本后从官网下载,也可以从历史版本中选择下载。
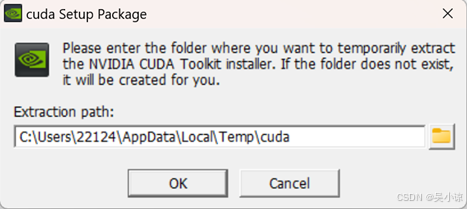
作者选择的是cuda_12.1.0_531.14_windows。双击下载的CUDA安装可执行程序,需要选择一个临时目录存放抽取的安装包(安装完成后会自动删除临时目录、安装的目标目录在后面选择)
下面按照步骤安装即可:
选择自定义,如图:
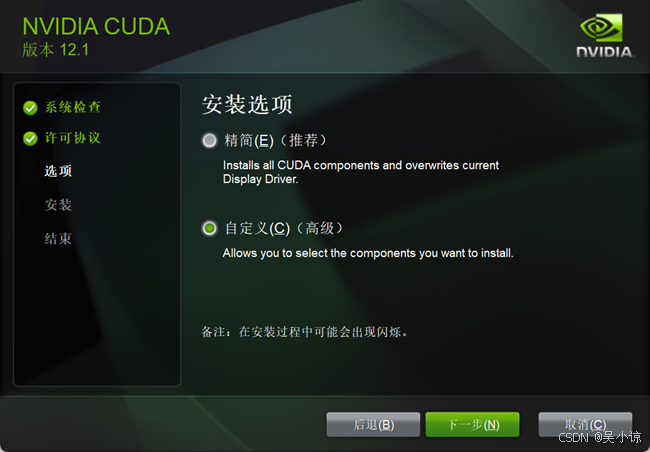
在组件选择这里,如果是第一次安装CUDA,就全选,如果是二次安装,则比较当前版本与更新版本选择安装,

如果你在安装CUDA前,电脑已经安装有了Visual Studio Code,则勾选上这两个选项,若没有,就取消勾选。
安装位置尽量选择非系统盘:

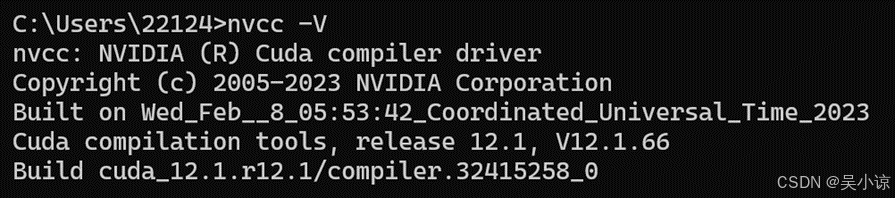
后面等待安装即可。安装结束后再打开命令行窗口,运行nvcc -V,显示如下图说明已经安装成功CUDA12.1。
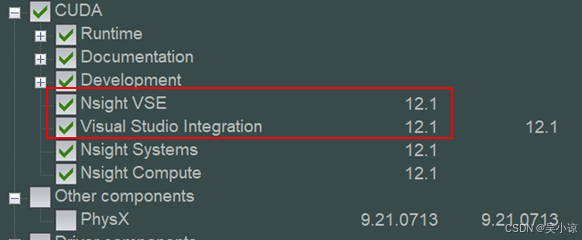
cuDNN安装:
cuDNN是一个由NVIDIA开发的深度学习GPU加速库,旨在为深度学习任务提供高效、标准化的原语(基本操作)来加速深度学习框架在NVIDIA GPU上的运算。官网在这里。与CUDA类似,如果主页不是适合你的版本,则在历史版本中下载。作者选择的是8.9.7版本的。下载同样需要登录账号。

(二)Anaconda+pytorch
