







linux link list结构图如下:
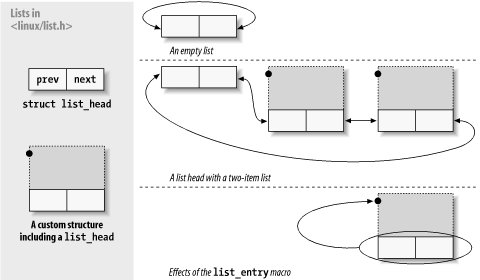
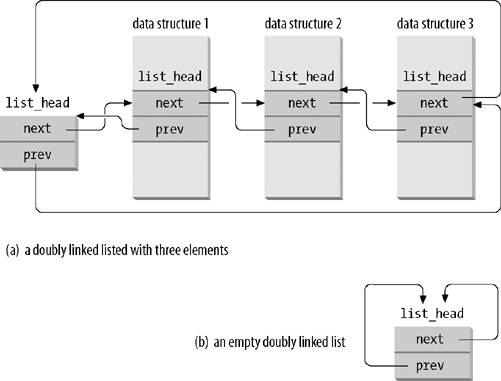
内核双向链表的在linux内核中的位置:/include/linux/list.h
使用双向链表的过程,主要过程包括创建包含struct link_head结构的结构体(item),建立链表头,向链表中添加item(自定义数据结构,双向链表数据单元),删除链表节点,遍历链表,判空等。
1、建立自定义链表数据结构
- struct kool_list{
- int to;
- struct list_head list; //包含链表头
- int from;
- };//自定义欲链接的数据额结构,并包含双向链表结构
- struct kool_list mylist;
- INIT_LIST_HEAD(&mylist.list);//初始化一个链表表头
static LIST_HEAD(adc_host_head);//初始化一个链表头adc_host_head
第二种创建链表头和第一种的区别在于,第二种在编译的时候才会被初始化。还有一点就是链表头是独立的还是位于自定义链表数据结构中的。就好比在《例说Linux内核链表(二)》中给出的链表结构图和本文给出的结构图的区别。
3、向链表添加item
list_add(struct list_head *new, struct list_head *head);
例如:
- struct kool_list *tmp;
-
- tmp= (struct kool_list *)malloc(sizeof(struct kool_list));
- printf("enter to and from:");
- scanf("%d %d", &tmp->to, &tmp->from); //初始化数据结构
- /* add the new item 'tmp' to the list of items in mylist */
- list_add(&(tmp->list), &(mylist.list));//项链表中添加新的元素节点,tmp中的list
list_add_tail(struct list_head *new, struct list_head *head);
在链表的尾部添加一个item,和list_add的区别在于,list_add把新的item加到了链表头的后面,list_add_tail把item加到了链表头的前面。
4、遍历链表
list_for_each_entry(type *cursor, struct list_head *list, member)
这并不是一个函数,它是一个for循环,依次列出要遍历的链表,三个元素代表的意义:type *cursor代表item的指针,struct list_head *list是链表头,member是item中包含的list_head数据项。通过这三个数据可以定位到链表的每一个数据元素。其中定位原理就是结构体偏移。
例如:
- list_for_each_entry(tmp, &mylist.list, list)
- printf("to= %d from= %d\n", tmp->to, tmp->from);
这个宏可以分为两步,第一步是遍历链表,pos依次指向链表中每个item的struct list_head 结构,第二步是获取pos指向的struct list_head所在的item。这里是tmp 。
list_for_each(pos, &mylist.list){//遍历链表,pos依次指向链表的元素
tmp= list_entry(pos, struct kool_list, list);//获得包含pos节点的数据结构指针
5、删除
删除链表中的某节点,首先要使用安全遍历,然后再删除。
例如:
- list_for_each_safe(pos, q, &mylist.list){
- tmp= list_entry(pos, struct kool_list, list);
- printf("freeing item to= %d from= %d\n", tmp->to, tmp->from);
- list_del(pos);
6、链表空
int list_empty(struct list_head *head);
Returns a nonzero value if the given list is empty.
参考网站:http://www.makelinux.net/ldd3/chp-11-sect-5
版权声明:本文为博主原创文章,未经博主允许不得转载。
原文:http://blog.csdn.net/eliot_shao/article/details/47253297















 4462
4462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