Anaconda软件的安装就简单多了,直接从官网下载最新的安装即可,当然,同样需要注册并登陆。如果从官网下载速度慢的话可以用清华镜像下载。
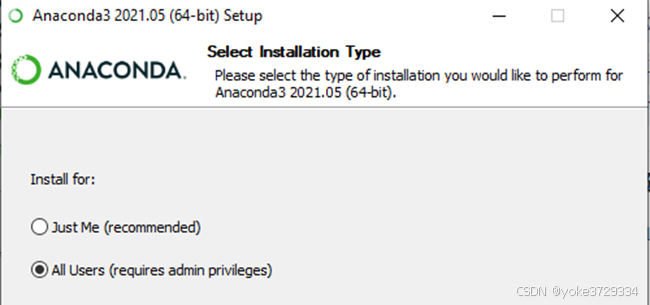
需要注意的是选择安装对象这里,需要选择所有用户,并且安装完之后查看系统属性——环境变量——系统变量——Path里是否有如下配置,如果没有则手动添加。
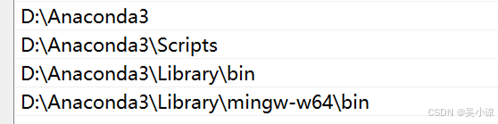
安装好之后打开Anaconda Prompt,运行conda info可查看下载源,和默认环境保存位置,把它改到非系统盘明显更好。在C盘-用户-用户名,找到.condarc文件,如果找不到打开Anaconda prompt或者命令提示符输入以下命令:
conda config --set show_channel_urls yes就能找到了,用记事本打开,全部删除,输入以下内容:
envs dirs:
- D:\Anaconda3\envs
pkgs dirs:
- D:(Anaconda3\pkgs 选择合适的环境位置(envs)和包目录的配置位置(pkgs),并保存。
再运行以下指令更新下载源。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
而后创建一个名为YOLOv11,python版本为3.10的虚拟环境(Python的版本要大于3.8):
conda create -n yolov11 python=3.10创建成功后激活环境:
conda activate yolov11接下来开始安装pytorch。浏览pytorch官网。
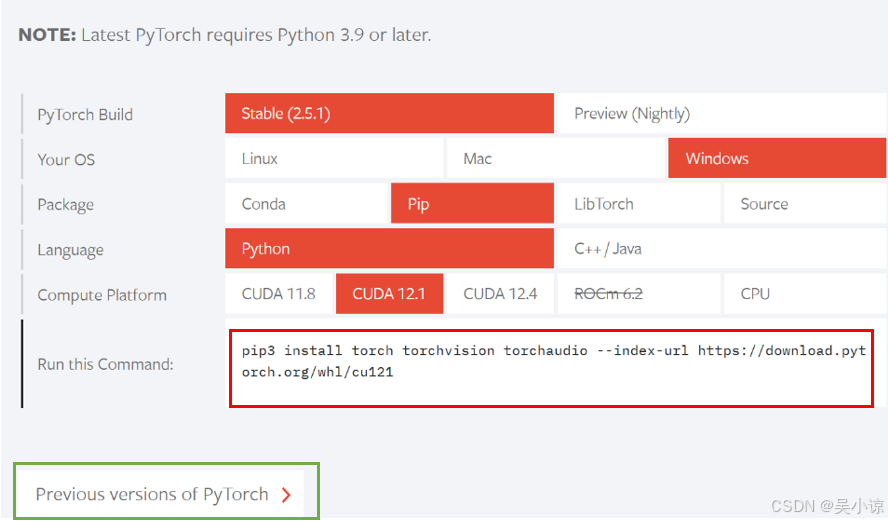
选择对应的环境并复制红色框内代码粘贴进Anaconda Prompt并运行。
如果主页没有你选择的环境,则点击绿色框进入历史界面选择。
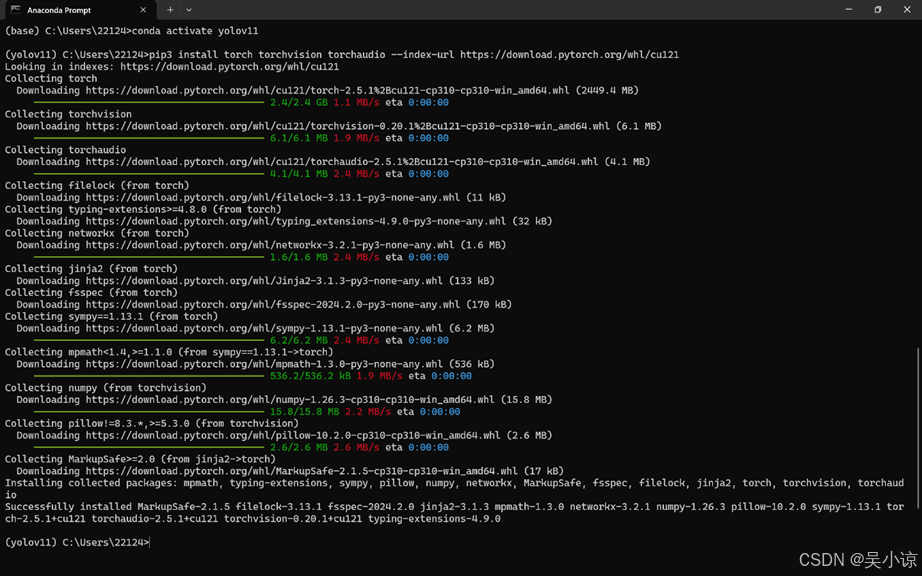
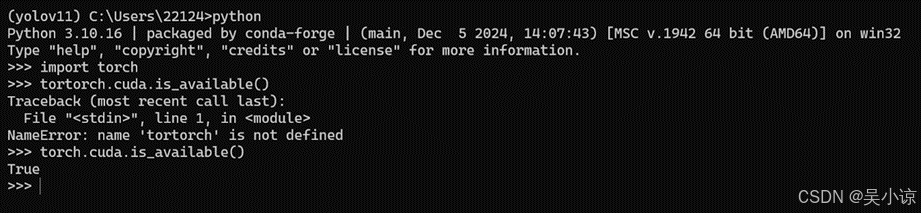
安装成功后进入python,运行torch.cuda.is_available()查看torch是否安装成功。注意安装pytorch时尽量不要使用清华源安装。
(三)YOLOv11源码下载及相关库安装
进入YOLOv11官网,点击code下载压缩包并解压。
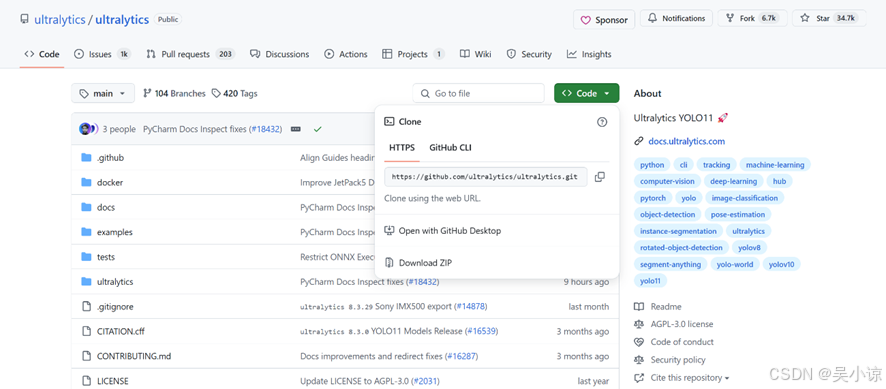
打开Anaconda Prompt,激活YOLOv11环境,安装ultralytics库
pip install ultralytics 这个库包含了几乎全部运行YOLOv11所需的环境,输入以下命令后耐心等待即可,如果速度确实太慢的话可以在后面特定加上清华源,这样速度就能快很多。
(注:CSDN上有比较多的博主说yolov11也需要使用reguirements.txt文件安装相关的库,但是YOLOv11官网上并没有体现这个,只是说了要安装安装ultralytics库,reguirements.txt是v8版本之前yolo才有的,v8之后是安装ultralytics库)
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple不过不同版本的ultralytics库也有所差异:ultralytics的最新版本全面支持YOLOv5-YOLOv11,ultralytics8.0.x8.1.x8.2.x版本支持的YOLO有所区别,比如ultralytics8.0.x一般支持YOLOv5和YOLOv8,具体ultralytics 版本支持的YOLO差异,请去ultralytics官网查询,最新版本的向下兼容,无特殊情况一般推理安装最新版本的ultralytics即可,除非你的项目有ultralytics版本限制。
(四)PyCharm安装
打开PyCharm官网,点击下载,进入版本选择界面,选择免费的社区版本的即可,

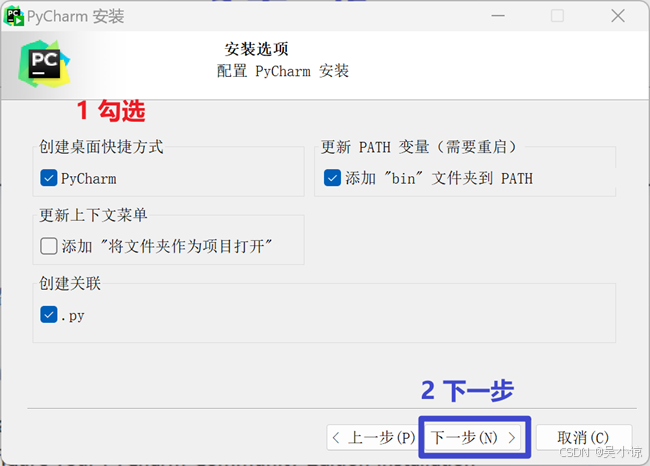
安装过程中,建议不勾选更新上下文菜单。
安装好后重启电脑,打开软件,新建项目(也就是你的YOLOv11源码所在位置),也可以先在左侧Plugins中修改语言以及背景色。
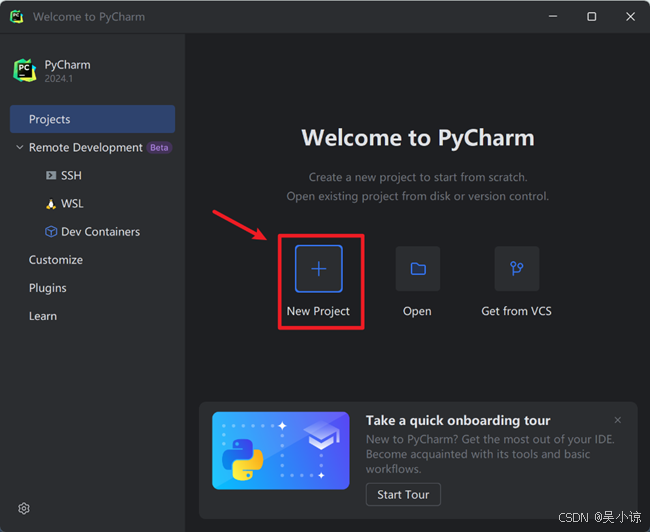
(上面的两张图片是我从网上获取的,因为打开了项目之后我还不懂怎么回到这个欢迎界面)
进入软件后点击右下角,选择添加本地解释器。如图:
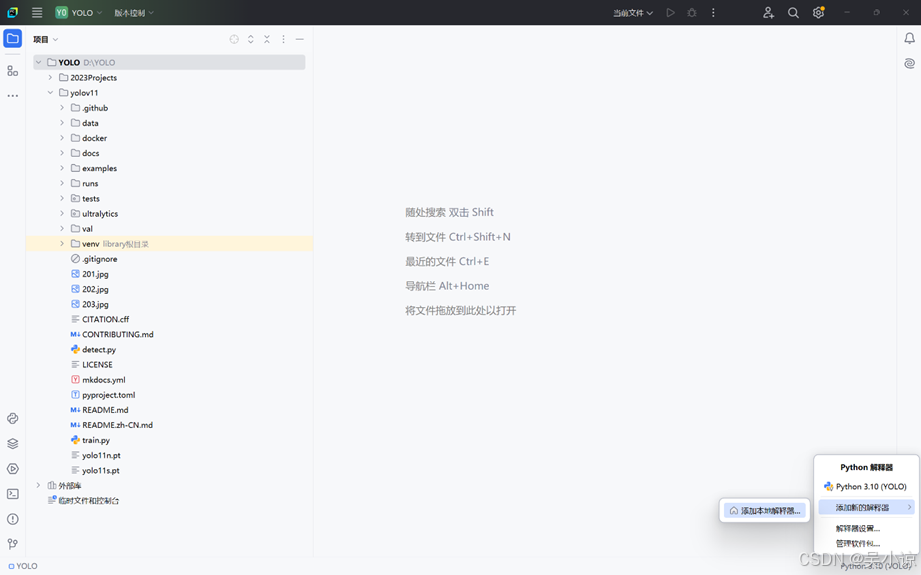
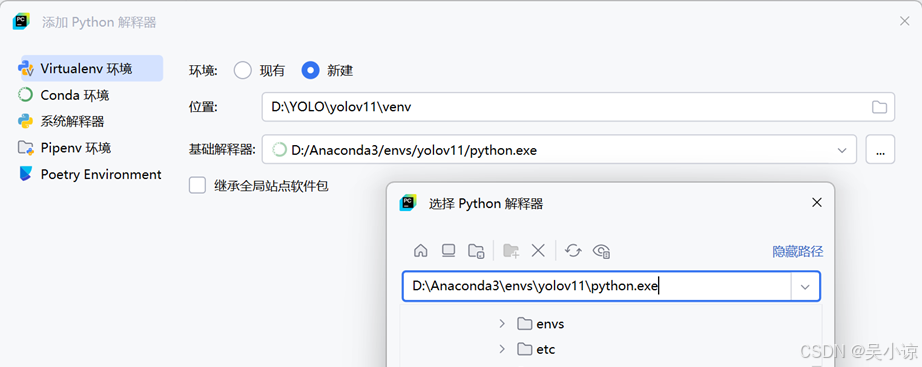
而后点击基础解释器右边的三个点,选择前期Anaconda创建的yolov11环境路径下的python.exe文件,上面的位置选框建议不要修改,因为修改之后可能你在yolov11环境中安装的包或者库在PyCharm中找不到。
二、YOLOv11使用
(一)环境验证
从官网下载权重文件yolo11n.pt放到yolov11源文件夹下,打开Anaconda Prompt,激活yolov11环境,将运行路径调整到yolov11文件夹下,执行指令:
yolo predict model=yolo11n.pt source="D:\YOLO\yolov11\vltralytics\assets\bus.jpg"出现如下图说明yolov11的所有环境安装正确
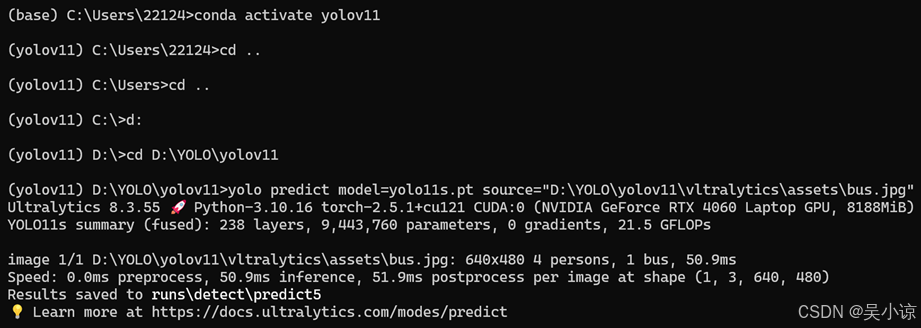
(注:原文件中是ultralytics文件夹,作者修改成了vltralytics,因为\u在python中会被认为是unicode 码)
(二)数据集标注
训练自己的数据集,要先对数据集进行标注。常见的数据集标注工具是labelimg,安装时要在Anaconda Prompt新建并激活一个虚拟环境labelimg,指定Python的版本在3.8及以下,太高版本的话会出现闪退现象,而后按顺序执行下面指令:
pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple(作者就是先安装了labelimg,然后出现了一堆错误)安装成功后打开labelimg,就可以开始标注了。
(labelimg) C:\Users\22124>labelimg如下图,先打开数据集文件夹images,修改标注格式,按“W”键进行画框标注,Ctrl+S保存,路径选择数据集标签文件夹labels,按“D”键下一张图片。(“A”键是上一张照片)
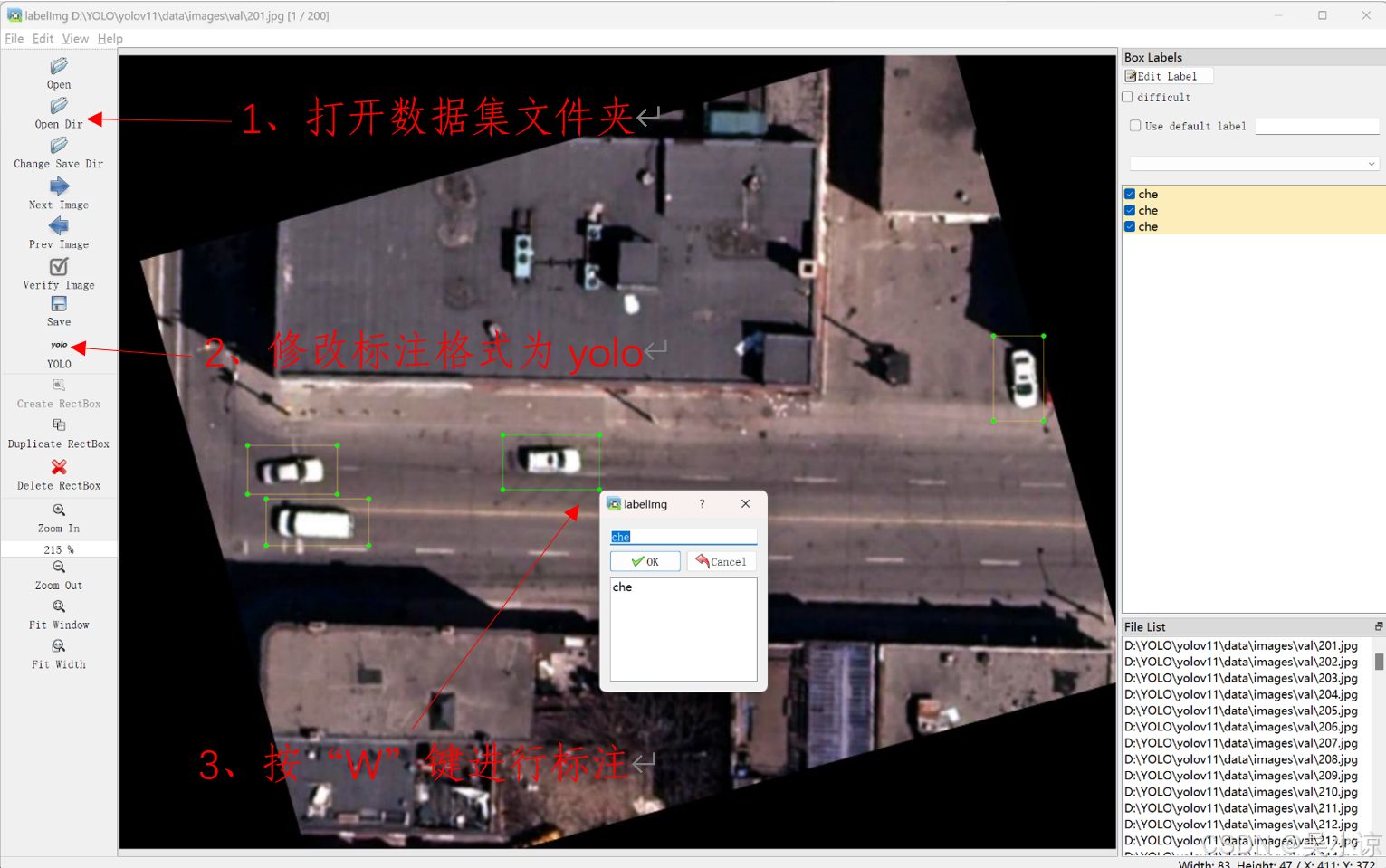
标注完成之后你会在标签文件夹里发现一个名为classes.txt的文件,里面保存有你所标注过的所有类别名。(注:作者这里的照片是已经打好标注后划分好的,所以是在images\val里)
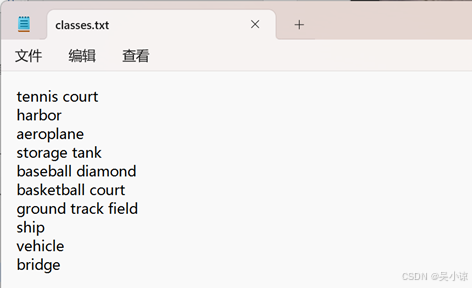
(三)数据集划分
使用YOLO训练模型,数据集划分如下:
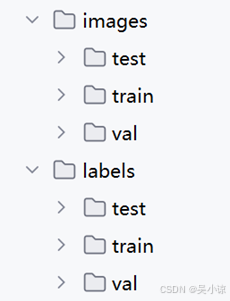
照片放在images中,标签放在labels中,其中,test文件夹是不必须的。一般来说训练集train与验证集val的比例要尽量的大,作者的比例是8:2。
(四)设置配置文件
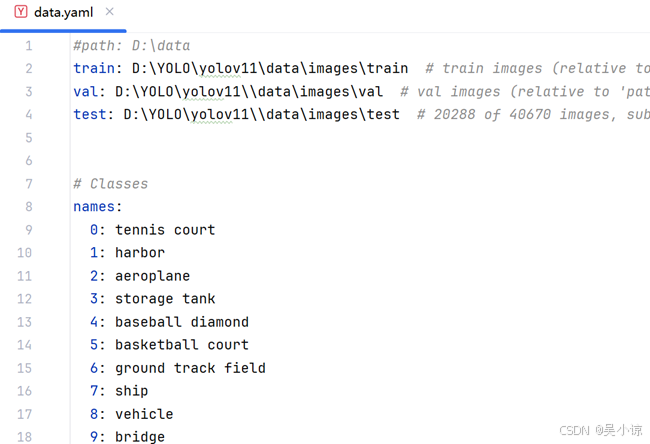
新建一个配置文件data.yaml,如下图,只需要写入照片所在的路径即可,YOLO会自动寻找标签,但要注意标签所在路径与前文一致。
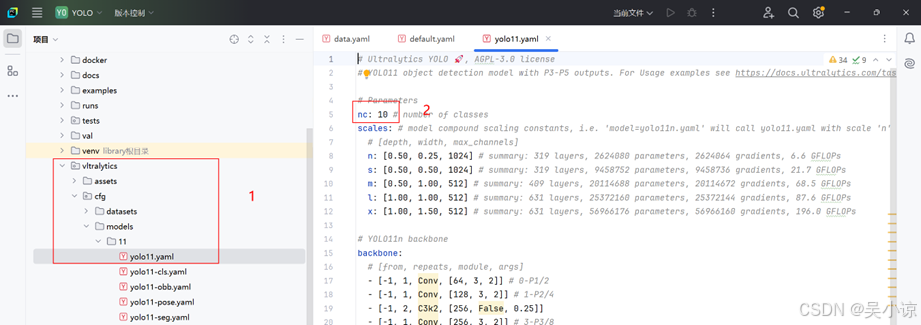
找到yolo11.yaml文件,修改nc,改成你的数据集所分类的数量。
(五)开始训练
训练方法主要分两类,一个是使用Anaconda Prompt命令行,一个是用PyCharm软件。
方法一:先讲Anaconda Prompt,激活yolov11环境,进入到yolov11目录下,执行:
yolo task=detect mode=train model=yolo11s.pt data=data/data.yaml batch=16 epochs=100 imgsz=640 workers=8 device=0
其中:model=yolo11s.pt表示使用小模型,batch=16表示批数量,epochs=100表示训练轮数,imgsz=640表示输入图片的大小,workers=8表示工作线程数,device=0表示选择使用GPU (也可以用其他参数:device=0 or device=0,1,2,3(多个GPU) or device=cpu)
使用命令行的缺点就是相关的参数需要打出来并指定,但优点是环境肯定是没有问题的,不会出现缺包缺库之类的情况。
方法二:通过指定cfg直接进行训练,配置好default.yaml这个文件之后,可以直接在命令行执行这个文件进行训练,这样就不用在命令行输入其它的参数了。
yolo cfg=vltralytics/cfg/default.yaml 
注:这个文件里有一个参数resume,当其为True时表示用于从先前的训练检查点(checkpoint)中恢复模型的训练,即上一次中断的训练可以接着训练,使用该参数时,model应该指向上一次训练时保留的最新模型last.pt。另外,路径尽量使用绝对路径。
方法三:创建train.py文件,输入如下指令,调整参数运行。
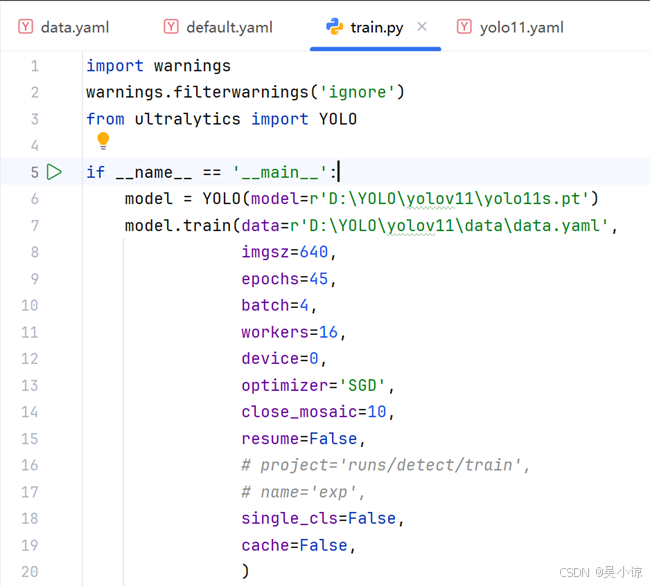
无论通过上述的哪一种方法只要输出如下图片的内容即代表训练成功。
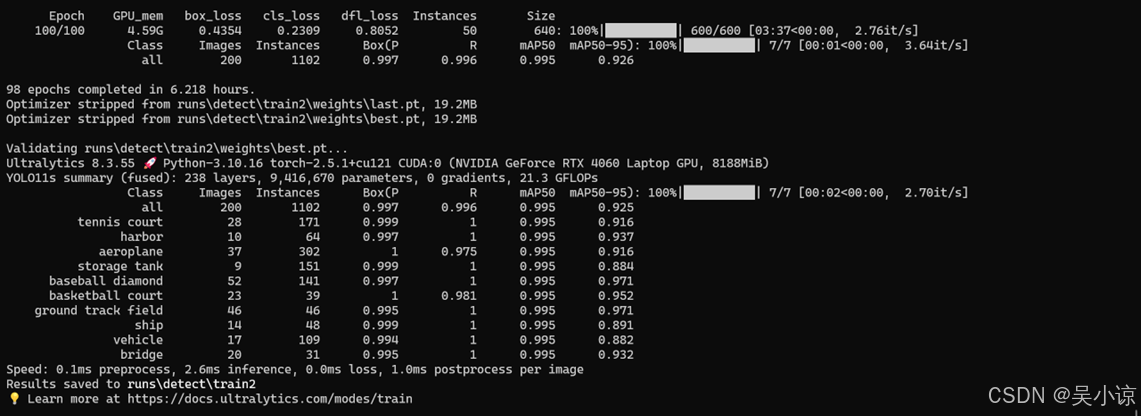
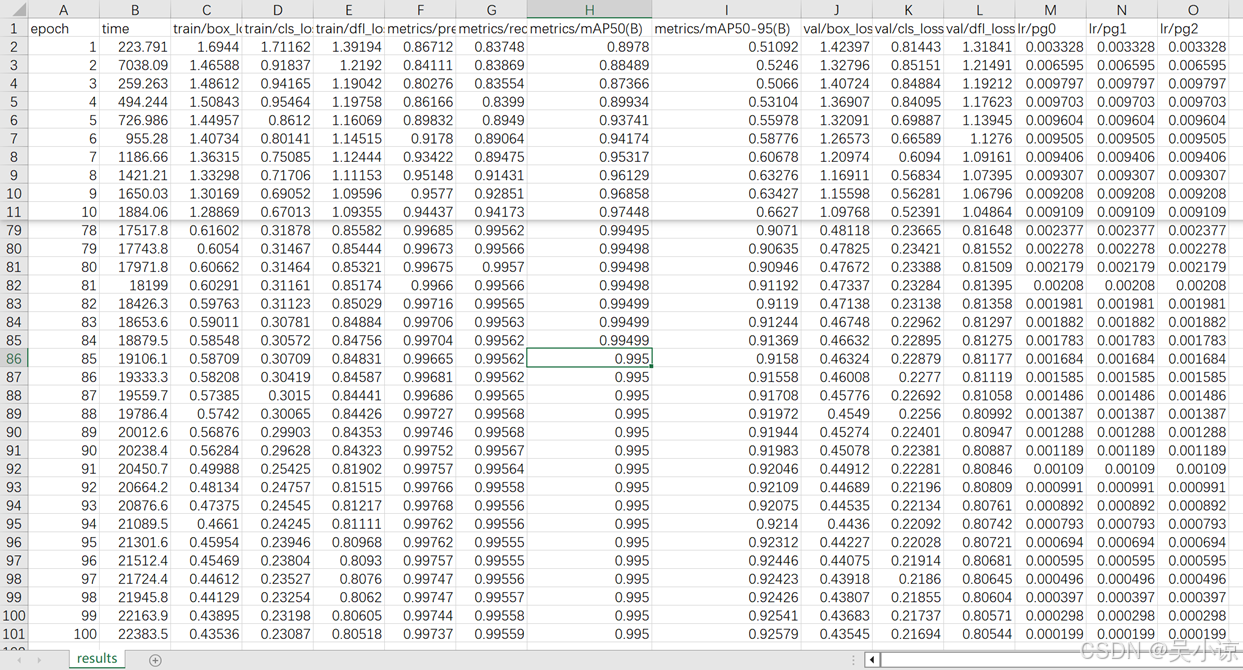
结果保存到了runs\detect\train2中。打开results.csv可以看到,我的mAP50在第7轮的时候就达到了0.95,在第85轮的时候就稳定在了0.995。
参考文献:
目标检测:YOLOv11(Ultralytics)环境配置,适合0基础纯小白,超详细_yolov11环境配置-CSDN博客
YOLOv11来了,使用YOLOv11训练自己的数据集和推理(附YOLOv11网络结构图)-CSDN博客
最新版最详细Anaconda新手安装+配置+环境创建教程_anaconda配置-CSDN博客
附件:
train2.zip
通过网盘分享的文件:train2.rar
链接: https://pan.baidu.com/s/1m9S_yA3tyXPBu9j6rL9Abg?pwd=7arj 提取码: 7arj

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









